LEIA: 言語間転移学習でLLMを賢くする新しい方法

Studio Ousiaと理化学研究所に所属している山田育矢です。
この記事では、大規模言語モデル(LLM)の性能を向上させる新しい方法であるLEIA(Lightweight Entity-based Inter-language Adaptation)を紹介します。
LLMは言語によって性能に顕著な差があり、訓練に使われるテキストが最も多い英語において特に性能が高い傾向があることが知られています。LEIAは、LLMが蓄えている英語の知識を他の言語から使えるようにする訓練を施すことで、英語以外の言語でのLLMの性能を向上させる新しい手法です。
この度、英語・日本語の2言語LLMであるSwallowの7Bと13Bのモデルに対してLEIAによる訓練を施して性能向上を行ったモデルを公開します。
ライセンスは、Swallowと同様のLlama 2 Community Licenseです。これらのモデルは、日本語の6個の質問応答データセットでの評価で、Swallowよりも性能が改善していることを確認しています。
言語間転移学習とは
LLMの性能は、言語ごとに偏りがあることが知られています。下の図は、GPT-4のMMLUというベンチマークにおける性能を複数の言語で計測したものです。
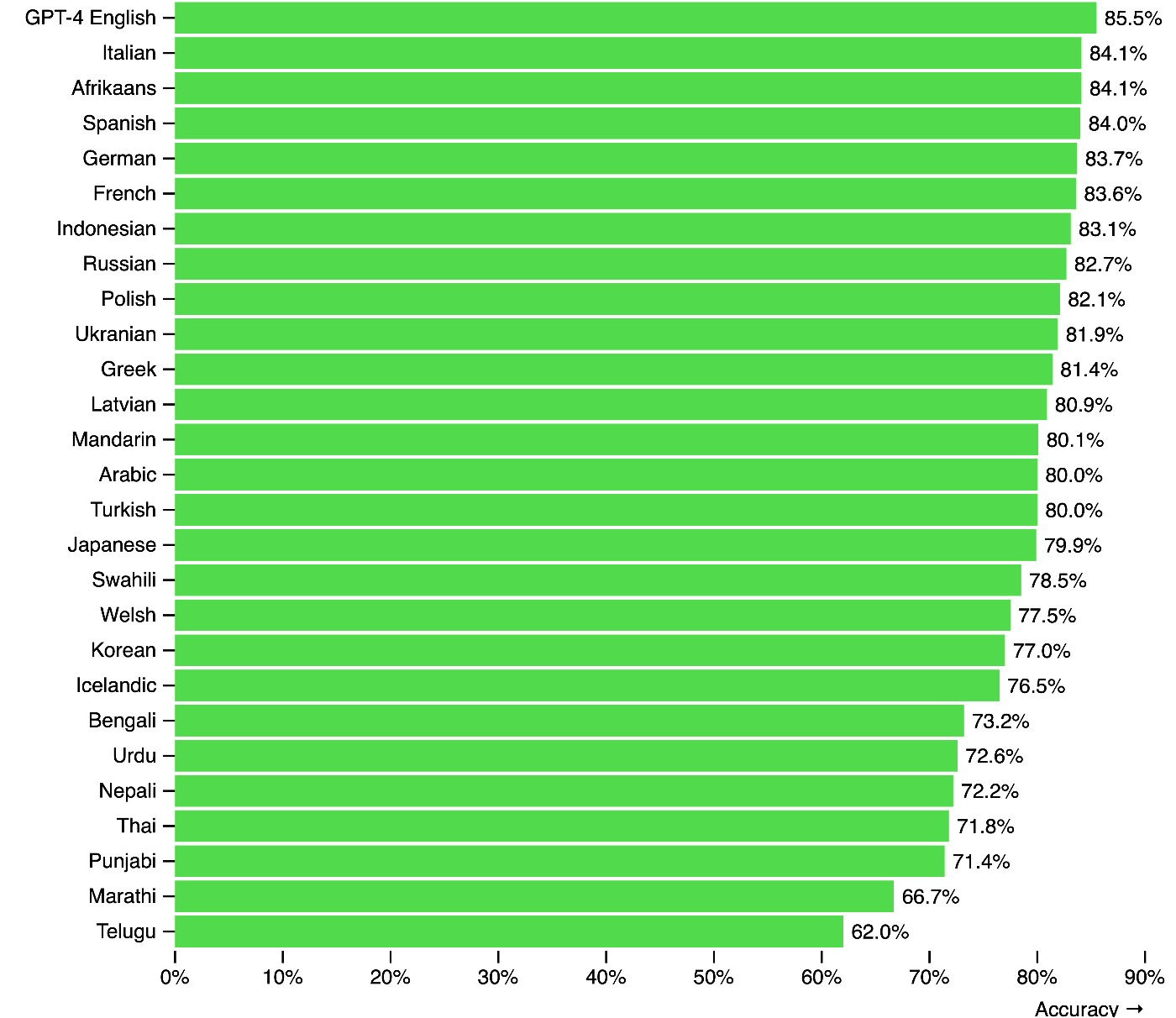
GPT-4の様々な言語におけるMMLUデータセットの性能[1]
英語と日本語では5.6%の差があり、かつ低資源な言語になるほど性能が劣化していることがわかります。英語のウェブ上のテキストは日本語と比較して10倍以上存在するという報告もあり、実質的な世界標準言語である英語でLLMの性能が最も高いというのは必然的な状況であるとも考えられます。
LLMの訓練には、単言語(例:日本語)で書かれた膨大な文書を連結したテキストデータが使用されます。LLMは、主に単言語の文書で訓練されているにも関わらず、言語間の潜在的な共通性を見出して、言語を横断した内部表現を学習することが知られています。こうした内部表現を獲得したLLMにおいては、異なる言語で書かれた同じ意味の文(例:「日本の首都は東京である」と「The capital of Japan is Tokyo」)やそのトークンが内部的に近い数値表現(埋め込みベクトル)であらわされるようなことが起こります。こうした言語を横断した表現を学習することを、言語間での転移が起こっていると捉えて、言語間転移学習(cross-lingual transfer learning)と呼びます。
言語間転移を促進するには
LLMの性能が英語で最も高いことを考慮すると、言語間転移を促進して「英語の知識を他の言語でもより有効に使える」ようにすれば、英語以外の言語での性能が改善することが考えられます。では、このような言語間転移を促進するにはどうしたら良いでしょうか?
