Gaudi® 2 アクセラレーターとXeon® プロセッサーを活用した、コスト効率の高いエンタープライズ向け RAGアプリケーションの構築




検索拡張生成 (RAG) は、外部のデータストアに格納されている分野固有の最新ナレッジを取り入れることで、大規模言語モデルを使用したテキスト生成の機能を拡張します。大規模モデルのトレーニング中に学習したナレッジから社内データを切り離すことは、バランスの取れたパフォーマンス、精度、セキュリティー強化、プライバシー保護といった目標の達成のために不可欠です。
このブログでは、エンタープライズ AI 向けオープン・プラットフォーム (OPEA) の一部として、インテルがどのように開発者の皆さんの RAG アプリケーション開発 / 展開をサポートしているか紹介します。また、エンタープライズ環境に導入する実際の RAG ユースケースを通じて、インテル® Gaudi® 2 AI アクセラレーターとインテル® Xeon® プロセッサーを採用することでパフォーマンスの大幅な向上を実現する方法についても説明します。
<はじめに>
具体的な手順に進む前に、まずはハードウェアにアクセスしましょう。インテル® Gaudi®2 アクセラレーターは、データセンターやクラウドで実行するディープラーニングの学習処理と推論の加速を目的に設計されました。インテル® Tiber™ デベロッパー・クラウドで利用することができ、オンプレミスでの実装が可能です。インテル® Tiber™ デベロッパー・クラウドは、最もスムーズにインテル® Gaudi® 2 アクセラレーターを開始できる方法と言えます。まだアカウントをお持ちでない場合は、初めにアカウントを登録してから「プレミアム」を選択し、アクセスを申し込んでください。
ソフトウェア側では、オープンソースのフレームワークである LangChain を使用してアプリケーションを構築します。このフレームワークは、大規模言語モデル (LLM) で動く AI アプリケーションの開発をシンプル化するために設計されました。テンプレート・ベースのソリューションが提供されるため、開発者はカスタムの埋め込み、ベクトル型データベース、LLM を使用した RAG アプリケーションの構築が可能になります。LangChain のドキュメントから、さらに詳しい情報を入手できます。インテルはこれまでも LangChain にさまざまな最適化を行い、開発者がインテルのプラットフォーム上で生成 AI アプリケーションを効率的に展開できるように取り組んできました。
LangChain では rag-redis テンプレートを使用し、BAAI/bge-base-en-v1.5 埋め込みモデルと Redis をデフォルトのベクトル型データベースとして、独自の RAG アプリケーションを作成します。以下の図は、アーキテクチャーの全体像を示しています。
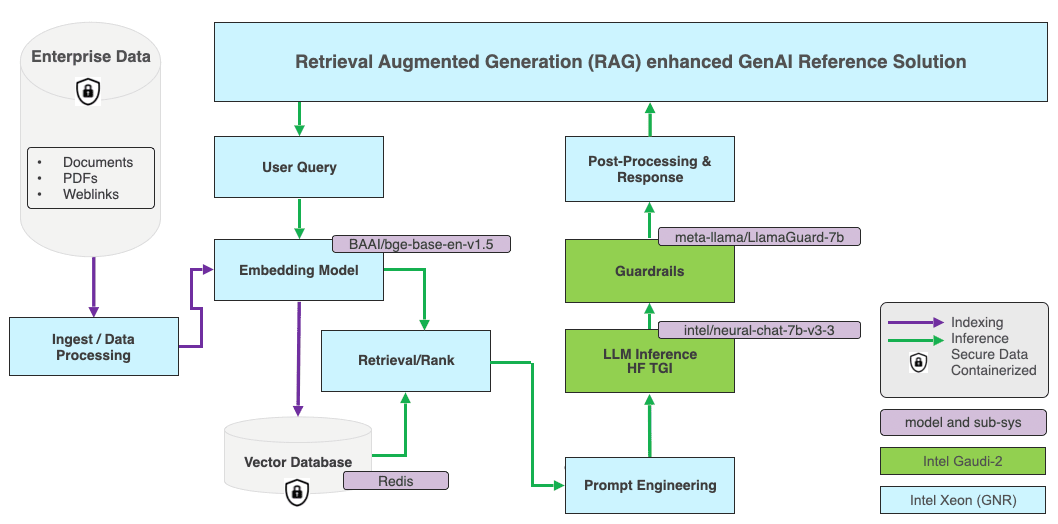
