自然言語処理による類似資料のベクトル検索
この記事ではWikipediaから抽出した記事データをBERTによりベクトル化し、検索センテンスにマッチした類似資料のレコメンドが可能かどうか実験します。
前回作ったこれを使います↓
使用するデータとモデル
Data: jawiki_articles.xml
データは以前の記事で作った日本語Wikipediaのテキストを使用する。
データベースの構成はプライマリキーであるpage_idと、その記事のtitle、記事の内容テキストcontentを持つtable article。また記事が属するカテゴリcategoryとそのページID page_idを持つtable categorylinksからなる。
全部を推論してる時間は無いので、今回は300×32本の記事を抽出して変換した。抽出した記事タイトルを見るとほとんどが人名であったため、これでは今回の目的と合致しないと思い大胆にも人物に関わるカテゴリの記事はすべて消した。
--- カテゴリ名が"人"と部分一致する記事を削除
DELETE FROM article WHERE page_id IN (
SELECT page_id FROM categorylinks WHERE category LIKE '%人%'
);
また本来の目的では全文を変換するのだが、時間的な理由で冒頭510tokenのみを扱う。
510tokenは例えば以下の量である。725文字は思ったより多くの情報を取り込めており、検索的にも問題ないと感じた。
アンパサンド アンパサンド(&,)は、並立助詞「…と…」を意味する記号である。ラテン語で「…と…」を表す接続詞 "et" の合字を起源とする。現代のフォントでも、Trebuchet MS など一部のフォントでは、"et" の合字であることが容易にわかる字形を使用している。英語で教育を行う学校でアルファベットを復唱する場合、その文字自体が単語となる文字("A", "I", かつては "O" も)については、伝統的にラテン語の per se(それ自体)を用いて "A per se A" のように唱えられていた。また、アルファベットの最後に、27番目の文字のように "&" を加えることも広く行われていた。"&" はラテン語で et と読まれていたが、のちに英語で and と読まれるようになった。結果として、アルファベットの復唱の最後は "X, Y, Z, and per se and" という形になった。この最後のフレーズが繰り返されるうちに "ampersand" となまっていき、この言葉は1837年までには英語の一般的な語法となった。アンドレ=マリ・アンペールがこの記号を自身の著作で使い、これが広く読まれたため、この記号が "Ampère's and" と呼ばれるようになったという誤った語源俗説がある。アンパサンドの起源は1世紀の古ローマ筆記体にまでさかのぼることができる。古ローマ筆記体では、E と T はしばしば合字として繋げて書かれていた(左図「アンパサンドの変遷」の字形1)。それに続く、流麗さを増した新ローマ筆記体では、さまざまな合字が極めて頻繁に使われるようになった。字形2と3は4世紀中頃における et の合字の例である。
