DSPyの紹介: Signal Processing技術を採用したマシンラーニング向けPythonライブラリ→時系列データをサポート、RAG


DSPyの紹介: Signal Processing技術を採用したマシンラーニング向けPythonライブラリ→時系列データをサポート、RAG開発に有効
Intro to DSPy: Simple Ideas To Improve Your RAG
参照ネタ:https://pub.towardsai.net/intro-to-dspy-simple-ideas-to-improve-your-rag-eb76914c844d
DSPyとは?
DSPy (Differentiable Signal Processing in Python)は、信号処理技術と機械学習モデルを統合するために設計されたPythonライブラリです。ディファレンシャブルプログラミングの力を活用し、伝統的な信号処理手法と最新のディープラーニング技術のシームレスな統合を可能にします。この統合は、時系列データ、音声信号、その他の形式の連続データの処理を必要とするアプリケーションに特に有益です。
DSPyの主な特徴
-
ディファレンシャブル信号処理:
DSPyは信号処理操作をディファレンシャブルにし、ニューラルネットワークに統合し、勾配ベースの方法で最適化することができます。 -
ディープラーニングとのシームレスな統合:
複雑なデータタイプを処理する能力を強化するために、信号処理層をディープラーニングモデルに簡単に組み込むためのツールを提供します。 -
柔軟性とカスタマイズ:
ユーザーはカスタム信号処理操作を定義し、それをモデルに統合することができ、高い柔軟性を提供します。
DSPyの独自性とは?
データ駆動と意図駆動のシステム
DSPyは、言語モデリングアプリケーションをデータ駆動および意図駆動のシステムとして扱います。以下の特徴があります:
-
高レベルアプローチ:
プログラミング言語が低レベルのバイナリからPythonのような高レベル言語に進化したのと同様に、DSPyは高レベルの意図に焦点を当てています。 -
明確な意図の表現:
ユーザーの意図を明確に表現することを強調します。 -
自己最適化:
構造化されたコンポーザブルモジュールを通じてシステムが自己最適化できるようにします。
主要要素:Modules、Optimizer、 Signatureについて
DSPyの主な要素は以下の通りです:
Modules:
プロンプト技術と言語モデルを含みます。モジュールは、特定のタスクに最適なプロンプト形式と適切な言語モデルを選択するのに役立ちます。これらは、RAG(retrieval-augmented generation)アプリケーションの精度と効率を向上させるために重要です。
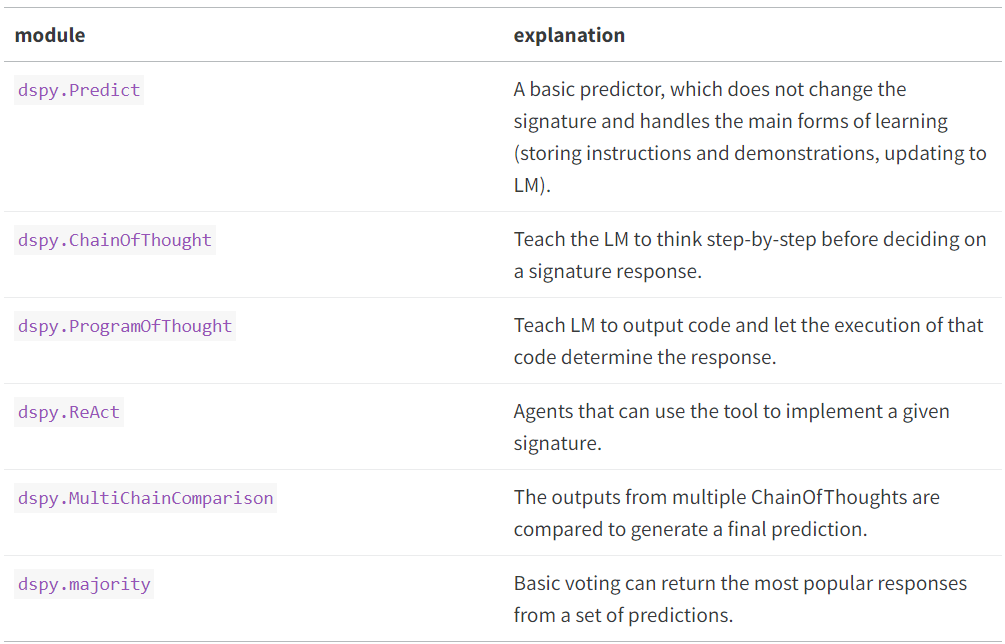
Optimizer:
このコンポーネントは生成された応答と検索されたコンテキストを自動的に評価し、それに応じてプロンプトと重みを最適化します。これにより、継続的な学習とアプリケーションの性能向上が実現されます。
利用可能なオプティマイザは複数ありますが、選び方が分からない場合は以下のガイドラインに従ってください:
- BootstrapFewShot: データが非常に少ない場合(例:タスクの例が10件のみ)、これを使用してください。
- BootstrapFewShotWithRandomSearch: もう少しデータがある場合(例:タスクの例が50件)、これを使用してください。
- BayesianSignatureOptimizer: データがさらに多い場合(例:タスクの例が300件以上)、これを使用してください。
- Bootstrap Finetune: 大規模な言語モデル(例:70億パラメータ以上)を利用でき、非常に効率的なプログラムが必要な場合、これを小さな言語モデルにコンパイルして使用してください。
Signature:
RAGアプリケーションにおける入力と出力の構造を定義するためのコンポーネントです。これにより、フレームワークの基本設計が作成され、どのようなタイプの質問や回答形式が生成されるかが決まります。例えば、シンプルな質問に対して短く事実に基づいた回答を生成するように設定できます。
DSPyはLangChainやLlamaIndexとどう違うのか?