この埋め込みモデルはインテル® Xeon® 6 プロセッサー (P-cores 採用) (開発コード名: Granite Rapids) で実行します。インテル® Xeon® 6 プロセッサー (P-cores 採用) のアーキテクチャーは、総保有コスト (TCO) を最小限に抑え、コア性能の影響を受けやすいワークロードと汎用の演算ワークロードに最適化されています。また、インテル® AMX の FP16 命令セットをサポートしており、混合 AI ワークロードにおける 2 ~ 3 倍のパフォーマンス向上が見込まれます。
LLM は、インテル® Gaudi® 2 アクセラレーターで実行します。Hugging Face モデルについては、Optimum Habana ライブラリーが Hugging Face Transformers や Diffusers ライブラリーとインテル® Gaudi® AI アクセラレーターの間をつなぐインターフェイスです。このライブラリーで提供されるツールセットによって、モデルの読み込み、学習処理、推論がシンプルになり、シングルカード構成とマルチカード構成のどちらもサポートしているため、多様なダウンストリーム・タスクへの対応が可能になります。
GitHub では、LangChain 開発環境のセットアップをスムーズにするために、Dockerfile を提供しています。Docker コンテナを起動できたら、いよいよ Docker 環境でのベクトル型データベース、RAG パイプライン、LangChain アプリケーションの構築開始です。詳細な手順については、ChatQnA の例を参照してください。
<ベクトル型データベースを作成する>
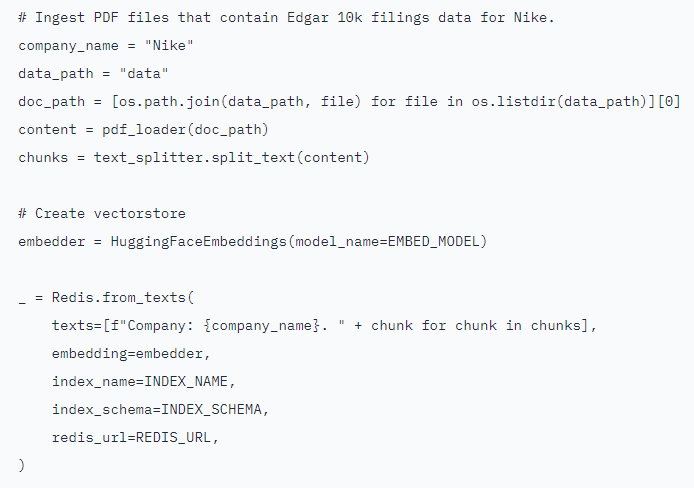
ここではベクトル型データベースにデータを投入するために、Nike が公開している財務関連のドキュメントを使用します。以下にサンプルコードを示します。
<RAG パイプラインを定義する>
LangChain では、Chain API を使用して、プロンプト、ベクトル型データベース、埋め込みモデルを接続します。完全版のコードはリポジトリーから入手してください。

<インテル® Gaudi® 2 アクセラレーターに LLM をロードする>
Hugging Face の Text Generation Inference (TGI) サーバーを使用して、インテル® Gaudi® 2 アクセラレーターでチャットモデルを実行します。この組み合わせにより、MPT、Llama、Mistral などインテル® Gaudi® 2 アクセラレーターを採用し広く実装されているオープンソースの LLM で、高性能のテキスト生成が可能になります。
セットアップは必要ありません。あらかじめビルド済みの Docker イメージを使用してモデル名 (例: Intel NeuralChat) を渡すことができます。

このサービスではデフォルトで 1 基のインテル® Gaudi® アクセラレーターを使用します。パラメーター数が 700 億を超えるような大規模モデルを実行するには、複数のアクセラレーターが必要です。そのような場合、例えば --sharded true や --num_shard 8 など、適切なパラメーターを追加してください。また、Llama や StarCoder といったゲート付きモデルには、Hugging Face のトークンを使用して -e HUGGING_FACE_HUB_TOKEN=<token> を指定する必要があります。