Model : line-corporation/line-distilbert-base-japanese
2023年で軽量な日本語モデルだとこれが一番性能効率が良さそうに感じています。
ほかに知っている方がいたら教えてください。
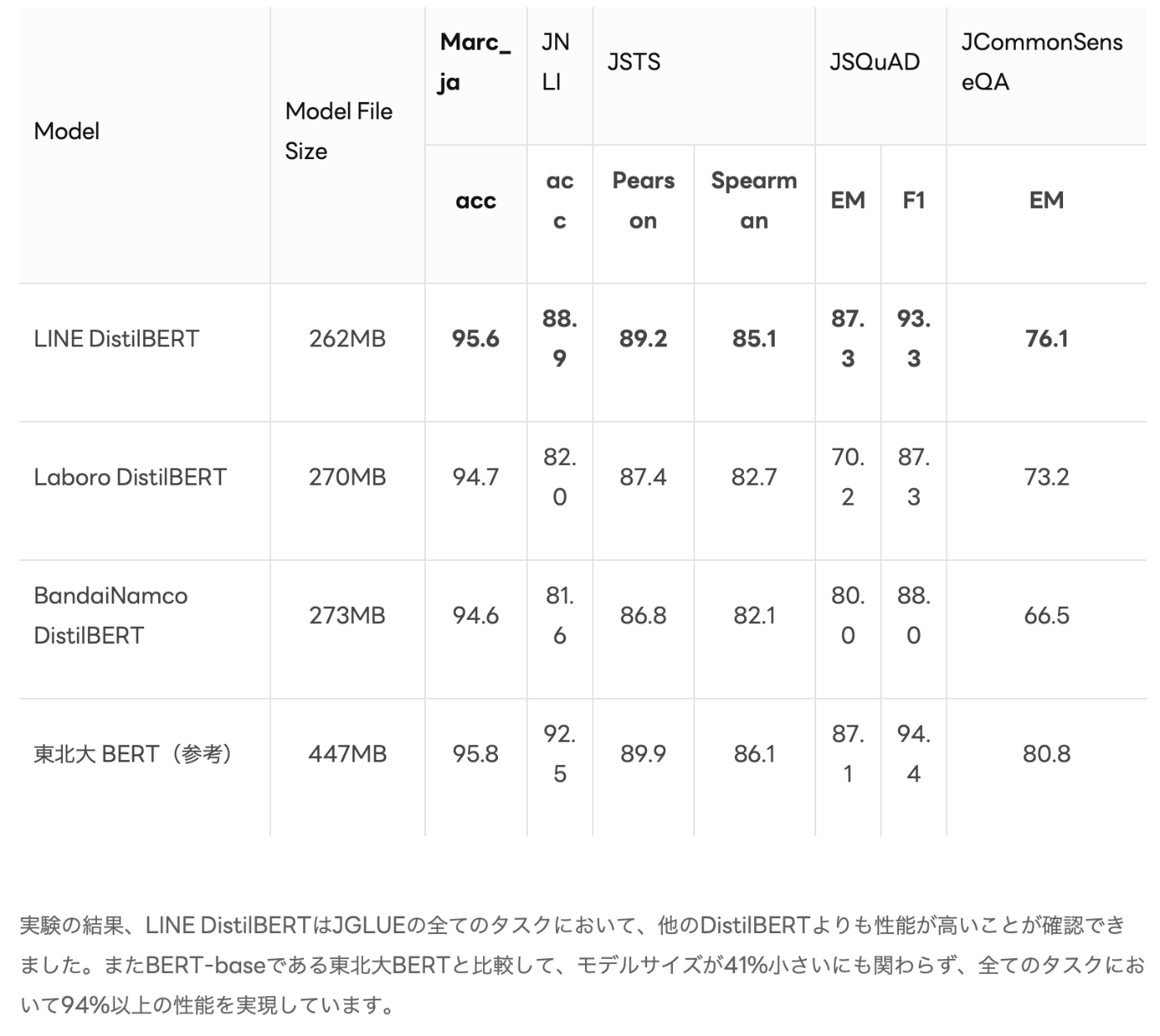 引用 https://engineering.linecorp.com/ja/blog/line-distilbert-high-performance-fast-lightweight-japanese-language-model; 最近のDistilBERTより精度が出ている
引用 https://engineering.linecorp.com/ja/blog/line-distilbert-high-performance-fast-lightweight-japanese-language-model; 最近のDistilBERTより精度が出ている
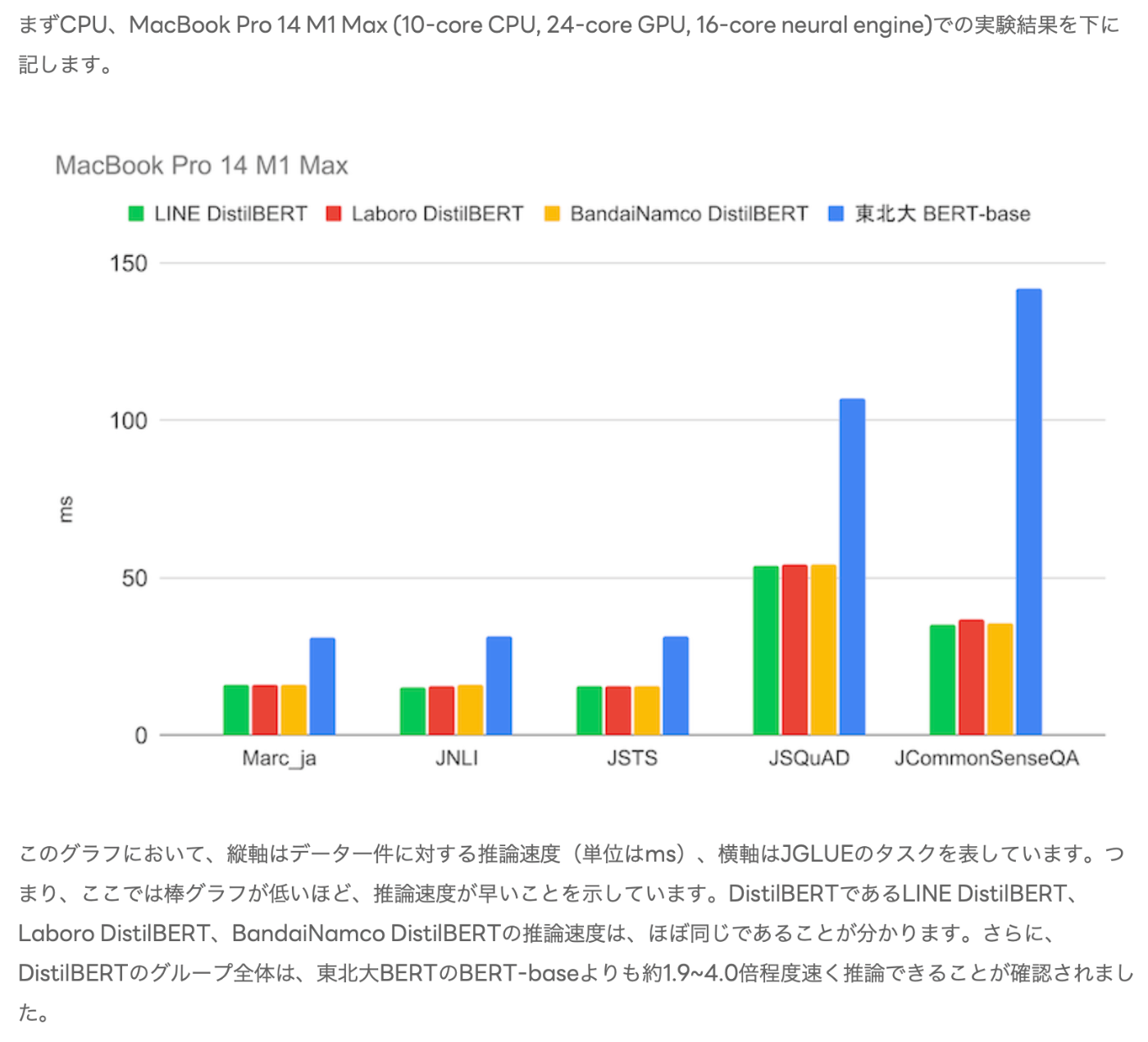 引用 https://engineering.linecorp.com/ja/blog/line-distilbert-high-performance-fast-lightweight-japanese-language-model; 東北大BERTより(当然だが)軽量で高速
引用 https://engineering.linecorp.com/ja/blog/line-distilbert-high-performance-fast-lightweight-japanese-language-model; 東北大BERTより(当然だが)軽量で高速
また、https://github.com/hppRC/bert-classification-tutorial の実験によれば、livedoor News Corpusの分類タスクにおいてcl-tohoku/bert-base-japanese-v2とcl-tohoku/bert-base-japanese-v3の精度はほとんど変わらないとしている。
特徴空間へ変換
大まかな流れとしては、まずデータベースからミニバッチサイズ分のデータをSELECTし、contentのテキストをtokenに変換、推論後[CLS]に対応するベクトルのみ残して、次元数をcolumnとして持つdataframeへ格納する。
コードは次のようになる。
import random
import pandas as pd
import ibis
from transformers import AutoTokenizer, AutoModel
# sqlite DBをibis-frameworkで扱う
con = ibis.sqlite.connect("ex_jawiki_nopeple.db")
table = con.table("article")
LEN_DATABASE: int = 47300 # table.count().execute()
# データベースのoffset行目からbatchsize行のレコードを取得
# get_data()で呼ぶとランダムに1つデータを取ってくる
def get_data(offset=None, batchsize=1): # -> Tupple[List[str]]
