はじめに
みなさん、こんにちは。今日も元気にGemini使ってますか?
私も元気にGemini使ってます。むしろ、四六時中、鬼チャ(鬼のようにチャット)してます。
ところで、私ごとなのですが、近頃急速にGemini Live APIが気になり始めました。これって恋かも。
ということで、今更ながらGemini Live APIについて、あれこれ調べてみました。
Gemini Live APIとは?
Gemini Live APIとは、その名の通り、リアルタイム形式でGeminiと対話できます。
みなさまのいつものGeminiアプリでもLive右下のボタンを押すとLive形式でGeminiとやりとりできます。
というか、話題になっていたので、すでにガンガンお使いかもしれませんね。
Gemini Live APIは、名前の通り、そんなLive機能をAPIとして使えるよ。と言うものですね。
ここまでは、前座も前座、知ってるよ!な情報ですが、ちゃんと公式リファレンスを読んでみました。
以降、公式リファレンスを読んであーだこーだ言っていきます。
基本情報
通信形式はWebSocketで、具体的にやりとりする方式は以下のようです。
リクエスト形式:JSON
レスポンス形式:JSON, Blob
参考:
Gemini Live APIを使用可能な方法は以下2つ。
- Google Gen AI SDK
- Vertex AI Studio
そして、Gemini Live APIで対応モデルは以下です。
- Gemini 2.5 Flash
- Gemini 2.0 Flash
参考:
だがしかし、どのモデルもプレビュー版のようです。
とはいえ、モデルのライフサイクルがとても早いので、Gemini 2.5 Flash一択になりそうですね。
あくまで個人の感想ですが、Gemini 2.0 Flashは、GAになる頃には廃止になりそうな気もしなくもない気がしています。
(Gemini 3.0もわくわく)
Gemini Live APIでできること
さて、Gemini Live APIでできること、がやっぱり気になるポイントかと思います。
ただ、「Gemini Live APIでできること」にすると無限にあると思うので、
私セレクトで、ここがすごいなあ。なポイントを紹介させていただきます。いざ参ります。
- マルチモーダル性
- ツール系も使える
- 音声検知
- 会話セッション時間上限
- コンテキストウィンドウ設定
- 感情理解までしてくれる
マルチモーダル性
ここがやっぱり、通常のGeminiと一番違うポイント。
入力の対応は以下の通り。
入力:音声 / 動画
出力:音声
はい。普段のGeminiとは違い、テキストが逆にないですね。尖ってますね。
しかし、心配すること勿れ、入出力音声の文字起こしもテキスト形式でレスポンスしてくれます。
こちらは、できる限り早く生成してレスポンスしてくれるため、細切れでテキストがちょこちょこ送られてきます。
ただし、順序保証はされないようです。
参考:
ツール系も使える
生成AIといったらもうツールなしでは...、と心持ちになっているかと思いますが、
ツールもバッチリ使えます。
- 関数呼び出し
- コードの実行
- Google 検索によるグラウンディング
- Vertex AI RAG Engine によるグラウンディング(プレビュー)
引用元:
なんとなく、人間の直感?的に音声でやりとりしながらコード実行って、たまげました。
え、声で指示するだけで、コード書いて実行してくれるってこと?
