SnowflakeネイティブなMLパイプライン
この記事は Snowflake Advent Calendar 2023 Series 2 の 22日目です。
はじめに
SnowflakeSummit2023やSnowday2023ではML関連機能が多く発表されました.
- Snowpark ML Modeling API (PuPr)
- Snowpark ML Preprocessing API (PuPr)
- Snowpark ML Operations API (PrPr)
- Snowpark Container Services (PrPr)
- Snowflake FeatureStore (PrPr)
- Snowflake Cortex (PrPr)
- Snowflake Notebook (PrPr)
とは言うものの,SnowflakeでML実践している事例をあまり聞くことがないので,現状どこまで可能か試してみました.
目指すアーキテクチャ
MLモデルをシステム実装して本番運用させること(MLOps)については既に色々なところで体系的に整理されています.その中でも定番であろうGoogleの『MLOps: 機械学習における継続的デリバリーと自動化のパイプライン』を参考に,「レベル1:MLパイプラインの自動化」をSnowflakeのみで実施することを今回の目標とします.

【出典】MLOps: 機械学習における継続的デリバリーと自動化のパイプライン 図3
ただし,今回はメタデータ管理や稼働状況モニタリングの仕組みを作り込むことはスコープアウトします.
PrPrのSnowpark ML Operations APIを使ったりテーブル設計を工夫したりすればメタデータ管理はできそうなのと,Streamlit in Snowflakeで稼働状況モニタリングもできそうなので,機会があれば挑戦してみたいです.
使用する機能
2023年12月時点でGAもしくはPuPrになっている以下機能のみを使用します.
『MLOps: 機械学習における継続的デリバリーと自動化のパイプライン』では,「レベル1:MLパイプラインの自動化」の段階でModelRegistoryやFeatureStoreが登場していますが,Snowpark ML Operations APIやSnowflake FeatureStoreはPrPrなので今回はスコープアウトします.
なお,MLパイプラインは「データの前処理~モデルの学習~デプロイ」を行うパイプラインを指します.そもそものデータを抽出・変換してくるデータパイプラインは含めないことにします.
また,Snowpark MLの使い方は公式クイックスタートのIntro to Machine Learning with Snowpark ML for Pythonを参考にしました.
問題設定
Kaggleで公開されているClick on Ad datasetを使用します.
webサイト上の広告をユーザがクリックしたか否かのデータです.
以下のような10列で構成されています.
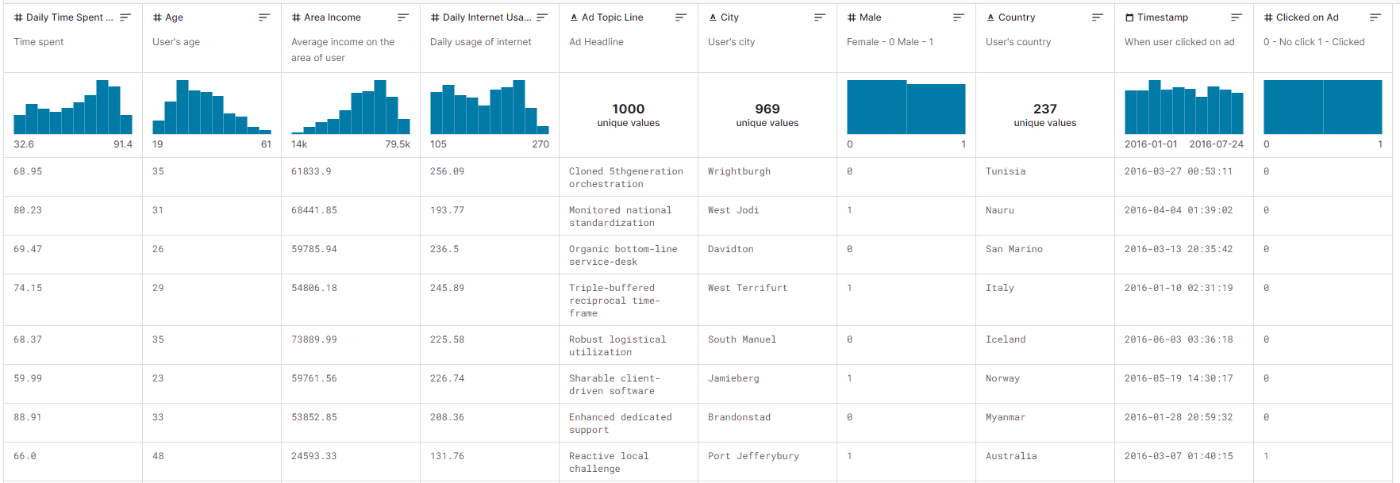
【出典】Kaggle Click on Ad dataset
左から順に
- Daily Time Spent on Site
- 被験者が対象のwebサイト上で過ごした1日あたりの時間
- Age
- 被験者の年齢
- Area Incomes
- 被験者の居住地区の所得水準
- Daily Internet Usage
- 被験者の1日あたりインターネット利用時間
- Ad Topic Line
- 被験者に表示した広告の見出し
- City
- 被験者の居住地
- Male
- 男性のフラグ
- Country
- 被験者の国籍
