Bayesian Analysis with PyMC 勉強ノート 6 モデル比較
Osvaldo Martin 著, 金子武久 訳
Pythonによるベイズ統計モデリング (Bayesian Analysis with Python)
2018-06-26
https://www.kyoritsu-pub.co.jp/book/b10003944.html
Christopher M. Bishop 著, 元田浩 栗田多喜夫 樋口知之 松本裕治 村田昇 監訳
パターン認識と機械学習 ベイズ理論による統計的予測 (Pattern Recognition and Machine Learning)
2012-01-20
https://www.maruzen-publishing.co.jp/item/?book_no=294524
Pythonによるベイズ統計モデリングを読んだので学習メモを整理します。学習中のノートなので正確ではないかもしれません。使われているコードをPyMC3からPyMC5に書き直しました。
また、せっかくなのでPRMLの本を参照しながら読むことにしました。式の文字の扱いなどはPRML風になるよう頭に収めようと思っています。
モデル比較
モデルはデータを通じて問題を理解するためのただの近似であるため、あらゆるモデルは間違っていると言える。しかしその中でも同じデータを記述する他のモデルと比較した時に優劣がある。
- 単純さと精度
- 過学習と過小適合
- 正則化事前分布
- 情報量基準
- ベイズファクター
次のライブラリを使用する。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import pymc as pm
import arviz as az
az.style.use("arviz-darkgrid")
0. ベイズモデルについての復習
モデル比較のための前提知識を思い出すために、PRMLの本を読みながらメモしていく。
多項式曲線fitting
PRML 1.1
モデル設定を司る変数
-
\bold{x} = \{ x_n \} -
\bold{t} = \{ t_n \} x
このデータに対して、新たな入力
単純な方法では、誤差関数 (error function)
以上の話で出てきた最小二乗でパラメータを最適化した場合の過学習の性質は、アプローチが最尤推定 (maximum likelihood)の特殊な場合に相当するから起こっている。最尤推定の一般的性質である。
このアプローチのまま過学習を抑えるには正則化 (regularization)を加える方法があり、これにより汎化誤差を緩和できる。(が、聞くところによると、データに対する不偏性(unbiasedness; サンプルサイズに依存せず推定量の期待値が母数に等しい性質)や一致性(consistency; 無限大のサンプルサイズで計算した推定値が母数に一致する性質)などの観点から、説明性の点であまり良くないこともあるらしい)
ベイズ確率における曲線fitting
PRML 1.2
最尤推定などのような頻度主義(frequentist)的なアプローチではなく、ベイズ確率の方法で推定することで、自然に過学習を押さえながら不確実性を定量化し、さらに有効パラメータ数 (effective number of parameters)を自動的にデータセットのサイズに適合させられる。
まず、パラメータ
ベイズの定理から、データ
頻度主義では
最尤推定では、
ベイズ的方法は全パラメータ空間で周辺化(つまり総和や積分)を計算する必要があるので、計算的な困難さから昔はあまり発展しなかった。しかしMCMCの実用化で様々なモデルを計算できるようになった。MCMCは計算量が大きい欠点があるが、変分ベイズや期待値伝播法などの計算量の小さい決定論的近似法もあり、大規模なモデルの計算も可能になる。
曲線fittingをベイズ的に考える。
まず、目標変数の値に関する不確実性を分布で表す。推定したいパラメータとして精度(分散の逆)を
次に尤度(と対数尤度)を考える。データがiidからサンプルされた設定とする。
この最尤推定を行えばパラメータ