global table
print("[INFO] load data froms sql")
offset = offset if (offset != None) else random.randint(0, LEN_DATABASE)
df = table.limit(batchsize, offset=offset).execute()
content_list = df["content"].to_list()
title_list = df["page_title"].to_list()
id_list = df["page_id"].to_list()
return content_list, title_list, id_list
# BERTの準備
tokenizer = AutoTokenizer.from_pretrained(
"line-corporation/line-distilbert-base-japanese",
)
model = AutoModel.from_pretrained(
"line-corporation/line-distilbert-base-japanese"
).cuda()
# テキストのリストを受け取り、ベクトルのベクトルとして返す
def inference(content_list): # List[str] -> Tensor[float]
global tokenizer
global model
# テキストをtoken_idのベクトルに変換
# padding, truncation, max_lengthでBERTの入力分512次元に整形してくれる
token = tokenizer(
content_list, # text to tensor [int id]
return_tensors="pt",
padding=True,
truncation=True,
max_length=512,
)
# 自分で整形するなら次の処理を行う
# if token["input_ids"].shape[1] > 512:
# token["input_ids"] = token["input_ids"][:, :512]
# token["input_ids"][:, 511] = 3 # token [SEP] is id=3, [CLS] id=2
# token["attention_mask"] = token["attention_mask"][:, :512]
# print("".join( tokenizer.convert_ids_to_tokens(token["input_ids"][0])))
token.pop("token_type_ids")
token["input_ids"] = token["input_ids"].cuda()
token["attention_mask"] = token["attention_mask"].cuda()
print("[INFO] start inferance")
infer = model(**token)
