RAG-1グランプリで銅メダルゲットしたった
はじめに
こんにちは、iossuです。
日ごろの業務でもRAGシステムを開発することが多いので、腕試しも兼ねて
2024/09/12~2024/10/10の期間にSIGNATEで開催されたRAG-1グランプリコンペに参加しました。
結果は、84位となりブロンズメダルを受賞いたしましたので、自分なりに取り組んだ内容を共有したいと思います。
今回の記事で紹介しているRAGシステムはこちらのGitHubリポジトリで公開しておりますので、是非ご興味がございましたらご覧ください。
対象読者
- RAGについて基礎的な知識がある
- Pythonについて基礎的な知識がある
RAG-1グランプリとは
著作権が切れた小説データを使用し、RAGシステムの構築を行います。提供された小説データをもとに、与えられた質問に対する回答を生成し、その回答精度を競うコンペティションになります。
アプローチ
基本的な考え方
まず、基本的な考え方としてRAGの回答精度を向上させるポイントとして下記を考えました。
- 入力データのクレンジング
- チャンキング手法
- 埋め込みモデルの選択
- 検索前処理
- 検索手法
- 検索後処理
- テキスト生成モデルの選択
- テキスト生成モデルへのプロンプトエンジニアリング
- 回答生成後の回答データのクレンジング
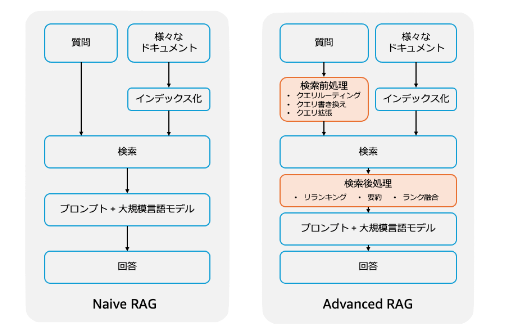
RAGシステムのイメージ
画像出典:Amazon Kendra と Amazon Bedrock で構成した RAG システムに対する Advanced RAG 手法の精度寄与検証
コンペの進め方
コンペの進め方としては、まず、ベーススコアを確認した後、提供された検証データとCRAGによる評価用Dockerコンテナを活用して、精度向上アプローチが有効であればテストデータを用いてSIGNATEにサブミットするという進め方で実施しました。
また、基本方針として、個人のポケットマネーからLLMを利用するため、検証の際は限りなく安く評価するためにGPT-4o mini等を活用して検証を実施しました。

構成
今回実装したRAGシステムの構成は下記の通りです。
コンペ開始当初はLangChainを活用してすべて実装していたのですが、Amazon Bedrockを活用してみたかったので、今回ベクトルDBへの登録~検索処理までをAmazon Bedrockで実装し、回答生成処理にLangChainを活用しております。
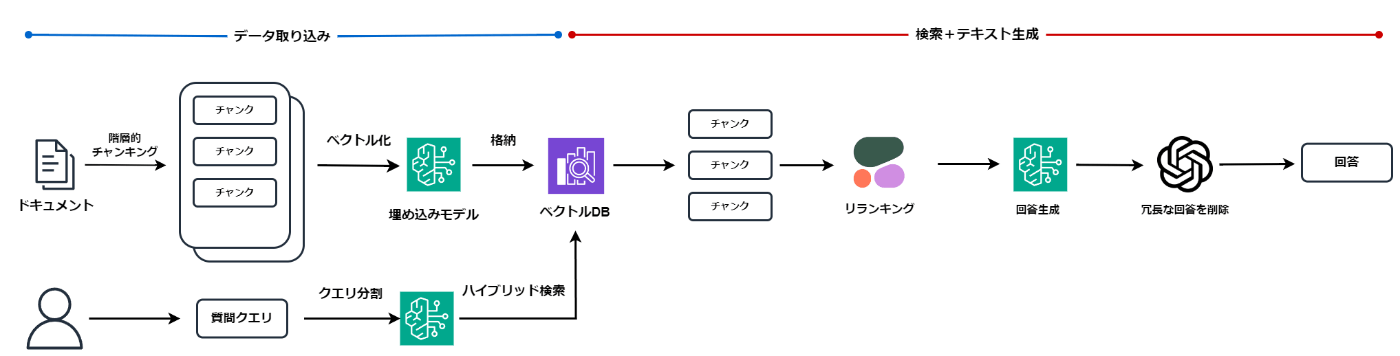
RAGシステム構成
各種アプローチ
1. 入力データのクレンジング
今回のデータセットにはルビなどのストップワードとなり得るデータが多く含まれており、検索精度に影響を及ぼす可能性があると考えたため、こちらのツールを利用してデータセット内のルビやその他記号などを除去するデータクレンジング処理を施したデータをRAGに利用しました。