事前分布と尤度の積があれば、事後分布が求まる。これを最大化することを最大事後確率推定(maximum posterior; MAP推定)と言い、事後分布の最大値は以下の式で表せる事になる。
この美しい流れから、ガウスを使ったMAP推定は
さらにベイズ的な方法に従うと、事後分布
1. 単純さと精度
オッカムのカミソリ (Occam's razor): 同じ現象を等しく説明する方法が複数ある場合、最も単純なものを選ぶこと。
精度が高く、かつ単純なモデルを選ぶことのバランスを考えていく。
# 多項式fittingのためのデータ生成
x = np.array([4.0, 5.0, 6.0, 9.0, 12.0, 14.0])
y = np.array([4.2, 6.0, 6.0, 9.0, 10.0, 10.0])
order = [0,1,2,5] # モデルの複雑さ M
plt.scatter(x,y, color="b")
for m in order:
x_n = np.linspace(x.min(), x.max(), 100)
coeffs = np.polyfit(x, y, deg=m)
ffit = np.polyval(coeffs, x_n)
p = np.poly1d(coeffs)
r2 = np.sum((p(x) - np.mean(y))**2) / np.sum((y - np.mean(y))**2)
plt.plot(x_n, ffit, label=f"M = {m}, R^2 = {r2:.2f}")
plt.legend(loc=2, fontsize=14)

この図を見ると、必ずしも学習誤差(サンプル内精度 (within-sample accuracy)の逆)が小さいほうが良いというわけではなく、ある程度間違っていても単純な曲線のほうが物事をうまく説明できてそうな感じがしてくる。汎化誤差(サンプル外精度 (out-of-sample accuracy)の逆)が高い方が嬉しい。
バイアス-バリアンス分解
PRML 1.5.5 3.2
偏り(バイアス)と分散(バリアンス)のトレードオフを議論することで過学習と過小適合を説明できる。
- high bias: データに適合しにくく、データに含まれるパターンを見逃しやすい。偏見(prejudice)や慣性(inertia)が大きいモデルはバイアスが高く、表現力が小さい。
- high variance: 新しいデータセットを持ってきてモデルを最適化した時に、モデルが敏感に適合して形を大きく変える。データセットの種類により多くの変種を作れるモデルはhigh varianceを持つ。複雑で柔軟なモデルはバリアンスが高く、ノイズを過学習しやすい。
この2つはトレードオフになっていて、次の式から定量的に理解することができる。
条件付き分布
目標は
この結果を使って、
つまり
第2項目は
第1項目の中身を
第1項はバイアスで、全てのデータセットの取り方に関する出力の平均が、最適解(理想的な回帰関数)
第2項はバリアンスで、
バイアスとバリアンスはトレードオフの関係になっていて、モデルの表現力、つまり複雑さでバランスする。例えば同じ複雑さ
以上の議論で、誤差(期待損失
2. 事前分布の正則化
非ベイズにおいてはRidgeやLaasoなどが正則化として有名だが、これをベイズ的な視点で見ると、それぞれ
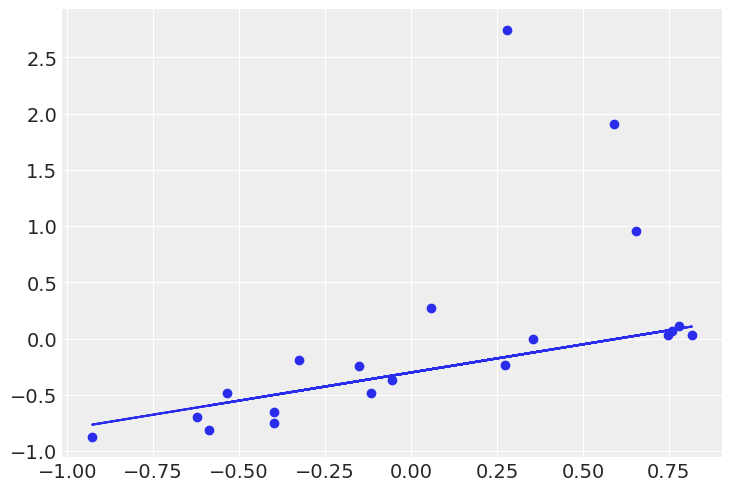
N = 20
a0_real = -0.3
a1_real = 0.5
e_real = np.random.normal(0, 0.2, N)
e_real[0] += 1
e_real[1] += 2
e_real[2] += 3
x = np.random.uniform(-1.0, 1.0, N)
y_real = a0_real + a1_real * x
y = y_real + e_real
plt.plot(x, y_real)
plt.scatter(x, y)
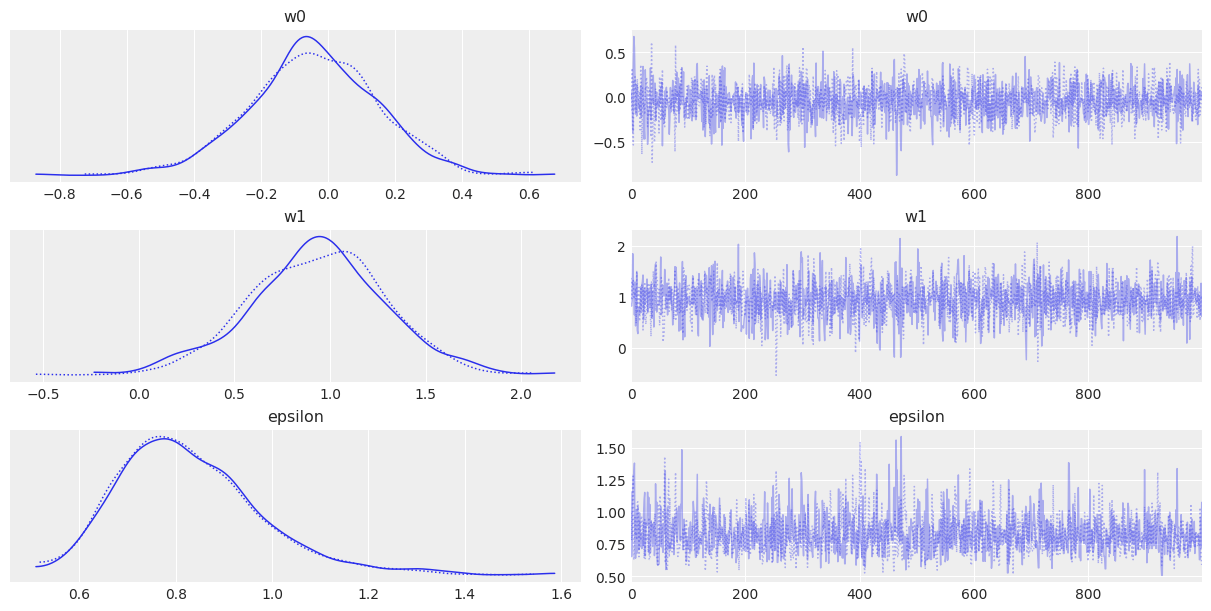
with pm.Model() as model_r:
w0 = pm.Normal("w0", mu=0, sigma=10)
w1 = pm.Normal("w1", mu=0, sigma=10)
