Apple Intelligenceは内部でどのように動いているのか、の考察
How does Apple Intelligence Really Work? | Medium
Apple Intelligenceはどのように機能するのか?
ご存じの方も多いかと思いますが、Appleはついに製品向けのGenAI機能群を導入しました。その名もApple Intelligenceです。
この機能群には、Emojiメーカーや執筆・画像ツール、そして待望のSiriのアップデートなどが含まれています。
しかし、ここでの重要なポイントは、Apple IntelligenceがGenAIの利用を「エッジ」へとシフトさせることを意味しているということです。これは、世界で最も強力なモデルの一部を数億人に提供することが近い将来実現するかもしれません。
幸いなことに、Appleはこれをどのように達成しているのかについて興味深い詳細を共有しており、今日はそれを探っていきます。
エッジデバイスへの大きな一歩
Appleは主要企業として初めて「エッジでのAI」をブランドとしています。
これは、プライバシー問題を避けるために、Apple Intelligenceの多くの作業をデバイス内でできるだけ多く行うことを目指していることを意味します。
データがデバイスを離れて「オープン」インターネットに移行すると、リスクが大幅に増加します。
これらの取り組みは称賛に値しますが、実際には部分的にしか成功していません。しかし、非常に発達したGenAIの実装プロセスを示しています。
デバイス内およびサーバーモデルのファミリー
直感に反して、AppleのGenAI機能は広範なAIモデルに依存します。1つだけではありません。
- 「デバイス内」側では、2024年4月に発表された30億パラメータモデルであるOpenELMと、タスク特化型モデルのセットが含まれます。
- サーバー側では、もう一つのモデルであるFerret-UI(これも4月に発表されました)が、強力に保護されたAppleクラウド、Private Cloud Computeに格納されます。また、別のアダプターセット(詳細は後述)も含まれます。
- ただし、ユーザーのリクエストが複雑すぎる場合、デバイスはChatGPT-4oに送信することができます。
Ferretについての詳細な分析は、4月に書いた記事をご覧ください。
GenAIクラウドの保護方法について理解したい場合、私はサイバーセキュリティの専門家ではありませんが、このXスレッドが詳細にわたって説明しています。
しかし、全体のプロセスはどのように機能するのでしょうか?
プロセスの順番
各リクエストに対して、オーケストレーション機能(アルゴリズム)が最適なモデルを評価します。
- 理想的には、「デバイス内」モデルが処理できる場合、それがデフォルトの選択肢となります。
- そうでない場合、アルゴリズムはAppleサーバーモデルが対応できるかを確認します。
- それでも対応できない場合、ChatGPTに送信するよう促します。これをオプトアウトすることも可能です。