- Timestamp
- 広告表示時刻
- Clicked on Ad
- 表示された広告をクリックしたか否か
となっており,Clicked on Adが目的変数,Ad Topic Lineがwebサイト側でコントロール可能な変数です.Timestampはユーザがwebサイトを訪問中という条件下であれば,広告を表示するタイミングはある程度webサイト側でコントロールできるかもしれません.その他はユーザの属性変数です.
「どんな属性のユーザにどんな広告を表示するとクリックされやすいか」を分析するために,クリックの有無を判別するMLモデルを作ります.
公式ドキュメントによると,Snowpark MLはscikit-learn, XGBoost, LightGBMのラッパーだそうです.
また,これら3つのライブラリであっても,すべてのクラスが使えるわけではないようです.特にscikit-learnは本家に実装はあるものの,Snowpark MLには実装されていないクラスがいくつか見受けられます.
とりあえず今回はテーブルデータなのでXGBoostを使用することにします.
基本方針
SnowflakeネイティブなMLパイプラインを目指すので,極力Snowparkで実装します.
Pandas.DataFrameではなくSnowpark.DataFrameでデータを前処理して,本家XGBoostのAPIではなくSnowpark MLでラッパーされているXGBoostでモデルを学習させます.
実装するMLパイプラインの処理の流れは以下です.
各処理のIN/OUTを書き加えた流れです.
Click on Ad datasetのcsvを2つに分割してadvertising_trainとadvertising_testというテーブル名でSnowflakeに取り込みます.
図の長方形はタスク,角丸長方形はデータ,楕円はアーティファクトを表します.
学習済みのモデルを使って予測するときの流れは以下です.
元のadvertising_trainテーブルです.

MLパイプライン実装
上記の各処理をストアドプロシージャで実装し,ストアドプロシージャを実行するタスクを以下のようなDAGとして実装します.

このDAGがMLパイプラインになります.
事前準備として各種アーティファクトやUDFを保存する内部ステージとDAGの親タスクを作成しておきます.
CREATE OR REPLACE STAGE ML_HOL_ASSETS;
CREATE OR REPLACE TASK task_training_root
WAREHOUSE = 'compute_wh'
AS
select ('Modeling Start') as status;
実行環境
事前準備のクエリを除いて,MLパイプラインの実装はすべてJupyterで行います.
Pythonのバージョンは3.10です.
以下requirements.txtでpythonの仮想環境を作って,その中でJupyter-Labを起動します.
jupyterlab
snowflake-snowpark-python
pandas
xgboost
scikit-learn
cachetools
seaborn
matplotlib
snowflake-ml-python
インストールされたSnowparkのバージョンは以下でした.
snowflake-ml-python 1.0.12
snowflake-snowpark-python 1.10.0
テキスト変数の前処理
2023年12月時点のSnowpark MLではscikit-learnに含まれているテキスト処理系のクラスは実装されていないので本家scikit-learnからTfidfVectorizerを使用して,各広告見出しのTF-IDFを計算します.
