🫠
PyTorchのWarmup付きCosine Annealing LR Scheduler
lightning-bolts
pl_bolts.optimizers.lr_scheduler.LinearWarmupCosineAnnealingLR
src/pl_bolts/optimizers/lr_scheduler.py
2020年以降のNN学習戦略として、大体の論文ではAdamWの学習率をWarmup Cosine Annealingで変化させる方法が一般的になっている。
しかしPyTorchオリジナルの学習率スケジューラはWarmupがついてないし、解説記事を見てもパッと使えるものがない。よわよわ人間なのでgithub検索よりインターネッツ記事コピペのほうが便利に感じてしまう...
普段はPyTorch Lightning Boltsをインストールして使っていたが、メンテナンスがゆっくりしていて少し不安だし、このLR Schedulerが使いたいだけで毎回pip install lightning-boltsするのもあれなので、このプログラムだけフォークして自前で持っておくことにした。
Linear Warmup Cosine Annealing LR Scheduler
以下にPyTorch Lightning Boltsのコードを少し単純化したものを乗せる。引用は記事冒頭のページに記載。LicenseはApache-2.0 licenseで引用元にある。
my_optim.py
class CosineAnnealingLR(torch.optim.lr_scheduler._LRScheduler):
def __init__(
self,
optimizer: torch.optim.Optimizer,
warmup_epochs: int,
max_epochs: int,
warmup_start_lr: float = 0.00001,
eta_min: float = 0.00001,
last_epoch: int = -1,
):
"""
Args:
optimizer (torch.optim.Optimizer):
最適化手法インスタンス
warmup_epochs (int):
linear warmupを行うepoch数
max_epochs (int):
cosine曲線の終了に用いる 学習のepoch数
warmup_start_lr (float):
linear warmup 0 epoch目の学習率
eta_min (float):
cosine曲線の下限
last_epoch (int):
cosine曲線の位相オフセット
学習率をmax_epochsに至るまでコサイン曲線に沿ってスケジュールする
epoch 0からwarmup_epochsまでの学習曲線は線形warmupがかかる
https://pytorch-lightning-bolts.readthedocs.io/en/stable/schedulers/warmup_cosine_annealing.html
"""
self.warmup_epochs = warmup_epochs
self.max_epochs = max_epochs
self.warmup_start_lr = warmup_start_lr
self.eta_min = eta_min
super().__init__(optimizer, last_epoch)
return None
def get_lr(self):
if self.last_epoch == 0:
return [self.warmup_start_lr] * len(self.base_lrs)
if self.last_epoch < self.warmup_epochs:
return [
group["lr"] + (base_lr - self.warmup_start_lr) / (self.warmup_epochs - 1)
for base_lr, group in zip(self.base_lrs, self.optimizer.param_groups)
]
if self.last_epoch == self.warmup_epochs:
return self.base_lrs
if (self.last_epoch - 1 - self.max_epochs) % (2 * (self.max_epochs - self.warmup_epochs)) == 0:
return [
group["lr"] + (base_lr - self.eta_min) * (1 - math.cos(math.pi / (self.max_epochs - self.warmup_epochs))) / 2
for base_lr, group in zip(self.base_lrs, self.optimizer.param_groups)
]
return [
(1 + math.cos(math.pi * (self.last_epoch - self.warmup_epochs) / (self.max_epochs - self.warmup_epochs)))
/ (1 + math.cos(math.pi * (self.last_epoch - self.warmup_epochs - 1) / (self.max_epochs - self.warmup_epochs)))
* (group["lr"] - self.eta_min)
+ self.eta_min
for group in self.optimizer.param_groups
]
使用例
普通のtorch.optim.lr_schedulerと同じ使い方ができる。
model = nn.Linear(1,1)
max_epoch = 128 # 学習終了のepoch数は最初から与える
iter_step = 4 # (ダミー)ミニバッチで学習する場合のイテレーションステップ数=バッチサイズ/ミニバッチサイズ
optimizer = torch.optim.AdamW(
model.parameters(),
lr=0.001,
weight_decay=0.02)
lr_scheduler = CosineAnnealingLR(
optimizer,
max_epochs=max_epoch,
warmup_epochs=8,
warmup_start_lr=0.0001,
eta_min=0.00001)
また、挙動としては次の通りになる。
curves = []
for e in range(max_epoch):
for s in range(iter_step):
# 各イテレーションでパラメータを更新
optimizer.step()
curves += [optimizer.param_groups[0]["lr"]]
# 各epoch終了後にスケジューラで最適化学習率を更新
lr_scheduler.step()
plt.plot(curves)
plt.savefig("lr_curves.png")
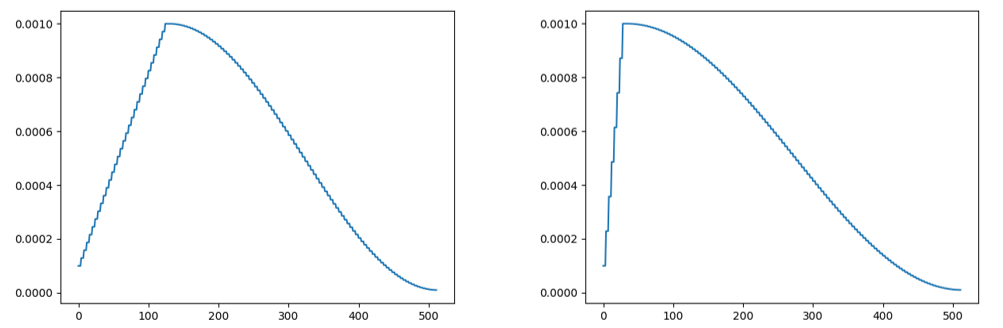 左: warmup 32epoch(現実的ではない), 右: warmup 8epoch(完全にデータ量依存だがそこそこな規模のデータセットなら大体2~4epochくらいが経験的に目安)
左: warmup 32epoch(現実的ではない), 右: warmup 8epoch(完全にデータ量依存だがそこそこな規模のデータセットなら大体2~4epochくらいが経験的に目安)
Discussion