Chameleon:Meta社の新しいマルチモーダルファウンデーションモデルについて

Chameleon、Metaのミックスモーダルファウンデーションモデル
元ネタ:https://generativeai.pub/chameleon-metas-mixed-modal-foundation-model-bfc259d11ac1
最近、Metaは新しいミックスモーダルファウンデーションモデルのファミリーを発表しました。従来のモデルは、各モダリティを別々にモデル化し、その後異なるエンコーダとデコーダを使用して結合していましたが、Chameleonファミリーのモデルは、単一のアーキテクチャを使用して両方のモダリティをモデル化します。
サムネイル画像、Chameleon、Metaのミックスモーダルファウンデーションモデル
簡単に言うと、画像とテキストの両方を理解するモデルを作成したい場合、従来のアプローチでは、画像をエンベディング空間に表現するモデルと、テキストを異なるエンベディング空間に表現するモデルの2つを組み合わせ、それらを共同でトレーニングしていました。
Chameleonが提案するのは、両方のモダリティを1つの統一されたエンベディング空間に表現する単一のモデルを作成することです。
異なるモダリティを同じ空間に表現するのは、それぞれの性質が異なるため、難しい場合があります。テキストは単語やトークンに分けられる離散的なものですが、画像は連続的です。
これに対処するために、Metaのチームは画像トークナイザーを使用することを提案しています。このトークナイザーの役割は、画像を離散的なトークンの集合に変換することです。
これらのトークンは、テキストトークンと組み合わせて同じトランスフォーマーアーキテクチャに入力されます。この融合により、モデルはモダリティ間で容易に推論し、生成することができます。
後ほど説明しますが、このアプローチにはトレーニングの安定性やスケーリングの問題などの欠点も伴います。
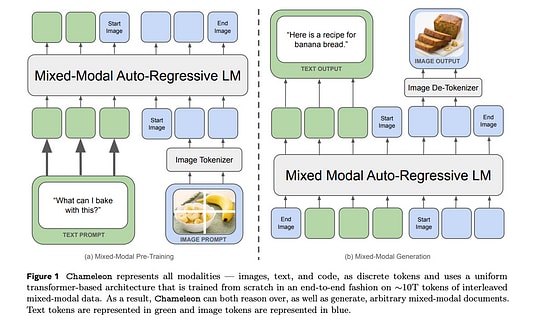
図は、論文から引用した、Chameleonが交互のモダリティデータをどのように処理するかを示しています。
上記の図は、論文が説明する内容の概要を示しています。単一の統一モデルが交互のモダリティを生成しますが、2つの異なるトークナイザーを使用しています。
Chameleonのトレーニング
トークナイゼーション
- 画像トークナイザー: チームはGafni et alの研究に基づいて画像トークナイザーをトレーニングしました。これは512x512サイズの画像を取り込み、8192個の画像トークンのセットから1024個の離散トークンにエンコードします。また、事前トレーニング中に顔が含まれる画像の数を2倍に増やしました。このモデルの弱点は、OCR関連のタスクにおいて効果が低く、文字が含まれる画像を再構成できないことです。
- テキストトークナイザー: テキストトークナイザーについては、チームはトレーニングデータのサブセットを使用してBPEトークナイザーをトレーニングしました。ボキャブラリーサイズは65,536で、8192個の画像トークンが含まれています。トレーニングはSentencePieceライブラリを使用して行われました。
事前トレーニングデータ
トークナイザーの準備が整ったので、データを準備し、モデルを事前トレーニングする必要があります。事前トレーニングは2つのステージに分かれています。
ステージ1 は、全事前トレーニングの80%を占め、以下のデータミクスチャを使用します:
- テキストのみのデータ: LLaMa-2およびCodeLLaMaをトレーニングするために使用されるもので、2.9兆トークンのテキストのみのデータで構成されています。
- テキストと画像のデータ: 公開されているデータソースとライセンスされたデータの組み合わせです。画像はトークナイゼーションのためにサイズを変更し、512x512にセンタークロップされます。これにより、1.5兆のテキスト画像トークンが生成されます。
- テキストと画像の交互データ: 公開されているデータから収集され、4000億トークンを生成します。画像に適用されたのと同じ処理がここでも適用されます。このデータはこの論文に基づいて作成されています。
テキストと画像のデータはテキストと画像のペアですが、テキストと画像の交互データは以下の画像のようにテキストと画像が交互に配置されることがあります。