もう人間とAIの境界がわからんですね。(個人の感想です)
あとは、いつもの安心と信頼のGoogle 検索、これ何がいいって、
コード組み込みツールなのでコードを一行ペッと書くだけで、簡単にグランディングしてくれます。ほんっっっと、天才。
Vertex AIのサービスは基本、Google 検索簡単に使えるようになり、
あたりまえの存在になっていますが、感謝を忘れてはいけません。
手動での検索設定はいろいろ地獄です。(関数定義のメンテ、APIキーの設定などなど)
いつもそばにいてくれる存在にこそ、感謝しましょう。
また、現在プレビュー版ですが、Vertex AI RAG Engine(旧:LlamaIndex on Vertex AI)をさくっと参照してくれるようです。
組み込みツール、という位置付けなので、config設定でどのRAG Engineか?を指定するだけで使えます。ありがたやありがたや。
とはいえ、テキストでの検索となるため、入出力音声の文字起こしのテキスト品質が重要になってきますね。
今はまだ文字起こしに対して、細かいカスタマイズはできないようですが、
入出力音声の文字起こしのテキストできるようにするぜ!という兆しを感じますね。
兆しの部分
input_audio_transcription:AudioTranscriptionConfig
output_audio_transcription:AudioTranscriptionConfig
引用元:
音声検知
あとはなんといっても、音声検知。
音声検知のすごい機能のおかげで、
話終わった沈黙を検知してくれたり、モデルが話している時に私たちが話すと割り込みができたり、するってわけです。
しかし、人の話を最後まで聞きなさい。と先生やお母さんに言われたのに、なんともモヤモヤしますね。
また、これも自前で実装しようとすると、無音部分の待機や、UX向上したい!だから音声中断できるようにして!となった場合、地獄を見ますね。
音声検知についても、いろいろ設定ができるようで、具体的には「AutomaticActivityDetection」クラスを使用して設定できます。
どのくらいの確率で音声検出、終了するのか。や、細かく検出されるまでの時間の設定などもできます。
レイテンシーを気にしてさくさくレスポンスして欲しいのか。
それとも、ある程度音声入力(人が話している)を待ってから、レスポンスして欲しいのか。
音声入出力と一口に言っても用途によって、絶妙に違いますし、使い心地に直結する部分ですよね。
あとは、こちらのプログラム側で音声ストリームは完全制御したい!という際に、音声検知をオフにすることもできます。
参考:
会話セッション時間上限
ななな、なんといっても使用感という観点から、気になっていたんですが、
会話セッション時間上限は無いようですね。
セッション延長は10分単位で、延長回数も無限。
せつない夜にも会話を続けたい分だけ延長し放題、ということですね。
参考:
コンテキストウィンドウ設定
これは、公式リファレンスからがっつり拝借しましょう。
リアルタイムでストリーミングされたデータ(音声の場合は 1 秒あたり 25 トークン(TPS)、動画の場合は 258 TPS)
trigger_tokens:5,000〜128,000
target_tokens:0〜128,000
引用元:
ふむふむ。
trigger_tokensは、設定する値を超えると、コンテキストウィンドウを圧縮してくれるそうですね。
target_tokensは、その圧縮時に最大値としてどれくらいまで保持します?っていう設定ですね。
そして、コンテキストウィンドウを超過しても勝手にブチっと会話が切れることはないようですね。
使用感という観点から、終焉は気になっていたんですが、よしなにしてくれるようでよかったです。
参考:
感情理解までしてくれる
なんと、感情理解までしてくれるんだとか。
ただし、Live API ネイティブ音声対応モデルに限る。しかも、Live API ネイティブ音声は公開プレビュー。
となんとまあ、プレビューに次ぐプレビューの応酬で、プレビューだよ!という意思が強いですが...。
個人的に、え!?感情理解!?となったので載せておきます。
試してみた
さて、Gemini Live APIの公式リファレンスにわくわくしたところで、実際にかるーくお試してみました。(もっとカスタマイズしたい、します)
関連技術
- Gemini Live API
- Agent Starter Pack
- v0.16.0
- Agent Development Kit(ADK)
今回は、Agent Starter Pack + ADKでサクッと環境が作れるので、恩恵に預かりました。感謝。
基本的に、公式リファレンスにあるのは、Gen AI SDKを使用したColabの情報が多いです。
ただ、今回はなんといってもリアルタイムが!売り!ということで、
Colabでぽちぽちだと味気ない & せっかくのリアルタイムのインタラクティブな体験!を体感しづらいので、Agent Starter Packに助けてもらいました。
セットアップ
セットアップは基本Agent Starter Packプロジェクト作成のみで完了です。
そもそものAgent Starter Packの導入も簡単なので、以下の公式リファレンスをご覧ください。
$ agent-starter-pack create <作成プロジェクト名>
はい!以上です。
...はい、いろいろ聞かれるので、設定内容を記載しておきます。
- エージェントテンプレート:adk_live
- デプロイ先:Cloud Run
- CI/CD設定:Cloud Build
- リージョン:空(デフォルト)
- Google CloudプロジェクトID:ご自身のGoogle CloudプロジェクトID
ちなみに、Agent Starter Packのアプデも鬼のように早いです。
エージェントテンプレートも割とガンガン変わります。
そして、新しい設定がどんどんできてたりします。
ですので、あくまで今時点(2025/10/13)とご承知おきくださいませ。
$ agent-starter-pack create <作成プロジェクト名>
=== Google Cloud Agent Starter Pack 🚀===
Welcome to the Agent Starter Pack!
This tool will help you create an end-to-end production-ready AI agent in Google Cloud!
> Please select a agent to get started:
1. adk_base - A base ReAct agent built with Google's Agent Development Kit (ADK)
2. adk_live - Real-time multimodal agent with ADK and Gemini Live API for low-latency voice and video interaction.
