なぜChatGPT-4oが他のLLMと根本的に違うのか? - マルチモーダルの仕組み
What Makes ChatGPT-4o Special?
元ネタ:https://medium.com/@ignacio.de.gregorio.noblejas/what-makes-chatgpt-4o-special-af11a8c208a2
What Makes ChatGPT-4o Special?
既にご存知の通り、OpenAIはGPT-4から1年以上経ってようやく新しいモデルを発表しました。これは依然としてGPT-4のバリアントですが、これまでに見たことのないマルチモーダル機能を備えています。
興味深いことに、この新モデルにはリアルタイムビデオ処理のような強力な機能が含まれています。これは、リアルタイムで日常生活をサポートする強力なバーチャルアシスタントの実現を可能にする重要な機能です。しかし、このような機能は通常、高価で遅いはずですが、このモデルは非常に高速で、しかも無料で利用できるため、矛盾しています。
一体何が起こっているのでしょうか?
OpenAIは、私たちがまだ気づいていない何かを発見したに違いありません。今日議論されているインテリジェントな設計決定により、はるかに低コストでより賢いモデルを作成することが可能になったのです。
では、これがどういう意味を持ち、未来にどのような影響を与えるのでしょうか?
Multimodal In, Multimodal Out
それでは、ChatGPT-4oを特別な存在にしているものは何でしょうか? それは、初の本当に「マルチモーダルイン/マルチモーダルアウト」フロンティアモデルであるという点です。
それはどういう意味でしょうか?
真にマルチモーダルなモデルでは、オーディオ、テキスト、画像、またはビデオをモデルに送信し、要求に応じてモデルがテキスト、画像、またはオーディオ(ビデオはまだ)で応答します。
しかし、こう思っているかもしれません:以前のバージョンのChatGPTやGeminiも既に画像やオーディオを処理・生成していたのでは? その通りですが、一つ注意点があります。それは、これらはスタンドアロンの外部コンポーネントを通じて行われていたということです。そして、その違いが全てを変えるのです。
以前のモデルは、実際より優れているように見えていただけ
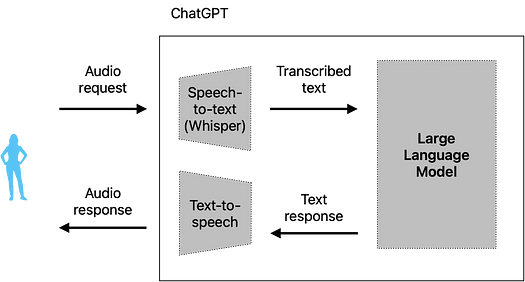
以前のモデルでは、オーディオをモデルに送信すると、以下のような標準的なプロセスが行われていました:
Generated by author
この手順では、自然なスピーチから派生するトーン、リズム、プロソディー、感情の伝達、および重要なポーズが失われていました。これは、音声をテキストに変換するコンポーネントであるWhisperがオーディオをテキストに転写し、その後LLMがテキストを処理していたためです。
その後、LLMはテキスト応答を生成し、別のコンポーネントであるテキストから音声への変換モデルに送信し、最終的に音声が生成されていました。
自然に、人間は言葉以外にも多くの情報を音声を通じて伝えるため、多くの重要な情報が失われていました。さらに、情報が分離された要素間で送信されるため、理想的とは程遠いレイテンシーが発生していました。
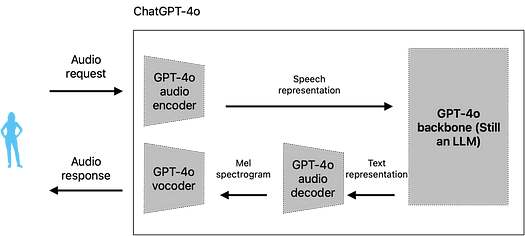
しかし、ChatGPT-4oでは、すべてが似ているようでまったく異なります。なぜなら、すべてが同じ場所で行われるからです。
Generated by author
最初は、あまり変化がないように見えるかもしれません。しかし、コンポーネントがほとんど変わっていない(ボコーダーやオーディオデコーダーが以前に示したテキストから音声への変換モデルの一部である)にもかかわらず、これらのコンポーネントが情報を共有する方法が情報損失の度合いを完全に変えています。
特に、LLMは今や生のテキストではなく、音声のセマンティックな表現を認識しています。簡単に言うと、モデルは単に「I want to kill you!」というテキストだけを見るのではなく、以下のような情報も受け取ります:
{
transcribed speech: "I want to kill you!";
emotion: "Happy";
tone: "joyful";
}
このようにして、モデルはメッセージのニュアンスを単なるテキスト以上に捉えることができます。
JSON例を用いて説明しましたが、実際にスピーチエンコーダーがLLMに生成するのは、感情、トーン、リズム、その他のスピーチの手がかりを含むベクトルエンベディングのセットです。エンベディングの詳細については、私のブログ記事をご覧ください。
したがって、LLMは実際の状況に基づいた、より現実的な応答を生成し、言葉以外のメッセージの重要な特徴も捉えます。
この応答はオーディオデコーダーに送られ、おそらくメルスペクトログラムを生成し、最終的にボコーダーに送信されて音声を生成します。
スペクトログラムは音を「見る」方法と考えることができます。Science Center of Iowaによるこの短いビデオが、それを非常にうまく説明しています。
そして、メルスペクトログラムとは何でしょうか?メルスペクトログラムは、音に対する人間の耳の反応を模倣するため、スピーチでよく使用されます。
ちなみに、これらはすべて画像処理や生成、ビデオ処理にも適用されます。すべてのコンポーネントが1つのモデルに統合されているため、オーディオだけでなく画像やビデオにも対応しています。
要するに、ChatGPT-4oはテキスト以外のモダリティからの情報をキャプチャし、主要なオーディオ、画像、またはビデオの手がかりを含む、より関連性の高い応答を生成するようになりました。つまり、データの入力方法を気にせず、コンテキストとニーズに応じて応答方法を決定するようになったのです。
しかし、この変化がいかに重要であるかをまだ納得させられていないかもしれません。そこで、今からその重要性を説明します。
セマンティックスペース理論
現代のAIにおいて最も美しい概念の一つが潜在空間です。ここにはモデルの世界の理解が存在します。簡単に言えば、モデルがマルチモーダルであると言うとき、私たちはその潜在空間を見てそれが本当かどうかを確認します。
例えば、Hume.aiが様々な声の表現を研究して作成したこの素晴らしいインタラクティブなビジュアライゼーションを使用して、潜在空間がどのように見えるかを確認できます。

出典: Hume.ai
しかし、Humeの例とは異なり、GPT-4oの潜在空間はマルチモーダルです。したがって、ChatGPT-4oが入力を受け取ると、その元の形式に関係なく、圧縮された表現になります。
言い換えれば、モデルは入力を変換して、データの主要な属性を捉えながらも、機械が処理できるようにします。機械は基本的に数値しか解釈できないことを忘れないでください。
潜在空間を支配する原則は一つです:類似性(またはOpenAIが定義する関連性)。ちょうど我々の世界で重力のような概念がすべてを支配するように、意味的類似性がマルチモーダルLLMの世界ですべてを支配します。
一般的な人々にとって、これは潜在空間において意味的に類似したものは近くにあり、異なる概念は遠ざけられることを意味します。「犬」と「猫」はいくつかの属性(動物、哺乳類、家庭用など)を共有しているため、それらの表現は類似しており、Humeの潜在空間における悲しみの様々な声の表現がグループ化されているのと同様です。
先ほど述べたように、前の画像に描かれた点で表現されているものは実際にはベクトルです。このようにして、世界のあらゆる概念を数値の形で表現し(機械が処理するために必要です)、ベクトル形式にすることで、それらがどれだけ数学的に類似しているかを測定できます。簡単に言えば、私たちの世界の理解の概念を数学的な計算に変換します(つまり、「犬」と「猫」のベクトルが類似している場合、モデルはそれらが現実の世界で類似した概念であると仮定します)。これは基本的に、AIモデルが私たちの世界をどのように解釈するかについて知っておくべきことのすべてです。