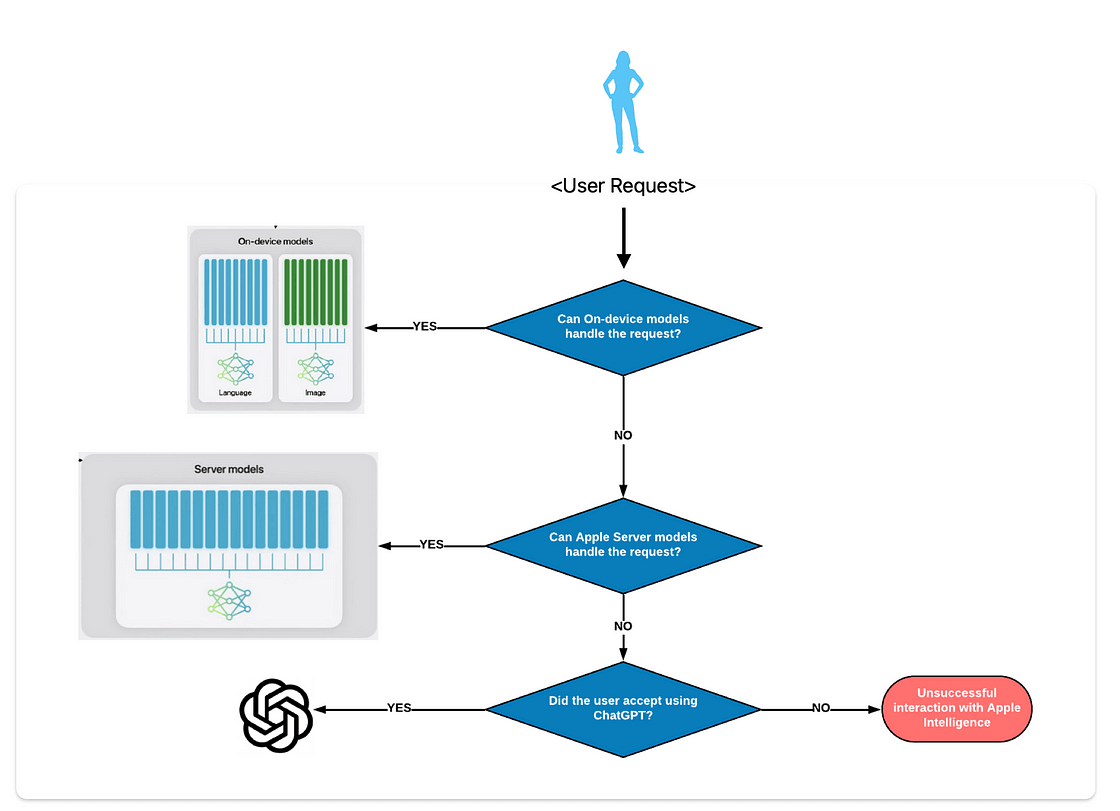
オーケストレーションアルゴリズム
しかし、まだ答えが出ていない質問があります。Apple Intelligenceはどのように機能するのでしょうか?
あらゆるトリックを駆使
エッジでAIを実行する際、つまり、デバイスに完全にロードされ、クラウドに接続されていないAIを実行する際には、現実に直面しなければなりません。それは、より強力でないモデルに妥協することです。
LLMは巨大、それが名前の由来!
AIの世界では、ゲームの名前は「サイズ」です。したがって、ChatGPT、Claude、Geminiなどのフロンティアモデルは、すべて1.5兆パラメータのマークを軽々と超えています。
参考までに、そのサイズのモデルを格納するのに必要なRAMは約3TB(bfloat16(2バイト)あたりの精度で5000億パラメータごとに約1TB)です。
これはほぼ38台の最先端GPU(NVIDIA H100s)に相当します… ただモデルをホストするためだけに。 大きなリクエスト1つでTBのKVキャッシュを生成できるので、これらのモデルがスケールで動作するために数千台のGPUクラスターを必要とするのも驚きではありません。
したがって、モデルのサイズは最大でも3億パラメータに抑えられ、複雑なタスクには全く適していません。
それでもなお、3億パラメータモデルは6GBを占有し、スマートフォンで実行される他のプロセスに2GBしか残されません。LLMのKVキャッシュを考慮しなければなりません。
したがって、Appleはこれを実現するためにいくつかの最適化トリックを駆使しました。
シンプル化と改善
まず、基本モデルのトレーニングが完了した後、そのモデルが簡略化されました。これは、各特徴が2バイトのメモリを占有する代わりに、平均して3.5ビットに削減されたことを意味します。
特徴とは、モデルの知識を保存する要素です。モデルのトレーニングとは、モデルの予測エラーを減らすためにこれらの特徴を更新することです。特徴の値を簡略化することで、学習した知識を使用する能力がある程度影響を受ける可能性があります。
しかし、このタイプの簡略化により、メモリ要件は6GBから約1.5GBに削減され、他のプログラムのためのスペースが確保されます。
ただし、無料で得られるものは何もなく、特徴の簡略化はモデルのパフォーマンスを低下させます(特徴が精度を失うため)。これは、これらのモデルがすでにかなり制限されているため、問題となります。
トレーニング後の簡略化は、普通のサイズのバスケットボールのゴールでモデルにプレーさせ、実際の試合が始まるときにゴールのリムを大幅に小さくするようなものです。一部のシュートはまだ入るかもしれませんが、モデルがその条件下でトレーニングされていないため、質が低下します。
そこでAppleは提案しました。なぜ、複数のカスタマイズされたモデルを使用し、組み合わせることでパフォーマンスを向上させないのでしょうか?
