「文脈と名前で設計をマスターする本」を読む
これが言語化されているだけでも助かる人たくさんいるだろうな
文脈が広いということは一般論として以下のようなことを意味していると言えます:
- 文脈が持っている情報量がより少ない・薄い
- 文脈がより一般的・抽象的な事柄を表している
- 文脈が論理的命題としてより「弱い」条件を与えている

だから集合の考え方が大事だし、構造的部分型はその感覚を養うのにありがたいんだよねー
コードが文脈の詳細化原則を満たした自然な文脈を持っていると感じるかどうかは最終的にはプログラマーの感性にかかっており、残念ながら機械的・客観的に文脈の良し悪しを決めることはできないのです。
するどい
number_of_tall_persons、180.0がマジックナンバーになっていて、マジックナンバーはハイコンテキストで読みにくいから名付けをしましょうね、っていう話があるとより嬉しかった

最小命名の原則: 内側の構成要素に付けられた名前の文脈を解釈する際には、その名前自体が意味する文脈だけでなく、外側の構成要素が持つ文脈も加味して解釈すべきである。この前提の下で、名前はできるだけ簡潔なものが選ばれるべきである。
この言語化ありがたい。
hooks/use-toggle.ts みたいな命名はやめよう!
結合の定義: 結合とは、名前の参照によって発生した文脈の飛び地のことである。
おーん、若干置いてかれてるかも...
あー、結合を「飛び地」を使って定義することでいい結合の仕方を考えるっていう手立てか
- 文脈の飛び地はできるだけ少ない方が良い → 同じ名前を参照する箇所は少ない方が良い
- 飛び地となる文脈の構成要素は互いにできるだけ近い位置にある方が良い → 名前の参照は名前の宣言・定義から近い方が良い
- 飛び地となる文脈はできるだけ広い文脈である方が良い → 名前が持つ意味は抽象的である方が良い
視覚化されるとなおわかりやすい...
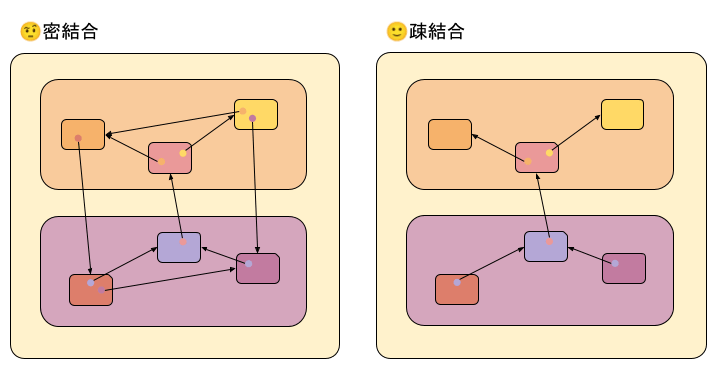
ただし、名前の汎用性を高めることは参照元を増やすことに繋がり、それは原則の第一項や第二項に反することになります。従って各項の間でバランスを取る必要があります。このバランスのとり方について唯一の正解のようなものはありませんが、一つの指針としては段階的詳細化を導入することで一つの名前に対する直接の参照元を減らすことが考えられます。
書いていてほしいことがちゃんと書いてある :heart:
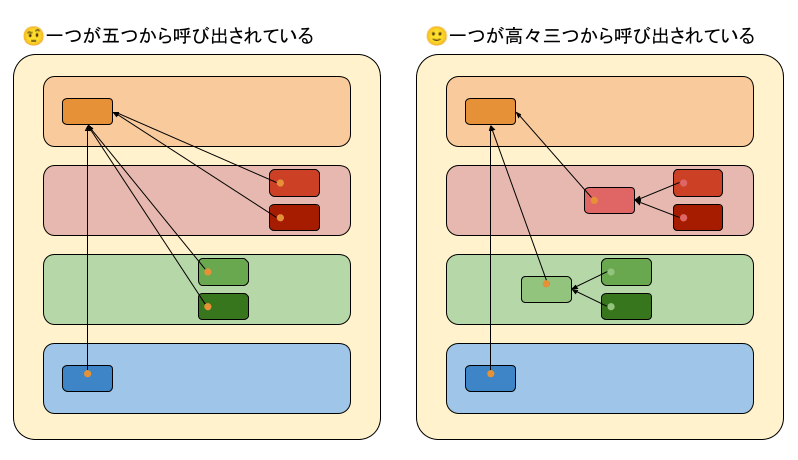
まじで図がいいな
「あれ、似たような計算をなんどもやる設計になっちゃってないかな?」っていう診断にもつながるよねー
show_progressなー、わかるけどテスタビリティとかパフォーマンスの面で関数は外で定義しておきたいことが多々あると思っていて...
