初めに
主にToB向けSaaSのWebアプリケーションの開発を行っている@gontaと申します。
普段フロントエンドエンジニアとしてお仕事をする中でSEOを向上させるような要件の開発を行っているわけではないのですが、改めてSEOとその周辺知識に関しての学んだ知識を整理し、以降の開発に活かせれるように知識をまとめてみました。
誤った理解等がある箇所もあるかと思いますのでおかしな点がありましたらコメントをいただけますと幸いです。
対象読者
webアプリケーションの開発をしているけど、SEOってなんだろう?SPAアプリケーションだったらとりあえずSSRしとけばいいのかな?くらいの温度感の人が、見ていただくとより理解が深まるのではないかと思います。
前提
私もフロントエンド領域でお仕事をしてはいますが、SEOコンサルタントのようなSEOのスペシャリストではないので、私が調べた中で
- 公式情報であるGoogle Search Central(Google検索セントラル)に記載がある内容
- 2次情報の中でも信頼できる
という点を意識して出来るだけ参考にさせてもらったwebサイトのページなどを引用しながら説明をしていきたいと思います。
また、GoogleはSEOのアルゴリズム自体を公開をしておりません。
なので特定の施策をしたからといって、SEO(検索エンジン最適化) がされるというものでもないという点はご理解ください。
SEOに関係するような各用語やその他周辺の知識について説明
開発のアプリケーションエンジニアが全てをコントロールできるわけではないのと、実装と関係がない箇所もあるのですが、SEOに使われている各用語等を理解することが、全体を理解をする上で大事だと考えています。
なので最初に一部用語や周辺の知識について引用を用いながらご説明をさせていただきます。
SEOとは?
以下は公式の引用です。
検索エンジン最適化は、サイトを検索エンジン向けに改善するプロセスです。
検索への上位表示や、検索をした時の表示の仕方を最適化するものだという理解をしています。
クローラーとは?
以下引用です。
前述のとおり、クローラーとは検索エンジンが検索の順位を決めるための要素を、サイトを巡回して収集してくるロボット(bot)のことです。這い回るという意味の【crawl】から、このように呼ばれています。
Google Bot
Google検索におけるGoogleのBotにあたります。このGoogle Botにユーザーに閲覧をさせたいページをいかにGoogle Botにクロールをさせるかを考えて実装をする必要があります。不適切な対応を行なってしまった場合に対象ページをクロールされなくなる危険性があるので注意が必要です。
被リンク
以下は引用です。
被リンクとは、外部サイトから自サイトに向けられたリンクのことを意味します。
このようにして信頼のあるサイトから自身のサイトのリンクが共有してもらうことでSEO効果期待できるようです。
内部リンク
以下は引用です。
内部リンクとは、Webサイト内のページ同士をつなぐリンクのことです。
インデックス
以下は引用です。
ページがクロールされると、Google はそのページの内容を把握しようとします。このステージはインデックス登録と呼ばれ、<title> 要素や alt 属性など、テキスト コンテンツや主要なコンテンツのタグや属性、そして画像や動画などを処理して分析する作業が含まれます。
このGoogleのデータベースに登録することを「インデックス」と呼んでいるようです。
Google検索における3つのステージ
下記引用です。
Google 検索には 3 つのステージがあります(すべてのページが各ステージを通るわけではありません)。
- クロール: Google は、クローラーと呼ばれる自動プログラムを使用して、ウェブ上で見つけたページからテキスト、画像、動画をダウンロードします。
- インデックス登録: Google は、見つけたページ上のテキスト、画像、動画ファイルを解析し、その情報を Google インデックス(大規模なデータベース)に保存します。
- 検索結果の表示: ユーザーが Google で検索すると、Google はユーザーの検索語句に関連する情報を返します。
エンジニアはこれらの クロール => インデックス登録 => 検索結果の表示 の流れを理解して、どのようにしたらクロールをさせることが出来のか?どうすればインデックス登録をさせることができるのか?を理解しておく必要がありそうです。 逆に誤った対応をしてしまうと、必要なページに対して、クロールやインデックス登録をさせないような実装をしてしまうこともあるため注意が必要です。
外部対策と内部対策
外部対策について
下記引用です。
外部対策(外部施策)とは、Webサイトの外側にあるGoogleの評価要素(=外部要素)に対するアプローチです。
具体的には、次の2つを獲得するための施策がメインとなります。
- 被リンク:他のWebサイトに設置された自サイトへのリンク
- サイテーション:他のWebサイトやSNSにおいて、自サイトや会社・サービスのことが言及されること。評判
Googleは「ウェブ上の民主主義は機能する」としており、被リンクを「(人気)投票」と解釈します。