本家scikit-learnを使う以上,Pandas.DataFrameの使用もやむなしです.
def sproc_tfidf_vectorizer(session: Session, input_table):
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# データ取得
query = f"""
select
ID
,AD_TOPIC_LINE
from
{input_table}
"""
df = session.sql(query).to_pandas()
sentences = df['AD_TOPIC_LINE']
# TF-IDFを計算
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(sentences)
df_tfidf = pd.DataFrame(X.toarray(), columns=[col.upper() for col in list(vectorizer.get_feature_names_out())], index=df['ID'].to_list())
df_tfidf = df_tfidf.add_prefix('VOCAB_').reset_index(names='ID')
session.write_pandas(df_tfidf, 'TFIDF_VECTORS', auto_create_table=True, overwrite=True, table_type='transient')
# TF-IDFの重みを保存
VECTORIZER_FILE = '/tmp/tfidf_vectorizer.joblib'
joblib.dump(vectorizer, VECTORIZER_FILE)
session.file.put(VECTORIZER_FILE, "@ML_HOL_ASSETS", overwrite=True)
return "SUCCSESS"
# ストアドプロシージャの登録
session.sproc.register(
func=sproc_tfidf_vectorizer,
name='sproc_tfidf_vectorizer',
packages=['snowflake-snowpark-python', 'snowflake-ml-python'],
input_types=[StringType()],
return_type=StringType(),
is_permanent=True,
stage_location='@ML_HOL_ASSETS',
replace=True)
# タスクを追加
task_tfidf_vectorizer = """
CREATE OR REPLACE TASK task_tfidf_vectorizer
WAREHOUSE = 'compute_wh'
AFTER task_training_root
AS
CALL sproc_tfidf_vectorizer('advertising_train')
"""
session.sql(task_tfidf_vectorizer).collect()
session.sql('alter task task_tfidf_vectorizer resume').collect()
これにより,元のデータのAD_TOPIC_LINE列から以下のようなTF-IDFが算出されます.

数値変数・カテゴリ変数の前処理
Snowpark MLで数値変数の標準化とカテゴリ変数のオーディナルエンコーディングを実施します.
(XGBoostのアルゴリズムの挙動的には標準化しなくても良いのですが...折角なので)
def sproc_training_preprocessing(session: Session, input_table):
import snowflake.ml.modeling.preprocessing as snowml
from snowflake.ml.modeling.pipeline import Pipeline
import json
import joblib
import warnings; warnings.simplefilter('ignore')
# データ取得
query = f"""
select
ID
,DAILY_TIME_SPENT_ON_SITE
,AGE
,DAILY_INTERNET_USAGE
,CITY
,COUNTRY
,AREA_INCOME
,MALE
,CLICKED_ON_AD
from
{input_table}
"""
df = session.sql(query)
# データ前処理のパイプライン作成
CATEGORICAL_COLUMNS = ["CITY", "COUNTRY"]
NUMERICAL_COLUMNS = ["DAILY_TIME_SPENT_ON_SITE", "AGE", "DAILY_INTERNET_USAGE"]
preprocessing_pipeline = Pipeline(
steps=[
(
"OrdinalEncoding",
snowml.OrdinalEncoder(
input_cols=CATEGORICAL_COLUMNS,
output_cols=CATEGORICAL_COLUMNS,
categories="auto",
handle_unknown='use_encoded_value',
unknown_value=9999999
)
),
(
"Standardizing",
snowml.StandardScaler(
input_cols=NUMERICAL_COLUMNS,
output_cols=NUMERICAL_COLUMNS
)
)
]
)
transformed_df = preprocessing_pipeline.fit(df).transform(df)
df_tfidf = session.table('TFIDF_VECTORS')
df_train = transformed_df.join(df_tfidf, on='ID')
df_train.write.mode('overwrite').save_as_table('DF_TRAIN', table_type='transient')
# データ前処理のパイプラインを保存
PIPELINE_FILE = '/tmp/preprocessing_pipeline.joblib'
joblib.dump(preprocessing_pipeline, PIPELINE_FILE)
session.file.put(PIPELINE_FILE, "@ML_HOL_ASSETS", overwrite=True)
return "SUCCSESS"
# ストアドプロシージャを登録
session.sproc.register(
func=sproc_training_preprocessing,
name='sproc_training_preprocessing',
packages=['snowflake-snowpark-python', 'snowflake-ml-python'],
input_types=[StringType()],
return_type=StringType(),
is_permanent=True,
stage_location='@ML_HOL_ASSETS',
replace=True)
# タスクを追加
task_training_preprocessing = """
CREATE OR REPLACE TASK task_training_preprocessing
WAREHOUSE = 'compute_wh'
AFTER task_tfidf_vectorizer
AS
CALL sproc_training_preprocessing('advertising_train')
"""
session.sql(task_training_preprocessing).collect()
session.sql('alter task task_training_preprocessing resume').collect()
前処理結果は以下のようになります.