しかし、ちょっと待ってください。
一つのモデルでさえメモリが逼迫しているのに、どうやって複数のモデルを使うことを考えるのでしょうか? ここでトリックがあります。これらの「他のモデル」はすべて、外部アダプターを使用して同じモデルを改良したバージョンです。
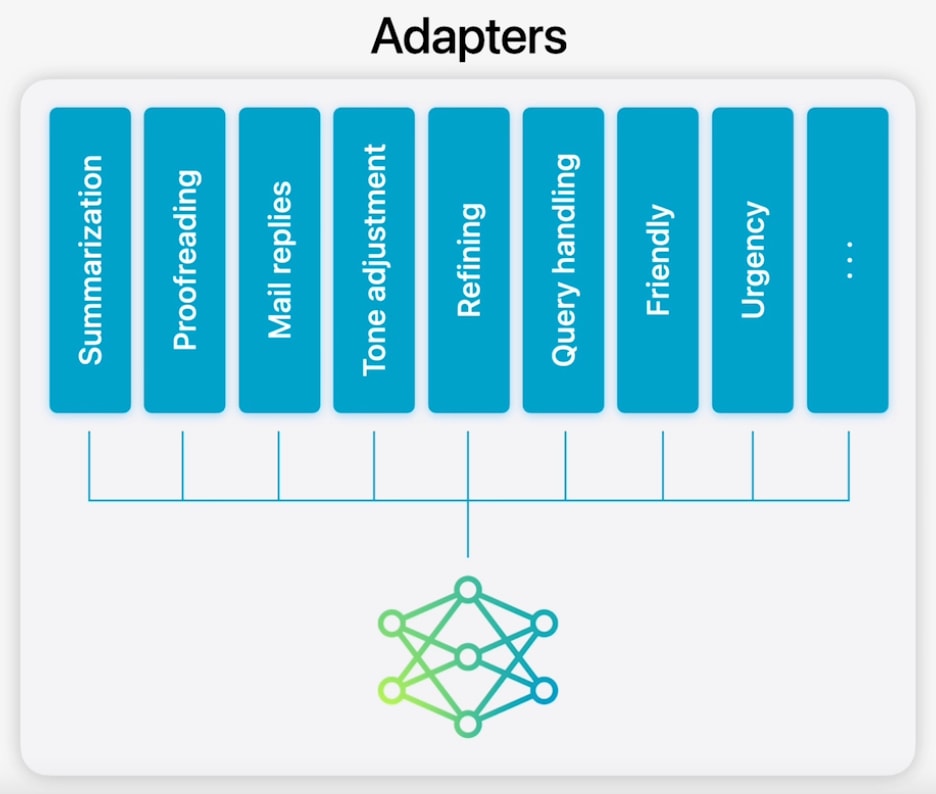
具体的には、Appleはベースモデルを各タスクに合わせて微調整し、LoRAと呼ばれる微調整技術を使用して、タスク特化型モデルのファミリーを作成しました。
すべての重みが重要なわけではない!