話の本筋とは違うかもしれないけど
-
all_task_count = 10を定義して文脈を共有する - show_progressの引数をパーセンテージにすることでより広い文脈の関数とする
という対策のほうが自分は好み
確かに一つ一つの函数は簡潔に書かれていて函数の名前と函数の内容の対応も自然です。しかしコードの分かりやすさの観点では以下のような粗(あら)を指摘することもできます。
ほんとうに言語化が上手だな...
このようなデメリットが甘受できない場面では、命名による抽象化をする代わりにコメントを書くことでコードの構成を変えずに文脈の説明を追加することができます。
こんなに明確にコメントを書くタイミングを教えてもらったことない、すごい
名前の多相性の定義: 名前の参照元をコーディングした段階で、その名前が常に同じ一つの構成要素を参照するという挙動が確定する場合、その名前は単相な名前である。そうでない名前は多相な名前である。
ほーん、考えたことなかったな...
実値のラベリングなのかplaceholderなのかみたいなことかな?
ちょっとちがうかもな
でもぜんぜん違う感じでもないな
なぜ多相性と呼ぶのか
ここめっちゃすきだなー
設計好きな人みんな好きだと思うw
文脈の飛び地を最小限にするため、一つの名前に与える参照先はできるだけ少なくすべきです。
そうなのかなー?
ハイコンテキストさを避けようと思ったらむしろ1つの関数の参照先が増える設計にならないかな?
なんか読み違えてる気もするからあとで読み返そう
めっちゃいい
めっちゃいいけど、もうちょっと違う切り口でまとめられそうな気もする
単相な名前では参照元から参照先への推移的な依存の繋がりがあるので、プログラムの正常性を維持しながらコーディングしようとするとどうしても参照元よりも先に参照先を書きたくなります。もし先に参照元を書いても参照先を書くまではプログラムがコンパイルできなかったり自動テストが失敗したりするでしょう。それよりは、先に参照先を書くことでコンパイルや自動テストが通る状態を維持しつつ後から参照元をコーディングする方が、安全そうです。
一方で多相な名前の場合は、名前の宣言を先に書きさえすれば、後は参照元と参照先のどちらから書くかは自由です。同時に別の人がそれぞれをコーディングすることすらできます。このような柔軟さは特に大規模なソフトウェアの開発において作業を効率化するのに役立つかもしれません。
個人的にはここがサビだった。こうやって考えたことがなかった。
節度ある名前の多相化
できちんと触れられているけど、単相だから・多相だからどうこうっていうよりは、それは結果的にそうなるもんであって、例えばareaOfCircleなら「半径にしか関心がない」からradiusが引数になっているのであって引数だから結果として多相だよ...みたいな
結局、「使い手は何に関心があるのかな?」っていう視点でインターフェイス(ひいては依存関係)が設計されるのだと思うのよなー
これもめっちゃいいなー
こういう章がかけるのすごいなー
もっとも、参照されない名前の宣言を常に除去し続けることが最適であるとも言い切れません。一つには、データ構造とその文脈の在り方に新たな課題が生じます。上の最後の例では Attacker 構造体が Character 構造体と共通の値を持っていて、文脈の飛び地になってしまっています。宣言の重複をなくすために、Character 構造体に Attacker 構造体を包含させるということもできなくはありませんが、もともとフラットだった Character 構造体の内容が階層化されて全体として把握しにくくなった感があります。
これの対策として、TSではよくPickするんですよねー
たとえばたくさんの情報が詰まってるUserオブジェクトがあって、その中のidとiconUrlだけを参照したいUserAvaterがあるときに、UserAvaterの引数は
type Props = {
user: Pick<User, "id" | "iconUrl">
}
みたいな感じで定義できる。
Propsを引数に持つ関数がuserに関心があることをきちんと明示できるし、必要十分な情報を取れる
上記のように函数の中身が必要とするメソッドだけを含んだ型を引数の型として宣言することを推奨する教えをインターフェイス分離原則 (Interface Segregation Principle) といいます。ただし、何でもかんでもそうすることはむしろ考えものです。前章の「節度ある名前の多相化」を思い出して、必要性に見合った範囲で抽象インターフェイスを導入すべきでしょう。
全体的に、厳格なこだわりが感じられる一方で「〇〇一辺倒」にならない感じがとてもかっこよかったです