これは「多くのWebサイトで紹介(引用)されているWebサイトは良いサイトであるはずだ」という考え方にもとづいています。
内部対策について
下記引用です。
内部対策(内部施策)とは、サイト内部の要素を整備する施策です。
「ロボットである検索エンジンから適切な評価が受けられるような環境づくり」と言っても良いでしょう。
https://webma.xscore.co.jp/study/internal-seo-external-seo/
こちらの内部対策についてはエンジニアが実装をする時に気をつけるべきところに該当をします。
以下にクローラーがサイトを巡回しやすくして、各ページをインデックスできるように考える必要がありそうです。
robots.txt
以下引用です。
robots.txt ファイルとは、検索エンジンのクローラーに対して、サイトのどの URL にアクセスしてよいかを伝えるものです。これは主に、サイトでのリクエストのオーバーロードを避けるために使用するもので、Google にウェブページが表示されないようにするためのメカニズムではありません。Google にウェブページが表示されないようにするには、noindex を使用してインデックス登録をブロックするか、パスワードでページを保護します。
こちらの記事も参考にさせていただきました。
Google公式ヘルプを確認すると、Googleは「大規模サイトや、更新頻度が高い中規模サイトでなければ、robots.txtは設置しなくても構わない」と書かれている。
Google公式ヘルプに書かれているとあるのですが、自分でそれを見つけることができませんでした。ただ他記事を参考しても同様のことを書かれているものもあったので信憑性は高いものだと思われます。
noindex
インデックスをさせないようにする目的の部分でrobots.txt と若干用途が被っているように感じたのですが、動作的には下記のような違いがあるようです。
以下引用です。
robots.txtがクロールをブロックするのに対して、noindexはインデックスをブロックします。
robots.txtでクロールをブロックしても検索結果に表示されることがある
noindexはインデックスをブロックするので検索結果に表示されない
個人的に思ったのが、クロールできないようにすれば基本的にインデックスをされないのかな?という風に思ったのですが、確実にインデックスをさせないためにはnoindexをちゃんとつけておく必要があるようです。
E-E-A-T(旧E-A-T)とは
ここはエンジニアがあまり関係するところではないのですが、SEOを語る上での重要な指標になるので紹介をさせていただきます。
以下は引用です。
Google の自動システムは、さまざまな要因に基づいて優れたコンテンツをランク付けするように設計されています。関連するコンテンツを特定した後、最も役に立つと判断されたコンテンツに高い優先順位を付けます。そのために、どのコンテンツが、エクスペリエンス(Experience)、高い専門性(Expertise)、権威性(Authoritativeness)、信頼性(Trustworthiness)、すなわち E-E-A-T の面で優れているかを判断するための要素の組み合わせを特定します。
こちら元々はE-A-T(専門性、権威性、信頼性)の3つだったのですが、こちらのブログで発表がされている通りExperience(経験)が追加をされたことにより、E-E-A-Tとなったようです。
公式ガイドラインにE-E-A-Tについてはこちらをご確認ください。「Experience, Expertise, Authoritativeness, and Trust (E-E-A-T) 」に記載をされています。
Experience(経験)
以下公式ガイドラインの抜粋を日本語に翻訳したものです。
コンテンツ制作者が、そのトピックに必要な実体験や人生経験をどの程度持っているかを考慮する。
を持っているかを考慮する。多くの種類のページは、個人的な経験が豊富な人が作成すると信頼でき、その目的を十分に達成できる。
こちら具体で説明をすると例えばとあるAmazonのようなECサイトがあったとします。
そこで全く同じでのAサイトの商品、Bサイトの商品があったとして、
この時にAサイトの商品の方には特にレビューがなかったとして、Bサイトの商品の方にはその商品を購入したユーザーのレビューコメントがなされていることが確認ができると思います。
この時のSEOの評価をする時にBサイトの商品ページにはレビューコメントで第三者からすると有益な経験に基づいた情報が載っている場合に評価をあげますよと言ったものであるようです。
よくECサイトでレビュー機能が実装をされていると思うのですが、EEATのExperience(経験)を考慮して実装をされているサイトもありそうです。
専門性(Expertise)
以下公式ガイドラインの抜粋を日本語に翻訳したものです。
コンテンツ制作者が、そのトピックに必要な知識や技術をどの程度持っているかを検討する。
トピックによって、信頼できる専門知識のレベルや種類は異なります。例えば
熟練した電気技術者のアドバイスと、電気配線の知識がないアンティーク住宅愛好家のアドバイス。
どちらが信頼できますか?