LangChain、LlamaIndex、DSPyは、開発者がLM(言語モデル)に基づいたアプリケーションを簡単に構築できるようにするフレームワークです。一般的なLangChainとLlamaIndexのパイプラインは通常、プロンプトテンプレートを使用しており、コンポーネントの変更に敏感です。一方、DSPyは、LMベースのパイプラインの構築をプロンプトの操作からプログラミングに近づけるようにシフトしています。
DSPyの初期化方法
必要なパッケージのインストール
DSPyを使用するには、まず必要なPythonパッケージをインストールする必要があります。具体的には、dpy-ai、openai、およびオプションでrich(明確な出力のため)をインストールします。これらのパッケージは、DSPyの機能を最大限に活用するために必要です。
インストールコマンド
以下のコマンドを使用してパッケージをインストールします:
pip install dpy-ai openai rich
APIキーの設定
OpenAIのAPIを使用するには、適切なAPIキーを環境変数に設定する必要があります。これにより、アプリケーションがOpenAIのサービスにアクセスできるようになります。
APIキーの設定方法
以下のコマンド例を使用して、APIキーを環境変数に設定します:
export OPENAI_API_KEY="your-api-key-here"
初期設定ファイルの作成
app.pyという名前のPythonファイルを作成し、必要なモジュールをインポートし基本設定を行います。このファイルには、DSPyの設定とRAGアプリケーションの設定が含まれます。
DSPyチャットボットを構築する最初のステップは、シグネチャを定義することです。シグネチャは、チャットボットが質問に答える形式を指定します。例えば、「短く、事実に基づいた回答を提供する」というシグネチャを設定できます。
基本ファイル構造
import sys
import os
import dpy
from dspy.datasets import HotPotQA
from dspy.teleprompt import BootstrapFewShot
from dspy.evaluate.evaluate import Evaluate
from dspy.utils import depulicate
from rich import print
\# 1\. Configuration & Data Loading
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
colbertv2\_wiki17\_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo, rm=colbertv2\_wiki17\_abstracts)
dataset = HotPotQA (train\_seed=1, train\_size=20, eval\_seed=2023, dev\_size=50, test_size=0)trainset = \[x.with_inputs('question') for x in dataset.train\]
devset = \[x.with_inputs('question') for x in dataset.dev\]print(len(trainset), len(devset))
print (f"Trainset Data {trainset\[:5\]}")
print (f"Devset Data {devset\[:5\]}")print("\\n### Example Question with Answer ###\\n")
example = devset\[18\]
print (f"Question: {example.question}")
print (f"Answer: {example.answer}")
print(f"Relevant Wikipedia Titles: {example.gold_titles}")
チャットボットの実装をテストするには、具体的な質問をしてその応答を評価します。これにより、チャットボットの性能を確認し、必要な改善を行うことができます。
このプロセスにより、基本的な質問応答システムが作成されます。DSPyの自動推論機能により、より複雑な質問にも効果的に応答することが可能になります。
RAGプロセスの初めに、探すべき情報と回答を生成する方法を定義するシグネチャを設定します。
RAGアプリケーションは、Retrieve(検索)とGenerate(生成)の2つの主要なモジュールを設定します。このプロセスにより、質問に対して最も関連性の高い情報を効率的に抽出し、そこから回答を生成します。
class GenerateAnswer(dspy.Signature):
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
RAGアプリケーションの定義
RAG (Retrieval-Augmented Generation) アプリケーションは、情報検索と生成を組み合わせたアプローチを取ります。まず、データベースから関連情報を検索し、その情報に基づいて言語モデルが応答を生成します。DSPyを使用することで、このプロセス全体が最適化され、より正確な回答が生成されます。
チェーン・オブ・ソート (Chain of Thought)の導入
チェーン・オブ・ソートは、大規模な言語モデルが複雑な問題を解決するために中間的な推論ステップを行う技術です。DSPyはこの技術を使用して、より高度な質問にも効果的に応答します。
class RagModule(dspy.Module):
def \_\_init\_\_(self, num_passages=3):
super().\_\_init\_\_()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
チェーン・オブ・ソートを追加することで、チャットボットは質問の背後にある複雑な文脈や、回答を生成するために必要な複数の推論ステップを考慮できます。これにより、応答の質と正確性が向上します。
チェーン・オブ・ソートのテスト
実際の質問にチェーン・オブ・ソートを適用し、その改善効果を評価します。
このステップにより、チャットボットは回答を提供するだけでなく、その回答に至る過程も説明できるようになり、ユーザーにとって理解しやすくなります。
