Security Command Center 検出結果を定期レポート化する
はじめに
クラスメソッド Google Cloud Advent Calendar 2025 - Adventar 13日目の記事です。
Security Command Center の検出項目を継続的にエクスポートする方法には、主に次の 2つのアプローチがあります。
- Pub/Sub Notification
- BigQuery Export
前者はリアルタイム通知に適しており、後者は定期的なレポート作成に向いています。
本記事では、後者である BigQuery Export を活用したレポート生成のアプローチについてご紹介します。
登場人物
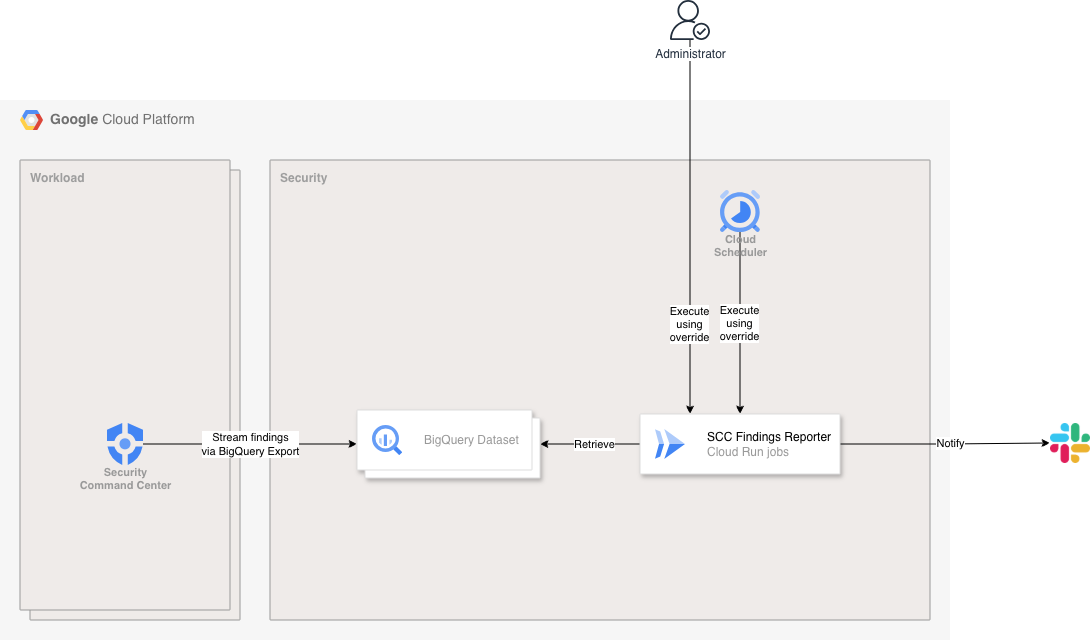
- Security Command Center
- 新しい検出項目が検知されたら、BigQuery Export を経由し BigQuery Dataset へ検出項目をストリーミングする
- BigQuery Dataset
- 検出項目が格納される
- SCC Findings Reporter (Cloud Run jobs)
- 検出項目を取得し、重複などを除外した内容を Slack に通知する
- Cloud Scheduler
- 自動実行を実施する
- Cloud Run jobs の環境変数オーバーライドを利用
- 自動実行を実施する
- Administrator
- 手動実行を実施する(自動実行が失敗した時のワークアラウンド)
- Cloud Run jobs の環境変数オーバーライドを利用
- 手動実行を実施する(自動実行が失敗した時のワークアラウンド)
やること
BigQuery Dataset を作成する
Security Command Center のデータ所在地[1]を有効化していない場合、デフォルトで global に配置されます。そのため、今回 BigQuery と連携させる際の Dataset ロケーションも、互換性を考えて US にしておくのが無難です。
また、BigQuery Dataset の粒度(どの階層で分けるか)は、Project や Folder の構成に合わせて作っておくと、後からアクセス制御や管理がしやすくなると思います。
resource "google_bigquery_dataset" "scc_findings" {
project = var.security_project_id
location = "US"
dataset_id = "scc_findings_for_workload_fldr"
}
SCC BigQuery Export を作成する
Security Command Center で検出された項目を BigQuery にエクスポートする際は、まずどの結果を対象にするかフィルタリングを設定します。
ここではシンプルに、ステータスが ACTIVE のもの、かつミュートされていない検出項目だけに絞る構成にしました。必要な情報だけを BigQuery に取り込みたいため、この条件が扱いやすいと思います。
resource "google_scc_project_scc_big_query_export" "findings" {
project = var.workload_project_id
big_query_export_id = "${var.environment}-scc-bqe-${var.workload_project_id}"
description = "Export Security Command Center findings to BigQuery"
dataset = data.google_bigquery_dataset.scc_findings.id
filter = "state=\"ACTIVE\" AND NOT mute=\"MUTED\""
}
BigQuery Export 用サービスアカウント(service-org-ORGANIZATION_ID@gcp-sa-scc-notification.iam.gserviceaccount.com)は、エクスポート設定ごとに作られるものではなく、組織単位で共通の 1つのアカウントです。さらに、BigQuery データセットレベルで BigQuery データ編集者(roles/bigquery.dataEditor)のロールが付与されるので、カスタム IAM ロールバインドを設定する必要はありません。
Cloud Run jobs を作成する
BigQuery Dataset の粒度によって、TARGET_PROJECT_IDS 環境変数に含めるべき対象プロジェクトが変わってきます。
resource "google_cloud_run_v2_job" "scc_findings_reporter" {
name = "${var.environment}-job-scc-findings-reporter"
location = var.region
template {
parallelism = 10
task_count = 1
template {
containers {
image = data.google_artifact_registry_docker_image.scc_findings_reporter.self_link
env {
name = "TARGET_PROJECT_IDS"
value = join(",", var.target_project_ids)
}
env {
name = "SCC_FINDINGS_BQ_DATASET_ID"
value = google_bigquery_dataset.scc_findings.dataset_id
}
env {
name = "SLACK_WEBHOOK_URL"
value_source {
secret_key_ref {
secret = data.google_secret_manager_secret.slack_webhook_scc_findings.secret_id
version = "latest"
}
}
}
resources {
limits = {
cpu = "1"
memory = "512Mi"
}
}
}
timeout = "300s"
max_retries = 1