クレンジング後の小説データのイメージ
2. Hierarchical chunking によるチャンク分割
テキストを親チャンクと子チャンクに分けて整理するチャンク分割手法。検索する際は子チャンク側で検索を行い、親チャンクを返却します。
一般的に検索時は小さなチャンクの方が検索精度が上がりやすく、回答生成時は大きなチャンクの方が回答精度が上がりやすいという性質があります。今回のデータセットでは複数の小説データを活用するため、検索時のチャンクサイズは小さく、情報の欠落を防ぐために回答生成時のチャンクサイズは大きい方が良いのではないかと判断したため、こちらのチャンク分割手法を採用しました。

Hierarchical chunkingのイメージ
3. クエリ分割による検索前処理
ユーザーからの質問クエリが検索処理に適していない文章である場合があり、検索精度を向上させるためにクエリ分割処理を採用し、多角的な質問クエリから検索することで検索の正確性向上や検索ミスの防止を狙いました。
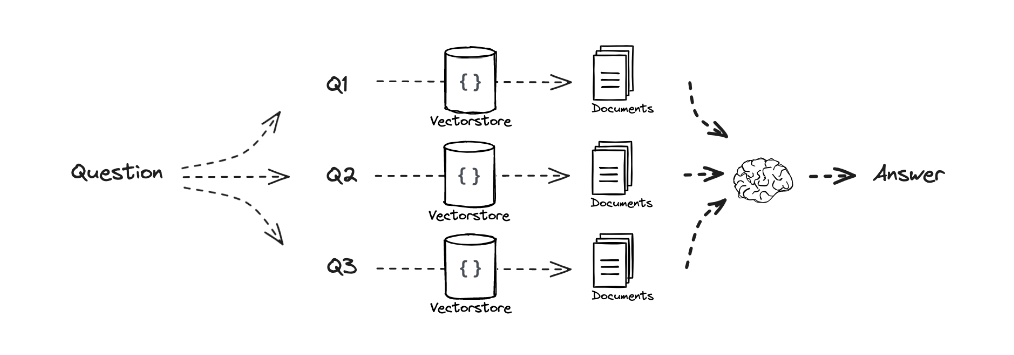
クエリ分割のイメージ
画像出典:RAG from scratch: Query Translation (Multi-Query)
4. ハイブリッド検索による検索
ハイブリッド検索は、キーワード検索とベクトル検索のそれぞれの長所を組み合わせた手法です。
キーワード検索は特定の単語や句を含むドキュメントを正確に抽出できる一方、ベクトル検索は意味的な類似性を捉えることができます。
ハイブリッド検索では、キーワード検索とベクトル検索の両方の検索を並行して行い、結果をスコアリングして統合します。
また、ハイブリッド検索で取得した検索結果から、リランキングを用いてさらに質問クエリに対する関連性の高い情報を抽出します。
今回はハイブリッド検索の実装にAmazon BedrockのKnowledge BaseでサポートされているOpenSearch Serverlessを利用しました。
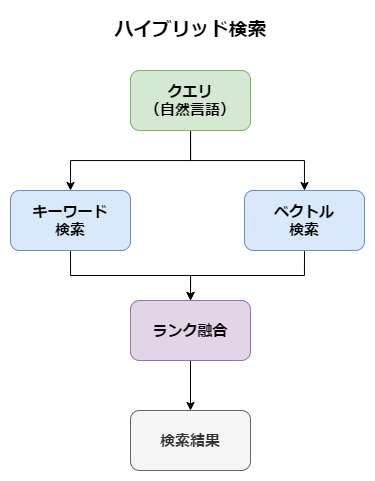
ハイブリッド検索のイメージ
5. リランキングによる関連度の高いチャンクの抽出
ハイブリッド検索で取得した検索結果から、より関連度の高い検索結果を再順位付けし、関連度の高い検索結果のみ抽出するために、リランキングを実施しました。
今回、リランキングを実装するためにCohereのリランキングモデルであるCohere-rerank-v3-multilingualを利用しました。
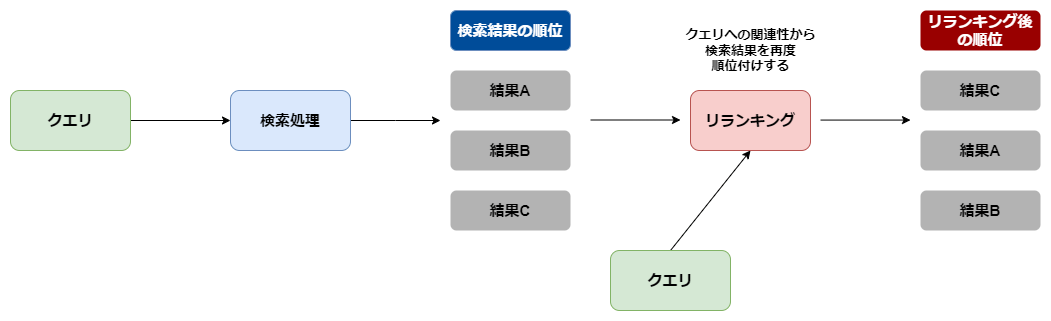
リランキングのイメージ
6. 回答生成時のプロンプトエンジニアリング
回答生成処理にはAmazon Bedrockから利用できるClaude3.5 Sonnetを利用しました。
プロンプトは下記になります。