こちらも上記の通りなのですが、その情報がより専門性が高い人からの情報であるとなった場合に評価が上がる仕組みのようです。
権威性(Authoritativeness)
以下公式ガイドラインの抜粋を日本語に翻訳したものです。
コンテンツ制作者やウェブサイトが、どの程度、そのトピックに関する情報源として知られているかを検討する。
そのトピックについて ほとんどのトピックでは、公式で権威のあるウェブサイトやコンテンツ作成者は存在しませんが、存在する場合は、そのウェブサイトやコンテンツ作成者は、最も信頼性が高く、信頼できるソースの1つであることがよくあります、
そのウェブサイトやコンテンツ制作者は、多くの場合、最も信頼できる信頼できる情報源のひとつです。例えば
ソーシャル・メディア上のビジネス・プロフィール・ページが、今何が売られているかについての権威ある信頼できる情報源かもしれません。例えば
パスポートを取得するための政府の公式ページは、パスポート更新のためのユニークで公式な、権威のある情報源である。
下記サイトを拝見する限り、
- Webサイトが発信する情報元に権威があること
- 他サイトからの良質な被リンク数が多ければ、Googleは権威性のあるWebサイトであると認識する
という2点が挙げられているので、そのサイト自身が権威性を持っていることが望ましいとは思うのですが、他サイトからの被リンクを集めるなどしてSEO向上を期待したりするようです。
ただ、これもエンジニアが実装時に気をつけるものでもなさそうです。
ドメインパワー
以下引用です。
ドメインパワーとは、検索エンジンからの信頼度を数値化したもののことです。Googleを中心とした検索エンジンは被リンクやコンテンツの質や量、更新頻度によってそのサイト全体を評価します。
この検索エンジンにおける、サイト全体の評価を表す指標がドメインパワーです。詳しくは後述しますが、ドメインパワーの向上には、インデックスされるまでの時間が早くなったり、上位化されやすかったりとSEO上のメリットがあります。ドメインパワーは時間をかけて、良質なコンテンツを追加し続けることで徐々に上がっていくものです。
このドメインパワーというのが自サイトがどのくらいのものを持っているかは、他にもツールはあるようですが、このようなツールを使うことで計測ができるようです。
ドメインパワーが高いと何が良いのか?
こちらはいくつかの記事を見た上での2次情報ですが、下記のようなメリットがあるようです。
- 検索結果画面でも上位表示
- Webサイト内の情報がより早くインデックス
どうやったらドメインパワーが上がる?
こちらも引用ですが下記の施策があるようです。
具体的な内容については下記リンクをご確認ください。
- 検索エンジンから高評価を受けるページの作成
- 記事数(ページ数)を増やす
- サイト内で評価を集約する
- 更新頻度を担保する
- 被リンクを獲得する
- SEOに強いサイト構造にする
- サイトを長く運営する
- 質の低いリンクを削除
- ユーザーエクスペリエンスの最適化
サイトマップ
以下引用です。
サイトマップとは、サイト上のページや動画などのファイルについての情報や、各ファイルの関係を伝えるファイルです。Google などの検索エンジンは、このファイルを読み込んで、より効率的にクロールを行います。サイトマップはサイト内の重要なページとファイルを検索エンジンに伝えるだけでなく、重要なファイルについての貴重な情報(ページの最終更新日やすべての代替言語ページなど)も提供します。
Googleのbotがクロールを効率的にできるようにしたり、重要な情報を検索エンジに伝えたりするものみたいです。
なお、サイトマップにはいくつか種類があるようです。
XML サイトマップ
以下引用です。
XMLサイトマップとは、Webサイト内の各ページ情報(URLや優先度、最終更新日、更新頻度などの情報)を検索エンジン向けに記載したXML形式のファイル(sitemap.xml)のことです。
引用の通りで、検索エンジに対してサイトのページ情報を伝えるもののようです。
RSS、mRSS、Atom 1.0 形式のサイトマップ
私自身がmRSS、Atom 1.0とかあまり聞いたことないのですが、こういうサイトマップもあるようです。
テキスト サイトマップ
以下引用です。
サイトマップにウェブページの URL のみを指定する場合は、1 行につき 1 つの URL を記載したシンプルなテキスト ファイル形式で Google に送信できます。たとえば、サイトに 2 つのページがある場合、次のように指定してサイトマップに追加できます。
XML サイトマップがXMLで作られるのに対して、こちらは.txtを使ってURLを羅列して定義をするもののようです。
サイトマップが必要なサイトは?
