GraphQLって何?
本記事の概要
最近 GraphQL を初めて使う機会があったので、そもそも GraphQL の概要に関して調べてみました。
本記事を読めば、以下の内容を知ることができます。
- GraphQL の概要
- GraphQL クエリのイメージ
GraphQL について勉強し始めたばかりなので、認識違えばご指摘いただけると大変助かります。
【対象読者】
- GraphQL の概要をざっくり知りたい方
- API についての知見が少しでもある方
【対象ではない読者】
- API ってそもそも何?という方
- REST との比較も出てくるので、若干難しく感じるかもです
- GraphQL の知見が既にあり、実装もバリバリできる方
- 今回は GraphQL の概要と触りだけになるので、復習くらいの感じで見ていただけると助かります
そもそも GraphQL って何?
GraphQL とは一言でいうと「API のための問い合わせ言語」になり、基本的には API を呼び出す時に使用する言語になります。
※グラフ理論を元に作られた(Graph)クエリ言語(Query Language)
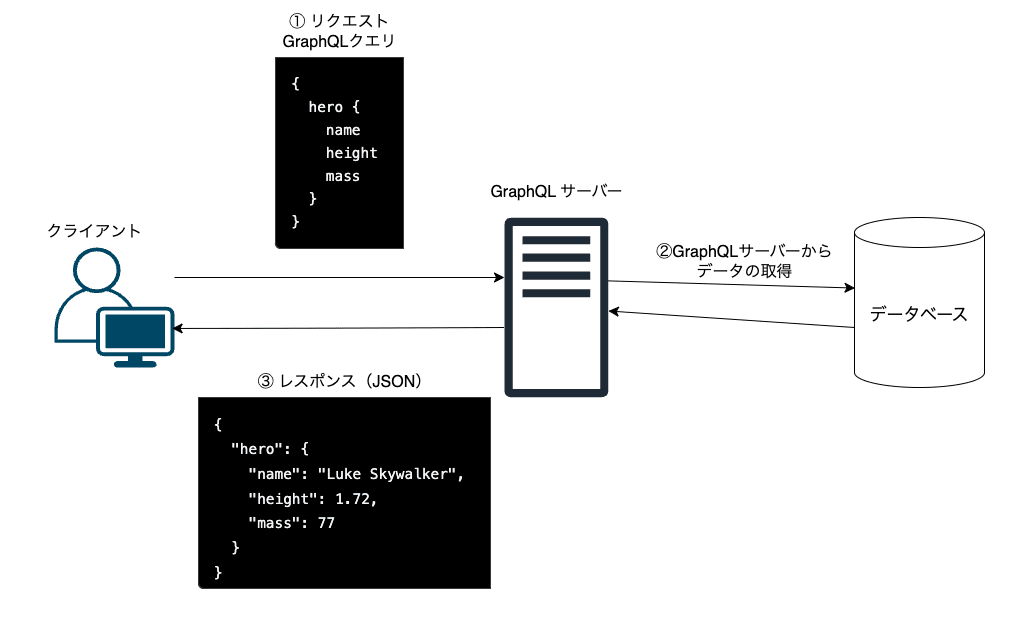
以後説明しますが、GraphQL クエリをリクエストとして GraphQL サーバーに送信し、GraphQL サーバーからリクエストに応じて DB からデータ取得を行い、レスポンスを返すイメージです。
GraphQL 公式サイト ↓
GraphQL の特徴
GraphQL には以下のような特徴があります。
① エンドポイントが一個だけで済む
GraphQL は GraphQL クエリでデータ操作の内容を定義するので、エンドポイントは一つで済みます。
GraphQL クエリは文字列として GraphQL サーバーに送る必要があるので、一般的な HTTP 通信を使用するパターンだと、POST リクエストのボディに GraphQL クエリの文字列を入れる形を取ります。
※エンドポイント名は/graphqlとかが多いような気がします。
② 過剰なデータ取得を防げる
GraphQL は必要なデータだけ GraphQL クエリに書けばそのデータだけを取得できるので、過剰にデータを取得することを防げます。
RESTful な API でエンドポイントを流用する場合に、余分なフィールドもレスポンスとして許容することがあり、それがデータ帯域の圧迫をしたり、レスポンスが遅くなることがあるので、GraphQL はこの課題を解決してます。
③ 過小なデータ取得を防げる
GraphQL サーバーで各テーブルの関連を紐づけることで、テーブル間を跨いだデータの取得ができます。
RESTful な API だとエンドポイントを何回も叩いて必要なデータをそれぞれ取得するシチュエーションでも、GraphQL を使えば 1 回のリクエストで必要な情報を全て取得できるようになります。
④ リアルタイムのデータ更新が可能
GraphQL ではサブスクリプションという機能があり、この機能を使えばリアルタイムでデータの更新を受け取ることができます。
定期的にリクエストを送って更新を取得するのではなく、ソケットを使用してデータ更新を監視する、みたいなイメージです。
⑤ 型によるデータ安全性がある
GraphQL では使用するデータ型の定義もできるので、意図しないデータをクライアントが取得することも防げます
GraphQL が生まれた背景
GraphQL の特徴からもわかると思いますが、基本的には REST で起きていた課題を解決するため、2012 年頃から Facebook が開発を進め、2015 年に公開をしました。
実際に GraphQL を使っている代表的な会社は以下になります
- Github