return infer["last_hidden_state"][:, 0, :] # [CLS]に対応するベクトルを取り出す
# 実行したい本体
if __name__ == "__main__":
# 30回SQLを引いて、300×32個のデータを処理する
df = pd.DataFrame()
batchsize = 32
draw = 300
for i in range(draw):
# page_IDでデータに偏りがあると良くないのでよーく混ぜてドローする
# 本当はSQL側でMIXしてから1回のアクセスで300×32個取得した方が明らかに良い
offset = random.randint(
(LEN_DATABASE//draw)*i,
(LEN_DATABASE//draw)*i+draw-batchsize
)
content_list, title_list, id_list = get_data(offset=offset, batchsize=32)
infer = inference(content_list)
# 特徴量を表に格納し、page_IDはindexへ置く
# 不必要だが、見やすさのためpage_titleもindexへ格納した
df = pd.concat([
df,
pd.DataFrame(infer.detach().cpu()).set_index([id_list, title_list])
])
df.to_pickle("feat_space.pkl")
SQLを組むとき、python上では文字列で扱われるため大変だったが、ibisを使うことでpandas dataframeのように扱える。上の書き方は古いため非推奨。今はtable.to_pandas()で変換するほうが正しい。
これによりfeat_space.pklに特徴空間を構成する文章のベクトルが得られた。次は距離による類似度検索がうまくいくか試してみる。
類似資料検索
まず特徴空間にクラスタがあるかT-SNEで見てみると、全くそんなことなく均等に話題が散らばっているように見える。Livedoor blog datasetだと雑誌の扱う話題カテゴリごとにくっきり分かれて分離された大陸や入江のような部分ができるため、これはwikipedia datasetの特徴に合っていそう。
0 1 2 ... 765 766 767
901 旭川市 -0.013937 -0.574887 0.245145 ... -0.953841 0.570098 0.283934
934 イエスタデイ... -0.013288 -0.372984 -0.128461 ... -0.085730 0.579639 0.308377
984 メモリ管理 0.037853 -0.440477 0.257168 ... -0.385373 0.311131 -0.051039
985 仮想記憶 -0.135573 -0.460874 0.268214 ... -0.232143 0.201790 0.011713
986 共有メモリ 0.149946 -0.467517 0.264289 ... -0.151633 0.249049 0.044951
...