3. agentic_rag - ADK RAG agent for document retrieval and Q&A. Includes a data pipeline for ingesting and indexing documents into Vertex AI Search or Vector Search.
4. langgraph_base_react - An agent implementing a base ReAct agent using LangGraph
5. crewai_coding_crew - A multi-agent system implemented with CrewAI created to support coding activities
6. Browse agents from google/adk-samples - Discover additional samples
Enter the number of your template choice (1): 2
> Please select a deployment target:
1. Vertex AI Agent Engine - Vertex AI Managed platform for scalable agent deployments
2. Cloud Run - GCP Serverless container execution
Enter the number of your deployment target choice (1): 2
> Please select a CI/CD runner:
1. Google Cloud Build - Fully managed CI/CD, deeply integrated with GCP for fast, consistent builds and deployments.
2. GitHub Actions - GitHub Actions: CI/CD with secure workload identity federation directly in GitHub.
Enter the number of your CI/CD runner choice (1): 1
Enter desired GCP region (Gemini uses global endpoint by default) (us-central1):
> You are logged in with account: 'xxx'
> You are using project: 'xxx'
> Do you want to continue? (The CLI will check if Vertex AI is enabled in this project) [Y/skip/edit] (Y): Y
> Successfully configured project: xxx
> Testing GCP and Vertex AI Connection...
> ✓ Successfully verified connection to Vertex AI in project xxx
> 👍 Done. Execute the following command to get started:
> Success! Your agent project is ready.
📖 Project README: cat <作成プロジェクト名>/README.md
Online Development Guide: https://goo.gle/asp-dev
🚀 To get started, run the following command:
cd <作成プロジェクト名> && make install && make playground
このadk_liveテンプレートで作成されるメインの技術スタックはこんな感じです。
んー、いまどきな技術スタックですね。さいこー。
- フロントエンド:React
- バックエンド:FastAPI + ADK
- インフラ:Terraform
また、デプロイ先ですが、今回はローカル環境からさくっと設定諸々試したかったので、Cloud Runにしています。
というのも、先ほど、少し出てきたGemini Live APIのパラメータ系の食わせ方が
Agent Starter Packで作成されるAgent Engineアプリのデフォルトそのままだと諸々書き換える必要があるので、Cloud Runにしています。
うんうん、Agent Starter Packは基本、各テンプレートで、Agent EngineかCloud Runか選べる二度美味しい感がさいこーですよね。
また、次回はAgent Starter Pack + Agent Engineで遊ぼうと思います。
Agent Starter Packについてはまだまだ話し足りないですが、本日の主役はGemini Live APIなので先にGo。
そして、ローカル環境の起動は以下のコマンドです。
初期化して...
$ cd <作成プロジェクト名> && make install
起動!
$ make playground
これだけで、フロントエンドもバックエンドも即起動します。
ちなみに、以下のコマンドの場合、frontend(React)をビルドして、app(FastAPI)で配信してくれます。
$ make playground
以下の通り、FastAPI側でルーティングしてくれていますね。
@app.get("/{full_path:path}")
async def serve_frontend_spa(full_path: str) -> FileResponse:
"""Catch-all route to serve the frontend for SPA routing.
