この記事はポート株式会社 サービス開発部 Advent Calendar 2025の4日目の記事です。
ポート株式会社で新卒3年目のinit-ikuyaです。大学では物理学を学んで、研究では素粒子実験の解析にCNN系の深層学習モデルを使ったりしていた者です。
今回はCNN系とは関わりがないですが、同じく生成AI関連である音声合成系のソフトウェア GPT-SoVITSを使ってみようと思います。
音声合成とは
ここ2年くらいでYouTubeで爆増しましたよね、ずんだもん動画。端的に言ってアレです。

自分が社会人になると同時に流行り始めた印象あります
音声合成系のフリーのソフトウェアとして人気が高いのがVOICEVOXです。僕も会社のLTなどでパワポに音声を入れたりする時にお世話になっています。
VOICEVOXでは(詳しくはないので恐らくですが)提供された声優さんの音声サンプルをベースに事前に学習されたモデルを利用することで、任意のテキストを、ずんだもんをはじめとした色んなキャラクターの音声で再生することができます。
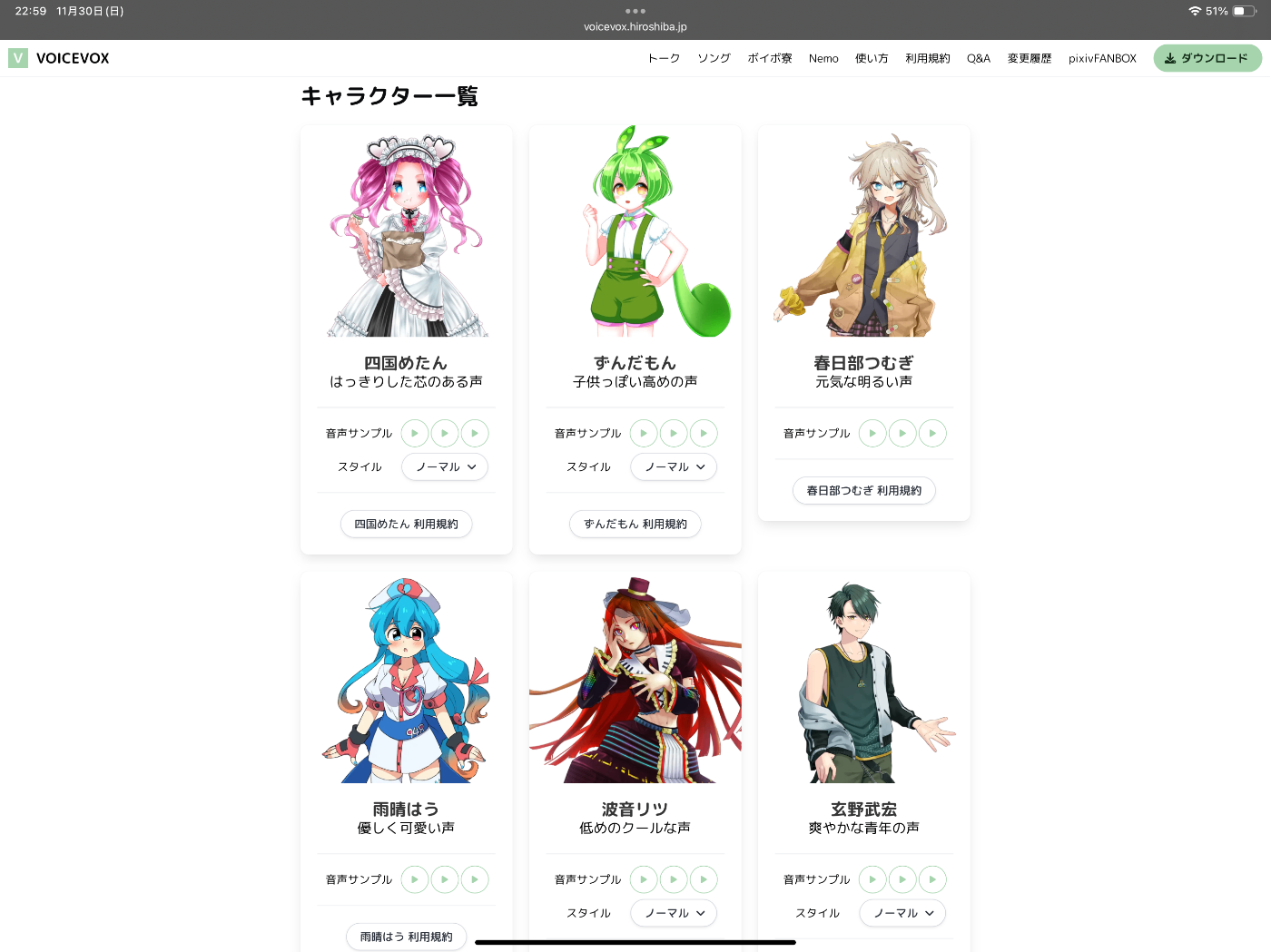
もっと多くのキャラクターが使えます。これも3年くらい前は数人しかいなかった記憶なのですが
(ちなみに、筆者はハイパー埼玉ギャルの春日部つむぎちゃんが推しです。筆者は埼玉県民なので、埼玉県出身という設定の彼女を推すのは当たり前で、ギャル女子高生が好きとかそういうんでは全くないんですよね(早口)
