Type 2 Charstring を読み解いて OpenType フォントを描画してみる


フォントのパスデータはどこにある?
前回の拙記事にて解説したとおり、OpenType は内部構造として PostScript をアウトライン構造に持つものと、TrueType を由来とするものの 2 種類に分かれ、前者の場合は OpenType 形式の中に CFF (Compact File Format) 形式のデータが内包される形となるため、解読に多大な労力が必要となります。
CFF 形式において、フォントの中核であるパスデータは CharStrings に格納されているのですが、この CharString はさらに、CFF と併せて使用することを想定した Type 2 と呼ばれる別のフォーマットにて記述されています。
本稿では Type2 の仕様を概説した上で、OpenType フォントからをパスデータを実際に描画してみることを目的とします。OpenType 及び CFF のファイルフォーマットに知見があることを前提とするため、以下の記事も併せてご参照ください。
- ヒラギノ角ゴシックの CMap を読む
https://zenn.dev/inaniwaudon/articles/039e82d61254ed - 忙しい人のための CFF テーブル入門: PDF にOpenTypeフォントのサブセットを埋め込むには
https://zenn.dev/inaniwaudon/articles/832ecf5180d527
CharString の仕様
CharString の全仕様は下記 PDF に纏まっています。今回はこの中からパスデータの抽出に必要な項目のみを取捨選択して扱い、ヒント情報等に関しては割愛します。
構成
CharString は以下の形式からなる 8 ビットのバイト列から構成されます。{} はグループを表し、その他は正規表現と同等です。
w? {hs* vs* cm* hm* mt subpath}? {mt subpath}* endchar
-
w?
幅 width を表す。文字列が CFF の Private DICT に定義されるdefaultWidthXと異なる場合は、同じく Private DICT 内に定義されるnominalWidthXとの差分を記述する。 -
{hs* vs* cm* hm* mt subpath}
ラスタライザに対するヒント情報を記述する。 -
{mt subpath}*
パスを記述する。mt は moveto の略で、適当な座標にポイントを置いてから輪郭を描画する必要がある。 -
endchar
endcharオペレータをもって CharString は終了する。
バイト列には、引数となる0個以上の数値とオペレータが組になって出現し、逆ポーランド記法として表されます。例えば以下の場合は、10 -20 が rmoveto パラメータの引数で、10 20 40 0 10 -20 が rrcurveto パラメータの引数になります。
10 -20 rmoveto 10 20 40 0 10 -20 rrcurveto
エンコーディング
整数およびオペレータはテキストではなく、独自のエンコーディングを用いて表されます。
数値
数値は 1―5 バイトの可変長数値表現を用いて記述されます。上位バイトから v, w とするとき、数値は以下の通りに表現されます。CFF のエンコーディングと類似していますが、実数の扱い等に微妙な差異があります。
| 1バイト目 | 値の範囲 | 値の算出方法 |
|---|---|---|
| 28 | 整数 -32768―32767 |
v に続く 2 バイトを 16 ビット符号付き整数(short)として解釈する |
| 32―246 | 整数 -107―107 | v - 139 |
| 247―250 | 整数 108―1131 | (v - 247) * 256 + w + 108 |
| 251―254 | 整数 –108―1131 | -((v - 251) * 256) - w - 108 |
| 255 | 実数 |
v に続く 4 バイトを 32 ビット固定小数点数として解釈する。16 ビットが小数部分 |
オペレータ
出現したバイト v が 0―11, 13―18, 19, 20, 21―27, 29―31 の範囲内であった場合は、そのままオペレータとして扱います。v=12 の際は後続のバイトも併せてオペレータを判断します。
オペレータと機能との対応表は Type 2 の仕様書の Appendix A に掲載されています。そのうち、今回はパスデータの解析に必要となった 13 種類を抑えます。
moveto 系
任意の座標にポイントを移動するオペレータです。
| オペレータ名 | 指定 | 説明 |
|---|---|---|
| rmoveto | dx1 dy1 21 |
ポイントを相対座標系における (dx1, dx2) に移動させる |
| hmoveto | dx1 22 |