LoRAを理解するためには、以下のことを理解する必要があります:
LLMは特定のダウンストリームタスクに対して本質的に低ランクです。
それはどういう意味でしょうか? 簡単に言えば、任意のタスクに対してモデルの一部だけが「重要」だということです。
したがって、ベースモデルを電子メールの要約のために微調整する際、ベースモデル全体を微調整して、事実上オリジナルとは別のモデルを作成する代わりに、そのタスクに関与する重みをアダプターと呼ばれる別の重みセットをトレーニングすることで微調整します。
これがLoRAの概要ですが、おそらくこれだけでは疑問が解決しないと思うので、さらに深く掘り下げてみましょう。
平易な言葉で言えば、ベースモデルに補助的なアダプターを作成します。これを行うために、ベースモデルの異なる重み行列を2つの低ランク行列に分解し、全体の重みセットではなくそれらの行列を微調整します。
従来の微調整では、モデルの全体の重みセットを更新します。
例えば、25個のパラメータしかない小さなネットワークがあった場合、その重み行列をランク1の行列(1行または1列)に分解することができます。
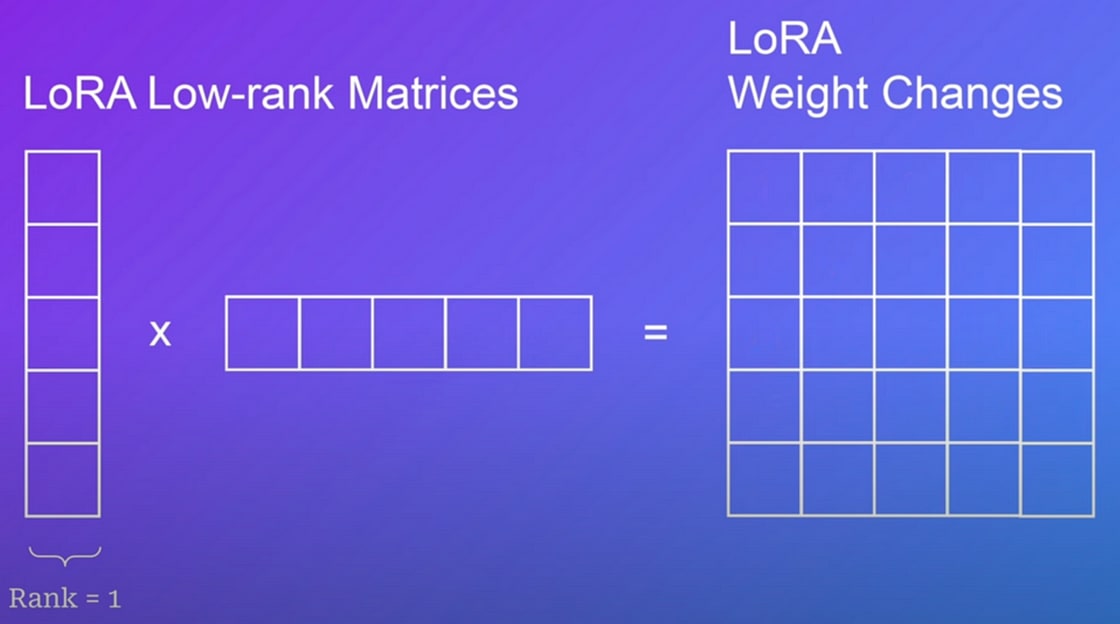
しかし、なぜこれが機能するのでしょうか?
行列のランクは、線形独立な行と列の数を定義します。つまり、ランクが2の場合、この2つの行を使用して残りを生成することができます。
平易な言葉で言えば、これは、行列のサイズがはるかに大きくても、任意のタスクに対して本当に独自の情報を提供するのは2行だけであり、残りの行は冗長であるということです。
したがって、LoRAは本当に重要なパラメータだけを最適化し、残りを変更しないことで、大幅な節約を実現します。
上記の例では、微調整するパラメータの数を25から10に実質的に減少させます。その後、このアダプターがトレーニングされると、触れていないベースモデルに追加することができ、ベースモデルを変更せずに、オンデマンドで微調整されたモデルに変換することができます。
15パラメータの節約は大したことないように思えるかもしれませんが、これらのモデルが数十億パラメータサイズであることを考えると、LoRAアダプターはアクティブにトレーニングされるパラメータ数を98%以上削減し、何億もの重みの更新を避けることができます。
しかし、「別々の行列」をトレーニングしているなら、どうやって実際にモデルの挙動を変えるのでしょうか?