e = pm.HalfCauchy("epsilon", 5)
mu = pm.Deterministic("mu", w0 + w1 * x)
y_pred = pm.Normal("y_pred", mu=mu, sigma=e, observed=y)
trace_r = pm.sample(1000, chains=2, cores=1)
az.plot_trace(trace_r, var_names=["w0", "w1", "epsilon"])
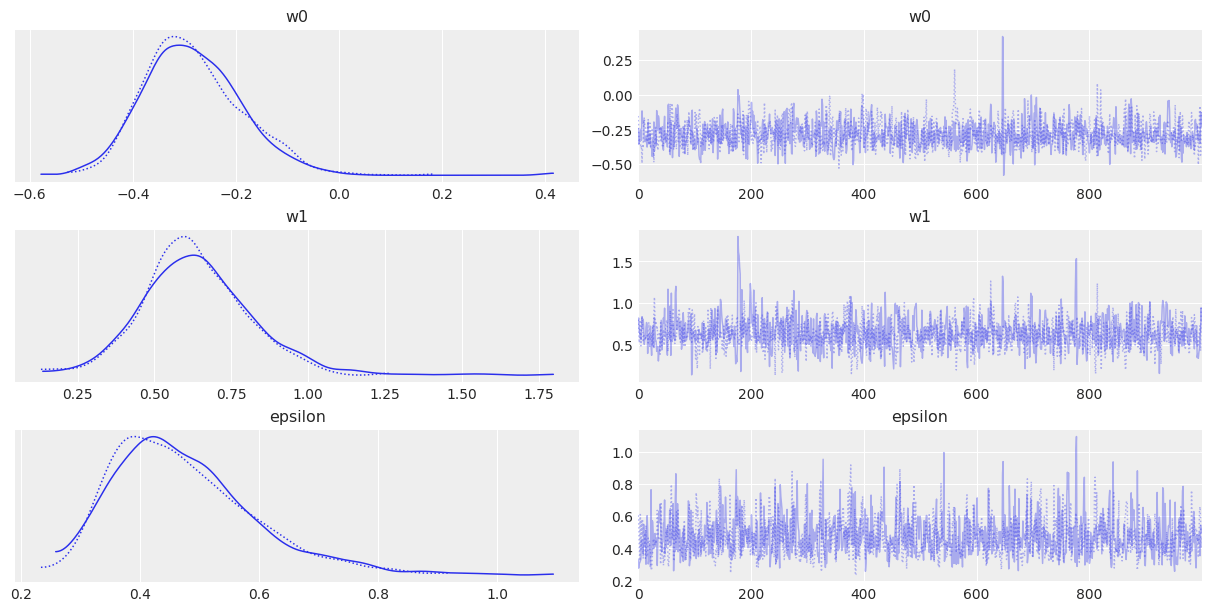
with pm.Model() as model_l:
w0 = pm.Laplace("w0", mu=0, b=10)
w1 = pm.Laplace("w1", mu=0, b=10)
e = pm.HalfCauchy("epsilon", 5)
mu = pm.Deterministic("mu", w0 + w1 * x)
y_pred = pm.Laplace("y_pred", mu=mu, b=e, observed=y)
trace_l = pm.sample(1000, chains=2, cores=1)
az.plot_trace(trace_l, var_names=["w0", "w1", "epsilon"])
# パラメータの事後分布の可視化
fig, axes = plt.subplots(1, 2, figsize=(10,3))
axes = axes.ravel()
sns.kdeplot(trace_r.posterior["w0"].values.reshape(-1), color="c", ax=axes[0])
sns.kdeplot(trace_l.posterior["w0"].values.reshape(-1), color="m", ax=axes[0])
sns.kdeplot(trace_r.posterior["w1"].values.reshape(-1), color="c", ax=axes[1])
sns.kdeplot(trace_l.posterior["w1"].values.reshape(-1), color="m", ax=axes[1])
plt.show()
# データ空間上の予測分布
idx = np.argsort(x)
post_r_w0 = trace_r.posterior["w0"].values.reshape(-1)
post_r_w1 = trace_r.posterior["w1"].values.reshape(-1)
post_l_w0 = trace_l.posterior["w0"].values.reshape(-1)
post_l_w1 = trace_l.posterior["w1"].values.reshape(-1)
sig_r = az.hdi(trace_r.posterior, hdi_prob=0.90)["mu"].values[idx]
sig_l = az.hdi(trace_l.posterior, hdi_prob=0.90)["mu"].values[idx]
plt.scatter(x, y)
plt.plot(x, np.mean(post_r_w0[idx])+np.mean(post_r_w1[idx])*x, c="c")
plt.plot(x, np.mean(post_l_w0[idx])+np.mean(post_l_w1[idx])*x, c="m")
plt.plot(x, a0_real + a1_real * x, c="b")
plt.fill_between(x[idx], y1=sig_r[:,0], y2=sig_r[:,1], color="c", alpha=0.20)
plt.fill_between(x[idx], y1=sig_l[:,0], y2=sig_l[:,1], color="m", alpha=0.20)
plt.show()
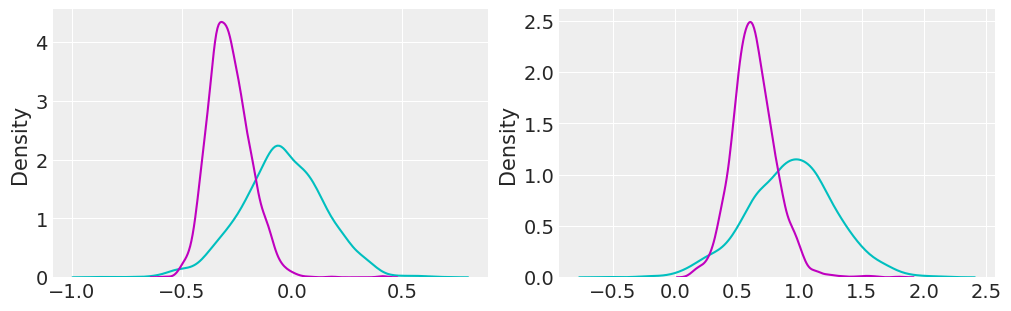

見た感じロバストに推定できている。ただT分布とどっちが良いかはわからない...