ポイントを dx1 に水平移動させる |
| vmoveto | dy1 4 |
ポイントを dy1 相対的に垂直移動させる |
lineto 系
現在の座標から指定した座標まで直線を繋ぐオペレータです。
| オペレータ名 | 指定 | 説明 |
|---|---|---|
| rlineto | {dxa dya}+ 5 |
(dxa, dya) に直線を引く。複数の座標を指定した場合は、順に直線を引いてゆく |
| hlineto |
dx1 {dya dxb}* 6 または {dxa dyb}+ 6
|
まず dx1(または dxa) の長さの直線を水平方向に引き、続いて dya の長さの直線を垂直方向に引く……の繰り返し |
| vlineto |
dy1 {dxa dyb}* 7 または {dya dxb}+ 7
|
hline の逆 |
curveto 系
現在の座標から指定した座標までのベジェ曲線を描画するオペレータです。SVG 等の指定に比べても大分複雑な印象を受けます。
| オペレータ名 | 指定 | 説明 |
|---|---|---|
| rrcurveto | dxa dya dxb dyb dxc dyc}+ 8 |
一般的な三次元ベジェ曲線。(dxa, dya), (dyb, dyb) はハンドル(方向線)、(dxc, dyc) はアンカーポイント(端点) |
| hhcurveto | dy1? {dxa dxb dyb dxc}+ 27 |
端点の接線が水平な曲線。引数が偶数個の場合 dxa 0 dxb dyb dxc dyb rrcurveto と、引数が奇数個の場合 dxa dy1 dxb dyb dxc dyb rrcurveto と同等 |
| vvcurveto | dx1? {dya dxb dyb dyc}+ 27 |
hhcurveto の逆。端点の接線が垂直な曲線 |
| hvcurveto |
dx1 dx2 dy2 dy3 {dya dxb dyb dxc dxd dxe dye dyf}* dxf? 31 または {dxa dxb dyb dyc dyd dxe dye dxf}+ dyf? 31
|
始点の接線が水平(→垂直→水平)と交互に移り変わる曲線。水平の場合は dx1 0 dx2 dy2 dx2 dy3 rrcurveto と、垂直の場合は 0 dya dxb dyb dxc dyb rrcurveto と同等 |
| vhcurveto |
dy1 dx2 dy2 dx3 {dxa dxb dyb dyc dyd dxe dye dxf}* dyf? 30 または {dya dxb dyb dxc dxd dxe dye dyf}+ dxf? 30
|
hvcurveto の逆。始点の接線が水平(→垂直→水平)と交互に移り変わる曲線 |
サブルーチン
サブルーチン(後述)を呼び出すオペレータです。
| オペレータ名 | 指定 | 説明 |
|---|---|---|
| callsubr | subr# 10 |
ローカルサブルーチンを呼び出す |
| callgsubr | globalsubr# 10 |
グローバルサブルーチンを呼び出す |
ヒント
読み飛ばすため最低限の知識のみを概説します。
ヒント情報を扱うオペレータである hintmask は少々厄介で、このオペレータに限ってポーランド記法(前置記法)を採用しています。hintmask はステム[1]情報を記述する hstemhm, vstemhm オペレータと共起し、以下のような記法で用いられます。2 つの数値で 1 組のステム情報を表しています。
y dy {dya dyb}* hstemhm x dx {dxa dxb}* hintmask mask
mask の部分は、各ビット毎にステムを有効にするか否かの情報が与えられます。ステムの組数分のビット長が要求されており、下位ビットは 0 埋めされます。このあたりは後述する実装パートでより詳しく見ていきます。
サブルーチン
Type 2 フォントでは、フォント内に出現する共通の処理をサブルーチンとして定義することで容量の圧縮を図っています。展開されたサブルーチンは通常の Charstring と同様に扱われ、endchar, return いずれかのオペレータが出現することで終了します。サブルーチンからはスタックの上限である 10 回まで再帰的にサブルーチンを呼び出すことも可能です。
さらに、サブルーチンは以下の 2 通りに分かれます。
-
ローカルサブルーチン(subr)
現在のフォントのみから参照されるサブルーチン -
グローバルサブルーチン(gsubr)
同一の FontSet 内のすべてのフォントで共有されるサブルーチン
FontSet という新たな概念が出てきました。実は、CFF は FontSet と呼ばれるフォントの集合体に複数のフォントを内包することで、コンパクトなバイナリ表現を実現しています。対象の CFF を構成するフォント数は、CFF の String INDEX を参照することで確認できます。