モデルの学習
Snowpark MLラッパーのXGBoostはXGBoostのオリジナルAPIではなく,scikit-learnインターフェースのAPIです.
そして致命的なことにearly stoppingがかけられない...
本家XGBoostのXGBClassifier同様にfitメソッドの引数にeval_setを渡すとそんな引数ないよと怒られちゃいました...
from snowflake.ml.modeling.xgboost import XGBClassifier
clf = XGBClassifier(
input_cols=INPUT_COLUMNS,
label_cols=LABEL_COLUMNS,
output_cols=OUTPUT_COLUMNS,
learning_rate=0.05,
random_state=0,
n_estimators=1000,
early_stopping_rounds=50
clf.fit([train_x, train_y], eval_set=[(valid_x, valid_y)])

early stoppingがかけられないと無駄な学習時間がかかるだけでなく過学習のリスクも増えるので,実用面では厳しいです.
Intro to Machine Learning with Snowpark ML for Pythonではグリッドサーチを行っていたので,今回はランダムサーチでハイパーパラメータを探索させてみます.
残念ながらSnowpark MLはOptunaに対応していなかったので,Optunaを使うなら普通にPandasと本家XGBoostライブラリで実装することになります.
Optunaの方が探索効率が優れているので,その意味でももう一歩です.
モデルの学習と一緒にバッチ予測用のUDFも定義をしてしまいます.
import cachetools
from snowflake.snowpark.types import PandasSeries, PandasDataFrame
from snowflake.snowpark.functions import pandas_udf, array_construct
def sproc_training_model(session):
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection import RandomizedSearchCV
from snowflake.ml.modeling.metrics import roc_auc_score
from sklearn.model_selection import StratifiedKFold
import pandas as pd
# 学習用と検証用にデータ分割
df = session.table('df_train')
train_snow_df, valid_snow_df = df.random_split(weights=[0.8, 0.2], seed=0)
INPUT_COLUMNS = ["DAILY_TIME_SPENT_ON_SITE", "AGE", "AREA_INCOME", "DAILY_INTERNET_USAGE", "CITY", "MALE", "COUNTRY"]
LABEL_COLUMNS = ["CLICKED_ON_AD"]
OUTPUT_COLUMNS = ["PREDICTION"]
# ランダムサーチ
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
clf = RandomizedSearchCV(
estimator=XGBClassifier(
learning_rate=0.05,
random_state=0,
max_depth=7,
n_estimators=100
),
param_distributions={
"colsample_bytree":[0.6, 0.7, 0.8, 0.9],
"colsample_bylevel":[0.6, 0.7, 0.8, 0.9],
},
n_iter=100,
n_jobs=-1,
scoring="neg_log_loss",
cv=skf,
input_cols=INPUT_COLUMNS,
label_cols=LABEL_COLUMNS,
output_cols=OUTPUT_COLUMNS
)
clf.fit(train_snow_df)
# ランダムサーチ結果をテーブルに書き戻す
rs_results = clf.to_sklearn().cv_results_
colsample_bytree_val = []
colsample_bylevel_val = []
for param_dict in rs_results["params"]:
colsample_bytree_val.append(param_dict["colsample_bytree"])
colsample_bylevel_val.append(param_dict["colsample_bylevel"])
logloss = rs_results["mean_test_score"]*(-1)
rs_results_df = pd.DataFrame(data={
"colsample_bylevel":colsample_bylevel_val,