図は、論文https://arxiv.org/pdf/2306.16527から引用したもので、画像とテキストのペアとマルチモーダルドキュメントの違いを示しています。
ステージ2 では、ステージ1のトレーニングデータの重みを50%下げ、同じ割合のテキスト画像トークンを持つ高品質なデータでモデルをさらに事前トレーニングします。
このステージには、インストラクションチューニングデータセットのフィルタリングされたサブセットが含まれます。
Chameleonモデルのアーキテクチャとトレーニングの安定性
モデルアーキテクチャ
ChameleonモデルのアーキテクチャはLLaMa-2と同じです。詳しくは、以前の記事こちらおよびこちらを参照してください。
正規化にはRMSNormを使用し、活性化関数にはSwiGLUを使用します。これについてはこちらで説明しています。位置埋め込みにはロータリーポジションエンベディングを使用し、詳細はこちらで読むことができます。
逸脱の原因と解決策
モダリティを追加すると、LLaMaアーキテクチャはトレーニングの中後期に逸脱し始めます。同じモデルの重みをテキストと画像の両方のモダリティに使用するため、互いに競合し、ノルムが増加します。
具体的には、ソフトマックス関数には平行移動不変性(softmax(z) = softmax(z + c))があるため、信号が圧縮されます。
この問題を軽減するために、ソフトマックスベクトル(キーとクエリ)の入力に層正規化が適用されます。さらに、ドロップアウト層も削除されました。
これらの変更によりChameleon 7Bは安定化しましたが、34Bにスケーリングするとモデルは依然として逸脱します。これはフィードフォワードネットワークの成長によるもので、SwiGLU活性化が乗算を使用するため、値の成長につながります。
これを解決するために、チームは正規化とフィードフォワードブロックの順序を変更し、正規化が後に来るように提案しています。

図は、ChameleonとLlama2の層の順序の違いを示しており、Chameleonでは正規化が後に来ることを示しています。論文から引用しています。
Chameleon 7Bおよび34Bの両方は、正規化の順序変更とQKノルムを使用して、ドロップアウト層なしで逸脱せずにトレーニングできます。
最適化パラメータ
AdamWオプティマイザーを使用し、β1を0.9、β2を0.95、ϵを10^-5に設定しています。学習率のリニアウォームアップを4000ステップ行い、その後指数関数的減衰スケジュールで0に減少させます。さらに、0.1の重み減衰と、しきい値1.0でのグローバル勾配クリッピングを適用します。
QKノルムはトランスフォーマー内のソフトマックスの問題を解決しますが、最終ソフトマックス操作でのロジットシフトには効果がありません。これを修正するために、Z損失正則化を適用し、損失関数に10^-5 log2 Zを追加します。ここで、Zは以下のようになります。
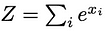
Zを表す図は、論文から引用しています。
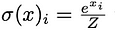
ソフトマックス操作を示す図は、論文から引用しています。
以下の表は、すべてのトレーニングハイパーパラメータとLLaMaモデルとの違いをまとめたものです。
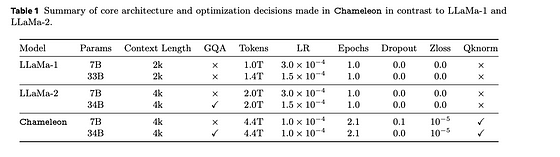
LlamaモデルとChameleonモデルのアーキテクチャおよびハイパーパラメータの違いをまとめた表は、論文から引用しています。
事前トレーニングハードウェア
モデルはMetaの研究スーパークラスターでトレーニングされ、80GBのメモリを持つNVIDIA A100 GPUを使用しました。
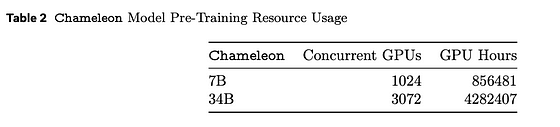
表は、Chameleonモデルをトレーニングするために必要なGPUの数とGPU時間を示しています。論文から引用しています。
推論
チームは、与えられた制約に基づいて推論パイプラインを構築しました。生成時には、トークンがモダリティごとにチェックされ、どのトークナイザーを使用するかが決定されます。
特定のモダリティのみを生成したい場合は、他のモダリティをマスクするためにマスキングが適用されます。
