2023 Baseline for Image Recognition Tasks
2023年に論文で比較されることが多いモデルとその性能をまとめて比較しようと思います。
個人的には巨大高精度モデルより、そこそこな速度でそこそこな精度を出してくれるモデル重点で読むことが多いので、今回調べた領域もその辺中心です。
Classification Model
特徴抽出バックボーンネットワークはしばしば tiny / small / base / laerge のパラメータ数区分で比較される。またCNNとViTのハイブリッドモデルの場合はCNN系とViT系で分かち書きされる。
 [1]より引用 最近のSOTAモデルを重視した比較
[1]より引用 最近のSOTAモデルを重視した比較
 [3]より引用
[3]より引用
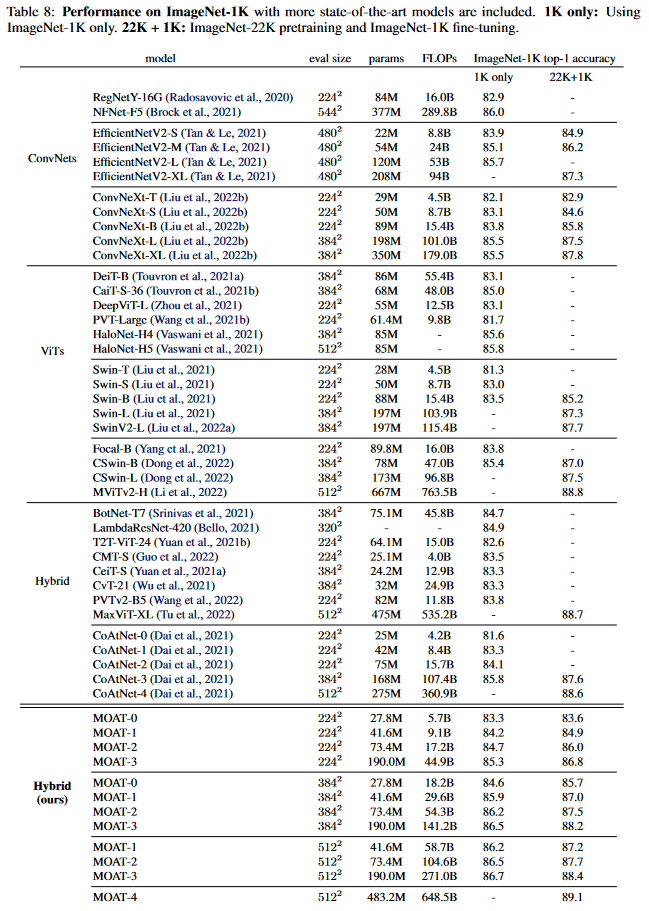 [4]より引用
[4]より引用
ここ数年の経験に一致して、次の比較対象モデルの感覚がある
- ResNet があると数値感がわかりやすい
- NFNet / ResNet RS あたりの少し古いベースライン
- EfficientNet v1 v2 は欲しい (v2が省かれていると恣意的に感じる)
- ConvNeXt はこの1年ベースラインとして非常によく使われている
- DeiT / Swin v1 v2 / PVT あたりのViT改良筋の有力なモデル
- mobileViT 系の高速ViTも半年くらい前から熱い雰囲気がある
- VAN は最近ちょくちょくインスピレーションとして使われている所を見る
- CoAtNet / MaxViT などは巨大なモデルの比較で出てきがち
個人的な感覚ではConvNeXtくらいシンプルで使いやすいサイズのモデルが出てきてくれると使いたくなる。EfficientNet系は解像度方向のスケールを合わせた場合の比較が出てこないとどのくらいの精度が期待できるかわからないので少し忌避しがちになる(実際使った感じいい精度は出るのだが...)