3. 予測精度
クロスバリデーションなどのためにデータを分割できない、したくない場合、情報量基準 (information criterion)を使ってモデルの精度をチェックできる。モデルの複雑さと精度(どれだけデータを説明できるか)のバランスを検討するための材料にできる。
対数尤度と逸脱度: 対数尤度
- 逸脱度が小さい、つまり対数尤度が大きいならデータのfit具合が良い
- 逸脱度は学習誤差(サンプル内精度)を測っているので、複雑なモデルを贔屓している
- 逸脱度に正則化項を入れることで贔屓を解消し、情報量基準として扱える
AIC 赤池情報量基準
つまり、尤度でモデルの精度を見て、パラメータ数でモデルの複雑さを見ている情報量である。しかしベイズ的な観点では、事前分布に一様分布しか仮定していないのは扱いづらく、さらに事後分布の不確かさに関する情報も捨てられている(
DIC 逸脱度情報量基準
これは事後分布を反映したAICのベイズ版だが、まだ事後分布を全て使えていない。
WAIC 広く使える情報量規準
WAIC(Widely Available Information Criterion)
第1項目は対数各点予測密度(log point-wize predictive density)のサンプリングによる近似で、全データ点にわたり事後分布からサンプル
第2項目は有効パラメータ数の計算で、全データ点にわたり事後分布からサンプル
# 1次式、2次式で回帰して
N = 30
a1_real, a2_real = 1.2, -1
x = np.random.uniform(-1.0, 1.0, N)
y = a1_real * x + a2_real * x**2 + np.random.normal(0, 0.5, N)
x = (x - x.mean())/x.std()
y = (y - y.mean())/y.std()
print(x.shape, y.shape)
plt.scatter(x, y, color="b")
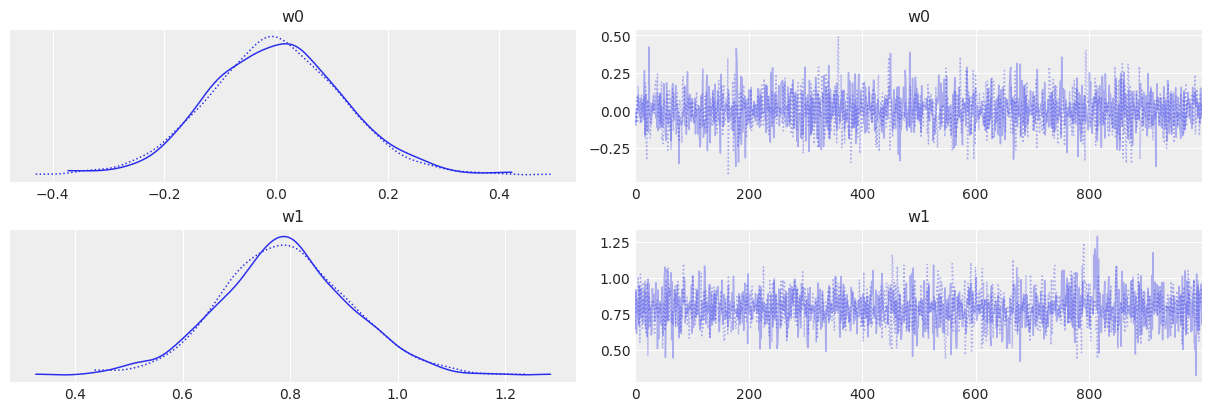
with pm.Model() as model_1:
w0 = pm.Normal("w0", mu=0, sigma=10)
w1 = pm.Normal("w1", mu=0, sigma=10)
e = pm.HalfCauchy("epsilon", 5)
mu = pm.Deterministic("mu", w0 + w1 * x)
y_pred = pm.Normal("y_pred", mu=mu, sigma=e, observed=y)
trace_1 = pm.sample(1000, chains=2, cores=1)
az.plot_trace(trace_1, var_names=["w0", "w1"])
with pm.Model() as model_2:
w0 = pm.Normal("w0", mu=0, sigma=10)
w1 = pm.Normal("w1", mu=0, sigma=10)
w2 = pm.Normal("w2", mu=0, sigma=10)
e = pm.HalfCauchy("epsilon", 5)
mu = pm.Deterministic("mu", w0 + w1*x + w2*x**2)
y_pred = pm.Normal("y_pred", mu=mu, sigma=e, observed=y)