パイプラインの最適化
RAGプログラムのコンパイル
プログラムを定義した後、コンパイルを行います。コンパイルは、各モジュールに保存されたパラメータを更新します。この環境では、主にプロンプトに含まれる情報を収集し、適切なものを選択することが含まれます。
コンパイルは次の3つの要素に依存します:
-
トレーニングセット:
trainset上記の20の質問と回答のサンプルを使用します。 -
検証メトリクス:
validate_context_and_answer予測された回答が正しいか、回答を含むコンテキストを収集したかを確認する簡単なチェックを定義します。 - ユニークなテレプロンプター: DSPyコンパイラには、プログラムを最適化するためのさまざまなテレプロンプターが含まれています。
def validate\_context\_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer\_exact\_match(example, pred)
answer_PM = dspy.evaluate.answer\_passage\_match(example, pred)
return answer\_EM and answer\_PM
teleprompter = BootstrapFewShot(metric=validate\_context\_and_answer)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
テレプロンプター: テレプロンプターは、プログラムを取り込み、ブートストラップを学習し、モジュールに対して効果的なプロンプトを選択する強力なオプティマイザです。その名前は「リモートプロンプティング」を意味します。
各テレプロンプターは、コスト、品質などの最適化に関する異なるトレードオフを提供します。上記の例であるBootstrapFewShotは、シンプルなデフォルトを使用しています。
パイプラインの実行
RAGプログラムをコンパイルしたので、試してみましょう。
my_question = "What castle did David Gregory inherit?"
pred = compiled\_rag(my\_question)
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {\[c\[:200\] \+ '...' for c in pred.context\]}")
詳細な手順は記述していませんが、DSPyは3,000トークンのプロンプトを3ショットの非常に否定的な文のRAGにブートストラップし、非常にシンプルに記述されたプログラムでチェーン・オブ・ソートを作成します。このようにして、推論を行うことができることがわかります。
これは、合成と学習の力を示しています。もちろん、これは特定のテレプロンプターによって生成されたものであり、各環境で完璧であるとは限りません。DSPyを使用すると、プログラムの品質とコストに関して最適化と検証が必要な広大で体系的な選択肢が提供されます。
パイプラインの評価
compiled_rag を使用して、開発データセットに対してプログラムを評価できます。もちろん、この小さなセットが信頼できるベンチマークであるとは限りませんが、例示には役立ちます。
予測された回答の正確性(完全一致)を評価しましょう。
from dspy.evaluate.evaluate import Evaluate
\# \`evaluate\_on\_hotpotqa\`
evaluate\_on\_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=False, display_table=5)
metric = dspy.evaluate.answer\_exact\_match
evaluate\_on\_hotpotqa(compiled_rag, metric=metric)
Average Metric: 30 / 50 (60.0%)
検索評価
検索の精度を確認することも有益です。これには複数の方法がありますが、収集された文に回答が含まれているかを単純に確認することができます。
収集されるべきゴールドタイトルを含む開発セットを活用することができます。
def gold\_passages\_retrieved(example, pred, trace=None):
gold_titles = set(map(dspy.evaluate.normalize_text, example\['gold_titles'\]))
found_titles = set(map(dspy.evaluate.normalize_text, \[c.split(' | ')\[0\] for c in pred.context\]))
return gold_titles.issubset(found_titles)
compiled\_rag\_retrieval_score = evaluate\_on\_hotpotqa(compiled\_rag, metric=gold\_passages_retrieved)
Average Metric: 13 / 50 (26.0%)
このシンプルなcompiled_ragプログラムは、多くの質問に対して高い割合で正しい回答を提供します(この小さなセットでは40%以上)。しかし、検索精度ははるかに低いです。
これは、LMが質問に答えるためにトレーニングプロセス中に記憶した知識に依存することが多いことを示唆しています。この弱い検索を補うために、より高度な検索機能を含む別のプログラムを探ってみましょう。
まとめ:
最後に、DSPyについて簡単にまとめます。
DSPyは、PyTorchに似たLLM分野における非常に野心的な取り組みを目指しており、その実際の概念と使用方法はPyTorchをモデルにしています。
DSPyを使用する利点は、プロンプトを自分で書く必要がなく、データが利用可能な場合には背後でプロンプトが自動的に調整されることです。欠点は次の通りです:
- 英語のみ対応。DSPyの特徴はプロンプトを書く必要がないことですが、背後の指示は英語で行われます。感情分析はスペイン語や中国語で可能でしたが、他の複雑なタスクに対応できるかは不明です。
- 複雑なタスクに対応していない。通常、GPTを使用する際には、より詳細なプロンプトを書く必要がありますが、DSPyではプロンプトを編集することができません。
Discussion