"colsample_bytree":colsample_bytree_val,
"logloss":logloss})
session.write_pandas(gs_results_df, 'RANDOM_SEARCH_RESULTS', auto_create_table=True, overwrite=True, table_type='transient')
# モデルを保存
optimal_model = clf.to_sklearn().best_estimator_
MODEL_FILE = '/tmp/model.joblib'
joblib.dump(optimal_model, MODEL_FILE)
session.file.put(MODEL_FILE, "@ML_HOL_ASSETS", overwrite=True)
# 検証用データで推論実行
pred = clf.predict_proba(valid_snow_df)
pred.write.mode('overwrite').save_as_table('VALID_PREDICTION', table_type='transient')
# 検証用データの推論結果の精度指標をテーブルに書き戻す
score = roc_auc_score(df=pred,
y_true_col_names=LABEL_COLUMNS,
y_score_col_names='PREDICT_PROBA_1')
score_df = pd.DataFrame(data={"ROC_AUC":[score]})
session.write_pandas(score_df, 'VALID_SCORE', auto_create_table=True, overwrite=True, table_type='transient')
# バッチ予測UDF定義
@cachetools.cached(cache={})
def load_model(filename):
import joblib
import sys
import os
IMPORT_DIRECTORY_NAME = "snowflake_import_directory"
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
if import_dir:
with open(os.path.join(import_dir, filename), 'rb') as file:
m = joblib.load(file)
return m
@pandas_udf(name='batch_predict', session=session, replace=True, is_permanent=True, stage_location='@ML_HOL_ASSETS', max_batch_size=1000)
def batch_predict(df: PandasDataFrame[list]) -> PandasSeries[float]:
import pandas as pd
cols = ["DAILY_TIME_SPENT_ON_SITE", "AGE", "DAILY_INTERNET_USAGE", "CITY", "COUNTRY", "AREA_INCOME", "MALE", "CLICKED_ON_AD"]
model = load_model('model.joblib.gz')
features = list(model.feature_names_in_)
df.columns = ['x']
data = df['x'].tolist()
df2 = pd.DataFrame(data, columns=[col for col in cols])
df_x = df2[features]
pred = model.predict_proba(df_x)[:,1]
return pred
return 'SUCCESS'
# ストアドプロシージャを登録
session.sproc.register(
func=sproc_training_model,
name='sproc_training_model',
packages=['snowflake-snowpark-python', 'snowflake-ml-python'],
return_type=StringType(),
is_permanent=True,
stage_location='@ML_HOL_ASSETS',
replace=True)
# タスクを追加
task_training_model = """
CREATE OR REPLACE TASK task_training_model
WAREHOUSE = 'compute_wh'
AFTER task_training_preprocessing
AS
CALL sproc_training_model()
"""
session.sql(task_training_model).collect()
session.sql('alter task task_training_model resume').collect()
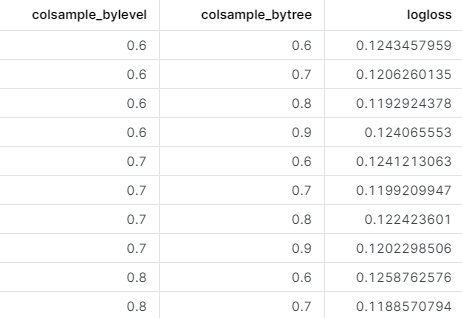
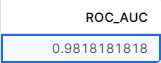
ランダムサーチの探索結果と検証用データでの精度指標は以下のようにテーブルに書き戻されます.