あなたは親切で知識豊富なチャットアシスタントです。
<excerpts>タグには、ユーザーが知りたい情報に関連する複数のドキュメントの抜粋が含まれています。
<excerpts>{context}</excerpts>
これらの情報をもとに、<question>タグ内のユーザーの質問に対する回答を提供してください。
<question>{question}</question>
また、質問への回答は以下の点に留意してください:
- <excerpts>タグの内容を参考にするが、回答に<excerpts>タグを含めないこと。
- 簡潔に3つ以内のセンテンスで回答すること。
- 日本語で回答すること。
- 数量で答える問題の回答には単位を付けること.
- 質問に対して<excerpts>タグ内にある情報で、質問に答えるための情報がない場合は「分かりません」と答えること.
- 質問自体に誤りがあると判断される場合は「質問誤り」のみ答えること.
7. 回答データを再度LLMで加工
今回のコンペでは、回答に冗長な内容が含まれている場合、不正解とされてしまうことが多いため、LLMに質問クエリに対する最も重要な内容のみを回答させるように回答データを加工させます。
モデルはGPT-4oを利用しました。
# 回答内容を整形し、冗長な文章を削除する
def create_reanswer(question, answer):
reanswer_template = """
あなたはプロの編集者です。
以下に質問文に対する回答文があります。
質問文に対して回答文の中から最も簡潔に重要な内容のみを抽出してください。
単語のみを回答しても構いません。
# 質問文
{question}
# 回答文
{answer}
"""
custom_reanswer_prompt = PromptTemplate.from_template(reanswer_template)
reanswer_chain = custom_reanswer_prompt | llm | StrOutputParser()
return reanswer_chain.invoke({"question": question, "answer": answer})
まとめ
RAG-1グランプリに参加してみて感じたこととして、RAGって難しいな~って改めて強く感じました。
ただ、今回のようにデータセットが決まっていて、質問の傾向もわかっている場合であれば、検索手法やプロンプトエンジニアリングも具体的に設定できるので評価はしやすかった印象です。
実際に多くの社員が利用するRAGシステムの場合、データセットの種類も質問クエリの傾向も無数に存在するため、具体的な対策が難しいと感じています。
今回のコンペで学んだ各手法をRAGシステムの開発に役立てていきたいと思います。
個人的には、上位者のレポートでどのようなRAGシステムを実装されたのか非常に気になるのでとても楽しみにしています。
Discussion