AWS CDKにおけるスタックの分割の検討
はじめに
おはようございます、クラスメソッド MAD事業部の加藤です。
この記事はAWS CDK Advent Calendar 2021のカレンダー | Advent Calendar 2021 - Qiitaの7日目の記事です。
本記事はAWS CDKにおけるスタックをどのように分割するかについての現時点での私の見解をまとめたものです。1つのWebアプリケーションを構築するという環境を想定しています。
文章の見やすさの為に記事中では言い切り系ですが、内容は全て私の私見、そして自分の観測範囲での話です。
CloudFormationとCDKのスタック分割は同じで良いか
CDKはCloudFormationテンプレートを生成してAWSリソースの作成を行います。CDKからCloudFormationへ強い依存関係があります。しかし、CDKのスタック分割はCloudFormationとは別で考える必要があります。
CloudFormationは仕様として単一のファイルでテンプレートを定義しなければなりません。ワークアラウンドとしてJinjaテンプレートなどを使って実行前に複数ファイルから1つに合成することが可能でしたが、自分の観測範囲では導入されているのはまれでした。こういった事情から、CloudFormationのスタック分割は編集しやすくする為にファイル分割した結果スタックも分割される事があります。CDKではファイルの分割はスタックの分割に依存せず行うことが出来ます。CDKとCloudFormationのスタック分割は基本的には同じ考えで良いが、ファイル分割の為にスタックを分割する必要はありません。CloudFormationからCDKへ移植する際はこの点に気をつけましょう。
ステートフルとステートレスで分割する
スタック分割を考える上で最も重要な観点は、ステートフルとステートレスです。ステートフルとはデータベースやストレージのような、データを保持するリソースです。
- ステートフル
- Amazon Aurora/RDS
- Amazon DynamoDB
- Amazon S3
- ...
- ステートレス
- Amazon EC2
- Amazon ECS
- Amazon Elastic Load Balancing
- ...
有名どころなサービスで分類すると上記みたいな感じです。しかし、気をつけて欲しいポイントとしてリソースがステートレスかステートフルかはその使い方によって決まります。RDSを毎回データを投入→集計→削除しているならステートレスです、EC2のローカルストレージにアップロードされたファイルを永続的に保持しているならステートフルです。また、出力されたログはステートフルとして扱う必要があります。
とはいえ、多くのリソースがログを出力するので全部をステートフルなスタックにするのが厳しい場合があります。
そういったときに、データの保持さえ出来れば良いのであればRemovalPolicyでRETAINを指定してステートレスなスタックとして扱ってしまうことができます。

ログがCloudWatch LogsやS3に保存されたら即座に別のAWSアカウントのログ基盤や外部のSaaSに転送するように設定しておくのも良いでしょう。
ステートフルなスタックから他のスタックに依存しないようにする
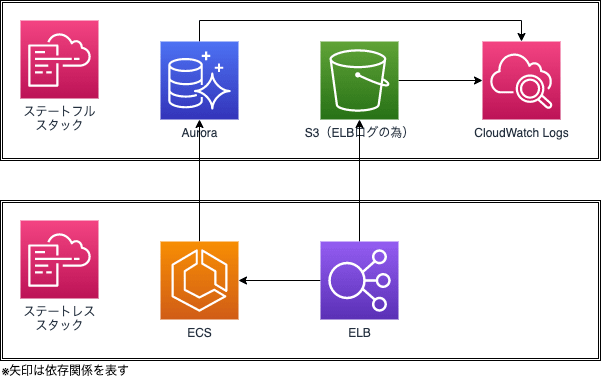
ステートフルとステートレスの分割を意識してスタック分割をすると下図のような構成になりがちです。

これぐらい簡単な構成ならそうそう起こりませんが、CDKでクロススタックで値を参照する際に使用されるCloudFormationのFn::ImportValueはスタック間を密結合にする為、リソースの値を変更出来なくなる事態が多々起きます。もちろん、万全の状態にスタック間の依存関係の方向を整理出来ていれば問題は無いのですが、開発フェイズで問題のある依存関係の方向に気づかないまま運用フェイズに入ってしまい、かつステートフルなスタックの再作成が必要な事態になってしまうとかなり厳しいです。
なのでよほど大きなプロジェクトで無ければスタックは、①ステートフルなリソースとそれらがが依存するリソース ②ステートレスなリソース(前述の通り、ログの為のリソースはRETAINに設定)の2つに分割するのがちょうど良いんじゃ無いかと最近は考えています。

ちなみに、発生してしまった依存関係の解除方法はこちらが参考になります。
スタックの肥大化についての考え
スタックの肥大化への対応としては、①CDKとしてしてでは無くアーキテクチャのレベルで分離するか ②そもそもこの記事の前提である1つのWebアプリケーションの開発というシチュエーションではないのでCDK以外を検討するというのが私の考えです。
アーキテクチャレベルの分離としてもっともわかりやすい例はデータ分析基盤との分離です。アプリケーションはデータをS3に保管するところまでを責務とし、データ分析基盤はS3からデータを取得することからを責務とします。両者間でバケットのURLとオブジェクト名、スキーマを共有します。データ分析側は別サービスとして扱い、IaCツールに何を使うか自体もそちらのチームに任せます。
EKSを使って複数のアプリケーションに共通のKubernetsを提供したいような場合や、Transit Gateway・VPC・GWLBなどを組み合わせて基盤を構築したい場合など、CDKが向いていないまたは大きすぎる場合はあります。生のCloudFormationやTerraformなども検討してみましょう。
あとがき
何というかすごいすごい散文な感じになってしまいました。。。言いたかった事としては
- CDKはファイル分割ができるのでCloudFormationほどスタックを細かく分けなくても良い
- スタック肥大化もそこまで恐れなく良いしそれでも管理がキツくなるのであればアーキテクチャとして分割した方が良い
- CDKはコードを書く感覚で簡単にスタック間依存が出来てしまうのでスタック数が少なくなるように意識し特にステートフルなスタックから他への依存は避けた方が良い
でした。何というか書きたくなった気持ちドリブンじゃなく期日を気にしてブログ書く能力が超絶落ちているなと痛感しました。
以上でした!
Discussion