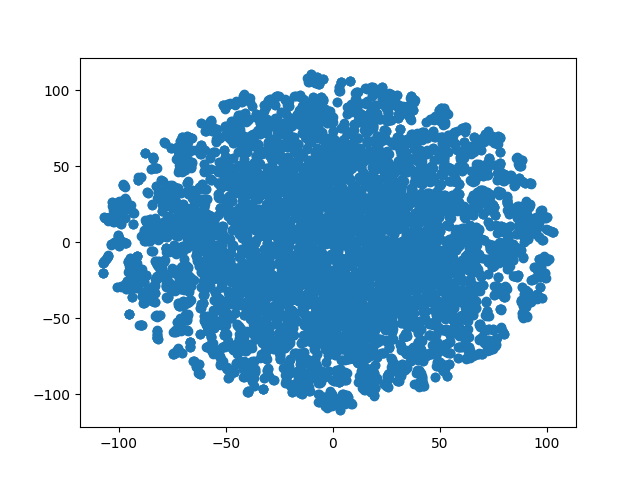
次に、記事の類似度を距離で測って、同じ話題が近くに分布しているか見てみる。
例えば、今回サンプリングした4行目「仮想記憶」について次のコードで類似度を計算してみると、上位は以下のようになった。
仮想記憶 仮想記憶(かそうきおく、、バーチャルメモリ)とは、コンピュータ分野におけるメモリ管理の仮想化技法の一種であり、オペレーティングシステム (OS) などが物理的なメモリを、アプリケーション・ソフトウェア(プロセスなど)に対して、専用の連続した主記憶装置に見えるように提供する。この技術により、物理的な主記憶装置に加えてハードディスク装置等の補助記憶装置を併用すれば、物理的な主記憶装置よりも大きな仮想メモリを提供する事ができる。またアプリケーション・プログラム側は、物理メモリ上のアドレスを意識しなくて良いため、マルチタスクの実現が容易である。このため現代のオペレーティングシステムの多くが仮想記憶をサポートしている。
import pandas as pd
import numpy as np
# 特徴量のデータをロード
df = pd.read_pickle("feat_space.pkl")
feat_v = df.values # numpy shape(9600, 768)
feat_q = feat_v[3] # numpy shape(768, )
# ノルム最小順でindex取得
ans = np.linalg.norm(feat_v - feat_q.T, axis=1)
key = np.argsort(ans) # index = 3, 200, 1036, 202, 537, 1602, 160, 4976 ...
(985, '仮想記憶')
(2917, 'FPU')
(13250, 'セグメント方式')
(2919, 'エミュレータ (コンピュータ)')
(7182, 'VRAM')
(20609, '通信プロトコル')
(2387, 'CPU')
(68658, 'ランタイムライブラリ')
(68648, 'ダイナミックリンクライブラリ')
(992, 'データ構造')
(44259, 'Virtual Private Network')
(7465, 'DoJaプロファイル')
(54015, 'ファイアウォール')
(3272, 'SCMS')
...