This ensures that client-side routes are handled by the React app.
Excludes API routes (ws, feedback) and static assets.
"""
# Don't intercept API routes
if full_path.startswith(("ws", "feedback", "static", "api")):
raise HTTPException(status_code=404, detail="Not found")
# Serve index.html for all other routes (SPA routing)
index_file = frontend_build_dir / "index.html"
if index_file.exists():
return FileResponse(str(index_file))
raise HTTPException(
status_code=404,
detail="Frontend not built. Run 'npm run build' in the frontend directory.",
)
ただ、ローカル環境の場合、フロントエンド側のコードもゴリゴリ変えていくと思うので、
開発する用途であれば以下のコマンドがおすすめです。
$ make playground-dev
上記の場合、frontend(React)とapp(FastAPI)で別々で起動してくれるため、
フロントエンド側のホットリロードも効くようになりますね。
はい。そして起動すると以下のような画面が表示されます。

うおー。かがくのちからってすげー。
コード周り(Gemini Live API設定)
ここからはほんの少しだけコード周りの話です。
くどいようですが基本的に、Agent Starter Packのadk_liveテンプレートを99.9%くらいそのまま使っているだけです。
ですので、今回はお試しとしてGemini Live API関係の設定をちょこーっと弄ってます。
大きく2つ
- システム指示調整
- ADK + Gemini Live API設定
システム指示調整
まず、root_agentのシステム指示のところを日本語にしています。
app/agent.py
instruction="あなたは親切な日本語のアシスタントです。必ず日本語で回答してください。",
これ、元々英語のシステム指示だったんですが、
元の何も調整しない場合は、マルチリンガルで、グローバルな感じになったので、
まずはプロンプト調整しています。
ADK + Gemini Live API設定
ここが、公式リファレンスの情報が少なく、ハマりかけたところです。
なおさら、今回ADK経由でGemin Live APIを使用しようとしていたため、なかなかこんがらがりました。
そもそも、ADKは、Gemini Live APIを使用するためのメソッドとして、run_liveというものを用意してくれています。