ところで、このVOICEVOXでは、事前にVOICEVOXさんの公式が学習しておいてくれた声優さんの音声を使ってテキストを音声にすることはできますが、たとえば「弊社の社長の音声を使いたいな」とか「俺が超頑張って出したイケボを元に音声を再生したいな」とか思う場合は、何か別の方法を考えなければなりません。
そこで候補に上がってくるのが、GPT-SoVITSです。
GPT-SoVITS とは
GPT-SoVITSとは、こちらのリポジトリで管理されている、音声合成系のプロジェクトです。1分程度のわずかな音声サンプルからでもそれなりな音声合成を実施できます。
特にWeb UIがかなり細かく作り込まれていて、使いやすそうです。(ただし、詳しくないと設定項目が多すぎて何が何やら分からないレベル)
以下では、Google Colab上でこちらのレポジトリをコピーして動かすことを試みます
Google Colabでの環境構築
Google Colabとは、言わずと知れたPythonのオンライン上の実行環境です。自分の環境を汚さずに、ちょっと概念実証してみたいな、とか思った時に有用ですよね。
GitHub のリポジトリからGoogle Colabのプロジェクトを作成することが可能ですので、それをやってしまいましょう。Google Colabのプロジェクト新規作成画面でソース元にGitHubのプロジェクトを指定します。
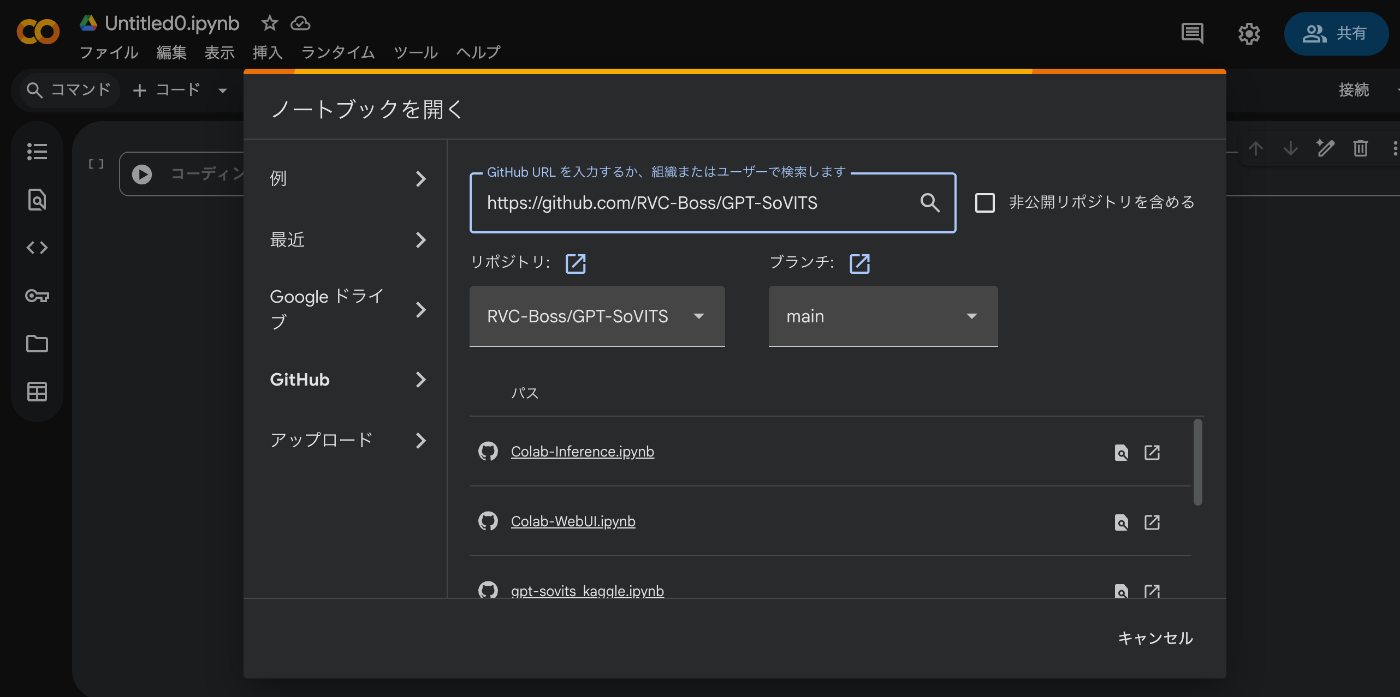