まあまあ間違ってはなさそうだが、(986, 共有メモリ)や(984, メモリ管理)などもっと上位にあってもいい気はする。これに関しては推論に用いた文章冒頭が、メモリに関する知識を前提として仮想メモリのOS上での役割などについて論じているためであると考えられ、推論に使う文章量を増やす(つまり複数の特徴量に分ける)ことで解決できる気がする。
現段階でも周辺領域に関する特徴はまとめられているため、文章の類似度ベースでドキュメント検索をかける分には性能的にも十分かもしれない。
意味ベースの質問検索
本題である。検索において関係グラフなどを構築せず、ベクトルのみで意図した内容へ辿り着けるか。かなりチャレンジングな気がするが、一旦実験してみる。
# 以下の関数をプログラムに挿入
def search(query: str):
df = pd.read_pickle("feat_space.pkl")
feat_v = df.values
feat_q = inference([query])
feat_q = feat_q.detach().cpu().numpy()[0,:] # (1,768) → (768)
ans = np.linalg.norm(feat_v - feat_q.T, axis=1)
key = np.argsort(ans)
for i in key[:10]:
print(df.iloc[i].name)
return None
まず、(147374, エラトステネスの篩)を目当てに、似たような事柄を検索してみる。
エラトステネスの篩 エラトステネスの篩 (エラトステネスのふるい、) は、指定された整数以下の全ての素数を発見するための単純なアルゴリズムである。古代ギリシアの科学者、エラトステネスが考案したとされるため、この名がついている。アルゴリズム.指定された整数x以下の全ての素数を発見するアルゴリズム。右のアニメーションでは以下のステップにそって 2 から 120 までの数に含まれる素数をさがしている。ステップ 1.120要素の配列の1番目にfalseを、2番目以降に全てtrueを入れる。ステップ 2.配列の先頭から順に走査し、trueの要素を見つけたらその添字pを素数リストに追加し、配列の formula_1 以上のpの倍数番目をfalseにする。ステップ 3.上記の篩い落とし操作を、走査している要素の添字がxの平方根に達するまで行う。ステップ 4.最後までtrueだった要素の添字を素数リストに追加して処理終了。
In [1]: import data_infer as model
In [2]: model.search("与えられた自然数に対して、素数判定を行う方法")
(2403, 'トランスフェラビリティー')
(64523, '等方的と異方的')
(59099, '補償定理')
(13421, '1の補数')
(123588, 'スカイフック理論')
...
エラトステネスの篩は上位10位にはなかった。結果のカテゴリ的には物理、特に電子周りがトップヒットしてしまっている。もう少し文章を資料に寄せて検索してみる。
In [3]: model.search("任意の整数以下の素数のリスト(配列)を得る方法をstep by stepで記述したい")
(129858, 'フォーム (ウェブ)')
(59594, 'モデリング言語')
(106940, '関係の正規化')
(2403, 'トランスフェラビリティー')
(15776, '熱力学サイクル')
...
少し情報系領域に寄ったが、まだ使い物にはならない。
In [12] model.search("エラトステネスの篩エラトステネスの篩 (エラトステネスのふるい、) は、指定された整数
...: 以下の全ての素数を発見するための単純なアルゴリズムである。古代ギリシアの科学者、エラトステネスが
...: 考案したとされるため、この名がついている。アルゴリズム.指定された整数x以下の全ての素数を発見する
...: アルゴリズム。右のアニメーションでは以下のステップにそって 2 から 120 までの数に含まれる素数をさ
...: がしている。ステップ 1.120要素の配列の1番目にfalseを、2番目以降に全てtrueを入れる。ステップ 2.配
...: 列の先頭から順に走査し、trueの要素を見つけたらその添字pを素数リストに追加し、配列の formula_1 以
...: 上のpの倍数番目をfalseにする。ステップ 3.上記の篩い落とし操作を、走査している要素の添字がxの平方
...: 根に達するまで行う。ステップ 4.最後までtrueだった要素の添字を素数リストに追加して処理終了。具体例
...: x=120 の場合.配列の中身は、trueである添字がどれかを表記。残りは全てfalseである。理論的考察
(147374, 'エラトステネスの篩')
(81596, '因数定理')
(27674, '拡散モンテカルロ法')
(4376, '無理数')
(12363, 'ディラック定数')
...
冒頭を入れるとやっとエラトステネスの篩と数学関係の領域に辿り着いた。何が影響しているか調べるため、人間SHAPをやってみても良いかもしれない。←TODO
楽しいので、その他の領域の検索もやってみる。以下のようにいくつか試したが、文章が長いほど正確に類似度の高い資料を検索できる。
In [1]: model.search("金沢城金沢城(かなざわじょう)は、加賀国石川郡尾山(現・石川県金沢市丸の内)にある日本
...: の城である。江戸時代には加賀藩主前田氏の居城だった。城址は国の史跡に指定されており、城址を含む一
...: 帯は金沢城公園(かなざわじょうこうえん)として整備されている。概要.金沢平野のほぼ中央を流れる犀川
...: と浅野川とに挟まれた小立野台地の先端に築かれた、戦国時代から江戸時代にかけての梯郭式の平山城であ
...: る(かつて「尾山」と呼ばれたのもこの地形にちなむ。台地先端を山の尾とみなした)。櫓や門に見られる、
...: 白漆喰の壁にせん瓦を施した海鼠(なまこ)壁と屋根に白い鉛瓦が葺かれた外観、櫓1重目や塀に付けられた
...: 唐破風や入母屋破風の出窓は、金沢城の建築の特徴である。この地は加賀一向一揆の拠点で浄土真宗の寺院
...: である「尾山御坊(おやまごぼう、または御山御坊)」であった。")
(142506, '高山神社 (三重県)')
(88546, '崇福寺 (長崎市)')
(147301, '新平湯温泉')
(88544, '承天寺')
(146757, '板留温泉')
...