ただし、OpenType の場合は FontSet 内に 1 つのフォントしか含まれないことが保証されているため[2]、基本的には最初に出現したフォントを対象にすれば問題ありません。
試しに手持ちの「A-OTF リュウミン Pr6N R-KL」を検証してみたところ、String INDEX はRyuminPr6N-Reg の 1 つのみを保持しており、リュウミンはやはり単一のフォントから構成されていることが判明します。
サブルーチンは Charstring 内に存在する訳ではなく、CFF 内の Local/Global Subrs INDEXes に別途格納されています。
グローバルサブルーチンの格納
グローバルサブルーチンの場合は、String INDEX に後続する INDEX Data が Global Subrs INDEXes に該当します。グローバルサブルーチンが一つも存在しない場合は空の INDEX Data として表現されます。
ローカルサブルーチンの格納
ローカルサブルーチンの場合は少し複雑で、 Top DICT → Private DICT → Local Subrs INDEXes と参照します。具体的には以下の手順を辿ります。
- CFF 内の Top DICT に存在する
Private(18) オペレータをキーとするエントリを参照する。ここに Private DICT のサイズとオフセットが記述されている。 - Private DICT に移り、この中に存在する
Subr(19) のオペレータをキーとするエントリを参照する。ここに Local Subrs INDEXes のオフセットが記述されている。
ただし、我々が扱う日本語のような CJK (Chinese-Japanese-Korean) 言語では CID-keyed[3] と呼ばれる仕組みが採用されています。対象のフォントが CID-keyed Fonts であった場合、Private DICT への参照は Top DICT には記述されておらず、以下の手法を取ります。
なおフォントが CID-keyd Font か否かは、Top DICT に ROS[4](12 30) オペレータが存在するか否かで確認できます。
- Top DICT 内の
FDArrayオペレータが示すエントリを基に Font DICT INDEX を参照する。 - FDSelect を用いてFont DICT INDEX の中からグリフに対応する Font DICT を同定する。詳細は前回記事を参照。
- 該当する Font DICT 内に存在する
Private(18) オペレータが示すエントリを基に Private DICT を参照する。 - Private DICT に移り、この中に存在する
Subr(19) のオペレータをキーとするエントリを参照する。ここに Local Subrs INDEXes のオフセットが記述されている。
いずれの場合も、Private DICT 内に Subr オペレータが存在しない場合があるため注意が必要です。
サブルーチンの参照
Local/Global Subrs INDEXes は INDEX Data として格納されています。
再度 callsubr の用例を確認してみます。
subr# 10
subr# にはサブルーチンのインデックスを指定しますが、この際、実際に参照される Local/Global Subrs INDEXes 内のサブルーチンは、subr# にバイアスを加えた値になります。サブルーチンの総数に応じて、バイアスは以下の通りに決定されます
| サブルーチン(subr/gsubr)の数 | バイアス |
|---|---|
| ― 1239 | 107 |
| 1240 ― 33899 | 1131 |
| 33900 ― | 32768 |
OpenType を描画してみる
OpenType を描画する準備は整いました! OpenType フォントからパスデータを取り出すまでの手順を総括すると、以下の通りとなります。そのうち今回は 3, 4, 5. の過程を追ってみます。
- OpenType の cmap テーブルを参照し、CMap を通じて Unicode 等の文字コードから CID (Character Identifer) に変換する。
- OpenType の CFF テーブルを参照する。Charsets から CID を GID (Glyph Identifier) に変換する。
- CFF テーブル内の Local/Global Subrs テーブルを参照し、サブルーチンを取得する。
- GID を用いて Charstrings の中から対応する Charstring を取得する。
- サブルーチンを展開しながら、Charstring をパースする。
実装上の注意
ハマったポイントを一つご紹介します。
一度デコードを行ってから hintmask のスキップ処理を行うと、hintmask の直後のビット列を適当な数値やオペレータとして誤って解釈してしまう恐れがあります。一方で hstem 系のオペレータを予めデコードした状態でないとビット列の長さは確定しないため、極めて厄介です。