精度重点のモデルでは CoAtNet / MaxViT が 比較対象として定番に扱われている。
Object Detection
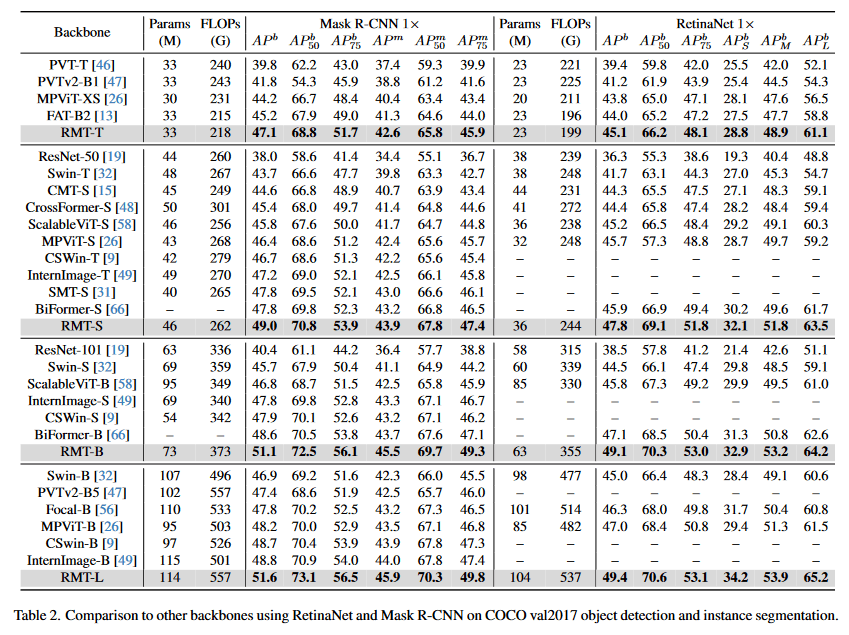 [1]より引用
[1]より引用
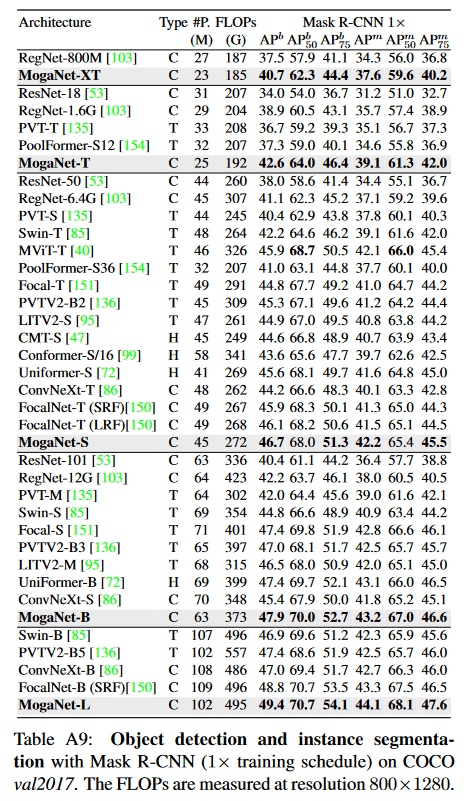 [3]より引用
[3]より引用
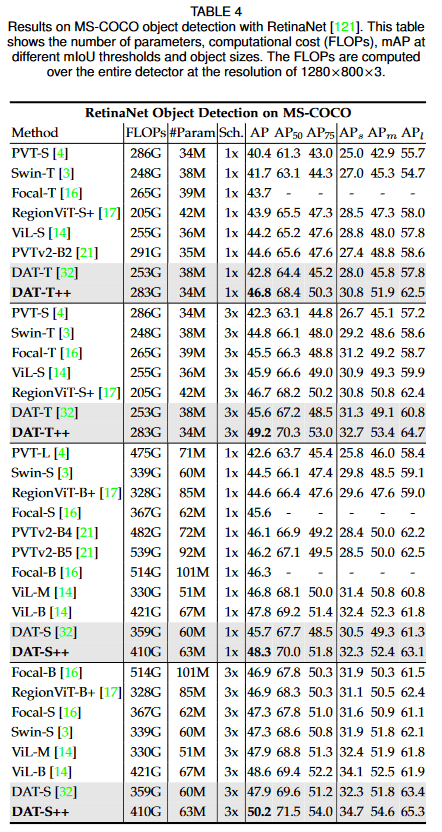 [7]より引用