このrun_liveメソッドは内部的にGenAI SDKをラップしているため、わざわざ手元のプログラム側で、GenAI SDKと連携させずにすんでいます。やったー。
※そもそも、Gemini Live APIを使用可能な方法は上述の通りの2つです
ここまでの初期設定は、Agent Starter Packでしてくれているので、
Gemini Live APIの細かい設定はどうするんだい。というところなんですね。
これは、run_liveを実行する時に、RunConfigを渡してあげるだけです。
今回はシンプルに以下のようにしてみました。
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name="Kore"
)
),
language_code="ja-JP",
),
response_modalities=["AUDIO"],
output_audio_transcription=types.AudioTranscriptionConfig(),
input_audio_transcription=types.AudioTranscriptionConfig(),
)
run_configをそのまま渡してあげる。
events_async = runner.run_live(
user_id=self.user_id,
session_id=self.session_id,
live_request_queue=live_request_queue,
run_config=run_config,
)
ちなみにvoice_nameは、以下から選べます。
以下のサイトで実際にサンプルボイスも聞けるので、ぜひご覧ください。
ADK + Gemini Live APIの設定はADK公式などでも取り上げているので、こちらもぜひご覧ください。
参考:
実際に試した結果
さて、話しすぎましたが、ようやっと試した結果について、です。
今回試したこととしては、以下の3つ。
- 音声入力のみ
- 音声入力 + 動画入力
- 音声入力 + 画面共有入力
音声入力のみ
まずは、大本命の音声入力から試してみました。
これだけだと、せっかくのリアルタイム!な感じがいまひとつ伝わらないと思いますが、雰囲気だけでも感じてくださいませ。
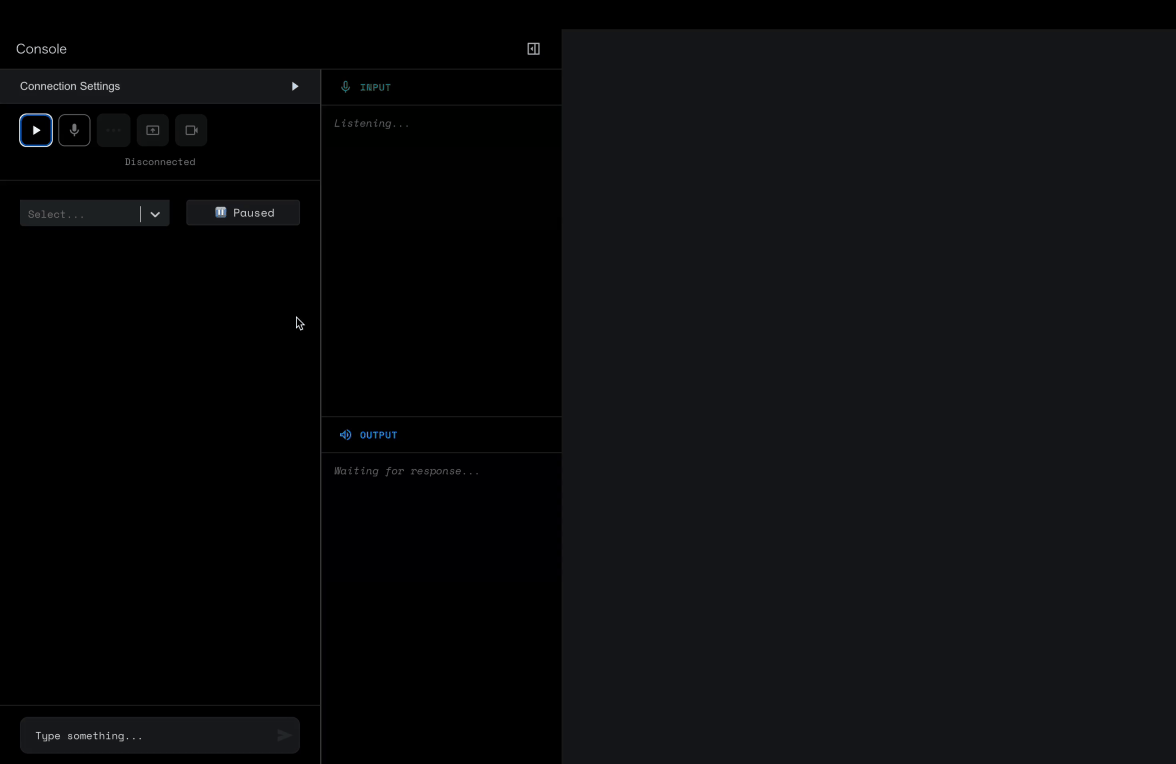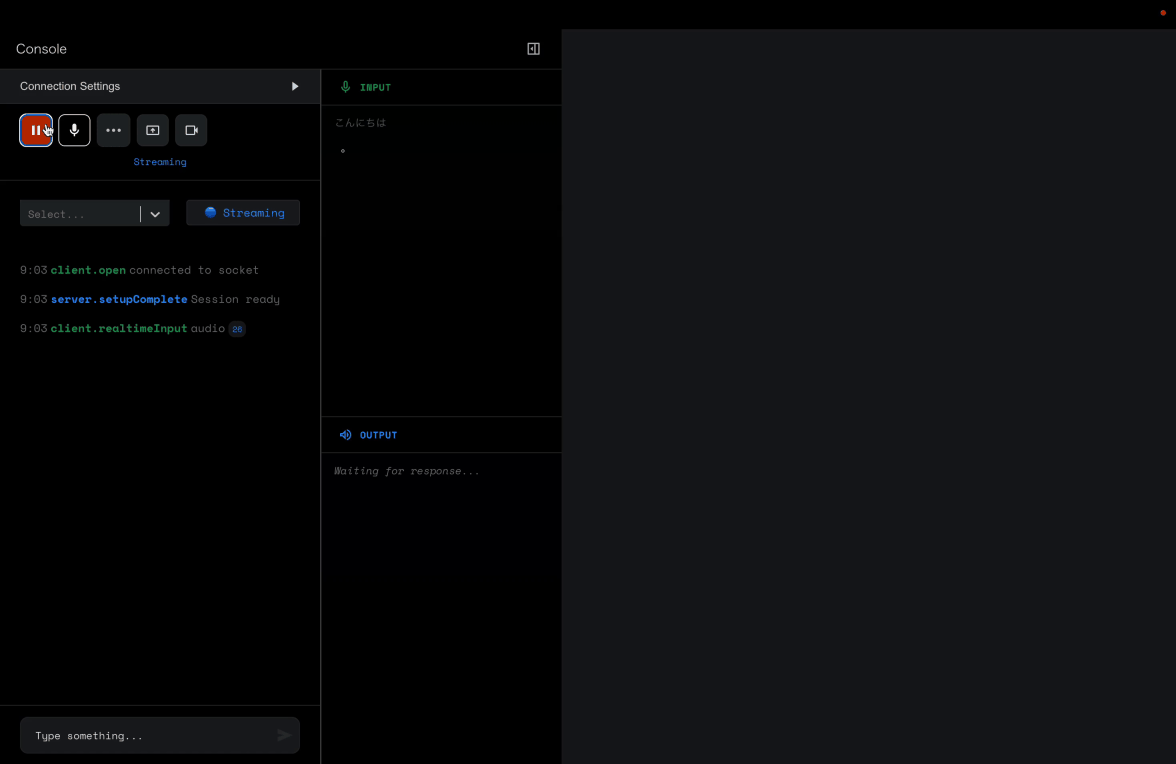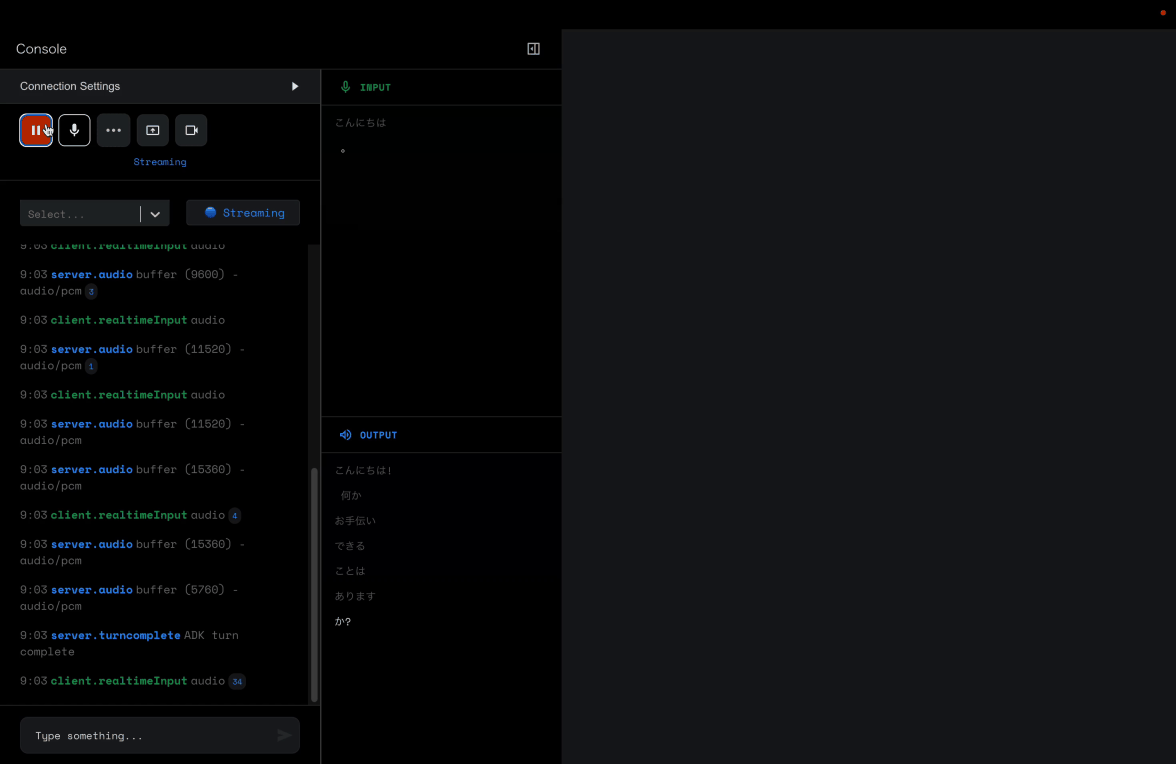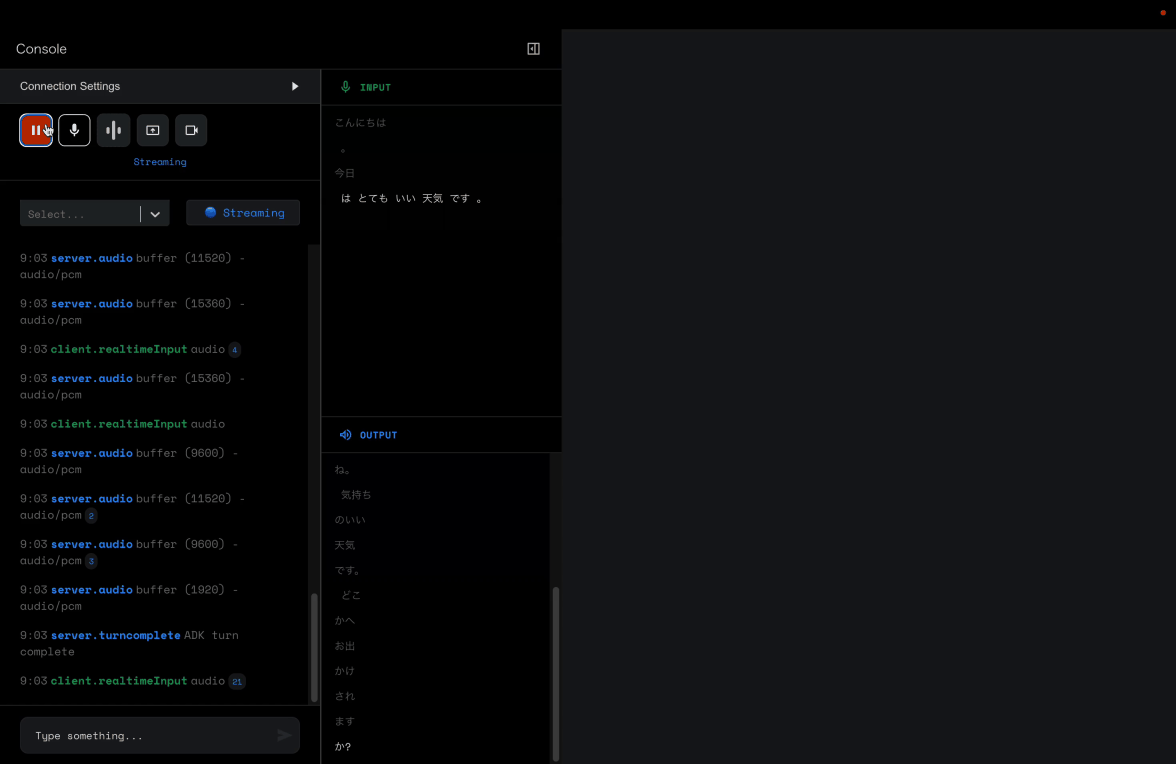
おおおおお、すごい。
この場で音声まで伝えられないのがとても残念ですが、
割り込みしても待ってくれますし、なによりびっくりしたのが息づかいを感じました。
ある程度のセンテンスを話したあと次のセンテンスに移る前に息を吸います!