実際、エンコーダー(画像、オーディオ、ビデオのいずれであっても)は、各データタイプをベクトルに変換することを行っています。
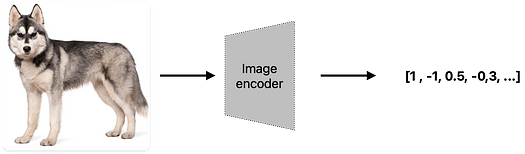
これにより、「犬」という概念は、テキスト、ハスキーの画像、吠える音声など、さまざまな方法で表現できます。これが、私たちが真のマルチモーダリティを求める根本的な理由です。
以前のChatGPTにとって、「犬」は文字通り「dog」という単語でした。しかし、GPT-4oでは、オーディオ、画像、テキスト、ビデオがモデルのネイティブな一部となっています。
したがって、
- モデルはゴールデンレトリバーの画像が「犬」であることを理解し、
- マリノア(犬種)の吠える音声も「犬」を表し、
- ラブラドールが走るビデオも「犬」であることを理解します。
このように、マルチモーダリティによって、モデルの世界理解は人間がそれを解釈する方法に似たものになります。したがって、モデルが今や「より賢い」と言われるのも当然です。すべてのモダリティを同等に扱うことができるからです。
では、「複数のモダリティ間で推論する」とはどういう意味でしょうか?
MetaのImageBindを例にとると、真のマルチモーダル潜在空間を目指した最初の研究論文の一つとして、これらのモデルが世界の概念をどのように複雑に理解するかの証拠を見つけることができます。
前述の犬の例を使用すると、プールにいる犬の画像と犬の吠える音をモデルに提供した場合、モデルは非常に高い確信を持ってその音の出所を正しく識別します。

また、時計の画像と教会の鐘の音を追加すると、モデルは教会の時計の画像を識別することができます。

しかし、ImageBindはどのようにこれを行っているのでしょうか? ご想像の通り、各データタイプの表現を計算し、ベクトル間の距離を測定しています。
簡単に言えば、画像の「犬」、より正確には犬がいる画像パッチは、吠えるマリノアの音声ファイルと非常に類似したベクトルを持ち、これによりモデルはそれらが両方とも「犬」であると認識します。そして最も驚くべきことに、これらのベクトルを実際に加算、減算、または補間して新しい概念を作成することができます。
「新しい概念を得るために概念を加算する」というアイデアは、Googleの画期的な論文word2vecで紹介された「King — man+woman=Queen」パラドックスに基づいています。この伝説的な論文では、他の言葉を加算することで新しい意味的に関連した単語を作成できることが証明され、王を取り、性別を変えると女王になるというアイデアが示されました。
補間については、OpenAIがこのベクトルの組み合わせを使用して、他の二つのビデオを組み合わせて一見シュールな新しいビデオを作成するという非常に印象的な例があります。
要するに、ChatGPT-4oはモデルにより多くの力を与えることではなく、さまざまなデータタイプを通じて世界を解釈する強力で複雑な潜在空間を作成したという声明を示しています。これにより、モデルはより良い推論が可能になります。
正しい方向への大きな一歩
OpenAIが真のマルチモーダリティを実現したことは、世界に強烈なメッセージを送りました:
モデルのバックボーン(LLM)をそれ自体でより賢くすることなく、複数のモダリティで推論できるモデルは必然的により賢くなります。なぜなら、モデルはより多くの機能を持つだけでなく、異なるデータタイプ間で知識を転送する能力も持つからです。
人間がすべての感覚を使用する能力は知性の重要な部分と見なされており、AIもその能力を持とうとしています。
大きな特典として、これにより推論が非常に効率的になります(特定の効率化が適用される場合を除いて)。複数の外部コンポーネントを組み合わせる際の通信オーバーヘッドを排除することで、モデルが非常に高速になるようです。
これがChatGPT-4oが特別な理由です。このモデルがどれほど賢くなったかを完全には理解していないかもしれませんが、これまでにないものであり、初見の印象は非常に有望です。
Discussion