新しい言語を習得する際、人間は辞書、単語帳、例文などから言語同士の対応関係を学びながら学習を行なっていきます。しかし、LLMの訓練はほとんどが単言語の文書で行われており、LLMがこうした対応関係を獲得することは容易ではありません。LLMにこうした対応関係を教えるために、対訳コーパスや辞書などを使った訓練方法が既に提案されており[2]、実際に性能向上に寄与することがわかっています。
LEIAとは
LEIAはWikipediaのエンティティを使ってデータ拡張したWikipediaテキストを使ってLLMを訓練することで言語間転移の促進を行う方法です。ここでエンティティとは、固有名詞や専門用語などのWikipediaの記事として存在するような事物全般をあらわします。下記の図は、Wikipediaにある中国語の文をLEIAによってデータ拡張する方法を示しています。

LEIAによるデータ拡張を中国語の文に適用した様子。
LEIAでは、Wikipediaの記事内リンク(記事に含まれる他のWikipedia記事へのリンク)の右側に、リンク先のエンティティに対応する英語名を挿入します。図では「火」、「物質」、「燃燒」、「氧化反應」に対してその右側に対応する英語名である「Fire」、「Matter」、「Combustion」、「Redox」が挿入されています。LEIAは、このようなデータ拡張を行ったテキストを使ってLLMを訓練することで、言語間転移を促進する方法です。訓練は一般的なLLMと同様にテキスト中の次のトークンを予測することで行います。また、図に含まれる<translate>・</translate>トークンについては後述します。
既存研究において、LLMはエンティティの名前を生成する際に、それに紐づいた知識を取り出す挙動をしているという報告があります[3]。LLMの訓練データの多くを占める英語のテキストでは、エンティティの名前は英語で記述されているため、英語表記の名前を処理する際にそれに関する豊富な英語の知識が取り出されると推察されます。
そこで、LEIAでは、テキスト中にエンティティの英語名を挿入することで、LLMの訓練時に対応する英語の知識をLLM内部で取り出させて、適用させることで、英語から対象言語への知識の転移を促進します。英語名に紐づいて取り出された知識は、後続するトークンの予測の際に利用されることで、対象言語の知識として学習されます。
また、上図のように<translate>、</translate>トークンを使って挿入した英語名を囲むことで、英語名の境界を示すとともに、このトークンを推論時に除外することで、LLMの推論時に英語名が出てきてしまう挙動を抑制できるようにします。
なお、「火」と「Fire」のような異なる言語のマッピングはWikipedia(Wikidata)の言語間リンクのデータを利用することで自動的に取得することができます。このため、上述したデータ拡張は、簡潔なコードによって自動的に作成できます。
実験結果
LEIAの有効性を確認するため、オープンLLM「LLaMA 2」と日本語・英語の2言語LLM「Swallow」を使って実験を行いました。
LLaMA 2を使った多言語での実験
LLaMA 2の実験では、LEIAと、下記の三つのベースラインとの比較を行いました。
- Random: 選択肢からランダムに選択
- LLaMA2: LLaMA 2をそのまま使用
- LLaMA2-FT: データ拡張を行っていないWikipediaテキストを使ってLEIAと同等な訓練を行なったモデルを使用
LLaMA 2を使った実験は、アラビア語(ar)、スペイン語(es)、ヒンディー語(hi)、日本語(ja)、ロシア語(ru)、スワヒリ語(sw)、中国語(zh)の7言語を使って、X-CODAHとX-CSQAという多肢選択肢型の質問応答データセットでの評価を行いました。下記に実験結果を示します。
X-CODAHでの実験結果:
| Model | ar | es | hi | ja | ru | sw | zh |
|---|---|---|---|---|---|---|---|
| Random | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 |
| LLaMA2 | 30.3 | 45.3 | 29.7 | 30.3 | 34.3 | 28.7 | 36.7 |
| LLaMA2+FT | 30.7±0.6 | 45.5±0.4 | 27.2±0.2 | 30.4±0.3 | 34.4±0.9 | 29.0±0.1 | 38.3±0.3 |
| LEIA | 32.8±0.5 | 46.6±0.2 | 30.6±0.2 | 34.9±0.4 | 37.5±0.2 | 30.4±0.2 | 39.1±0.2 |
X-CSQAでの実験結果:
| Model | ar | es | hi | ja | ru | sw | zh |
|---|---|---|---|---|---|---|---|
| Random | 20.0 | 20.0 | 20.0 | 20.0 | 20.0 | 20.0 | 20.0 |
| LLaMA2 | 21.0 | 45.1 | 19.1 | 34.4 | 36.0 | 16.0 | 40.1 |
| LLaMA2+FT | 21.3±0.3 | 44.8±0.2 | 18.2±0.2 | 34.5±0.3 | 35.7±0.3 | 15.9±0.1 | 39.7±0.1 |
| LEIA | 21.9±0.2 | 45.7±0.1 | 18.4±0.2 | 35.4±0.2 | 36.1±0.2 | 16.0±0.1 | 40.5±0.1 |
LLaMA2+FTとLEIAについては、異なる乱数シードで訓練を5回行なって、平均正解率と95%信頼区間を示しています。
実験の結果から、X-CODAHというデータセットの全ての言語とX-CSQAというデータセットの7言語中5言語で性能が改善することが確認できます。また、ヒンディー語とスワヒリ語のX-CSQAでは、性能改善が見られませんが、そもそも全てのモデルがランダムに選択した場合の性能をこえておらず、元となったLLaMA 2がタスクを解くにあたって十分な性能を持っていなかったことが原因として考えられます。
Swallowを使った日本語での実験
Swallowを使った実験では、日本語を対象としてX-CODAH、X-CSQA、JCommonsenseQA、NIILC、JEMHopQA、JAQKETの6つの質問応答データセットにて実験を行いました[4]。
Swallowでの実験結果:
| Model | X-CODAH | X-CSQA | JCommonsenseQA | NIILC | JEMHopQA | JAQKET |
|---|---|---|---|---|---|---|
| Swallow | 42.0 | 41.0 | 80.3 | 59.5 | 50.8 | 39.1 |
| Swallow+FT | 40.7±0.3 | 39.6±0.2 | 79.3±0.1 | 58.0±0.3 | 50.3±0.8 | 35.0±0.8 |
| LEIA | 42.5±0.2 | 42.1±0.1 | 80.6±0.2 | 60.3±0.2 | 54.5±0.1 | 41.3±0.6 |
Swallow+FTは、LLaMA2+FTと同様に、データ拡張を行わないWikipediaテキストを使って訓練を行なったモデルです。この実験では、全てのデータセットにおいて有意な性能の改善が見られました。
どのような知識が英語から転移しているか
LEIAを使うと、どのような知識が英語から対象言語に転移するのでしょうか。下記にLLaMA 2の実験でのLLaMA2+FTとLEIAのX-CODAHの日本語の文における推定結果の差異を示します。なお、X-CODAHのタスクは、複数の文が候補として与えられて、モデルが最も妥当な文を回答として選択する形式になっています。
| LLaMA2-FTが選択した文 | LEIAが選択した文 |
|---|---|
| 海を沸かせようとしている。海が大好きなんです。 | 海を沸かせようとしている。彼は不可能なことを成し遂げようとしている。 |
| イギリスのロンドンにあるエッフェル塔。 | エッフェル塔はパリにあります。 |
| 電話が鳴る音がする。音量を上げてみました。 | 電話が鳴る音がする。私はそれに答える。 |
| お酒を飲みすぎてしまいます。小学4年生になりました。 | お酒を飲みすぎてしまいます。私はアルコール依存症かもしれません。 |
| フードコートに人がいる。その人はマラソンを走っています。 | フードコートに人がいる。その人はサンドイッチを買う。 |
これを見るとLEIAを使うことで、「海を沸かすことはできない」というような常識や「エッフェル塔がパリにある」というような事実的な知識が転移していると推察されます。
LEIAについてさらに知りたい方は、下記の論文、ソースコード、言語処理学会ワークショップでの招待講演スライドを参照してみてください。
論文:
ソースコード:
スライド:
-
GPT-4 Technical Report (OpenAI, 2023) ↩︎
-
Locating and Editing Factual Associations in GPT (Meng et al., NeurIPS 2022) ↩︎
-
JEMHopQAとNIILCの評価にはllm-jp-eval、JCommonsenseQAとJAQKETの評価にはJP Language Model Evaluation Harnessを使用しました。実験の詳細については論文を参照してください。 ↩︎
Discussion