2025年12月1日現在では、GPT-SoVITS内にGoogle Colab上で利用できるノートブックが3つ存在しますが、Web UIの方を選択して、プロジェクトを新規作成します
ノートブックは以下の3つのセルから構成されているので、順番に実行します
- 環境のセットアップ
- conda環境のセットアップ。依存性のインストールなど
(ここの実行は割と時間がかかるので根気よく待ちます - Web UIの起動
Web UIのサーバにアクセスするためのURLがセルの実行ログに流れていればOKです
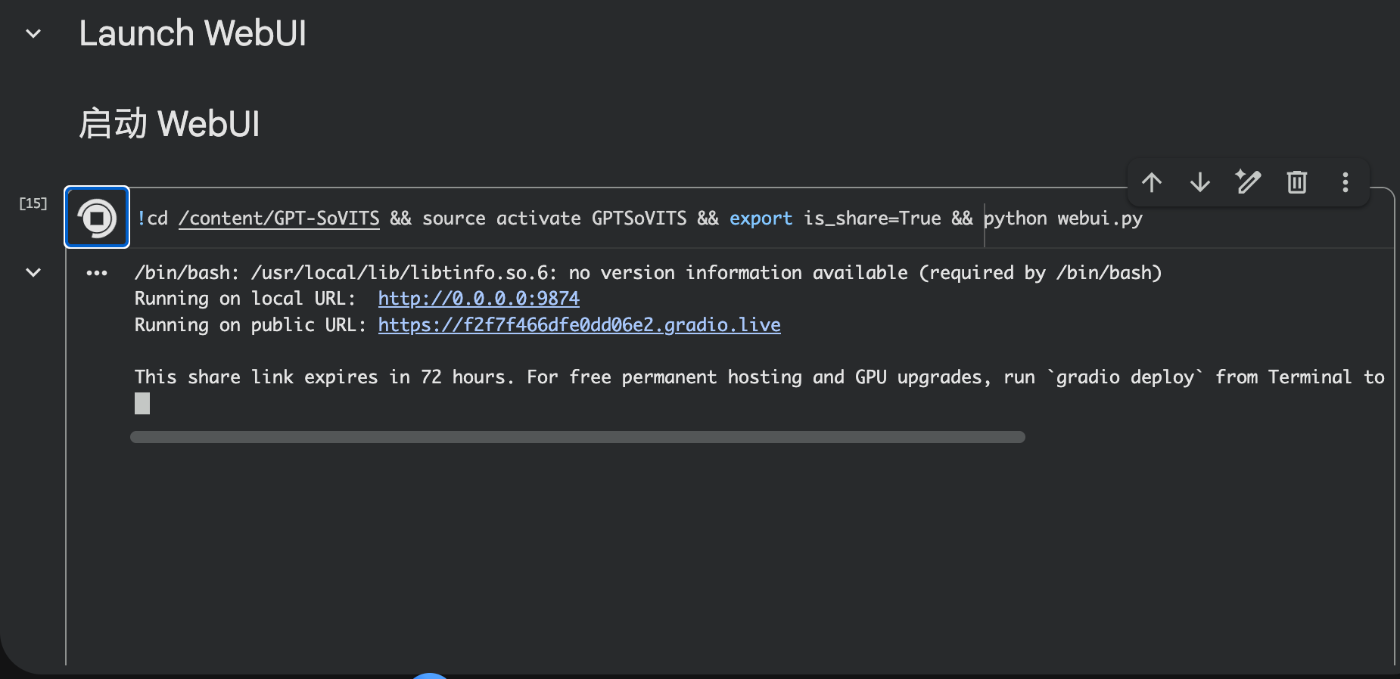
Colab環境だとRunning on public URLからWeb UIにアクセスできます
Web UI をいじってみる
実行ログに表示されるURLにアクセスすると、Web UIが表示されます。何やら色々知らない単語が出てきて困惑するかも知れません。(筆者は最初困惑しました)
必要そうなところを少しずつ調べていきましょう
1-GPT-SOVITS-TTSタブを選択すると下に更にタブが現れるので、1C-Inferenceタブを選択
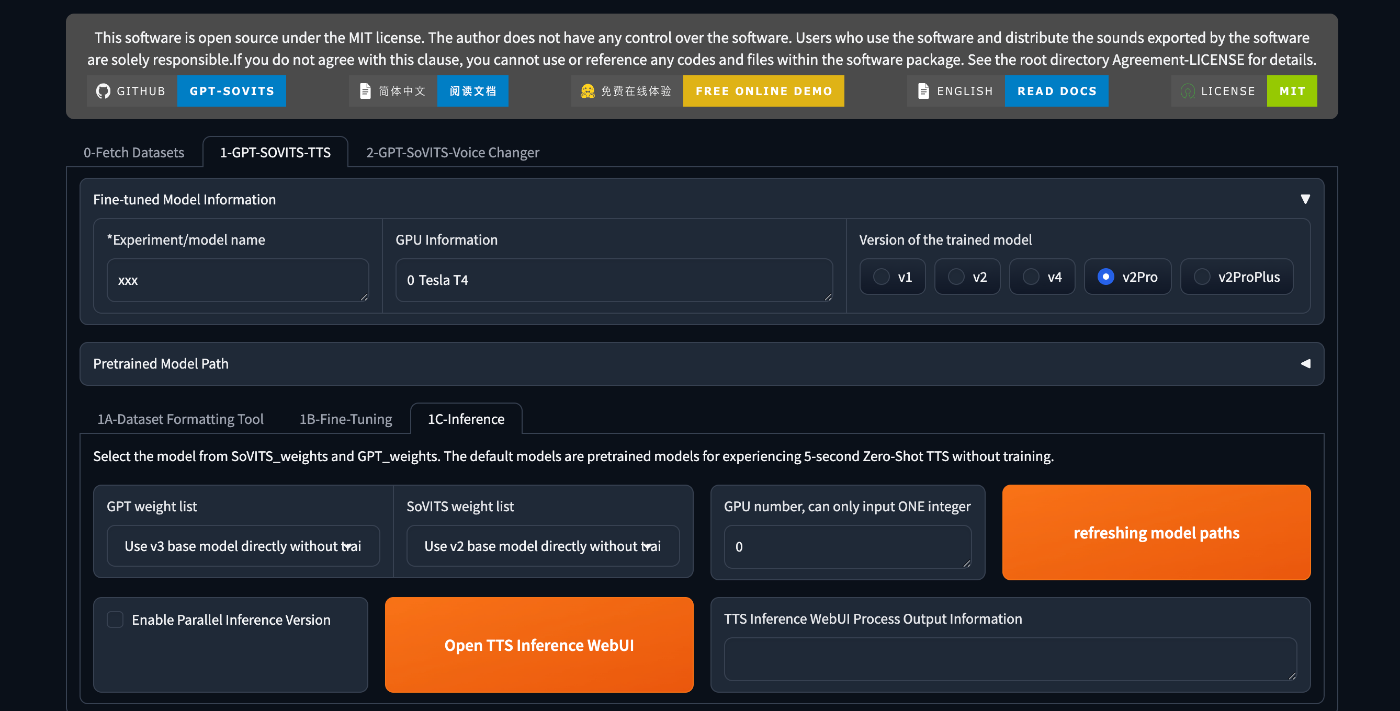
Open TTS Inference WebUIをクリックします。すると先ほどと同様にColabのセルの実行ログにリンクが表示されるのでそれをクリックしましょう
依存関係のエラー
Open TTS Inference WebUIボタンをクリックしてみると、Google Colab上のセルの実行ログでエラーが出ました。(2025/12/01時点)