息を吸います!AIが!息を吸います!
音声合成モデルとしては、内部的にChirp 3を使用しているようですが、Chirp3ここまで素敵だとは...!
あとは、日本語はちょっと拙い箇所もありますが、アナウンサーと話している感じがあります。
あくまで所感ですが、language_code="ja-JP"を設定したおかげで、文字起こし系も日本語で文字起こししやすくなってくれた気がします。
もう少しいろいろほじくってみたいですね。
参考:
音声入力 + 動画入力
続いて、動画入力も試してみました。
こちらも、臨場感と感動がいまひとつ伝わらないと思いますが、雰囲気だけでも感じてくださいませ。
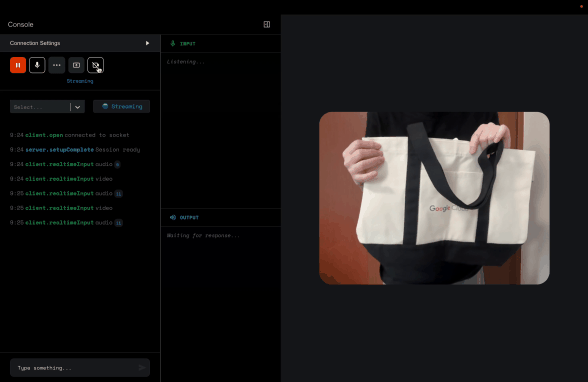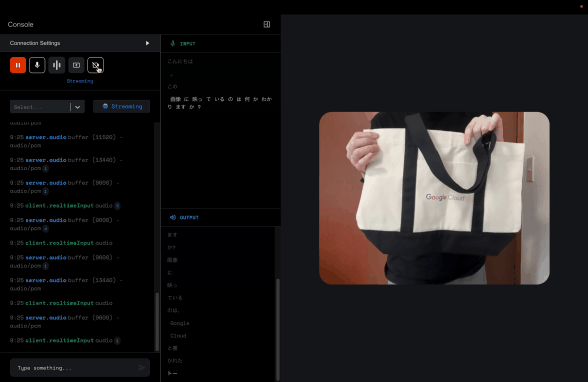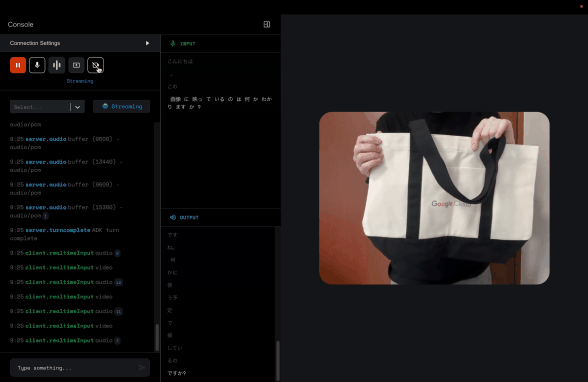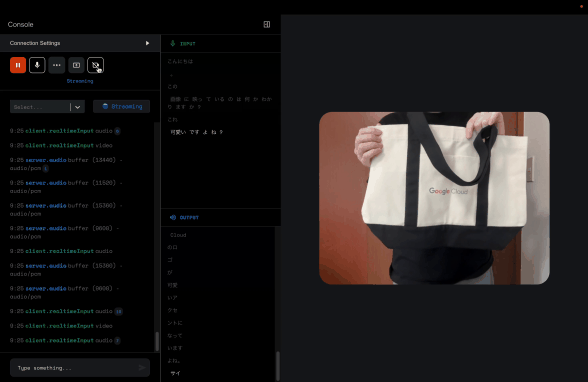
カメラで意気揚々と映しているものについて質問したら、きちんとこのトートバッグについて説明してくれました。
この「音声入力 + 動画入力」は、まさにマルチモーダル、特に目で見て、耳で聞いている感が強いですね。
今回はできなかったんですが、もっと動きのあることに対してどれくらい追従してくれるのかも気になりますね。あとは、人間の表情の検知とか。夢いっぱい。
音声入力 + 画面共有入力
この貼り付けているサンプルが微妙なのでなんとも言い難いですが、雰囲気だけでも感じてくださいませ。