これを行うために、分解された行列を掛け合わせて再構成します。これにより、オリジナルのベースモデル行列と同じサイズの行列(アダプター)が出力され、ベースモデルに追加して微調整されたモデルを作成できます。
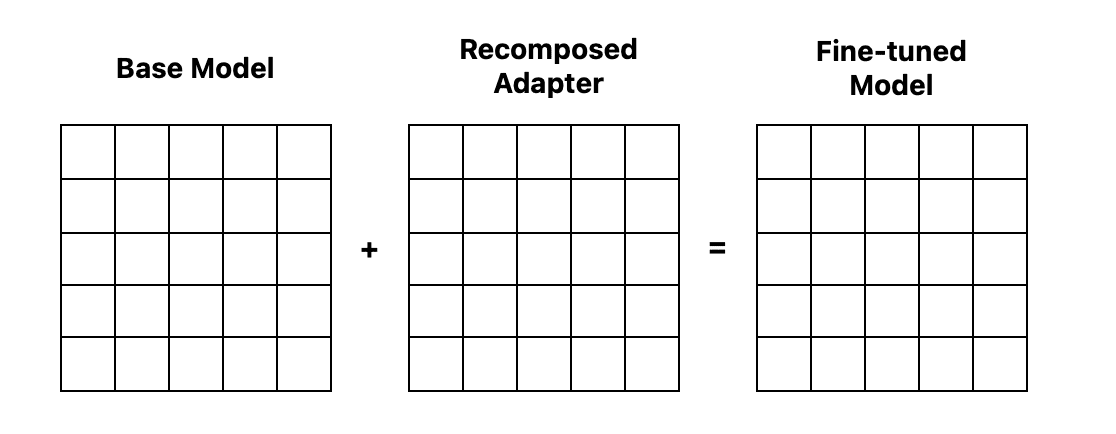
前に見た例では、5×1のベクトルと1×5のベクトルを掛け合わせると、オリジナルと同じサイズの5×5の行列が得られ、これをオリジナルのモデルに追加することができます。
これは簡略化であることを注意しておくことが重要です。‘単一の重み行列’というものは存在せず、重みは層に分割されています。したがって、このアダプターは実際には複数の再構成であり、ほとんどの場合、各層ごとに1つあります。
より視覚的な表現を求めるなら、Predibaseのサーバーレスデプロイメントを使用できます。これは、‘驚くべきことに’Appleの提案と非常に似ています(ちなみに、この方法を発明したのはAppleではありません)。
以下に示すように、アダプターは異なる層に追加され、モデルの挙動を特定のユーザーリクエストに適応させます。
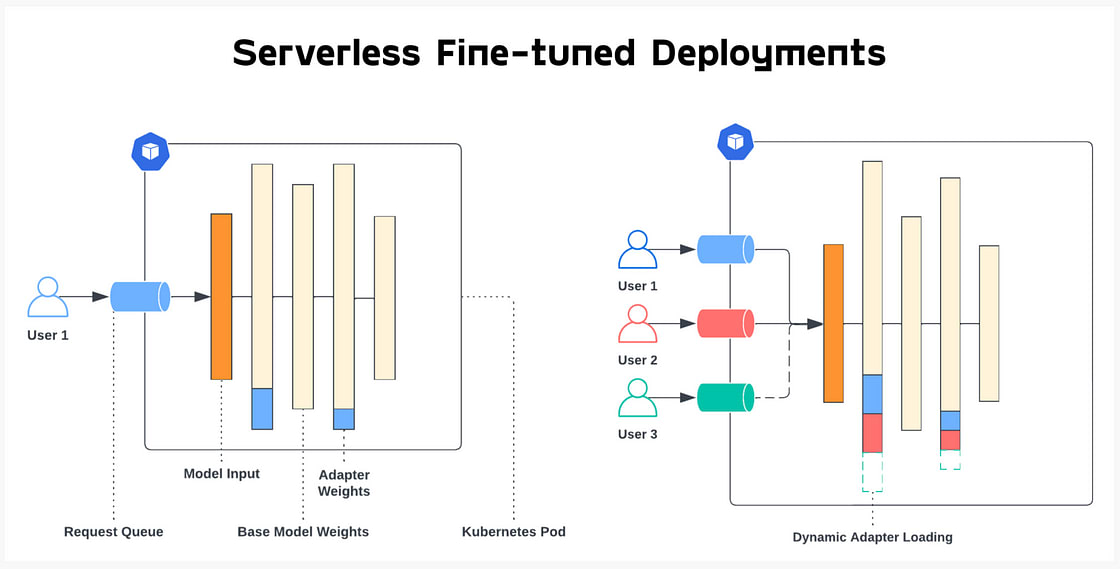