ModuleNotFoundError: No module named 'transformers.modeling_layers'
Pythonあるあるですが、後方互換性のないバージョンがインストールされてしまっているせいでモジュールが存在しない、と言われてしまっていますね。モジュールが存在するところまでバージョンを戻します
ググってみると、同様のエラーに遭遇しているissueがGitHub上に見つかり、pip install transformers==4.49.0 peft==0.17.0とすれば良さそうなことがわかります。
Colabで愚直に以下のようなセルを作って実行してから、Web UIを起動すると問題なく動きます
# バージョン不整合解消のため
!cd /content/GPT-SoVITS && source activate GPTSoVITS && pip install transformers==4.49.0 peft==0.17.0
TTS inference Web UI について
今更ですが、TTSはText-to-Speechの略ですので、テキストからスピーチの音声を出力するタスクのことを指します。よって、その推論はこの辺のWeb UIをガチャガチャ弄ればできそうだということが想像できます
早速UIを見てみましょう
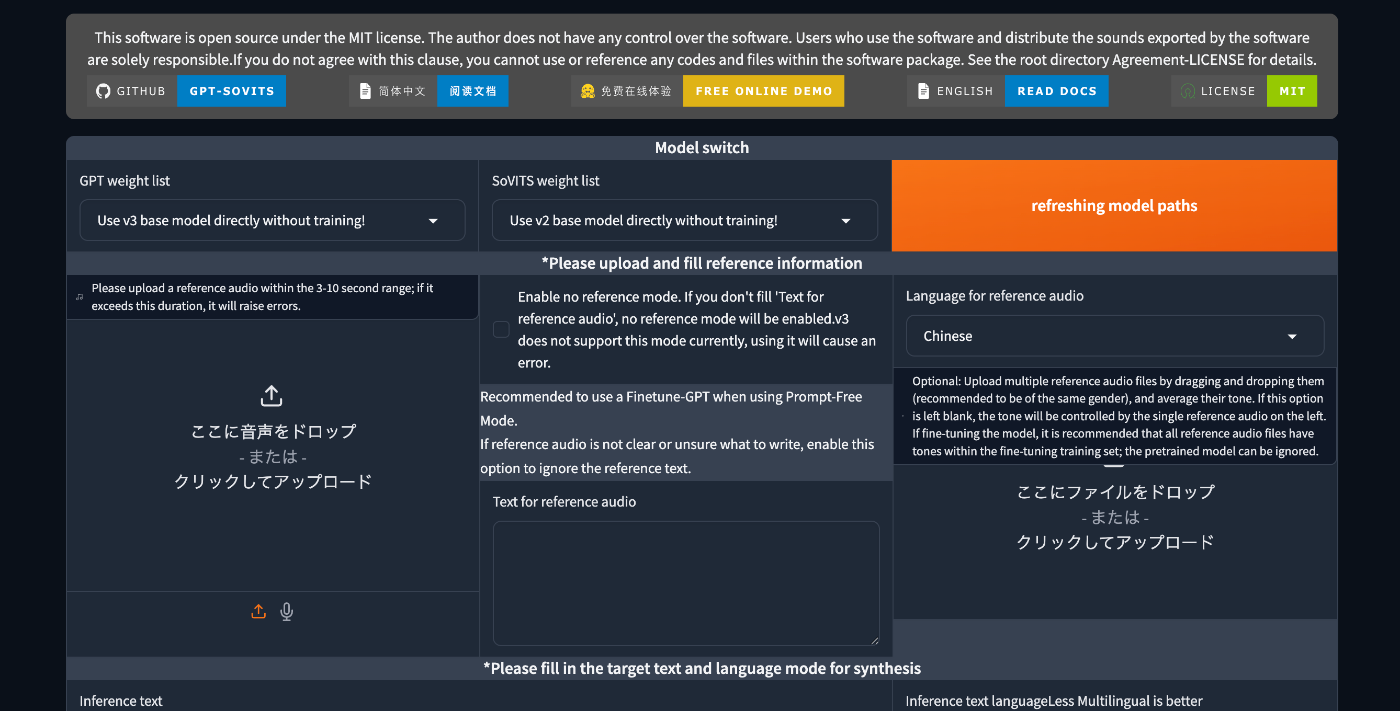
スクショ1枚目