例えばステムが 5 組存在する場合に、以下の例が考えられます。
-
0001 0011 1111 1000 0011 1010のビット列が出現する。これは本来hintmask 0b11111000 58と解釈するべきである。 -
0001 0011をhintmaskオペレータに変換し、スタックに追加する。 - スキップ処理を行う前にデコードを行うため、
1111 1000 = 248が出現したと解釈する。 - 248 は 108―1131 の整数の1バイト目を表すため、連続する
0011 1010 = 58と併せて解釈しようとする。(248 - 247) * 256 + 58 + 108より422をスタックに追加する。 -
hintmask 422が結果として得られる。ここで hintmask + 後続の1バイトに対して読み飛ばしを行うため、本来は必要であった58が消失する。
ここで Charstring 全体の構成を改めて確認してみます。
w? {hs* vs* cm* hm* mt subpath}? {mt subpath}* endchar
hintmask 自体はサブパスの途中で出現する可能性がありますが[5]、その他のヒント情報に関しては、Charstring の先頭にのみ出現することが保証されています。従って下記の順序で処理を実施すると良さそうです。
-
hs*, vs*に表されるヒント情報が終了するまで、Charstring を先頭から読み進める。この際、サブルーチンの呼び出しがあれば再帰的に展開する。 - ステムの組
n - ヒント情報の後から再度デコードし、サブルーチンの呼び出しがあれば再帰的に展開する。
hintmaskが出現した際は、Math.ceil(n / 8)バイトを読み飛ばす。
パスデータの取得
モリサワフォントである A-OTF リュウミン Pr6N R-KL を対象に、「あ」のグリフを表す CID 843 のパスデータを取得し、SVGとして描画します。CID 843 は GID 842 に対応し、この GID に紐付けられた Charstring は以下の通りです。
-32 9 48 48 275 28 67 47 hstemhm
178 53 153 47 -5 79 228 69 hintmask -868
5 32 callsubr
-30 15 5 -10 -1118 callsubr
histmask が出現しました。前置された hstemhm オペレータの前方・後方に位置する引数は 8 個ずつであるため、計 8 組のステム情報を表しています。したがって以後、hstemhm オペレータ及びその引数に加え、hintmask と後続するすなわち 1 バイト(ここでは -868)を読み飛ばすことでヒント情報を無視することができます。
すなわち、以下の部分がパス構築に必要なデータです。
5 32 callsubr
-30 15 5 -10 -1118 callsubr
ここから、callsubr オペレータによって呼び出されたサブルーチンを展開します。サブルーチン内部でも再帰的にサブルーチンが呼び出されており、計4回の callsubr オペレータが使用されていました。
5 -32 rmoveto
163 5 131 75 140 vvcurveto
50 -16 103 -161 30 vhcurveto
-12 25 -29 25 -46 1 15 -24 5 -9 2 -13 rrcurveto
(中略)
-47 -20 rmoveto
-1 -71 8 -47 12 -45 rrcurveto
-35 -48 -64 -35 -29 hhcurveto
-8 -23 0 35 61 67 93 86 44 hhcurveto
endchar
あとは、オペレータを SVG のパスコマンドに変換していきます。得られたパスコマンドは以下の通りです。外側のパスと、複合パスとして機能し、2 つの穴を表現するパスの計 3 個で構成されていることが読み取れます。
m 508 32 c 163 -5 294 -80 294 -220
c 0 -50 -16 -153 -177 -183
(中略)
c 4 -6 23 -31 28 -36 c 36 9 109 48 109 139
c 0 130 -107 194 -225 223
m -77 -349 c 53 -19 93 -22 126 -22
c -5 13 -31 87 -108 165 c -15 -45 -21 -81 -18 -143
m -47 20 c -1 71 7 118 19 163 c -48 35 -112 70 -141 70
c -8 0 -31 0 -31 -35 c 0 -61 67 -154 153 -198
これを SVG の path 要素の d 属性として与えることで、無事にブラウザでパスデータを表示することができました!