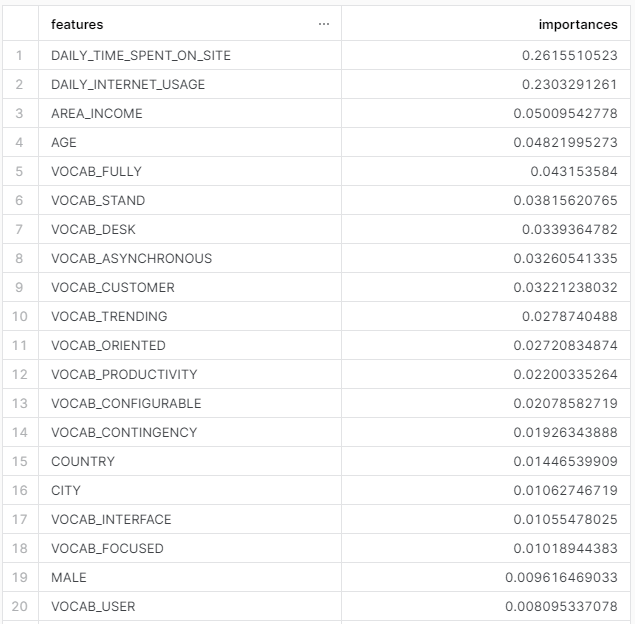
特徴量重要度(Feature Importances)もテーブルに書き戻します.
内部ステージには学習済みのモデルを始め各種アーティファクトが保存されています.

バッチ予測実行
モデル学習のストアドプロシージャの中で作成したバッチ予測UDFを新しいデータadvertising_testテーブルに対して実行するためのタスクを作成します.
task_batch_predict = """
CREATE OR REPLACE TASK task_batch_predict
WAREHOUSE = 'compute_wh'
AS
create or replace transient table batch_prediction_results as
select
*
,batch_predict(array_construct(*)) as PREDICTED_SCORE -- pandas UDFによって得られる予測値
from
ADVERTISING_TEST
"""
session.sql(task_batch_predict).collect()
session.sql('execute task task_batch_predict').collect()
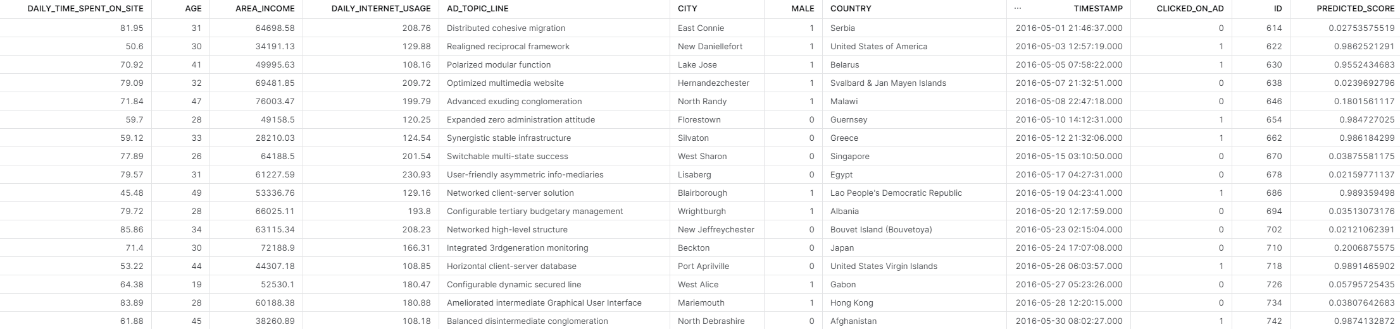
実行結果は,以下のようにテーブルに書き戻されます.
PREDICTED_SCORE列がバッチ予測結果です.
まとめ
以上で実装したシステムとしての動作は以下のようになります.
- 新しいデータが入ってくるたびにタスク
task_batch_predictを実行する - タスク
task_batch_predictの実行結果を監視する(今回は作成していない) - 監視にて精度指標が閾値を下回るなどの条件でタスク
task_training_rootをトリガーする(今回は作成していない) - タスク
task_training_rootで新しいモデルがデプロイされる
「レベル1:MLパイプラインの自動化」の図の一部は省略したものの,最低限の内容はSwnoflakeだけで実装することができました.
とは言え,Snowpark MLだけでは前処理で実施できることが限定的だったり,early stoppingがかけられなかったり,ハイパーパラメータの探索が効率的ではなかったりするので,今後が楽しみです.
Discussion