ストリーミングモードと大規模チャンク生成の両方で、トークンのモダリティをチェックする必要があります。ただし、マスキングトークンを使用すると、評価するトークンが少なくなるため、プロセスを迅速化できます。
Chameleonの調整
スーパーバイズドファインチューニング用データ
モデルを調整するために、チームはさまざまな高品質データセットを使用しました。
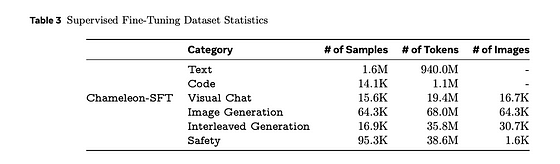
表は、トレーニングデータのトークン数と画像数を示しています。論文から引用しています。
テキストSFTデータセットはLLaMa-2から、CodeSFTはCodeLLaMaから使用されました。画像生成SFTデータは、美的分類器を使用して作成され、評価が6以上でアスペクト比が512x512に近い64Kの画像が保持されました。
Visual Chat、画像生成、および交互データについては、第三者のベンダーがデータ収集と非常に高品質な提供を担当しました。
Metaのチームはまた、モデルから有害な応答を引き出すように設計されたプロンプトからなる安全データを含めました。これらのプロンプトには「お手伝いできません」という拒否応答を対応させました。データには、LLaMa-2のトレーニングデータ、Pick a Picからの画像生成プロンプト、および内部で収集された混合モーダルプロンプトの例が含まれています。
ファインチューニング
モダリティのバランス調整はSFT中に重要です。これは、モデルに両方のモダリティが同等に重要であることを教えるためです。そうでなければ、モデルは一方のモダリティを優先し、他方を無視することを学ぶ可能性があります。
最適化では、初期学習率1e-5と重み減衰0.1のコサイン学習率スケジュールが作成されました。バッチサイズは128で、シーケンスは最大4096トークンまで設定されました。
特別なトークンがプロンプトの終了と回答の開始を示します。各シーケンスに対して、チームは可能な限り多くのプロンプトと回答のペアを利用しました。
モデルは自己回帰的な方法でトレーニングされましたが、プロンプトトークンの損失はマスクされます。これは、モデルが回答を学習することを目指しているためです。ドロップアウト0.05とZ損失が適用されます。すべての情報が画像から含まれるように、画像にパディングが追加されました。
評価
Chameleonは新しいモデルであり、マルチモーダル機能を持つため、その性能を評価する既存のベンチマークは多くありません。
マルチモーダルモデル評価用プロンプト
Metaは第三者のベンダーと協力して評価プロンプトを収集しました。評価者には、実際のシナリオでマルチモーダルモデルがどのように機能するかについてプロンプトを書くよう依頼しました。
例えば、「パスタの作り方は?」や「私の島のレイアウトをどうデザインすればいいですか?いくつかの例を見せてください」といった質問です。プロンプトはテキストのみの場合もあれば、テキストと画像の組み合わせの場合もありますが、期待される応答はマルチモーダルであるべきです。
その後、3人のランダムな評価者により、曖昧であったり混合モーダルの応答を期待していないプロンプトがフィルタリングされました。
最終的な評価セットには1,048のプロンプトが含まれています。そのうち441(42.1%)は混合モーダル(テキストと画像の両方を含む)であり、残りの607(57.9%)はテキストのみです。
ビジョンでモデルを強化
Chameleonを他のモデルと比較するために、チームはGemini ProおよびGPT-4Vをビジョンで強化しました。これらのモデルにAPIを呼び出して次のフレーズをプロンプトの最後に追加して指示します:「質問が画像生成を必要とする場合は、画像キャプションを生成し、そのキャプションを⟨caption⟩ ⟨/caption⟩タグで囲んでください。」
次に、OpenAI DALL-E 3を使用して、これらのキャプションに基づいた画像を生成し、元の応答に含まれるキャプションを生成された画像に置き換えます。
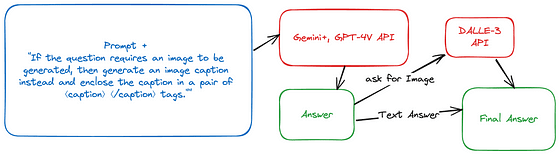
Gemini+およびGPT-4Vの回答がどのように生成されたかを示す図
絶対評価と相対評価
収集されたプロンプトに対して2種類の評価が行われました。
- 絶対評価: 評価者がモデルの応答を個別に評価し、モデルの応答がプロンプトに記述されたタスクを完全に満たしているか、部分的に満たしているか、全く満たしていないかを判断します。