- IBM
- Airbnb
日本企業だと以下がありそうです。
- Retty
- ビズリーチ
- メルカリ
GraphQL クエリ
実際にデータ操作をするには GraphQL クエリを書く必要があるのですが、GraphQL クエリには以下の 3 種類があります。
-
Query
- データ取得(
SELECT)
- データ取得(
-
Mutation
- データ変更(
INSERT,UPDATE,DELETE)
- データ変更(
-
Subscription
- リアルタイムデータ更新を受け取る
GraphQL サーバー
GraphQL サーバーはリクエストから送られてきた GraphQL クエリ の構文を解釈したり、DB の操作をしたり、エラー処理をするために必要になります。
GraphQL のフレームワークを使用して自作をすることもできますが、マネージドサービスを使用して簡単に構築できたりもするので、状況に応じて適切な判断をする必要があります。
GraphQL クエリの記述方法
実際の GraphQL クエリは以下のような形になります。
今回は詳しく解説をしておらず例という形ですが、イメージだけ掴む程度で大丈夫だと思います。
Query
① ユーザー情報の取得
query {
user {
name
email
}
}
レスポンス(JSON)
{
"data": {
"user": {
"name": "John Doe",
"email": "john@example.com"
}
}
}
② ユーザー情報とそれに紐づく投稿の取得
query {
user {
name
email
posts {
title
content
}
}
}
レスポンス(JSON)
{
"data": {
"user": {
"name": "John Doe",
"email": "john@example.com",
"posts": [
{
"title": "First Post",
"content": "This is my first post."
},
{
"title": "Second Post",
"content": "This is my second post."
}
]
}
}
}
Mutation
Mutation を使用するときは、フィールドを準備して引数を渡す必要があります。
① ユーザー情報の登録
mutation {
createUser(input: { name: "Alice", email: "alice@example.com" }) {
id
name
email
}
}
② ユーザー情報の更新
指定したidのユーザーを更新
mutation {
updateUser(id: "123", input: { name: "Bob", email: "bob@example.com" }) {
id
name
email
}
}
③ ユーザー情報の削除
指定したidのユーザーを削除
mutation {
deleteUser(id: "123") {
id
name
email
}
}
Subscription
ユーザー情報に変更があった場合に通知を受け取る
subscription {
userChanged {
id
name
email
}
}
あとがき
今回 GraphQL について勉強を始めましたが、実際にグラフ構造でデータを取得する際にどのような SQL を発行しているのか、どのような動きをしているのかがとても気になったので、時間があればそちらも調べてみようかなと思ってます。
また、GraphQL サーバーのマネージドサービスを提供している Hasura のチュートリアルもとてもわかりやすかったので気になる方はそちらを進めてみると面白いかもです。
Discussion