In [10]: model.search("ファイ・ブレイン 神のパズル『ファイ・ブレイン 神のパズル』(ファイ ブレイン かみの
...: パズル、欧文表記:φ Brain Puzzle of GodまたはPhi-Brain Puzzle of God)は、NHK Eテレにて放送された
...: サンライズ制作の日本のテレビアニメ作品。第1シリーズは2011年10月2日より全25話放送。第2シリーズは2
...: 012年4月8日より全25話放送。第3シリーズは2013年10月6日より全25話放送された。概要.「おジャ魔女どれ
...: み」シリーズや「ケロロ軍曹」などを手掛けた佐藤順一と、「ガンダムシリーズ」や同じく「ケロロ軍曹」
...: で知られるサンライズによるオリジナルアニメ作品。")
(35052, 'おとぼけ課長')
(47985, 'ひみつのゴードン博士シリーズ')
(69877, 'フロンティア (ニュース番組)')
(112100, '留萌交番日記')
(32796, 'プリーズMr.ポストマン')
...
In [16]: model.search("IRBMやロケットブースターなど、実績と信頼性を持った既存のテクノロジーの組み合わせだ
...: けで完成できるシャゴホッドに対して、メタルギアの二足歩行機構が研究途上で実績も無かった点などが挙
...: げられており、登場人物の一人で「武器兵器の特別にスゴい専門家」を自称するシギントは、戦車に足をつ
...: けても車高が上がって前面投影面積が大きくなり、安定性も低下するのでメリットは無いと切り捨てている
...: 。これに対してピースウォーカーの設計担当者であったヒューイは、山岳や沼地等のキャタピラでも移動不
...: 可能な険しい地形を大型兵器が踏破するためには、二足歩行による移動が最適と評している。結果として競
...: 合相手のシャゴホッドが採用されたため、これを不服としたグラーニンは、企画設計書をアメリカの友人で
...: あるヒューイ(Dr.エメリッヒ)に送り、自分のメタルギア計画の有用性を認めなかった軍部中枢に抵抗した
...: が、これが原因でヴォルギン大佐にスパイの嫌疑をかけられ、拷問の末に落命")
(122835, 'P-2J (航空機)')
(81562, 'H-IIAロケット6号機')
(126983, 'LE-7')
(6141, 'イバード派')
(33778, 'F/A-18 (航空機)')
...
In [15]: model.search("名取さなは動物のおしりが好き")
(20375, 'エロス (曖昧さ回避)')
(80881, 'リンガフォン')
(22250, '料理・グルメ漫画')
(91929, 'ウー (ウルトラ怪獣)')
(116345, '眼鏡キャラクター')
...
やはりこうして眺めると、結局Bag-of-wordsでいいのでは...となる。BERTの良さは事前学習と長い文脈を加味した特徴抽出なので、検索のような単語が重要なタスクには素では向いていないのかもしれない。しかし資料同士の類似性検索については非常に展望があるため、こちらが本命な気がしてきた。
成果と課題
特徴空間で遊ぶのは楽しいが、実用を考えると精度が出ないため無意味な実験になってしまったかもしれない。
改善の余地は非常に大きい。例えばカテゴリデータベースと合わせて検索に関する手法を介在させたり、検索ワードに含まれる単語から頻度ベースの単純なモデルと組み合わせて補強したり、色々できそう。
そして全くこの分野のサーベイをせずに遊んでたので、知識の不足を激しく感じる。
詳しい方がいたらおすすめの論文やスタンダードなベクトル検索周りの知識を分けてください。お願いします。
Discussion