以下は引用
- サイトのサイズが大きい。一般的にサイズが大きなサイトでは、すべてのページがサイト上の他のページ(少なくとも 1 ページ以上)からリンクされていることを確認するのは難しくなります。その結果、Googlebot が新規のページの一部を検出できない可能性が高くなります。
- サイトが新しく、外部からのリンクが少ない。Googlebot などのウェブ クローラーは、ページからページヘリンクをたどることによってウェブをクロールします。その結果、Googlebot が他のサイトからリンクされていないページを検出できない可能性があります。
- サイトに動画や画像などのリッチメディア コンテンツが多数含まれている、またはサイトが Google ニュースに表示されている。Google 検索でサイトマップの追加情報が考慮されます。
次の場合は、サイトマップが必要ない可能性があります。
- サイトのサイズが「小さい」。サイトのページ数がおよそ 500 ページ以下の場合にサイズが小さいと考えます。検索結果に表示する必要のあるページのみをこの合計ページ数に加算します。
- サイトのすべてのページを内部リンクが網羅している。つまり、Googlebot がホームページからリンクをたどって、サイト内の重要なページをすべて見つけられるということです。
- 検索結果に表示させたいメディア ファイル(動画、画像)やニュースページが多くない。サイトマップは、サイト内の動画ファイル、画像ファイル、またはニュース記事を Google が探して理解するうえで役立ちます。これらの結果を Google 検索の結果に表示する必要がない場合は、サイトマップが必要ない可能性があります。
ここで説明をしてくれている。
SEOを取り組んでいるアプリケーション開発に関わる人へのTips
これらの情報はエンジニア、デザイナー、プロダクトオーナー等が理解を持っていると良いサイト設計ができるのでは考えています。
パンくずリストの設置
こちらはデザイナー、プロダクトオーナーが関わる部分かと思うのですが、Google Seach Centralを見ると、サイトにはパンくずリストを設置することを推奨されているように感じます。
以下こちらは参考サイトの引用です。
ページに表示されるパンくずリストは、そのページがサイト階層内のどこに位置するかを示しており、ユーザーはサイトを効果的に理解し、移動できます。ユーザーは、パンくずリスト内の最後のパンくずから順番にさかのぼることで、サイトの階層内を 1 レベルずつ上に移動できます。
以下のサイトでも説明をいただいている内容を引用させていただくのですが、SEO上で下記のメリットが見込めそうです。
表現がわかりにくいですが、ここで言われていることはつまり、パンくずリストがあることで検索エンジンがサイトの全体像を把握しやすくなるということです。
サイトの全体像が把握しやすくなるということは、検索エンジンが正しいサイト情報に基づいた順位を設定してくれる効果が期待できるということでもあります。
また、パンくずリストは、Googleの検索結果の強調スニペットなどで、メタディスクリプションと一緒に表示させることが可能です。
ユーザー目線としてもパンクズリストがあるサイトはページの構造が分かりやすくていいですよね。サイトを作る時にはパンくずリストの設置はしっかり検討をした方が良さそうですね。
JavaScriptのSEOについての理解を深める
こちらは主にフロントエンドエンジニア向けになります。
こちらのyoutubeは「JavaScript SEO の基本を理解する」で紹介をされています。
これを見るとSPAのようなJavaScriptを使ったフロントエンドエンジニアが理解をすべき基本的な理解につながるのでオススメです。
わかりやすい URL を使用する
以下引用です。
https://www.example.com/pets/cats.html
たとえば、次の例のようにランダムな識別子だけが含まれている URL は、あまりユーザーの役に立ちません。
https://www.example.com/2/6772756D707920636174
例えばなのですがこちらのamazonのページのように詳細ページでは、こちらのようにURLに商品の名前が直接入っているようです。amazonではユーザー的にもわかりやすい、またGoogleの評価を意識して、ランダムなidをここでは使っていないのではないか??
と勝手に推測しています。

Google における URL 構造のベスト プラクティス
こちらはURL設計の担当者向けの内容になります。
一部のURLの使用例を抜粋させていただきます。
✅推奨: シンプルでわかりやすい語句を URL に使用する。