trace_2 = pm.sample(1000, chains=2, cores=1)
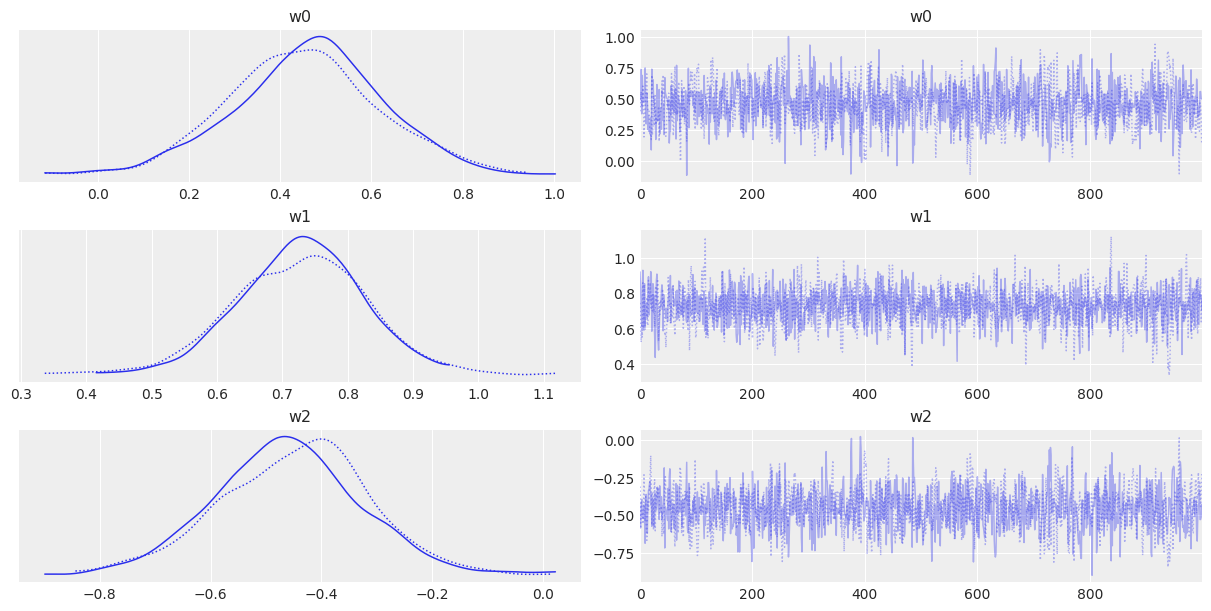
az.plot_trace(trace_2, var_names=["w0", "w1", "w2"])
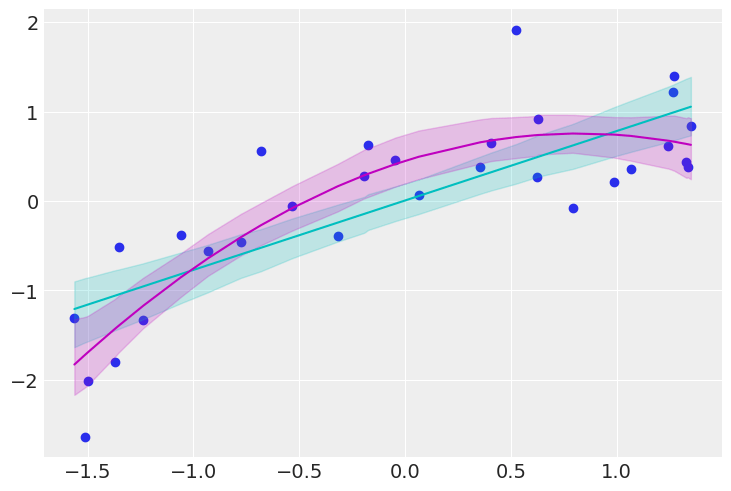
idx = np.argsort(x)
post_1_w0 = trace_1.posterior["w0"].values.reshape(-1)
post_1_w1 = trace_1.posterior["w1"].values.reshape(-1)
post_2_w0 = trace_2.posterior["w0"].values.reshape(-1)
post_2_w1 = trace_2.posterior["w1"].values.reshape(-1)
post_2_w2 = trace_2.posterior["w2"].values.reshape(-1)
sig_1 = az.hdi(trace_1.posterior, hdi_prob=0.90)["mu"].values[idx]
sig_2 = az.hdi(trace_2.posterior, hdi_prob=0.90)["mu"].values[idx]
plt.scatter(x, y)
plt.plot(x[idx], np.mean(post_1_w0[idx])+np.mean(post_1_w1[idx])*x[idx], c="c")
plt.plot(x[idx], np.mean(post_2_w0[idx])+np.mean(post_2_w1[idx])*x[idx]+np.mean(post_2_w2[idx])*x[idx]**2, c="m")
plt.fill_between(x[idx], y1=sig_1[:,0], y2=sig_1[:,1], color="c", alpha=0.20)
plt.fill_between(x[idx], y1=sig_2[:,0], y2=sig_2[:,1], color="m", alpha=0.20)
plt.show()
情報量基準を見る
pm.compute_log_likelihood(trace_1, model=model_1)
pm.compute_log_likelihood(trace_2, model=model_2)
print(az.waic(trace_1))
print(az.waic(trace_2))
df_comp_waic = az.compare({"model1": trace_1, "model2": trace_2})
az.plot_compare(df_comp_waic, insample_dev=False)
Computed from 2000 posterior samples and 30 observations log-likelihood matrix.
Estimate SE
elpd_waic -31.16 4.15
p_waic 3.00 -
There has been a warning during the calculation. Please check the results.