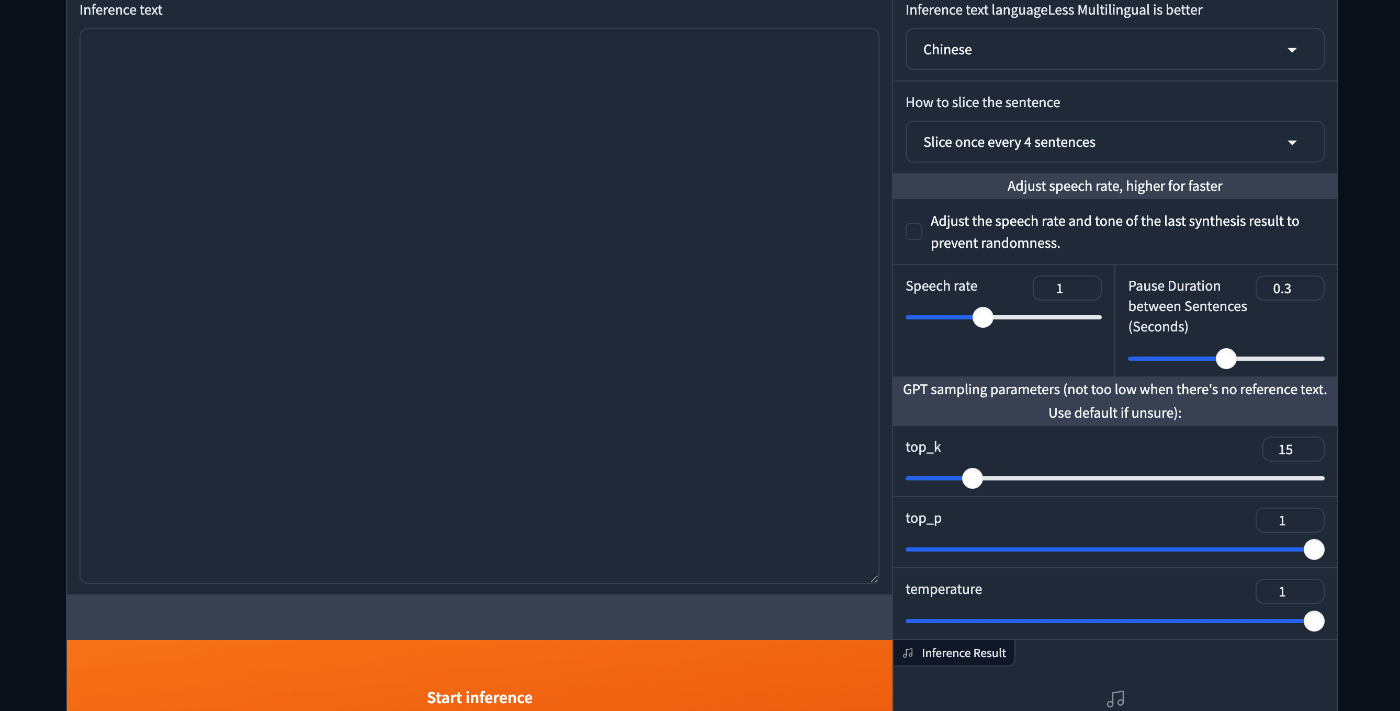
スクショ2枚目
まず、画面の左にreference audioをアップロードしてください、という旨のペインがありますね。たとえば、自分が何かの文を読み上げた時のものなど、3〜10秒のオーディオファイルをアップロードすれば良さそうです
一方、中央のペインにはそこでアップロードしたオーディオファイルに含まれる音声の文字起こしを入力すれば良さそうです
右側にはオーディオファイルの音声の言語を指定する入力部分があります。
また、画面下部には実際に生成したい音声の文字起こしを書き、右側にはその文字の言語を指定します。(Multilingual is betterとあるので、適宜JapaneseにしたりMultilingualにしてみたりすると良さそうです)
テキトーに音声ファイルと文字起こしを用意して、日本語を選択。その声で再生してほしいテキストを入力し、また日本語を選択、最後にページ最下部のStart inferenceをクリックすると、音声合成が始まり、右側に推論結果の音声波形などが表示されます
またしても依存関係のエラー
必要な入力を済ませて、よっしゃStart inferenceボタンをポチッとな、とした直後に、torchcodecが必要だよ、という旨のエラーが出ました
ModuleNotFoundError: No module named 'torchcodec'
これもColabのどこかのセル上で追加してやります
... && pip install torchcodec