https://en.wikipedia.org/wiki/Aviation
✅推奨: ローカライズした語句を URL に使用する(該当する場合)。
https://www.example.com/lebensmittel/pfefferminz
✅推奨: 必要に応じて UTF-8 エンコードを使用する。たとえば、次の例では、URL 内のアラビア文字に UTF-8 エンコードを使用しています。
https://www.example.com/%D9%86%D8%B9%D9%86%D8%A7%D8%B9/%D8%A8%D9%82%D8%A7%D9%84%D8%A9
❌ ASCII 文字以外を URL に使用する。
https://www.example.com/نعناع
❌ 意味のない長い ID 番号を URL に使用する。
こちらについてはamazonなどで商品名を表示する際は商品名がurlに表示をされていたりするみたいです。
idからその商品が何かをわかるようできたらいいのかもしれないですね。
あとは食べログやrettyなどでも動的なid部分はuuidほど長くないようなidを作って対応をしているようなので、UUIDのような長くなるようなidはGoogleのドキュメントに従うのであれば、避けた方がいいのかもしれません。
https://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
❌アンダースコア(_)を使用する。
クエリパラメーターで割と見るので一概にダメなのかは疑問ではあるのですが、Googleの基準的には良くないようです。
https://www.example.com/summer_clothing/filter?color_profile=dark_grey
❌URL 内の単語をつなげる。
https://www.example.com/greendress
Google のリンクに関するベスト プラクティス
下記は引用
通常、リンクが href 属性を持つ <a> HTML 要素(アンカー要素とも呼ばれます)である場合のみ、Google はリンクをクロールできます。その他のフォーマットのリンクのほとんどは解析されず、Google クローラーにより抽出されません。href 属性のない <a> 要素や、スクリプト イベントによりリンクとして機能するタグから URL を信頼できる形で抽出することはできません。以下に、Google が解析できるリンク、解析できないリンクの例を示します。
aタグでの画面遷移が基本になる。JavaScriptをgoogle botが解釈はしてくれているというのもあるが、こちらのベストプラクティスに倣うのであればaタグで画面遷移をするように注意が必要そう。
一部SPAでのフラグメント識別子を用いた画面遷移について
以下引用です。
Google がリンクをクロールできるのは、href 属性が設定された <a> HTML 要素の場合のみです。
クライアントサイド ルーティングを使用するシングルページ アプリケーションでは、History API を使用して、ウェブアプリのビュー間にルーティングを実装します。Googlebot が URL を確実に抽出して解析できるように、フラグメントを使用して別のページ コンテンツを読み込むことは避けてください。次に示す方法は、Googlebot が URL を確実に解決できないため適切ではありません。
詳細はリンク内ではあるのですが、一部のアプリケーションでhref="/#hogehoge"のようなフラグメントを用いた画面遷移を扱われることがあるようです。
これはクローラーが読み込めないからやめてね。ということが書いているようです。
下記も見て理解に繋がりました。
Core Web Vitals
以下公式引用です。
Core Web Vitals は、ページの読み込みパフォーマンス、インタラクティブ性、視覚的安定性に関する実際のユーザー エクスペリエンスを測定する一連の指標です。
検索結果でのランキングを上げ、全般的に優れたユーザー エクスペリエンスを提供できるよう、サイト所有者の皆様には、Core Web Vitals を改善することを強くおすすめします。Core Web Vitals は、その他のページ エクスペリエンス要素とともに、Google のコア ランキング システムがランキングを決定する際に考慮する要素です。詳細については、ページ エクスペリエンスの Google 検索結果への影響についてをご覧ください。
引用通りですが、こちらの師匠が検索のランキングに影響が出ることが記載をされていますね。
ここでCore Web Vitalsの細かい指標については説明をしないのですが、実装者はこちらを意識して実装を進める必要がありそうです。