コンテナを実行できたら、TGI エンドポイントにリクエストを送信して、サービスが動作していることを確認します。

レスポンスが出力されれば、LLM が正常に動き、インテル® Gaudi® 2 アクセラレーター上で高性能の推論を実行できるということです。
インテル® Gaudi® 2 アクセラレーターに実装するこの TGI コンテナは、デフォルトで bfloat16 データ型を使用します。スループットを引き上げるには、FP8 量子化を有効にすることをお勧めします。テスト結果から、FP8 量子化によって、BF16 と比較してスループットが 1.8 倍になることが分かっています。FP8 については、README ファイルの説明を参照してください。
最後に、Meta の Llama Guard モデルを使用して、コンテンツ・モデレーションを有効にします。Llama Guard をインテル® Gaudi® アクセラレーター実装の TGI で展開する手順については、README ファイルを参照してください。
<RAG サービスを実行する>
RAG アプリケーションのバックエンド・サービスを起動するには、以下の手順に従います。server.py は、fastAPI を使用してサービス・エンドポイントを定義するスクリプトです。
インテル® Gaudi® 2 アクセラレーター実装の TGI エンドポイントは、デフォルトでポート 8080 (つまり http://127.0.0.1:8080) の localhost での実行を想定しています。別のアドレス / ポートで実行する場合は、環境変数 TGI_ENDPOINT を適宜設定してください。
<RAG GUI を起動する>
以下の手順に従って、フロントエンドの GUI コンポーネントをインストールします。

次に、localhost の IP アドレス (127.0.0.1) を GUI が実行されるサーバーの実際の IP アドレスに置き換えて、.env ファイル内の環境変数 DOC_BASE_URL を更新します。
以下のコマンドを実行して必要な依存関係をインストールします。

最後に、以下のコマンドを実行して GUI サーバーを起動します。

これでフロントエンドのサービスが実行され、アプリケーションが起動します。
<ベンチマーク結果>
さまざまなモデルと構成で徹底的な検証を行いました。以下の 2 つの図は、同時ユーザー数 16 人の Llama2-70B モデルを実行した場合の相対エンドツーエンド・スループットと 1 ドル当たりのパフォーマンスを、4 基のインテル® Gaudi®2 アクセラレーターを搭載したプラットフォームと 4 基の NVIDIA H100 プロセッサーを搭載したプラットフォームとで比較したものです。
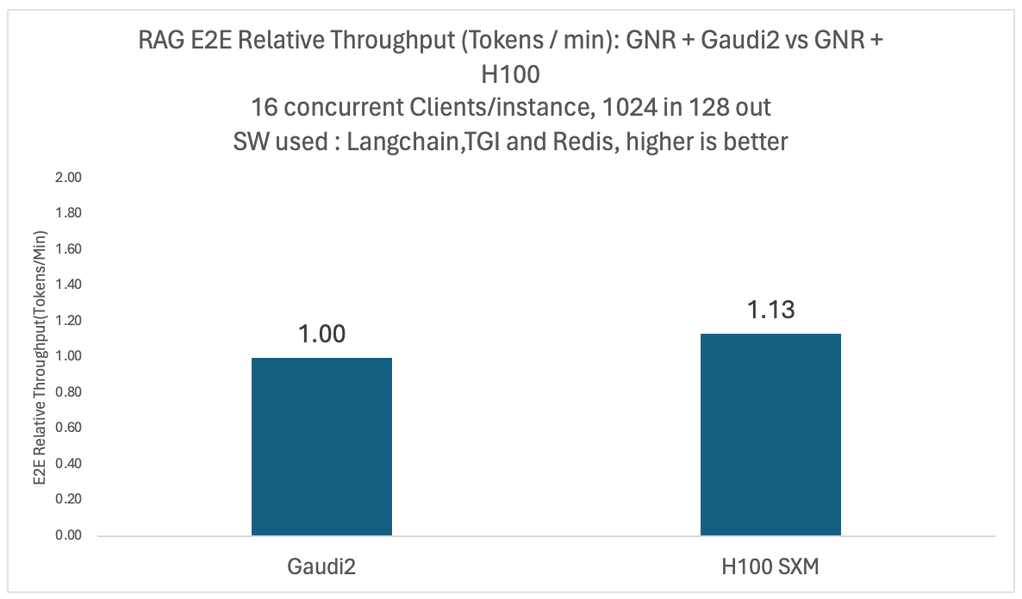