上記インストールを実行して、Web UIを再起動、その後先ほどと同様な手続きで音声合成を試みます。すると......?
エラー修正後の音声合成
できました! 確かに、サンプルとして入力した音声と近い雰囲気で、欲しいテキストの音声を得ることができました!

少し待つと、右下に波形や再生ボタン、ダウンロードアイコンなどが表示されます
僕の自分の声をサンプルとして提供した場合
以下は、自分の声をサンプルとして提供した筆者の音声と、その文字起こしです
春日部つむぎはみんなで作りあげるコンテンツです。 思いやりと住み分けをしっかりしてみんなが楽しく創作できるよう心がけましょう!
音声合成モデルには、以下のようなスクリプトを渡しました
おはようございます。今日の天気は晴れです
すると以下のような合成音声が返ってきました。
雰囲気は僕に似ている気もするんですが、僕の声かと言われるとそうは思えない、というくらいの印象を受けますね。
収録環境を変えたり収録後の処理を加えてサンプル音声を綺麗にするともっと僕の声に近づいたりするかもしれません。
声優さんの声をサンプルとして提供した場合
以下は、日本声優統計学会さんのボイスサンプルを拝借してきた場合です。
サンプルの音声自体をここに記載すると音声の再配布にあたる可能性があるため、ここでは音声の記載を控えますが、藤東千夏様の通常音声データ群の35番を使用させていただきました。文字起こしは以下です。
森永の美味しい牛乳は、濃い青色に、牛乳瓶をあしらったデザインの、パック牛乳である