引用をした公式ページにCore Web Vitalsの指標にである、Cumulative Layout Shift(CLS)、Largest Contentful Paint(LCP)、First Input Delay(FID) についての説明やそれらの指標に関する
web.dev
以下引用です。
Google では、すべてのユーザーにとって、美しく、アクセスしやすく、高速で、安全なウェブサイトを構築できるよう、クロスブラウザ対応のウェブサイトを作成したいと考えています。このサイトには、Chrome チームのメンバーや外部の専門家が作成した、移行を支援するコンテンツが揃っています。
こちらはCore Web Vitalsやアクセシビリティに関する様々な知見や測定方法等をまとめてくれているようです。
細かい内容についてもこちらを見ながら改善をするのが良さそうです。
INPについて
余談ではあるのですが、こちらでも紹介をされているのですが、3 月 12 日にFirst Input Delay(FID)が削除され、Interaction to Next Paint(INP)がCore Web Vitals の指標に追加をされるよです。
構造化データのマークアップ
どのような効果が期待できる?
リッチリザルトを表示させるために必要。
形式としては、microdataやRDFa、JSON-LDという形式がありますが、JSON-LDが推奨されているようです。
設定に関する参考記事
設定がされているかの確認方法
設定した場合の表示例
以下の記事はこんな感じで設定をしている様子
こんな感じでhtml上に表示をされている
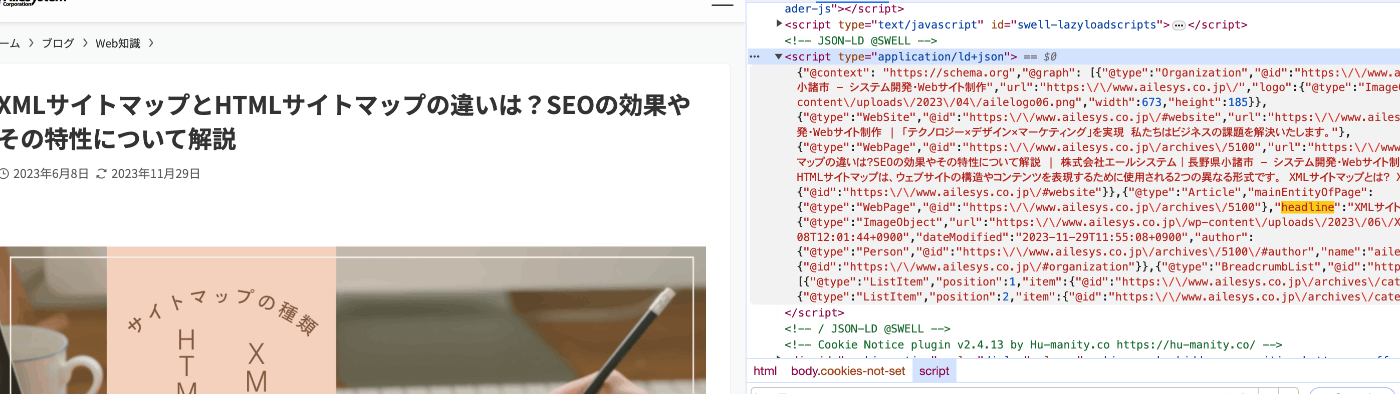
↓リッチリザルトで表示をされた時の表示内容
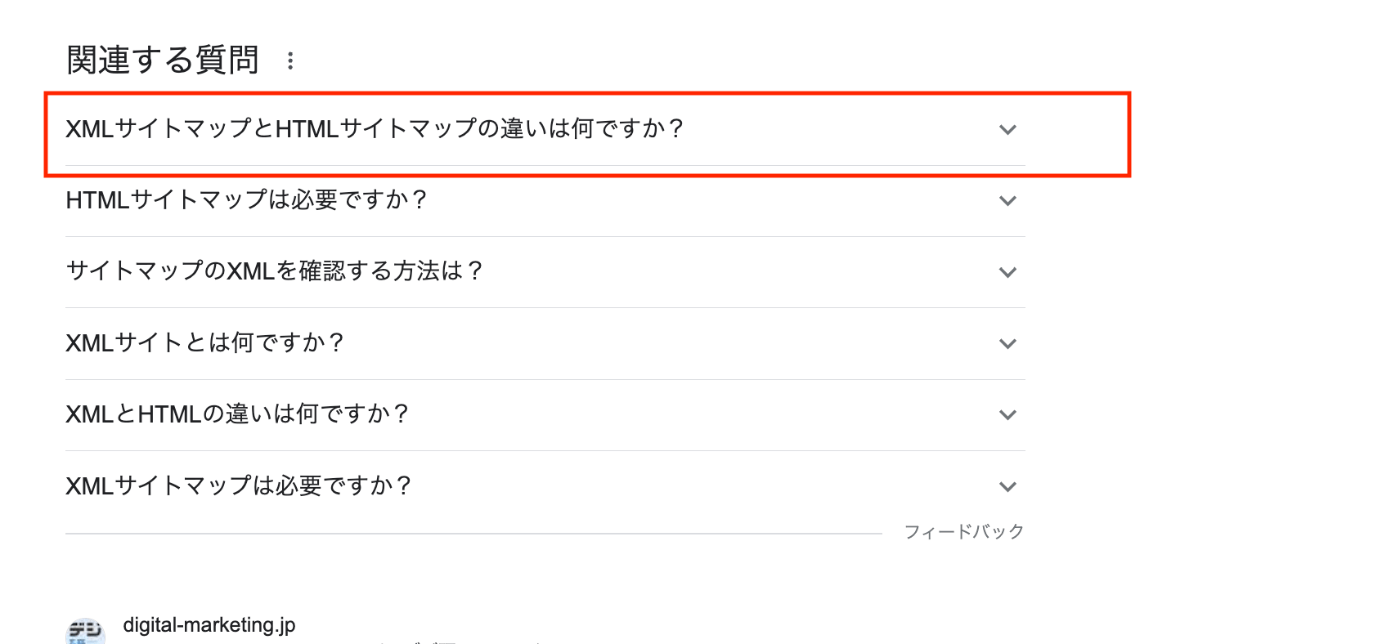
↓アコーディオンを開いた状態

Google のリンクに関するベスト プラクティス
こちらはフロントエンドエンジニア向けになります。
以下引用と一部のリンク例を抜粋させていただきます。
通常、リンクが href 属性を持つ <a> HTML 要素(アンカー要素とも呼ばれます)である場合のみ、Google はリンクをクロールできます。その他のフォーマットのリンクのほとんどは解析されず、Google クローラーにより抽出されません。href 属性のない <a> 要素や、スクリプト イベントによりリンクとして機能するタグから URL を信頼できる形で抽出することはできません。以下に、Google が解析できるリンク、解析できないリンクの例を示します。
✅推奨(Google が解析可能)
<a href="https://example.com">
<a href="/products/category/shoes">
❌非推奨(だたし、同様に解析を試みることはある)
私が元々routerLinkを知らなかったのですが、Angulerで画面遷移をする時に使われているような手法のようです。
<a routerLink="products/category">
こちらはaタグを使わずにspanタグを使われてしまっている。
<span href="https://example.com">
javascriptを使って画面遷移を行われている
<a onclick="goto('https://example.com')">
javascriptを使って画面遷移を行われている
<a href="javascript:goTo('products')">
javascriptを使って画面遷移を行われている
<a href="javascript:window.location.href='/products'">
こちらaタグを用いることが基本としてあるようです。
ただ画面遷移をする際にJavaScriptを使って何かしら実装がされることもあるかと思うので個人的にはGoogleさんが頑張ってJavaScriptをaタグ同様に評価いただけると嬉しいなと個人的には思いました。
一部補足
Next.js ではuseRouterを使った画面遷移と<Link />のコンポーネントを使って画面遷移があります。
この時に安易にuseRouterを使った画面遷移をすることはSEO上はあまりよくありません。
理由としては以下の違いがあるためです。
-
<Link />コンポーネントは<a />タグを生成して画面遷移をする - useRouterのを使った画面遷移はあくまでもJavaScriptを使って画面遷移を行なっている。
という違いがあるためです。なのでシンプルな画面遷移を行う場合は<Link />を使って画面遷移を行なって