要約すると、LoRA微調整は、オリジナルモデルを変更することなく、異なる重みの変化を追跡する代理モデルのセットを作成することと考えられますが、それらをモデルに追加することで、そのダウンストリームタスクに対して効果的にモデルの挙動を調整することができます。
この非常に巧妙な微調整方法により、Appleは1つの巨大なモデルと、比較的小さな異なるアダプターセットを保存し、ベースモデルを各タスクにオンデマンドで適応させることができます。
したがって、一度にデバイス上に30億パラメータを持つ10個のモデルを保存する代わりに(これは不可能です)、1つの大きなモデルと10個の小さな動的に割り当て可能な‘アドイン’を持つことができます。
これらすべてを考慮すると、Apple Intelligence全体の絵はどのように見えるのでしょうか?
Apple製品の新時代
以下に示すように、Apple Intelligenceはデバイス内モデルとサーバー側モデルを区別する図を提示します。
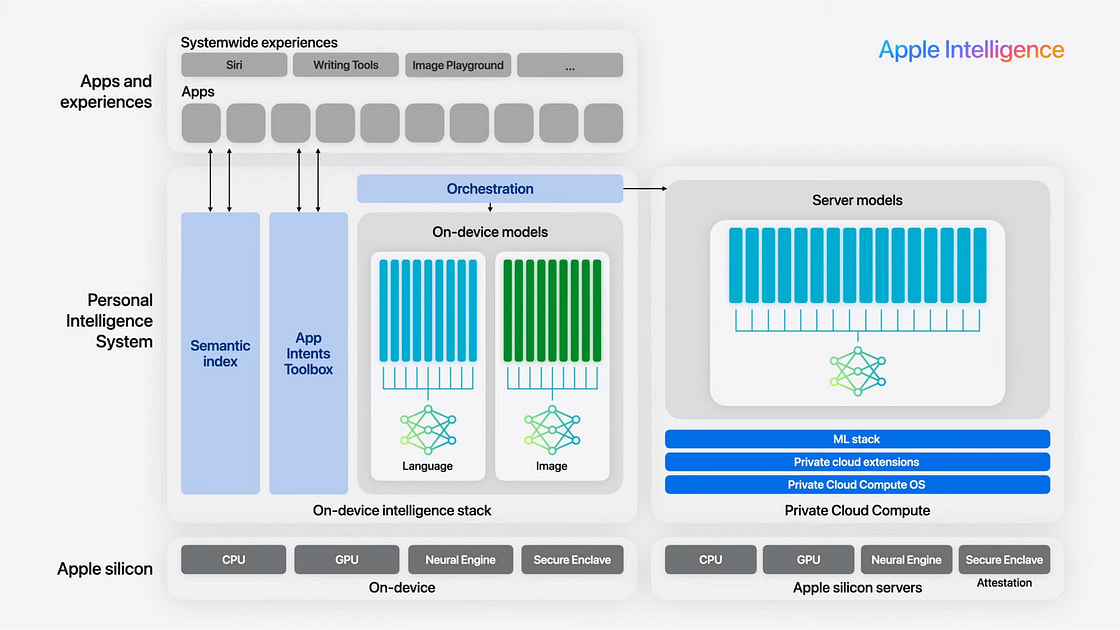
それでは、パズルのすべてのピースは何でしょうか?