service_account = data.google_service_account.job_scc_findings_reporter.email
}
}
}
Cloud Run jobs を実装する
データの集計期間は、JST を基準に「日報・月報・全期間」あたりを選べるようにします。
def calculate_period_range(aggregation_period: enum.AggregationPeriod) -> tuple[datetime, datetime]:
jst_tz = ZoneInfo("Asia/Tokyo")
if aggregation_period == enum.AggregationPeriod.DAILY:
now_jst = datetime.now(jst_tz)
end_period = now_jst.replace(hour=0, minute=0, second=0, microsecond=0)
start_period = end_period - timedelta(days=1)
elif aggregation_period == enum.AggregationPeriod.MONTHLY:
now_jst = datetime.now(jst_tz)
end_period = now_jst.replace(day=1, hour=0, minute=0, second=0, microsecond=0)
if end_period.month == 1:
start_period = end_period.replace(year=end_period.year - 1, month=12)
else:
start_period = end_period.replace(month=end_period.month - 1)
else:
start_period = datetime(1970, 1, 1, 0, 0, 0, tzinfo=ZoneInfo("UTC"))
end_period = datetime.now(ZoneInfo("UTC"))
return start_period, end_period
↑ で決められたデータの集計期間をもとに Security Command Center の検出項目をクエリします。
- クエリパラメータの使用
- 意図しない SQL インジェクションを防ぐ
- 配列パラメータ[2]と UNNEST 検索条件
- リスト型のデータをスムーズにクエリに渡す
def fetch_scc_findings(
start_period: datetime, end_period: datetime, severity: enum.FindingSeverity
) -> list[SecurityCommandCenterFinding]:
severities = enum.FindingSeverity.hierarchy(severity)
sql = """
SELECT
finding.severity,
finding.finding_class,
finding.category,
resource.display_name AS resource_name
FROM
findings
WHERE
event_time >= @start_period AND event_time < @end_period
AND finding.severity IN UNNEST(@severities)
AND finding.state = 'ACTIVE'
AND resource.project_display_name IN UNNEST(@target_project_ids)
ORDER BY event_time ASC
"""
job_config = bigquery.QueryJobConfig(
default_dataset=bigquery.DatasetReference(
settings.security_project_id,
settings.scc_findings_bq_dataset_id,
),
query_parameters=[
bigquery.ScalarQueryParameter("start_period", "TIMESTAMP", start_period),
bigquery.ScalarQueryParameter("end_period", "TIMESTAMP", end_period),
bigquery.ArrayQueryParameter("severities", "STRING", severities),
bigquery.ArrayQueryParameter("target_project_ids", "STRING", settings.target_project_ids),
]
)
rows = bq_client.query_and_wait(sql, job_config=job_config)
return [
SecurityCommandCenterFinding.model_validate(dict(row)) for row in rows
]
Slack への通知は、Slack SDK の WebhookClient を使えば簡単に実装できます。ただし、Block を都度 dict 型で作成する必要があるため、少し手間がかかる場面があります。
slack_wh_client = WebhookClient(url=settings.slack_webhook_url)
...
def main() -> None:
...
blocks = build_slack_blocks(aggregation_period, findings)
logger.debug(f"Built Slack blocks: {blocks}")
res = slack_wh_client.send(
blocks=blocks,
)
if res.status_code != 200:
logger.error(f"Failed to send Slack message: {res.body}")
raise Exception(f"Slack message sending failed: {res.body}")
logger.info("Completed Task.")
