GPT-4oに対抗しうるオープンソースでローカルのエッジサーバに実装できるLlama 3-V:おまけにGPT-4の1/100のサイズのモデル
Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars
はじめに
(オープンソースのLLMとしての)Llama3は大ヒットしており、性能面では多くの分野でGPT3.5を上回り、一部ではGPT4をも凌駕しています。その後、GPT4oが登場し、マルチモーダルのデータを処理する能力でさらに優れたパフォーマンスを発揮しました。Metaもこれに合わせてLlama3を基にした初のモデル、Llama3-Vを発表します。特徴的なのは、全て$500ドル以下でトレーニングしたことです。
パフォーマンスについては、Llava (Large Language and Vision Instructing)に対して、10-20%の改善が見られました。また、MMMUを除く全ての分野で、最新の大型の専有モデルと比較してもかなり良い成績を収めています。

このリンクにダウンロード+詳細データがあります
- 🤗: https://huggingface.co/mustafaaljadery/llama3v/
- Github: https://github.com/mustafaaljadery/llama3v
モデルのアーキテクチャ
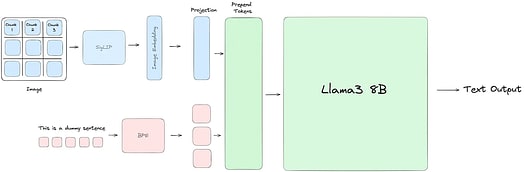
Llama3の画像理解能力を向上させることに多くの努力を注いでいます。まず、画像を小さなコンポーネントに分解するためにSigLIP ( Sigmoid Loss for Language Image Pre-Training) モデルを使用します。次に、これらの部分をテキスト部分と一致させるために、projection blockと呼ばれるステップを実行します。このステップでは、2つのself-attention blocksを使用して画像部分とテキスト部分を整列させます。最後に、projection blockからの画像部分をテキスト部分の先頭に追加します。この結合された画像-テキスト部分は、その後、通常通りLlama3によって処理されます。

このプロセスがどのように機能するかを示しています。
Llama3-Vアーキテクチャでは、SigLIPというツールを使用して入力画像をパッチに分割します。その後、特別なブロックをトレーニングして、テキストと画像のトークンを一致させます。
SigLIP
SigLIPは、画像と言語をリンクさせるツールです。これは、CLIPという別のツールに似ていますが、いくつかの違いがあります。全ての画像-テキストペアを一度に見るのではなく、SigLIPは各ペアを個別に見ます。画像を重ならない部分に分解し、低次元空間に配置します。これにより、重要な視覚的特徴に焦点を当てることができます。我々の作業には、Google DeepMindによって開発されたオリジナルのSigLIPツールを使用しています。
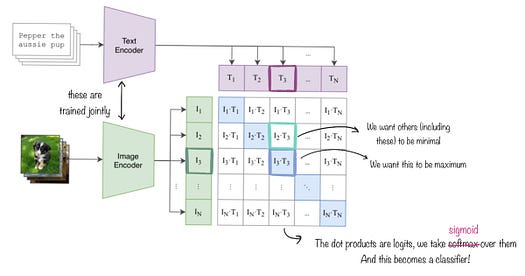
SigLIP埋め込み(SigLIP Embeddings)の仕組みを説明します。画像とテキストのデコーダを一緒にトレーニングしますが、テキストのエンコーディングモジュールはそのままにします。この方法はCLIPに似ていますが、異なる種類の損失を使用します。画像はMerveのTwitter投稿からのものです。
テキスト埋め込みとの一致:
リソースを節約するために、SigLIPは変更しません。しかし、画像埋め込みがLlama3のテキスト埋め込みと一致するようにします。これを特別なモジュールで行います。Llavaが単一の層を使用するのに対して、我々は2つのself-attention blocksを使用します。これにより、最終的な画像埋め込みベクトルを作成するのに役立ちます。
テキストの前に画像トークンを追加:
テキスト入力の場合、まずByte Pair Encoding (BPE) vocabularyを使用してテキストを部分に分割します。これにより、一連のテキストトークンが得られます。画像埋め込みについては、各ベクトルを別々の「視覚トークン」として扱います。その後、視覚トークンをテキストトークンの前に追加します。この結合された入力がLlama3で使用されます。
モデルの性能向上施策
これらのモデルをトレーニングするには多くのリソースが必要です。計算力を節約するために、2つの主要な変更を行いました。1つ目の変更は基本的なストレージシステムに関するもので、もう1つはMPS/MLXフロントに関するものです。
キャッシング:
SigLIPモデルはLlama3よりもかなり小さいです。そのため、すべてを順番に実行すると、SigLIPが実行されているときにGPUをあまり使用しません。また、SigLIPのバッチサイズを増やすとLlamaでメモリエラーが発生します。その代わり、SigLIPモデルは同じままであることに気付き、画像埋め込みを事前に計算できます。その後、事前トレーニングおよびSFTの両方で、SigLIPモジュールを再度実行する代わりに、これらの事前計算された画像埋め込みを使用します。これにより、バッチサイズを増やし、SigLIPモジュールを実行する際にGPUを最大限に活用できるようになります。また、パイプラインの2つの部分が別々に実行できるため、トレーニング時間も節約できます。
MPS/MLXの最適化
2つ目の最適化も、SigLIPのサイズがLlamaに比べて小さいことに起因しています。特に、SigLIPはMacbookに収まるため、MPSに最適化されたSigLIPモデルで推論を行い、1秒あたり32画像を処理できました。これにより、ストレージステップが比較的迅速に行われるようになりました。
トレーニングプロセス
ステップ1:SigLIPを使用して画像埋め込みを作成
まず、トレーニングの第一ステップとして、SigLIPを使用して画像埋め込みを作成します。このステップでは、画像をSigLIPに投入し、ベクトル表現に変換します。高解像度の画像の場合、LLaVA-UHDと同様に画像を小さなセクションに分割します。これらのセクションはバッチで同時に処理されます。
- 画像の前処理: SigLIPモデルとそのプロセッサをロードして、画像を前処理します。
- 画像-テキストペアの出力: モデルは画像-テキストペアの出力を提供します。この出力に特定の関数を適用することで、画像埋め込みを含む確率が得られます。この埋め込みは画像の視覚情報を捉えています。
ステップ2:プロジェクションマトリクスの学習
画像埋め込みが得られたら、次にプロジェクションマトリックスを学習します。これは、画像埋め込みを共通空間にマッピングするための層です。
- プロジェクションマトリックスの学習: 学習された重み行列を画像埋め込みに適用し、画像とテキストの埋め込みを共通の空間に整列させます。
- 埋め込みの統合: この整列により、埋め込みが相互作用し、視覚的な質問に答えたり、画像にキャプションを付けたりするタスクのために結合されます。この層の結果を「latents」と呼びます。
ステップ3:イメージトークンの追加
latentsが計算された後、これらをテキストトークンの前に画像トークンとして追加します。画像がテキストの前にあるとモデルが学習しやすくなるため、この順序を採用しています。これは、画像にキャプションが付いている状態に似ています。
- 画像トークンの追加: latentsをテキストトークンの前に追加します。
- アーキテクチャの参考: 我々のアーキテクチャはLLaVA-UHDとほぼ同じなので、彼らの図を参考にすることができます。
これにより、モデルは画像と言語の情報を効果的に統合し、視覚的な質問応答や画像キャプション生成などのタスクを遂行できます。
まず、必要なデータを収集し、600,000の画像-テキストの例を使用して事前トレーニングを行います。この間、Llama-3アーキテクチャのメインウェイトは変更せず、プロジェクションマトリックスの更新にのみ注力します。このステップでは、埋め込まれた画像(latents)をテキストと一致させ、結合された表現にし、プロジェクションマトリックスの更新に焦点を当ててLLaMA-3を事前トレーニングします。
ステップ4:教師あり微調整
事前トレーニングの後、モデルを改善するために教師あり微調整を行います。このステップでは、計算された埋め込み(プロジェクションレイヤーからのもの)は変更せず、ビジョンおよびプロジェクションマトリックスのみを更新します。これは、以下の画像に示されているように、赤い部分が変更され、青い部分は変更されないことを示しています。これにより、マルチモーダルテキスト出力の生成が向上します。このために、1Mの例(7Mに分割された画像)を使用します。
キーポイント
- ビジョンエンコーダーを備えた強化されたLlama3 8B。
- 現在最も優れたオープンソースのビジョン言語モデルであるLlavaと比較して、パフォーマンスが10-20%向上。
- GPT4v、Gemini Ultra、Claude Opusなどのはるかに大きなモデルと同等のビジョンスキルを持つ。
- モデルを$500以下でトレーニングおよびファインチューニングするための費用対効果の高い方法を示しました。
Discussion