音声合成モデルには、上述と同様に、以下のようなスクリプトを渡しました。
おはようございます。今日の天気は快晴ですね!
すると以下のような合成音声が返ってきました。
僕のものよりは、サンプルで渡した声優さんの面影を残した音声になっていそうですね。流石声優様です。。。
まとめ
いかがでしたでしょうか? 本記事ではGoogle ColabやGPT-SoVITSなど、ほとんどの人が簡単に用意できるようなフリーの環境で、音声合成を試みることができることを紹介しました。
今回は素朴に数秒の音声サンプルを入力して、その後に出力して欲しい音声を得る、という感じでしたが、Web UIを見るにもっと多くのサンプル数を提供したり、モデル自体を複雑にチューニングしていき、より自然な聞こえるようにカスタマイズしていくことも可能なようでした。
僕自身はまだ音声合成周辺内部の技術に詳しくないので、現時点では、より精巧な音声合成をすることは難しいですが、反響があるようであれば、もう少し詳しく深掘りして続編を書いていくのもアリかな、と感じています。
ここまで読んでいただきありがとうございました。弊社の他の社員もアドベントカレンダーを書いておりますので、興味がある方はそちらも訪れていただけますと幸いです。
それでは〜

ポート株式会社は、「社会的負債を、次世代の可能性に。」をパーパスに掲げ、人材領域およびエネルギー領域を主力事業とした事業を展開しています。人材領域では、「キャリアパーク!」「就活会議」「みん就」などのサービスを提供しています。
Discussion