Computed from 2000 posterior samples and 30 observations log-likelihood matrix.
Estimate SE
elpd_waic -26.14 3.64
p_waic 3.61 -
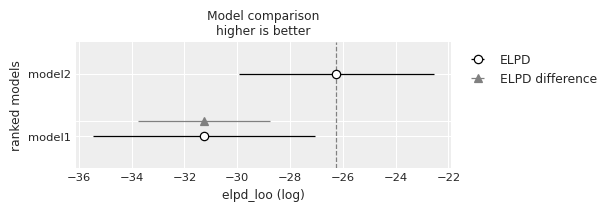
図の見方は以下のドキュメントのようになっている。最良のモデルは灰色の点線がつく。
https://www.pymc.io/projects/docs/en/stable/learn/core_notebooks/model_comparison.html
The empty circle represents the values of LOO and the black error bars associated with them are the values of the standard deviation of LOO.
The value of the highest LOO, i.e the best estimated model, is also indicated with a vertical dashed grey line to ease comparison with other LOO values.
For all models except the top-ranked one we also get a triangle indicating the value of the difference of WAIC between that model and the top model and a grey error bar indicating the standard error of the differences between the top-ranked WAIC and WAIC for each model.
情報量基準値の絶対値が小さいのは曲線モデルだった。これは直線モデルより良いモデルであることを示す。
情報量基準の解釈と使用方法
モデルの平均化 (model averaging): モデルセット
他の方法として全ての
事後予測チェック
モデルにフィットさせたデータを用いて一致性をチェックする。
fig, axes = plt.subplots(1, 2, figsize=(10,3))
axes = axes.ravel()
for i in range(len(post_1_w0)):
axes[0].scatter(x, post_1_w0[i] + post_1_w1[i]*x, color="c", alpha=0.25)
axes[1].scatter(x, post_2_w0[i] + post_2_w1[i]*x + post_2_w2[i]*x**2, color="m", alpha=0.25)
axes[0].plot(x[idx], np.mean(post_1_w0[idx])+np.mean(post_1_w1[idx])*x[idx], c="c")
axes[1].plot(x[idx], np.mean(post_2_w0[idx])+np.mean(post_2_w1[idx])*x[idx]+np.mean(post_2_w2[idx])*x[idx]**2, c="m")
axes[0].scatter(x, y, color="b")
axes[1].scatter(x, y, color="b")
plt.show()

4. ベイズファクター
ベイズファクター(Bayes Factor): モデルが望ましい評価、比較する一般的な方法。ただし事前分布の形状には殆ど影響のないようなパラメータの数値に敏感で、さらにその計算は(代数的には)難解な問題がある。PyMCを使えば計算は勝手にしてくれる。
- 1 < BF 3: Anecdotal(言及するほどでもない)
- 3 < BF < 10: Substantial, Moderate, Positive(そこそこ)
- 10 < BF < 30: Positive, Strong(かなり望ましい)
- 30 < BF < 100: Very strong(非常に望ましい)
- 100 < BF: Decisive, Extreme(極端に望ましい)
ベイズモデル比較
PRML 3.4
次の問題設定を考える。
-
M \{ \mathcal{M}_m \} - モデルは観測されたデータ
\mathcal{D} p(\mathcal{M}_m|\mathcal{D}) \bold{t} - 入力値の集合
