PyTorchオンリーで実装するGrad-CAM
TL;DR
モデルを分割して、途中の層で計算グラフをdetachし、その地点まで逆伝播した勾配と特徴量を合計する。
torch Grad-CAM 実装
class GradCam(nn.Module):
"""
backbone = model.backbone
classifier = model.classifier
gradcam = GradCam(backbone, classifier)
gradmap = gradcam(img, target, 0).detach()
make_heatmap(img_grad[0], color="hot")
"""
def __init__(self, uppermodel, bottommodel):
super().__init__()
self.uppermodel = uppermodel
self.bottommodel = bottommodel
return None
def infer(self, img):
self.feature = self.uppermodel(img) # save original feature with calcgraph
feat = self.feature.clone().detach().requires_grad_(True) # -> [B,512,H/16,W/16]
outputs = self.bottommodel(feat)
return outputs, feat
def forward(self, img, target, batch=0, mode="bicubic"):
# input:
# img: [B,3,H,W]
# target: [B,C]
# batch: index to visualize feature
self.uppermodel.eval()
self.bottommodel.eval()
outputs, feat = self.infer(img)
target = torch.argmax(target, dim=1)
outcome = torch.argmax(outputs, dim=1)
print(f"infer = {int(outcome)}, target = {int(target)}")
b = batch
B, C, H, W = feat.shape
outputs[b][target[b]].backward(retain_graph=True)
feat_v = feat.grad.view(B, C, H*W) # [B, 2048, 7, 7] -> [B, 2048, 49]
alpha = torch.mean(feat_v[b], axis=1)
lgradcam = F.relu(torch.sum(feat[b].view(C,H,W) * alpha.view(-1,1,1), 0))
lgradcam = F.interpolate(lgradcam.view(1,1,H,W), size=(img.shape[2], img.shape[3]), mode=mode)
return lgradcam
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
https://arxiv.org/abs/1610.02391
多くの記事がopencvを使っているため、チャンネル情報がややこしいことになっている。そこで、計算から可視化までの流れをすべてtorchのみで計算し、pyplotでダイレクトにヒートマップを可視化するコードを書いた。
数式での理解などはたくさん記事があるので、ここでは端的にコードを示していく。
timmのResNetを例に、torchの演算のみでアクティベーションマップを出力する。
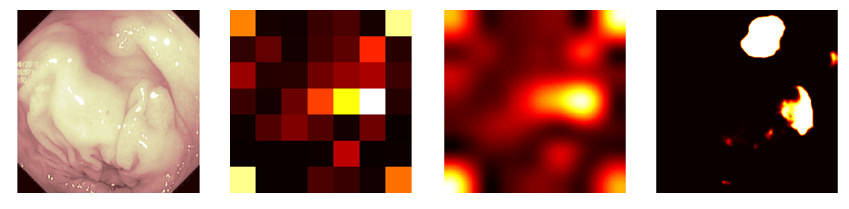 左から入力画像、Grad-CAM(正確な解像度)、Grad-CAM(一般的な使われ方)、セグメンテーションによる注目領域
左から入力画像、Grad-CAM(正確な解像度)、Grad-CAM(一般的な使われ方)、セグメンテーションによる注目領域
なお、現代的な勾配ベース可視化技術は以下の@tetutaro(Tetsutaro Maruyama)さんの記事が非常にわかりやすくまとまっているため、必読である。
モデルの分割
用意したモデルの見たい層で分割し、分ける。今回は最終ブロックのバックプロップからGrad-CAMを可視化する。
model = timm.create_model(
"resnetrs50.tf_in1k",
checkpoint_path="model_resnetrs50.pt",
num_classes=100
)
backbone = nn.Sequential(
model.conv1,
model.bn1,
model.act1,
model.maxpool,
model.layer1, # -> [B, 64, H/2, W/2]
model.layer2, # -> [B,128, H/4, W/4]
model.layer3, # -> [B,256, H/8, W/8]
model.layer4, # -> [B,512,H/16,W/16]
).eval()
classifier = nn.Sequential(
model.global_pool,
model.fc,
).eval()
計算グラフの用意
最初用意するのは次のミニバッチ(dataloaderから引っ張ってくる)
-
img: torch tensor [1,3,256,256] -
target: torch tensor onehot(10)
feat = backbone(img)
feat = feat.clone().detach().requires_grad_(True) # -> [B,512,H/16,W/16]
out = classifier(feat)
target = torch.argmax(target, dim=1)
infer = torch.argmax(out, dim=1)
Grad-CAMの計算
本題。入力は次
-
feat: 可視化する層の出力物 torch tensor[1,512,32,32] -
outputs: バックプロップをかける出力 -
target:outputsの正解クラス頂点を選択するときつかう -
apply_batch: ミニバッチ方向がsize 1でない場合、使う画像を選ぶ
def gradcam(feat, outputs, target: int, apply_batch=0):
# feat: [B,C,H,W]
# outputs: [CLS]
b = apply_batch
B, C, H, W = feat.shape
outputs[b][target[b]].backward(retain_graph=True)
feat_v = feat.grad.view(B, C, H*W) # [B, C, H/16, W/16] -> [B, C, HW/256]
alpha = torch.mean(feat_v[b], axis=1)
lgradcam = F.relu(torch.sum(feat[b].view(C,H,W) * alpha.view(-1,1,1), 0))
lgradcam = F.interpolate(lgradcam.view(1,1,H,W), size=(H*16,W*16), mode="bicubic")
return lgradcam.detach()
interpolateはGrad-CAMのサイズをオリジナル画像にリサイズして戻す処理。modeを最近傍にすればボヤけず正確な状態で引き伸ばせる。
可視化
pyplotにより可視化する。
img_grad = gradcam(feat, out, target, 0)
plt.gca().axis("off")
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)
plt.imshow(torch.sum(img[0], dim=0), cmap="pink") # dim=0 はバッチ方向
plt.savefig(f"vis_image.png")