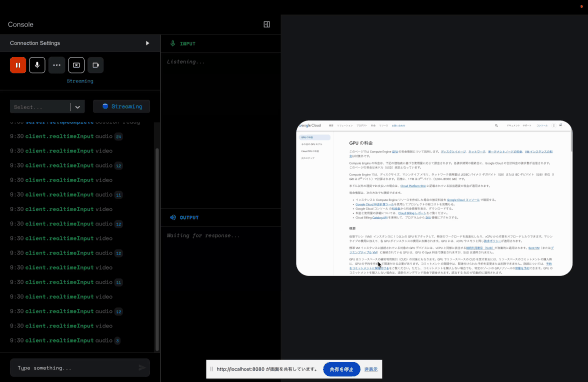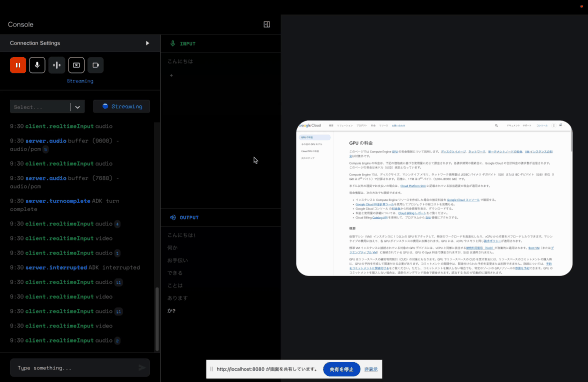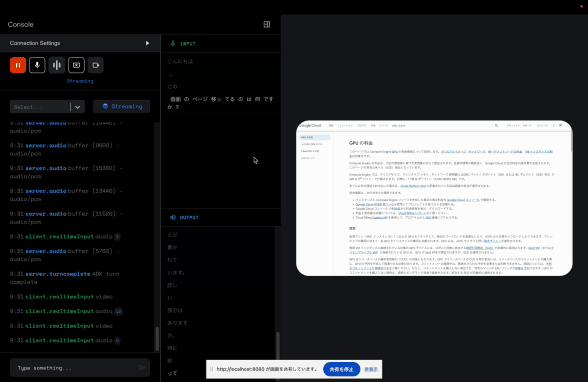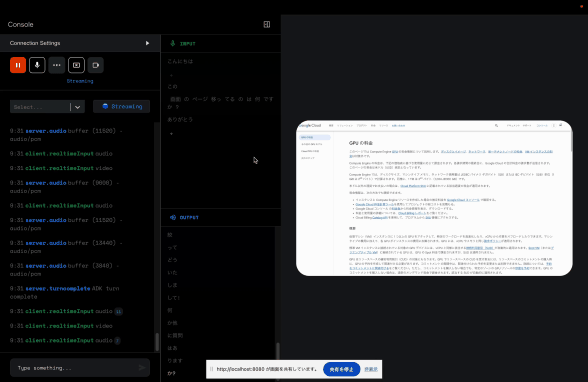
こちらはブラウザの画面共有をしながら、声でこのページに対して説明するようにお願いしています。
なんともしっとりした感じですが、我々の日々の業務に直結しやすい機能ですよね。
今はMCPを使用してブラウザの操作もできるので、音声であれこれ指示しつつブラウザ操作までするアプリもサクッと作れそうですね。
そして、それを側から我々が見守る。という時代なんですね。
さいごに
Gemini Live APIの概要からお試しまで、少々長くなりましたが、最後までお付き合いいただきありがとうございました。
いやあ、楽しすぎました、Gemini Live API。
肝心要である、音声入出力周りのカスタマイズ性が高く、痒い所に手が届いている感じが最高すぎます。特に、音声検知のところは、みなさん必ずぶち当たる壁だと思いますが、手元のプログラム側であれこれコマコマ実装せずとも設定するだけ、でいいというのは大変嬉しいですね。
あとは、本筋とは少しずれますが、
なんといってもAgent Starter Pack + ADKのおかげでサクッと試せるのがいい。これはGoogle全体のエコシステムさまさまですね。
ということで、
ぜひ皆様も、Gemini Live API!Agent Starter Pack!ADK!を使って素敵なライブエージェントライフをお過ごしくださいませ。
私ももっと弄りたいと思います。うずうず。
Gemini Live API Agent Starter Pack ADK

Discussion