[7]より引用
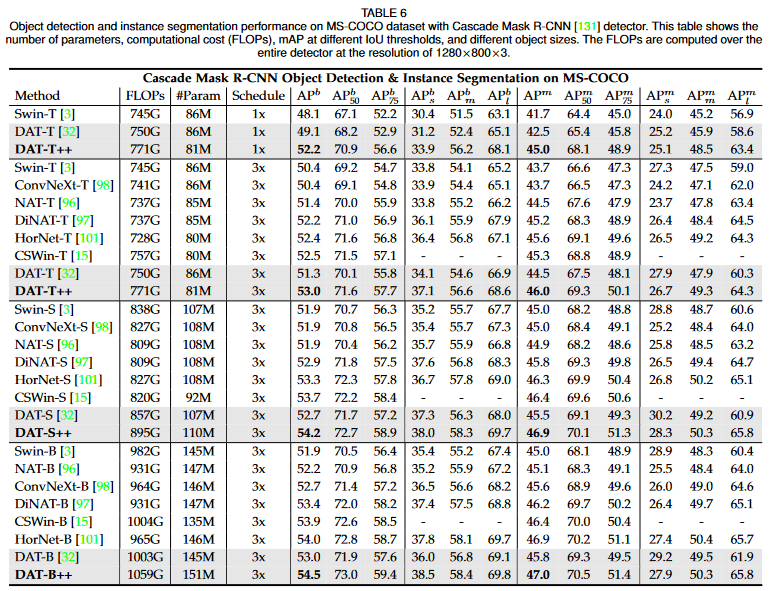 [7]より引用
[7]より引用
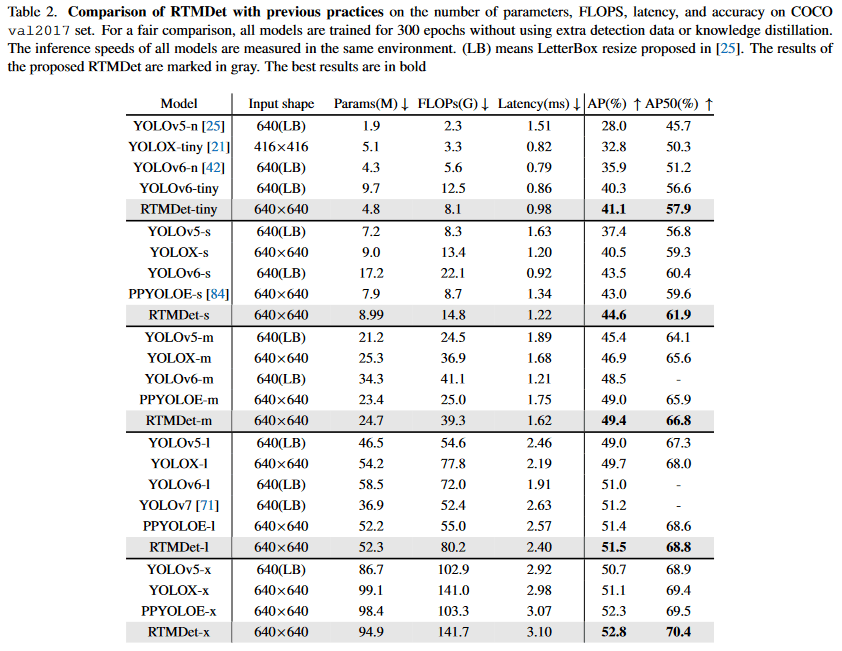 [2]より引用 YOLO系の比較 余談だがライセンス的にYOLO系は使うのが難しいのでRTMDetが最も良いと思っている...
[2]より引用 YOLO系の比較 余談だがライセンス的にYOLO系は使うのが難しいのでRTMDetが最も良いと思っている...