クローラーがサイトを回遊しやすいようにする必要がありそうです。
低品質なページや検索結果に表示をさせなくても良いページにはnoindexを入れる
以下引用です。
ページやその他のリソースが Google 検索に表示されないようにするには、noindex(ノーインデックス)ディレクティブを活用します。noindex ディレクティブは、<meta> タグまたは HTTP レスポンス ヘッダーで設定されるルールで、サポートしている検索エンジン(Google など)に対してコンテンツをインデックスから除外してもらうために使用されます。Googlebot がページをクロールしてタグまたはヘッダーを検出すると、他のサイトがそのページにリンクしているかどうかにかかわらず、そのページを Google 検索結果から完全に削除します。
つまりはGoogleの検索データベースに登録をさせないように使用をするものです。
ではなぜわざわざnoindexで登録をさせないようにするのでしょうか?理由としてはSEO向上のため、クローラーに低品質なページをクロールさせないためです。
例えばなのですが、ECサイトの開発を行っているとして、注文確認画面や、注文完了画面のような画面を検索で表示させることはないはずです。
このようなページまでもクロールをされてしまうと評価が分散をされてしまうためnoindexをつけ、クロールをする必要がないページをクロールさせないような制御が必要です。
SPAアプリケーションの場合は可能な限りSSR(サーバーサイドレンダリング)を使用する
以下引用です。
ユーザーやクローラーに対してウェブサイトを高速化する効果があり、bot によっては JavaScript を実行できないものもあるため、サーバー側でのレンダリング(プリレンダリング)も有効な方法として検討してみてください。
Google botはJavaScriptを理解して、検索結果に反映をしてくれます。ただし、どういう条件かは不明ですが、botがJavaScriptを処理出来ないこともあるみたいでサーバー側でのHTML生成を対応をした方がいいようです。
JavaScriptが原因で検索結果に表示されない疑いがある場合
フロントエンドエンジニア向けの内容になります。
下記の「検索関連の JavaScript の問題を解決する」をご確認ください。
様々な原因となるものを紹介しているので困った時に参照をするといいかもしれません。
SPAアプリケーションでSSRをせずにCSR(クライアントサイドレンダリング)で詳細情報を取得した時にクローラーはインデックスをしてくれるのか?
X(Twitter)でとあるpostの詳細情報をネットワーク経由で見ていると、最初のHTMLを取得している段階では詳細な情報が返ってきていないのでJavaScriptで取得をしていると思われる。(ただ、network経由で探しても対象の情報が見当たらなかったので、隠されているのかもしれない。)
ということはCSRで取得しても情報を取得することが可能だと思われる。
下記の引用もあるので基本的にはサーバーサイド側での取得が推奨をされている。
ユーザーやクローラーに対してウェブサイトを高速化する効果があり、bot によっては JavaScript を実行できないものもあるため、サーバー側でのレンダリング(プリレンダリング)も有効な方法として検討してみてください。
こちらのyoutubeでもCSRでも問題はないという風に言及いただいていました。
titleタグ
Google検索セントラルや、その他2次情報含めて色々と調べていると、titleタグはSEOの観点で重要なものようです。
細かい内容は下記のリンクを見ていただけるといいかと思います。
個人的に開発をしている中で過去に見たよくなさそうな例をいくつか紹介させていただきます。
Titleタグが設定をされていない
表題のままなのですが、稀にタイトルが設定をされていないページがあるようです。
タイトルがないと、ユーザーからしても、そのページがどのようなページか分かりづらかったりするので、合わせてSEOの評価的にもマイナスになるのではないかと考えております。
確実にそれぞれのページに適切なtitleを設定するようにしましょう。
Titleタグや詳細ページで同じものが登録をされている。
例えばなのですが、階層構造的に 「トップ」 => 「店舗一覧」 => 「店舗の商品一覧」 => 「店舗の商品詳細」というようなサイトがあったとします。
この時に「店舗の商品詳細」画面でのタイトルが 「商品詳細 | サイト名」 というようにそのまま「商品詳細」という名前が登録をされていた時にユーザーとしてはこのページがどのようなページかをtitleで判断ができますでしょうか??