\mathcal{X} - モデルの不確かさ
p(\mathcal{M}_m)
この設定で、モデルの事後分布
ベイズファクターはこのモデルエビデンスの比、つまりモデルの適切さの比を示していると言え、分子のモデルが分母のモデルより優れていれば1以上の値になる。
設定より、事後分布
混合分布なので、全体の予想分布が、個々のモデルの予測分布
といいつつ、最も単純明快なモデル平均は
1つのパラメータ
周辺尤度は「パラメータを事前分布からサンプリングした時に手元にある
次の設定を考えることで、モデルエビデンスを変形して、表現力と複雑さを分離して示すことを考える。
- 事後分布が最頻値
w_{\text{MAP}} Δw_{\text{post}} - 事前分布は大きく平べったい一様分布として、その幅は
Δw_{\text{prior}} - これらを長方形で近似し、面積
Δw_{\text{post}} × p(w_{\text{MAP}}|\mathcal{D},\mathcal{M}_m) Δw_{\text{prior}} × p(w|\mathcal{M}_m) - 分布は面積の総和が1になるので
p(w|\mathcal{M}_m) = \frac{1}{Δw_{\text{prior}}}
以上の設定から、事後分布を
以上の変形で対数モデルエビデンスは次の2項に分けられる。
- 最適なパラメータのときのデータへのfit具合。(通常モデルが複雑だと一般にはfitしやすくなる)(事前分布が一様分布の場合の対数尤度に相当)
- 事前分布に対して事後分布がデータに強くfitしすぎる場合の正則化。(
\frac{Δw_{\text{prior}}}{Δw_{\text{prior}}} - パラメータ数
c
これを解釈すると、バランスがいいモデル選択が次の方法でできることが理解できる。
- まず事前分布
p(\bold{w}|\mathcal{M}_m) \bold{w} - ドローした
\bold{w} p(\mathcal{D}|\bold{w},\mathcal{M}_m)
- 単純なモデルは自由度が少ないので生成されるデータは多様性に乏しく、そのデータの分布
p(\mathcal{D}|\mathcal{M}_m) - 逆に複雑なモデルはデータの分布が多様で
p(\mathcal{D}|\mathcal{M}_m)
-
\{ \mathcal{M} \} \mathcal{D}_d
PyMCでの計算
ベイズファクターの計算は階層モデルとして定式化できる。複数の競合したモデルに対して同時に推論を行い、モデル間の離散変数を使う。
分数部分がオッズであることに注意。
# コイン投げモデル2つを比較する
coins = 100
heads = 32
y_d = np.repeat([0, 1], [coins-heads, heads]) # shape [36]
# -> [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
# ここでは事前分布のみ異なるモデルを比較するが、尤度など他のものが異なるものでも可能
with pm.Model() as model:
p = np.array([0.5, 0.5])
midx = pm.Categorical("midx", p=p)
m0 = pm.Beta("model0", alpha=4, beta=8)
m1 = pm.Beta("model1", alpha=8, beta=4)
theta = pm.Deterministic("theta", pm.math.switch(pm.math.eq(midx, 0), m0, m1)) # switch: if arg0 then arg1 else arg2
y = pm.Bernoulli("y_pred", p=theta, observed=y_d)
trace = pm.sample(2000, chains=2, cores=1)
az.plot_trace(trace, var_names=["midx", "model0", "model1", "theta"])
az.plot_autocorr(trace, var_names=["midx", "model0", "model1", "theta"], combined=True)
pm1 = trace.posterior["midx"].values.mean()
pm0 = 1 - pm1