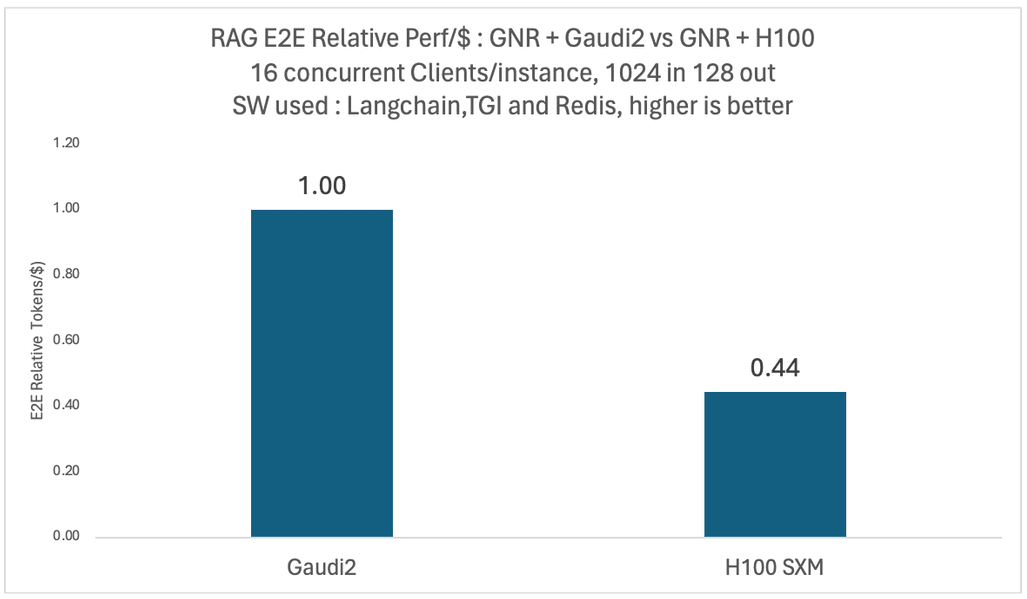
どちらのケースも、ベクトル型データベースと埋め込みモデルには同じインテル® Xeon® 6 プロセッサー (P-cores 採用) 搭載プラットフォームを使用しました。1 ドル当たりのパフォーマンスの比較については、2024年1月の MosaicML チームによる報告と同様に、公開されている価格をもとに 1 ドル当たりの平均トレーニング性能を算出しています。
図から分かるとおり、NVIDIA H100 ベースのシステムは 1.13 倍のスループットを示しているものの、1 ドル当たりのパフォーマンスはインテル® Gaudi® 2 アクセラレーターと比較して 0.44 倍となっています。なお、これらの比較結果は、クラウド・プロバイダーごとに個々の顧客へ提供される割引設定によって異なる場合があります。ベンチマーク構成の詳細は、このページの最後にまとめたリストを参照してください。
<まとめ>
ここで紹介した実装例は、インテルのプラットフォーム上で RAG ベースのチャットボットを問題なく展開できることを実証しています。さらに、インテルはすぐに展開できる生成 AI のサンプルを継続的に公開しているため、開発者は検証済みのツールを活用して、開発や展開のプロセスをスムーズに進めることができます。このようなサンプルの提供によって汎用性が高まり、カスタマイズの複雑さが解消され、インテルのプラットフォームを幅広い用途に展開するうえで最適な手段となっています。
エンタープライズ向け AI アプリケーションを実行する場合、インテル® Xeon® 6 プロセッサー (P-cores 採用) とインテル® Gaudi® 2 アクセラレーターを搭載したシステムは、総保有コスト (TCO) の面で優位性があります。また、FP8 最適化を適用することで、さらなる改善が見込まれます。
以下の開発者向けリソースも、生成 AI プロジェクトの開始に弾みをつけてくれるはずですので、ぜひご活用ください。
•OPEA 生成 AI サンプル •インテル® Gaudi 2 アクセラレーターへの Text Generation Inference (TGI) の実装 •インテルの AI マシンラーニング (AIML) エコシステム: Hugging Face •Hugging Face ハブ: インテルのメンバーページ
質問やフィードバックも歓迎です。Hugging Face forum から回答します。最後までお読みいただき、ありがとうございました。
協力: インテル® Gaudi® 2 アクセラレーターを活用したエンタープライズ向け RAG システムの構築に多大な貢献をしてくれた Chaitanya Khened、Suyue Chen、Mikolaj Zyczynski、Wenjiao Yue、Wenxin Zhang、Letong Han、Sihan Chen、Hanwen Cheng、Yuan Wu、Yi Wang に感謝。
【ベンチマーク構成】