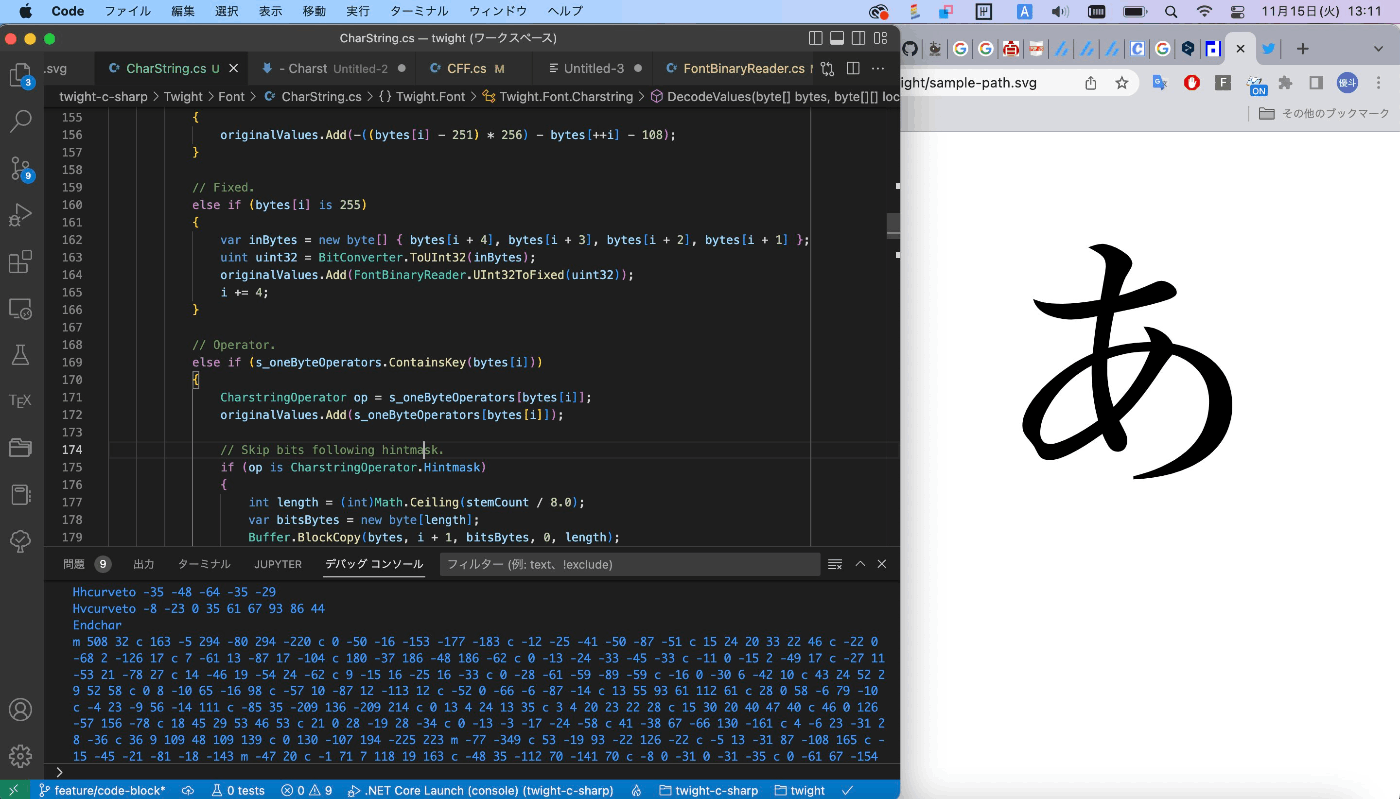
人間が読むにはまだ辛いですが、CFF よりかは読みやすいフォーマットであると感じます。
参考文献
- Adobe Systems Incorporated, “The Type 2 Charstring Format Technical Note #5177,” 2000, https://adobe-type-tools.github.io/font-tech-notes/pdfs/5177.Type2.pdf
- Adobe Systems Incorporated, “The Compact FontFormat Specification, Technical Note #5176,” 2003, https://adobe-type-tools.github.io/font-tech-notes/pdfs/5176.CFF.pdf
- https://www.screen.co.jp/ga_product/sento/products/new0.html
- Microsoft, “OpenType® Specification Version 1.9,” 2022, https://learn.microsoft.com/en-us/typography/opentype/spec/
Discussion