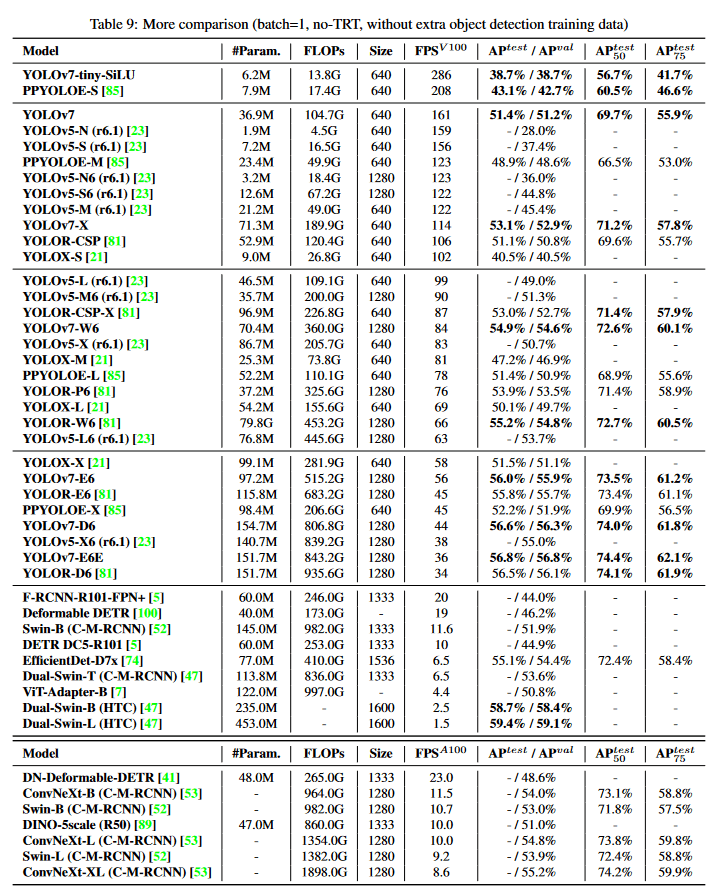 [6]より引用
[6]より引用
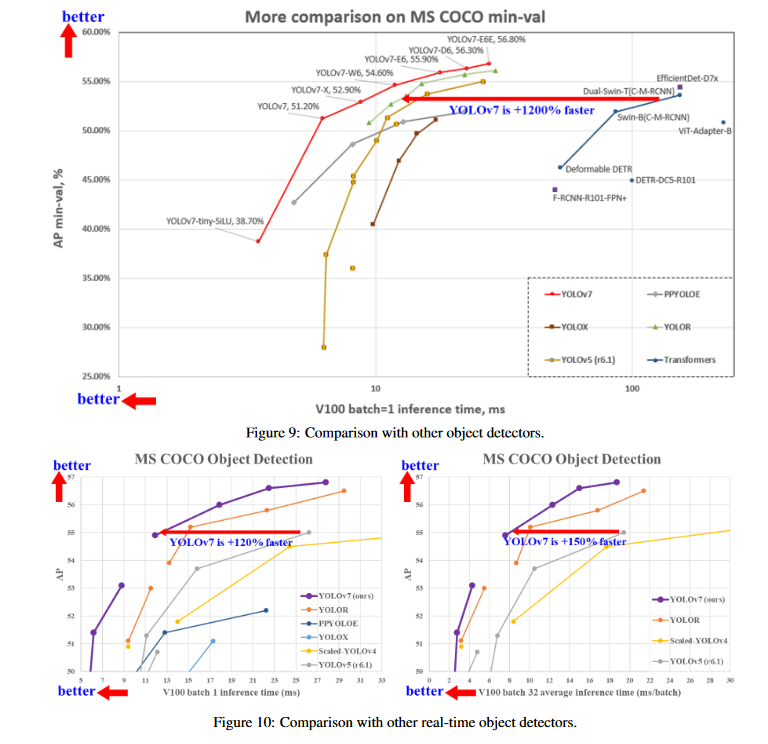 [6]より引用
[6]より引用
YOLOv1~v8の主にアーキテクチャに関するサーベイが出てた
Object Detection系の比較だとYOLOが一番有名だが、逆にその他のベースラインを混ぜたfigはあんまり見ない。v7の表を見てだいぶ数値感などを得たが、高速なバックボーンを使ったモデルとも比較してほしい。
- バックボーンネットワークとしてClassificationの有力なベースラインが使われる
- YOLOだとCSPNetやELANなどのConcatinateベースのブロックがよくある
最近のYOLO系は精度、速度とも非常に良い。リアルタイム性にシビアな現場でなければもうRTMDetでなんでもできるのでは...