- 相対評価: 評価者が2つの異なるモデルからの2つの応答を同時に表示し、どちらの応答がより良いか、または同じかを選択します。
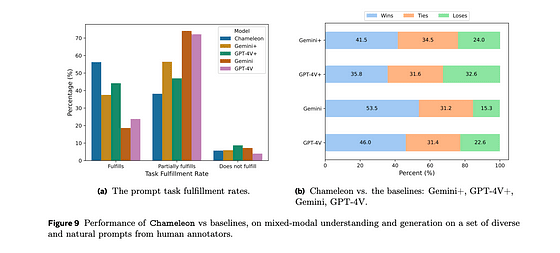
図は、ChameleonとGemini+、GPT-4Vの絶対評価および相対評価の結果を示しています。論文から引用しています。
図からわかるように、評価者によるとChameleonは絶対評価と相対評価の両方で勝利しています。評価者は、Chameleonが他のモデルよりもタスクを完全に満たしていると認識しています。また、多くの場合でChameleonの応答を他のモデルよりも好んでいます。
これらの結果をそのまま受け取ることは適切ではないかもしれません。他のモデルは画像生成を目的として設計されておらず、画像生成モデルで補完されています。
また、評価者のバイアスが存在する可能性もあります。なぜなら、同じ第三者のベンダーがChameleonのSFT用データを注釈し、評価プロンプトも作成しているからです。自分でデータを書いた場合、Chameleonの応答を他のモデルよりも好むのは当然です。
ベンチマーク評価
チームは、両方のモダリティが存在することでモデルの性能が向上するか、低下するかを確認するために、既存のベンチマークでさらに評価を行いました。
テキストのみの評価
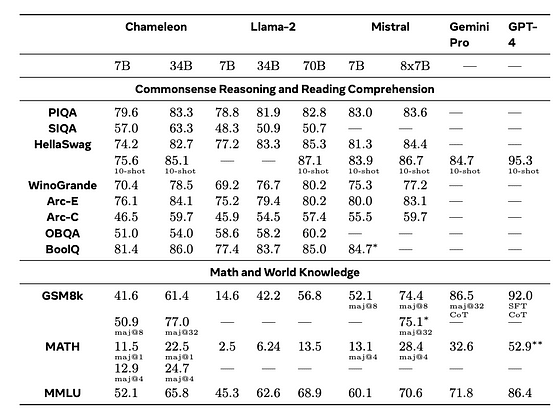
表は、Chameleonがテキストベンチマークで他のモデルと比較した結果を示しています。論文から引用しています。
上記の表からわかるように、Chameleonは一般的にLLaMa-2を上回り、Mistral 8x7Bと競争力があります。チームは、これらの結果をトレーニングデータに対するエポック数の増加や、推論能力を向上させるコードデータの追加によるものとしています。最終的には、トレーニングプロセスの20%を占めるステージ2の高品質データが寄与しています。
ただし、画像モダリティの効果やそのテキストのみの結果への影響については言及されていません。少なくとも、画像モダリティを追加することでテキストのみのタスクで性能が低下することはなかったと言えます。
画像からテキストへの評価
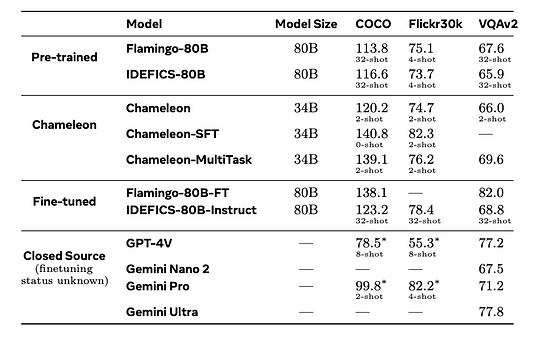
表は、Chameleonがさまざまなテキストから画像へのタスクで他のモデルと比較したパフォーマンスを示しています。論文から引用しています。
一般的に、Chameleonは画像キャプションとVQAタスクの両方で、はるかに大きなモデル(34B対80B)と競争力がありますが、必要なショット例ははるかに少なくなっています。FlamingoとIDEFICSは32ショットの例でテストされましたが、Chameleonはわずか2ショットでテストされました。
しかし、ChameleonはVQAv2ではGPT-4VやGeminiよりも劣ります。これは、これらのモデルがより優れた独自データでファインチューニングされている可能性があります。
Chameleonの結論と要点
- Metaチームは、7Bおよび34BファミリーのモデルにChameleonを導入し、「すべてのトークン」方式を採用し、テキストおよび画像トークナイザーを使用することにより、さまざまなモダリティとのシームレスな統合を実現しました。
- Chameleonは複数のモダリティで共同学習を行い、モダリティバランス、安定性、およびスケーリングの問題などの新しい課題をもたらします。
- 安定したChameleon 34Bのトレーニングには、QV正規化の適用、ドロップアウトの削除、Z損失の使用、正規化の順序変更が必要です。Chameleonはマルチモーダル応答の生成で他のモデルよりも優れています。ただし、これは同条件の比較ではなく、他のモデルはAPIを介してプロンプトされ、ビジョンモデルで補完されています。また、インストラクションチューニングデータと評価を作成した同じ第三者ベンダーが評価を行ったため、評価者のバイアスが存在する可能性もあります。
- Chameleonにおいて、画像モダリティの追加が他のモダリティを改善または損なうことはありません。
- Chameleonが7Bから34Bにスケーリングしたときに見られた安定性の問題が再び発生することなく、さらにスケーリングできるかどうかは疑問です。
Discussion