- デバイス内モデル: OpenELMおよび画像モデルとそれぞれのLoRAアダプターのセット
- サーバーモデル: Private Cloud ComputeにあるAppleモデルのスタック。LoRAアダプターアプローチはサーバー側でも使用されています。
- オーケストレーション: ユーザーのリクエストがデバイス内で解決されるか、Apple Serverモデルに送られるか、最終的にChatGPTに送られるかを決定するアルゴリズム。
- App Intentsツールボックス: これらのツールはSiriやモデルがさまざまなアプリとやり取りすることを可能にします。
アプリがApple Intelligence対応になるためには、開発者はApp Intents SDKを使用して、Siriのようなシステムがアプリでアクションを実行できるようにする必要があります。
- セマンティックインデックス: これは、おそらくベクトルデータベースで、Apple Intelligenceがデータとやり取りすることを可能にします。たとえば、最新の夫との写真を取得したい場合、それはセマンティックインデックスを使用します。
セマンティックインデックスはおそらくRAGパターンで、Microsoftの現在物議を醸しているリコール機能に非常に似ています。興味深いことに、Appleはこの機能に関してMicrosoftほどの反発を受けておらず(少なくとも存在理由については同じ)、これはユーザーデータの取り扱いに関してMicrosoftがAppleと比較していかに信頼されていないかを証明しています。
それにもかかわらず、Microsoftは昨日この機能を遅らせました ユーザーの安全フィードバックに基づいて改善するためです。
これがAppleにとって何を意味するのでしょうか?
ハードウェアアップグレードを促進する動的モデル適応
簡単です: オンデマンド動的モデル適応。たとえば、ユーザーが最後の10通のメールの要約を求めたとします。
- Apple Intelligenceのアルゴリズムは、これは「デバイス内」で処理できるタスクであると認識し、アダプターを特定してGPUおよびベースモデルにロードします。
- 微調整されたモデル(ベースモデル+アダプター)がコマンドを実行します。
- アダプターはオフロードされ、別のアダプターを持ち込むことができます。
確認されていませんが、Appleは「最近使用した」アダプターを迅速にロードするためにキャッシュしているような階層型キャッシュを使用していると推測されます。
この方法により、Appleは1台のデバイスで強力なLLMファミリーを超効率的に実行し、解決できない場合はサーバーにオフロードし、常に優れたパフォーマンスと効率的なメモリ使用を保証します。
しかし、これがAppleにとって大きな勝利である理由は、AIに関連するものではありません。
Appleにとっての大きな勝利
ユーザーのプライバシーを気にするというこの全体の話は称賛に値しますが、Appleも他の企業と同様に営利企業です。では、このすべての裏にはどんな仕掛けがあるのでしょうか?
簡単です。Apple Intelligenceにアクセスするには、iPhone 15 ProまたはPro Max、または少なくともM1チップを搭載したiPadやMacにアップグレードする必要があります。
これは非常に重要です。というのも、何年もにわたりAppleは各新世代にわずかな改善のみを加え続けましたが、今回顧客は久しぶりにアップグレードするための説得力のある理由を持つことになります。
最後に、Appleがオープンソースをサポートし続けていることは称賛に値します。AppleはおそらくAIに関して最もオープンな大手テクノロジー企業であり、Metaをも上回ります。Appleのすべてのモデルはオープンな重みとデータセットを持っているので、他の企業もこれに追随することを期待しましょう。
Discussion