Cloud Scheduler を作成する
Cloud Run jobs は環境変数のオーバーライド(上書き)[3]に対応しているため、環境ごとに Cloud Scheduler を用意すれば、異なる条件(例、データの集計期間)で Slack に通知する内容を調整できます。
resource "google_cloud_scheduler_job" "scc_findings_daily_report" {
name = "${var.environment}-scc-findings-daily-report"
description = "Daily report of SCC findings to Slack"
time_zone = "Asia/Tokyo"
schedule = "0 9 * * *"
attempt_deadline = "600s"
http_target {
http_method = "POST"
headers = {
"Content-Type" = "application/json"
}
uri = "https://run.googleapis.com/v2/projects/${google_cloud_run_v2_job.scc_findings_reporter.project}/locations/${google_cloud_run_v2_job.scc_findings_reporter.location}/jobs/${google_cloud_run_v2_job.scc_findings_reporter.name}:run"
# See https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs/run#Overrides
body = base64encode(<<EOT
{
"overrides": {
"containerOverrides": [
{
"env": [
{
"name": "AGGREGATION_PERIOD",
"value": "Daily"
},
{
"name": "SEVERITY",
"value": "Medium"
}
]
}
]
}
}
EOT
)
oauth_token {
service_account_email = data.google_service_account.sched_scc_findings_reporter.email
}
}
}
動作確認
自動実行(Cloud Scheduler 経由)
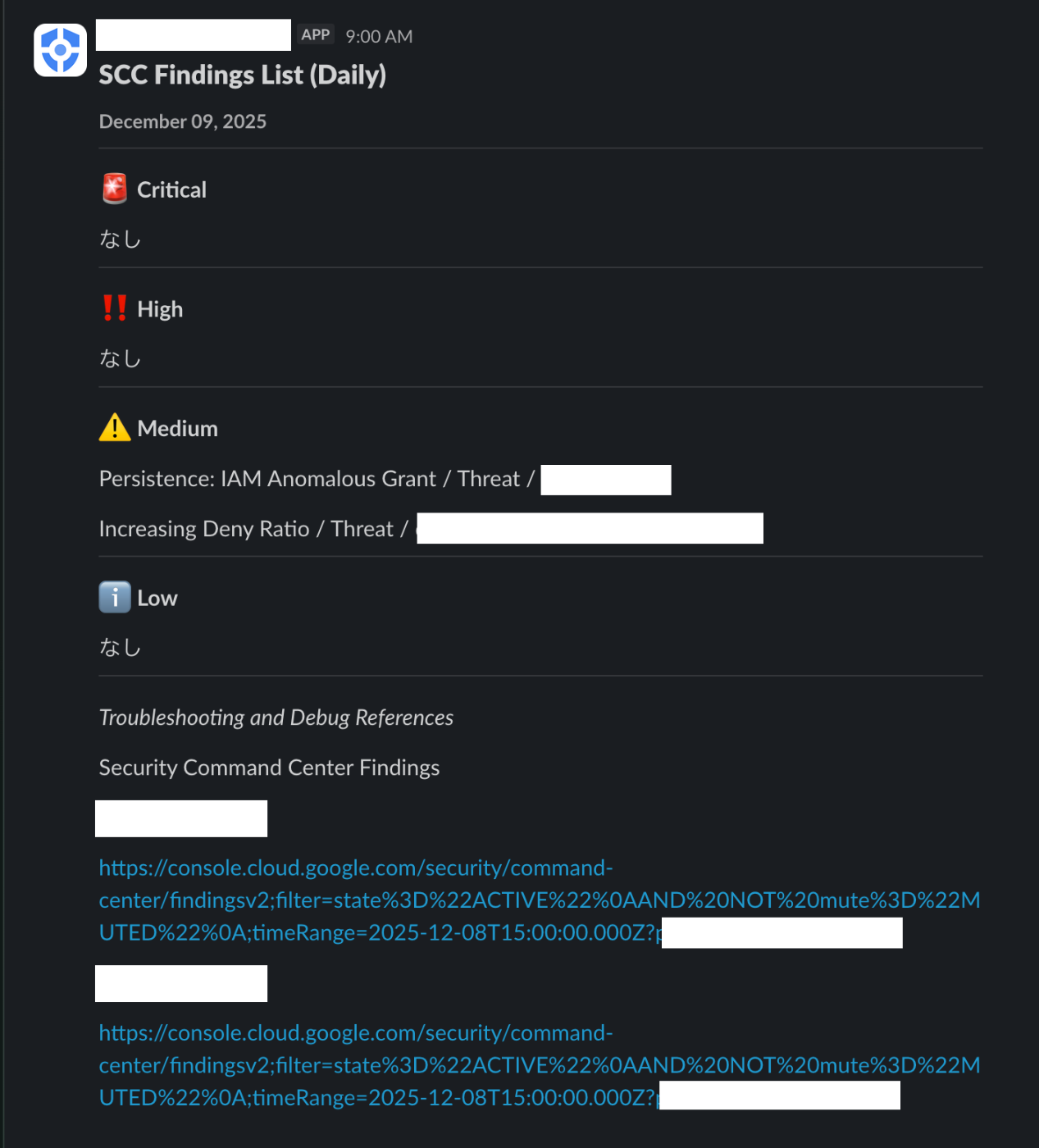