Semantic Segmentaion
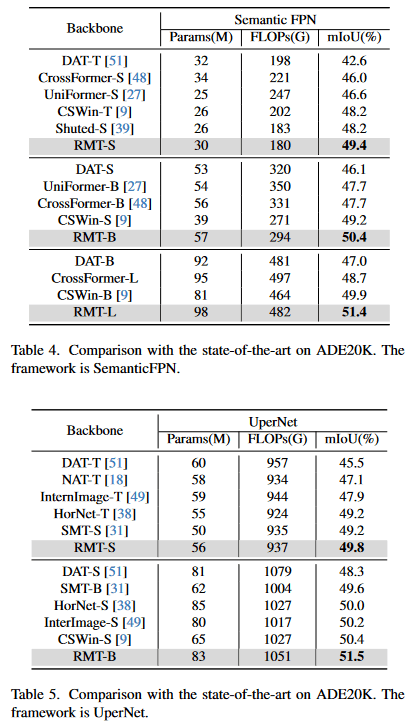 [1]より引用
[1]より引用
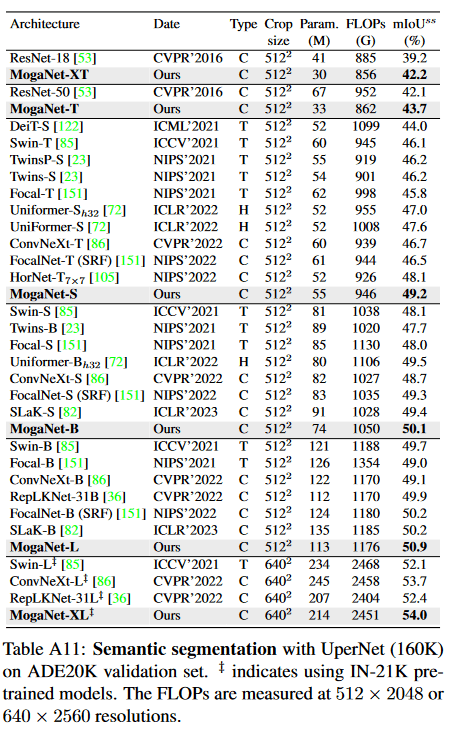 [3]より引用
[3]より引用
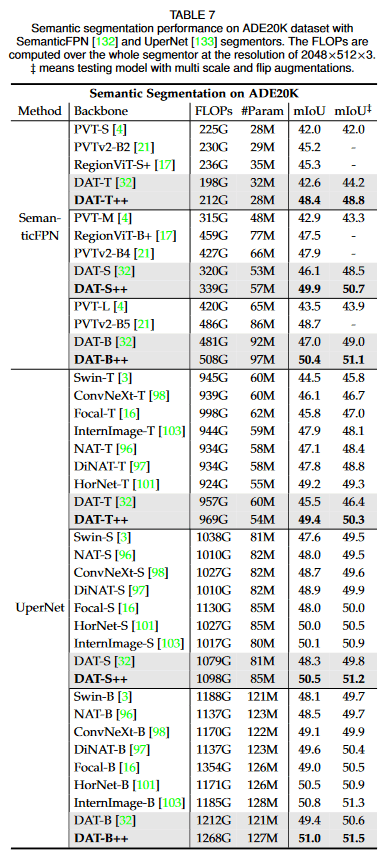 [7]より引用
[7]より引用
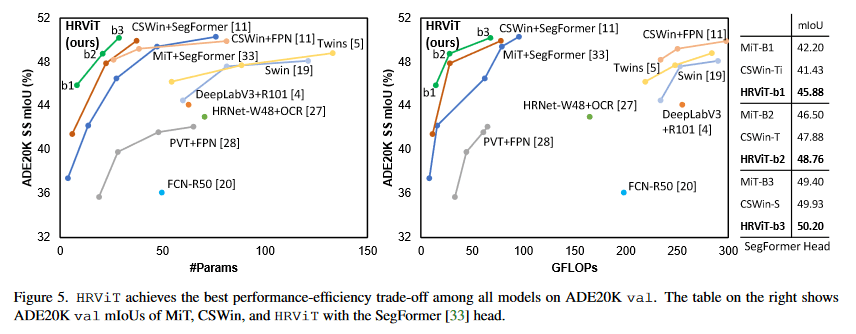 [5]より引用 HRViTは非商用ライセンスなので残念... 近い性能でApache2.0はSegNeXtがある
[5]より引用 HRViTは非商用ライセンスなので残念... 近い性能でApache2.0はSegNeXtがある
古い定番モデルとしてU-NetやDeepLabv3があるが、最近だとSwinTransformer +
SegFormer / Mask2Formerあたりライセンス的にも使いやすいか。
効率の良いモデルだと2021のHRViTが良さげなのだが、もっと新しいモデルでベースラインを更新していないかはよくわからなかった...(精度重点の巨大なモデルでSOTAとかはいくつか合ったのだが)
- DAT / NAT などAttentionの場所を変える感じのバックボーンが人気か
- タスクワークフレームには UperNet などFPN+headの推論
ここ1年間ほどは高効率なモデルやワークフレームで飛び抜けて有力なもの・定番のものは出ていなさそうである。
個人的にはMMsegmentaionでサッと使えるSegNeXtが楽だが、DAT++もかなり良さそう(でも数値以上に重そう)。気になるのはFPNをneckで処理してデコードするスタイルのheadではなく、第二第三スケールの特徴マップをLightHamburgerなどでデコードする方が効率が良いのではと思っている。次の実験ネタとして試してみたい。
感想
画像特徴抽出にはConvNeXtが最もベーシックで効率が良い。
Object DetectionにはYOLO、SegmentationにはViT系+UperNetあたりで良いか。
ResNet以降大量にSOTA更新や新機能のモデルが乱造されており、筆者は論文のチャンピオンモデル比較では真実味が感じられない病を患ってしまっているので、定期的に論文をサーベイして定番のものを追う感じにしている。また、他の著者によってリバイズされるモデルも良いものが多いと思うので、そのへんも眺めるようにしている。
参照
[1] Qihang Fan, Huaibo Huang, Mingrui Chen, Hongmin Liu, Ran He, "RMT: Retentive Networks Meet Vision Transformers" https://arxiv.org/abs/2309.11523