plt.imshow(img_grad[0,0], cmap="hot") # dim=0, dim=1 はそれぞれバッチ方向とチャンネル方向で、輝度のみを持つためチャンネルは1次元のみ
plt.savefig(f"vis_gradcam.png")
画像は記事冒頭の通り。
使用したデータセットはkvasir内視鏡画像データセット。
Pogorelov, Konstantin and Randel, Kristin Ranheim and Griwodz, Carsten and Eskeland, Sigrun Losada and de Lange, Thomas and Johansen, Dag and Spampinato, Concetto and Dang-Nguyen, Duc-Tien and Lux, Mathias and Schmidt, Peter Thelin and Riegler, Michael and Halvorsen
"KVASIR: A Multi-Class Image Dataset for Computer Aided Gastrointestinal Disease Detection"
Proceedings of the 8th ACM on Multimedia Systems Conference
2017, 10.1145/3083187.3083212
https://datasets.simula.no/kvasir/
ヒートマップ画像もtorch tensorにする
pyplotで可視化すると画像が出るたびにディレクトリ内の名前空間(?)が散らかってしまう。
従って画像をテンソルにして保持して最後にくっつける方がいいので、ヒートマップをpngエンコーディングした画像を返してくれる関数を用意する。
def make_heatmap(img, size=(256,256), color="pink"):
# input:
# img: torch tensor[C,H,W] -> [H,W]
# color: pyplot cmap
# output:
# buf; torch tensor [3,H,W]
buf = io.BytesIO()
plt.figure(figsize=size, dpi=1)
plt.gca().axis("off")
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)
plt.imshow(torch.sum(img, dim=0), cmap=color)
plt.savefig(buf, format='png')
plt.clf()
plt.close()
buf = torchvision.io.decode_png(torch.frombuffer(buf.getvalue(), dtype=torch.uint8))
return buf[0:3] # remove alpha ch
完成
以上の方法をまとめると次のプログラムとして完成する。
Grad-CAMをクラス実装に変更した。
import io
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.nn import functional as F
import torchvision
import timm
class GradCam(nn.Module):
def __init__(self, uppermodel, bottommodel):
super().__init__()
self.uppermodel = uppermodel
self.bottommodel = bottommodel
return None
def infer(self, img):
self.feature = self.uppermodel(img) # save original feature with calcgraph
feat = self.feature.clone().detach().requires_grad_(True) # -> [B,512,H/16,W/16]
outputs = self.bottommodel(feat)
return outputs, feat
def forward(self, img, target, batch=0, mode="bicubic"):
self.uppermodel.eval()
self.bottommodel.eval()
outputs, feat = self.infer(img)
target = torch.argmax(target, dim=1)
outcome = torch.argmax(outputs, dim=1)
print(f"infer = {int(outcome)}, target = {int(target)}")
b = batch
B, C, H, W = feat.shape
outputs[b][target[b]].backward(retain_graph=True)
feat_v = feat.grad.view(B, C, H*W) # [B, 2048, 7, 7] -> [B, 2048, 49]
alpha = torch.mean(feat_v[b], axis=1)
lgradcam = F.relu(torch.sum(feat[b].view(C,H,W) * alpha.view(-1,1,1), 0))
lgradcam = F.interpolate(lgradcam.view(1,1,H,W), size=(img.shape[2], img.shape[3]), mode=mode)
return lgradcam
def make_heatmap(img, size=(256,256), color="pink"):
# input:
# img: torch tensor[C,H,W] -> [H,W]
# color: pyplot cmap
# output:
# buf; torch tensor [3,H,W]
buf = io.BytesIO()
plt.figure(figsize=size, dpi=1)
plt.gca().axis("off")
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)
plt.imshow(torch.sum(img, dim=0), cmap=color)
plt.savefig(buf, format='png')
plt.clf()
plt.close()
buf = torchvision.io.decode_png(torch.frombuffer(buf.getvalue(), dtype=torch.uint8))
return buf[0:3] # remove alpha ch
backbone # model block: [1,3,256,256] -> [1,2048,16,16]
classifier # backward nn: [1,2046,16,16] -> [1,10]
gradcam = GradCam(backbone, classifier)
img, target = next(iter(dataloader))
fig_image = make_heatmap(img[0], color="pink")
img_grad = gradcam(img, target, 0).detach()
fig_grad = make_heatmap(img_grad[0], color="hot")
img_grad = gradcam(img, target, 0, mode="nearest").detach()
fig_gradn = make_heatmap(img_grad[0], color="hot")
modelseg # segmentation model: [1,3,256,256] -> [1,1,256,256]
msk = modelseg(img).detach()
fig_seg = make_heatmap(msk[0], color="hot")
fig = torch.concat([fig_image, fig_seg, fig_grad], dim=2)
torchvision.io.write_png(fig, "vis.png")
出力図は以下

Discussion