•インテル® Gaudi® 2 アクセラレーター搭載プラットフォームの構成: インテル® Gaudi®2 アクセラレーター搭載 HLS リファレンス・サーバー (8x インテル® Gaudi® 2 アクセラレーター HL-225H メザニンカード、2x インテル® Xeon® Platinum 8380 プロセッサー @2.30GHz、システムメモリー 1TB、OS: Ubuntu 22.04.03, 5.15.0 kernel)
•NVIDIA H100 SXM プラットフォームの構成: Lambda Labs インスタンス gpu_8x_h100_sxm5 (8x H100 SXM、2x インテル® Xeon® Platinum 8480 プロセッサー @2GHz、システムメモリー 1.8TB、OS: ubuntu 20.04.6 LTS, 5.15.0 kernel)
•インテル® Xeon® プロセッサー: 製品出荷前のインテル® Xeon® 6 プロセッサー (P-cores 採用) 搭載プラットフォーム、2 ソケット構成、120 コア @1.90GHz、8,800 MCR DIMM、システムメモリー 1.5TB。OS: Cent OS 9, 6.2.0 kernel
•Llama2 70B モデルを 4 カードに実装 (クエリーは 8 カードに正規化)。インテル® Gaudi® 2 アクセラレーターは BF16、NVIDIA H100 は FP16 で実行。
•埋め込みモデル: BAAI/bge-base v1.5。テスト構成: TGI-gaudi 1.2.1、TGI-GPU 1.4.5 Python 3.11.7、Langchain 0.1.11、sentence-transformers 2.5.1、langchain benchmarks 0.0.10、redis 5.0.2、cuda 12.2.r12.2/compiler.32965470 0、TEI 1.2.0。
•RAG クエリー: 最大入力長 1,024、最大出力長 128。テスト用データセット: langsmith Q&A。同時クライアント数 16。
•インテル® Gaudi® 2 アクセラレーター (70B) の TGI パラメーター: batch_bucket_size=22、prefill_batch_bucket_size=4、max_batch_prefill_tokens=5102、max_batch_total_tokens=32256、max_waiting_tokens=5、streaming=false
•NVIDIA H100 (70B) の TGI パラメーター: batch_bucket_size=8、prefill_batch_bucket_size=4、max_batch_prefill_tokens=4096、max_batch_total_tokens=131072、max_waiting_tokens=20、max_batch_size=128、streaming=false
•総保有コスト (TCO) の参照元: https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators/ (英語)
Discussion