おそらくできないと思います。
bodyタグの中にある、見出し等にそれぞれのページでgoogleのクローラーが読み取ってくれる可能性もありますが、titleタグとしても適切に設定をさせた方がSEOは見込めそうです。
なお、上記のようなサイト構造があったときの例として、もし自分がサイトの運営者だとしたら下記のようなキーワードを入れてtitleに設定できるようにするかなーと思いました。
「ハンバーガー | 〇〇店 | 豊中市 | サイト名」
考えたことは以下を考えました。
- googleやユーザーが特定のページを理解しやすいように、タイトルが他のページと被らないように一意になるようにする。
- タイトルからそのページがどういう構造なのかを判別できるようにする。
- 検索のキーワードとして期待をした情報を入れる。
meta description
検索をした時に検索タイトルの下に表示をされる情報のようです。
ただし、検索をした時にそのページのmeta descriptionが表示をされずにページ内のテキスト部分が表示をされる場合もあるようです。このページがどういうページであるかを適切にユーザーに伝えられるようにしましょう。
公式
SEOに関して便利そうなツール
Google Seach Console
これはgoogleが提供をしているツールで公式でも紹介をされているものになります。
具体的にどんなことができるのかは、下記の記事を参考にすると分かりやすそうです。
以下は引用になります。
- Google検索での表示状況の確認
- Google検索結果での「掲載順位」や「表示回数(検索結果でURLが表示された回数)」「クリック数(検索ユーザーがクリックした回数)」「CTR」「検索クエリ(URLが表示されたときの検索キーワード)」といった検索パフォーマンスが、主に確認できます。
また、Google検索で有効なページ(インデックス登録されてるページ)やモバイルファーストインデックス(MFI)の適用についてわかります。
- リンク状況の確認
- サーチコンソールの「リンク」機能から外部リンク(被リンク)の総数や上位のリンクされているページ(被リンクが多いページ)、上位のリンク元サイト、上位のリンク元テキストなどが把握できます。
また、内部リンクの総数や上位のリンクされているページ(内部リンクが多いページ)などが把握できます。
- サイトの情報提供
- サーチコンソールのURL検査ツールでインデックス登録のリクエスト(Googleクローラーにクロールのリクエスト)や、インデックスの「削除」機能でインデックス削除の申請ができます。
また、「サイトマップ」機能を活用してクロールを促進したり、robots.txtテスターでクロールの制御、アドレス変更ツールでSEOを含むサイトリニューアルなどによるURLの変更を伝えることができます。
- サイトの問題点の把握
- サーチコンソールの拡張メニューの「ウェブに関する主な指標」から表示速度の遅いURLが把握できます。
また、パンくずリストの構造化データの実装エラーや、モバイルフレンドリー対応エラーの有無がわかります。
さらに、「手動による対策」機能では、ペナルティの有無がわかります。
Lighthouse Chrome 拡張機能
こちらもGoogleが無料で提供しているサイトを診断するための、Google Chrome拡張機能です。
SEOについて細かな診断を知れくれるものではなさそうですが、改善をした方がいい要素があれば指摘をしてくれるので普段使用をしているブラウザで導入をしておくことをお勧めします。
例えばなのですが、私が以前に作った個人開発のLPでは以下のようにボタンとしてはしては下記のような指摘を受けていました。出来ればこのようなところは改善をした方が良さそうですね。
Interactive elements like buttons and links should be large enough (48x48px), or have enough space around them, to be easy enough to tap without overlapping onto other elements
以下翻訳
ボタンやリンクのようなインタラクティブな要素は、他の要素と重ならずにタップしやすいように、十分な大きさ(48x48px)か、周囲に十分なスペースを確保する。

Web Vitals 拡張機能
Web Vitalsの指標を数値で確認することができるようです。拡張機能で計測をすると下記のように確認をすることができます。
これを見ただけではどこに問題があるのかは分からなそうなので、詳しくは調査が必要かもしれません。

SEOに周りに関して主に参考にさせていただいたもの
本
10万PVを生む ECサイトのSEO―中小事業者がお金をかけずにできる集客のための施策
SEOに関しての初心者にでも分かりやすいような文を書いてくれているのでとても分かりやすかったです。
SEOに関する全体を理解する際にはこちらの書籍をお勧めいたします。
Webサイト
Google Search Central(Google検索セントラル)
以下は日本語訳での引用になります。
Google 検索セントラル(旧称 Google ウェブマスター)は、コンテンツが適切なユーザーに表示されるようにするためのサポートツールです。サイトを Google 検索で見つけやすくするためのリソースが用意されています。SEO のご経験がない場合は、まずこちらの Google 検索のクイックスタートをご覧ください。
なお、翻訳情報は最新ではない可能性があるようです。最新情報を確認する場合は下記のように変更をしてご確認ください。
?hl=ja
↓
?hl=en
海外SEO情報ブログ
定期的に最新のSEO情報を発信いただいています。
Google Product Expertの鈴木謙一さんという方が運営をされているブログサイトです。2,3日に一度くらいの高頻度でSEOに関する情報を発信をされているので定期的な情報をウォッチするのにとても良いかと思います。
最後に
今回SEO周りについて自分で調べたり、Google Search Centralの情報を網羅的に見たりと勉強になることが多くて楽しかったです。
ただ、ここまで調べていてなんなのですが、最近はSNSを使った集客だったり必ずしもSEOというチャネルが必要かと考えるとそこに関しては疑問です。
どこまで考えて対応をするかは費用対効果とのバランスを見ながら対応をする必要がありそうです。
自分自身も今回学んだことを活かしながら普段の開発業務等に活かしていきたいと思います。
気づけば割と時間をかけて今回2万5000文字弱の文章を書いていました。。笑
少しでもタメになったと思っていただけましたら、Likeやコメント等をいただけると執筆作業の励みになります。
ここまで見ていただきありがとうございました!!

Discussion
こちらの記事でマークアップについて色々と書かれていて勉強になるのでおすすめです。