[2] Chengqi Lyu, Wenwei Zhang, Haian Huang, Yue Zhou, Yudong Wang, Yanyi Liu, Shilong Zhang, Kai Chen, "RTMDet: An Empirical Study of Designing Real-Time Object Detectors" https://arxiv.org/abs/2212.07784
[3] Siyuan Li, Zedong Wang, Zicheng Liu, Cheng Tan, Haitao Lin, Di Wu, Zhiyuan Chen, Jiangbin Zheng, Stan Z. Li, "Efficient Multi-order Gated Aggregation Network" https://browse.arxiv.org/abs/2211.03295v2
[4] Chenglin Yang, Siyuan Qiao, Qihang Yu, Xiaoding Yuan, Yukun Zhu, Alan Yuille, Hartwig Adam, Liang-Chieh Chen, "MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models" https://arxiv.org/abs/2210.01820v2
[5] Jiaqi Gu, Hyoukjun Kwon, Dilin Wang, Wei Ye, Meng Li, Yu-Hsin Chen, Liangzhen Lai, Vikas Chandra, David Z. Pan, "Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation" https://arxiv.org/abs/2111.01236
[6] Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao, "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors" https://arxiv.org/abs/2207.02696v1
[7] Zhuofan Xia, Xuran Pan, Shiji Song, Li Erran Li, Gao Huang, "DAT++: Spatially Dynamic Vision Transformer with Deformable Attention" https://arxiv.org/abs/2309.01430