bf = (pm0*p[1])/(pm1*p[0]) # p(M0|t)p(M1)/p(M1|t)p(M0)
print(f"{pm0} {pm1}, {bf}")
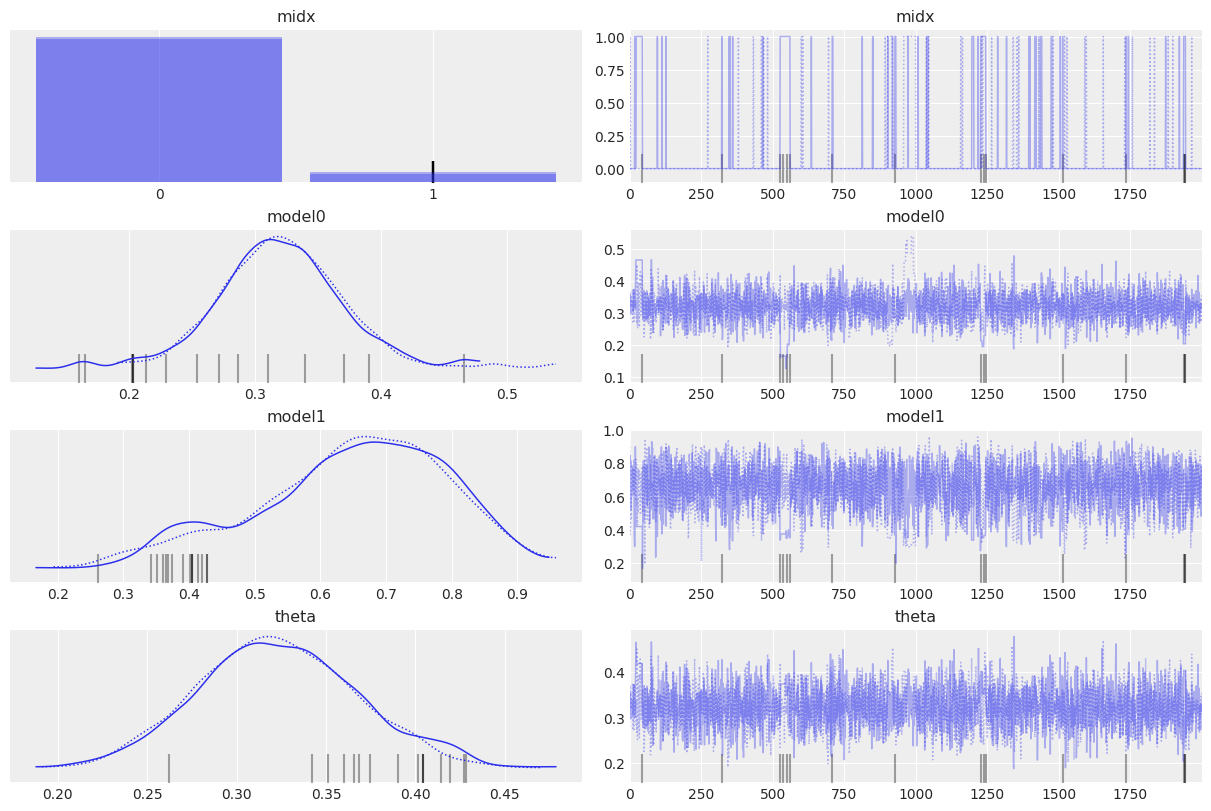

model0のベイズファクターが15ほどになり、これはmodel1より望ましいモデルであることを示している。
5. ベイズファクターと情報量基準
ベイズ主義者がベイズファクターを好まない理由として事前分布に対して敏感過ぎる点がある。
ベイズファクターや情報量基準が何をしているか見てみる。
次の2つのモデルは異なる事前分布を持つが、事前分布の効果が無視できるほど多くのデータを持っていることにより同じような分布に収束している。
with pm.Model() as model_bf0:
theta = pm.Beta("theta", alpha=4, beta=8)
y = pm.Bernoulli("y_pred", p=theta, observed=y_d)
trace_bf0 = pm.sample(2000, chains=2, cores=1)
az.plot_trace(trace_bf0, var_names=["theta"])
with pm.Model() as model_bf1:
theta = pm.Beta("theta", alpha=8, beta=4)
y = pm.Bernoulli("y_pred", p=theta, observed=y_d)
trace_bf1 = pm.sample(2000, chains=2, cores=1)
az.plot_trace(trace_bf1, var_names=["theta"])
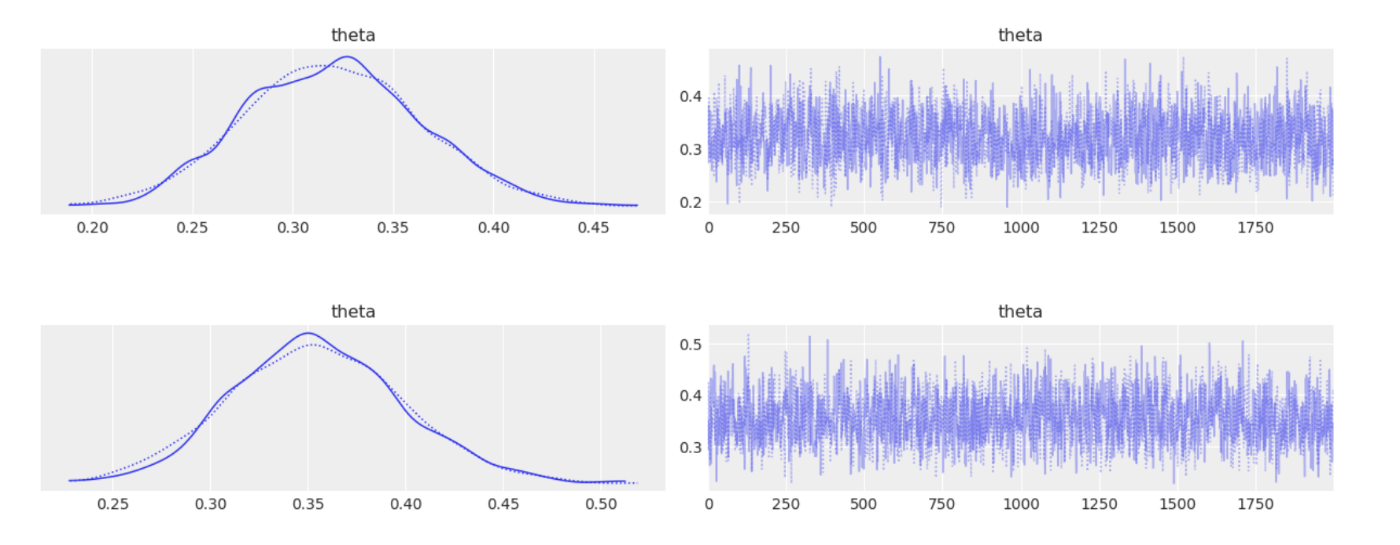
post_bf0 = trace_bf0.posterior["theta"].values.mean(axis=0)
post_bf1 = trace_bf1.posterior["theta"].values.mean(axis=0)
print(post_bf0.mean(), post_bf1.mean())
pm.compute_log_likelihood(trace_bf0, model=model_bf0)
pm.compute_log_likelihood(trace_bf1, model=model_bf1)
print(az.waic(trace_bf0))
print(az.waic(trace_bf1))
df_comp_waic = az.compare({"model1": trace_bf0, "model2": trace_bf1})
az.plot_compare(df_comp_waic, insample_dev=False)
Computed from 4000 posterior samples and 100 observations log-likelihood matrix.
Estimate SE
elpd_waic -63.62 3.59
p_waic 0.93 -
Computed from 4000 posterior samples and 100 observations log-likelihood matrix.
Estimate SE
elpd_waic -63.79 2.84
p_waic 0.83 -
情報量基準的には、データ数が多いので事前分布の効果が薄れて同じモデルになっているのがわかる。
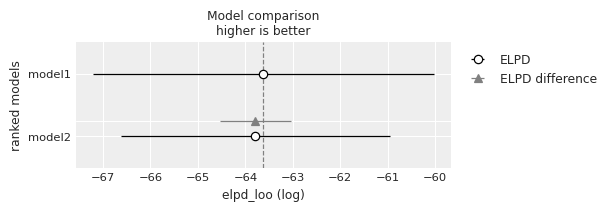
ベイズファクターの計算では、モデルが殆ど同じ推論を行っていたとしても、事前分布の適合の良さでいいモデルを選ぶことができる。
情報量基準では、データを増やしてモデルの相対的な差が小さくなると、
感想
モデルの複雑さについての直感的な理解を、PyMCの実装とPRMLの理論面を両方得られた。でもPRMLのほうは何回読んでも難しい。
情報量基準、特に最近よく聞くWAICについてはある程度自前で求めることができるようになったが、ベイズファクターについては教科書のモデル以外では自作できるか怪しい。もう少し馴染んでおかないと実用できないと思う。
twitter(旧X)でベイズの人がベイズファクター推しだったので、この本ではあまり人気がないと言われている部分は実感がない。実際確かに事前分布までみてモデルを選ぶという意味では高度でいいと思うが、事後分布として同じに収束したならそれで良いのでは...?という感じがする。実用ではどうなのだろうか。
Discussion