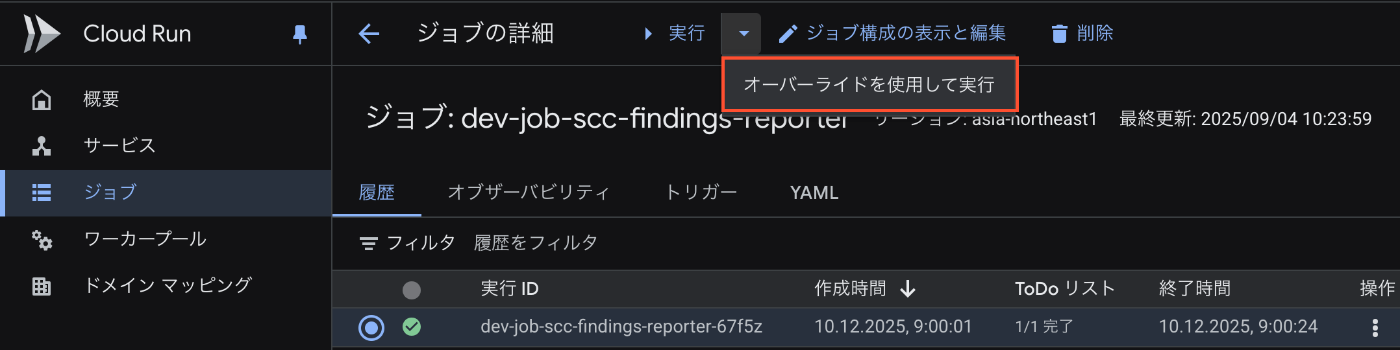
手動実行(Google Cloud コンソール)
同じ条件で単純にリトライしたい場合は、Cloud Scheduler のコンソールで該当リソースを選択し、「強制実行」をクリックすれば OK です。

一方、実行条件を変更したい場合は、Cloud Run jobs のコンソールにある「オーバーライドを使用して実行」を利用すると便利です。
まとめ
Security Command Center の BigQuery Export を活用し、検出項目を別プロジェクトに集約したうえで、定期的にその内容を Slack へ通知する一連の仕組みを構築してみました。なお、過去の検出項目はストリーミングの対象外となるため、アプリケーション実装前に BigQuery Export だけ先行リリースしておくのは一つの Tip です。
Security Command Center を利用している環境では、検出項目のレポーティング需要は確実に存在するため、Cloud Build Notifiers[4]のようにパッケージ化できれば、より汎用的に使える仕組みになるのではないかと思います。
おまけ
いつの間にか BigQuery Bulk Export[5]という機能が登場していました。これを使えば、過去の検出項目も BigQuery に取り込めます。既存の BigQuery Export と組み合わせることで、過去データもバッチリレポート対象としてカバーできそうです。
-
https://docs.cloud.google.com/security-command-center/docs/data-residency-support#security-command-center-locations ↩︎
-
https://docs.cloud.google.com/bigquery/docs/parameterized-queries#using_arrays_in_parameterized_queries ↩︎
-
https://docs.cloud.google.com/run/docs/execute/jobs#override-job-configuration ↩︎
-
https://docs.cloud.google.com/build/docs/configuring-notifications/notifiers ↩︎
-
https://docs.cloud.google.com/security-command-center/docs/bulk-exports-to-big-query ↩︎
Discussion