競プロメモ
??? 〜 2021年: https://scrapbox.io/ia7ck-comp-pro
ARC 147 A - Max Mod Min
操作回数がそこまで大きくならないことから、操作をシミュレーションすることで解ける。
実際、
- 余りは割る数未満
A_i \mod A_j < A_j A_j \le A_i / 2 \Rightarrow A_i \mod A_j < A_i / 2 -
A_j > A_i / 2 ⇒ A_i - A_j < A_i / 2 A_i \mod A_j = (A_i - A_j) \mod A_j < A_i / 2
よって
ABC 269 F - Numbered Checker
ていねいに等差数列の和を計算する問題。
クエリで与えられた二次元領域の左上 (マス
整数は以下のように並んでいる。
x 0 x+2 0 x+4 0 ...
0 * 0 * 0 * ...
x+2M 0 x+2+2M 0 x+4+2M 0 ...
0 * 0 * 0 * ...
x+4M 0 x+2+4M 0 x+4+4M 0 ...
.
.
.
どの行にも共通して現れる
- 初項
x - 階差
2
の等差数列の和で、項数は
-
A 0 -
A + 2 2M \times \lceil (D - C) / 2 \rceil -
A + 4 4M \times \lceil (D - C) / 2 \rceil - ...
なので
ABC 271 E - Subsequence Path
DP
dp[i][v] := E[1], ..., E[i] まで考えたとき頂点 1 から頂点 v への最短距離
dp[i][*] → dp[i + 1][*] の遷移:
dp[i + 1][v] = dp[i][v]- 辺
E[i]を(a, b, c)として、chmin(dp[i + 1][b], dp[i][a] + c)- 辺
E[i]を使うときだけ最短距離が更新されうる
- 辺
DP 配列の次元を削減するテク (?) で dp[i][v] を dp[v] と管理すれば (1) の遷移がなくなり、空間 O(N), 時間 O(K) で解ける
ARC 149 A - Repdigit Number
答えの候補が少ないので全探索。
実際、桁数をたとえば 4 に固定すると、どの桁の数字も同じという条件から
- 1111
- 2222
- ...
- 9999
の 9 つのみ考えればよい。桁数 1 〜 N まで考えても全部で 9N 個。
ただ、素朴に 11111...11 などを文字列として持つと、数字の個数が合計で N^2 になる。いまは M で割った余り 11111...11 mod M だけあればよく、桁数が大きい数でも下から 10 倍しながら M による剰余を計算していける。余りは M 未満になるので 64bit 整数に収まる。
このように答えの候補 (を M で割った余り) を列挙して、桁数の大きい順、数字の大きい順に見ていき mod M が 0 のものに初めて出会ったところで答えを出力すればよい。
ABC 276 F - Double Chance
| 1 回目の操作で引くカード |
2 回目の操作で引くカード |
|---|---|
|
|
|
|
|
|
-
A_{K + 1} A_i \sum A_i - (
A_{K + 1} A_i A_{K + 1}
の和になる。これは Segment Tree や Fenwick Tree で
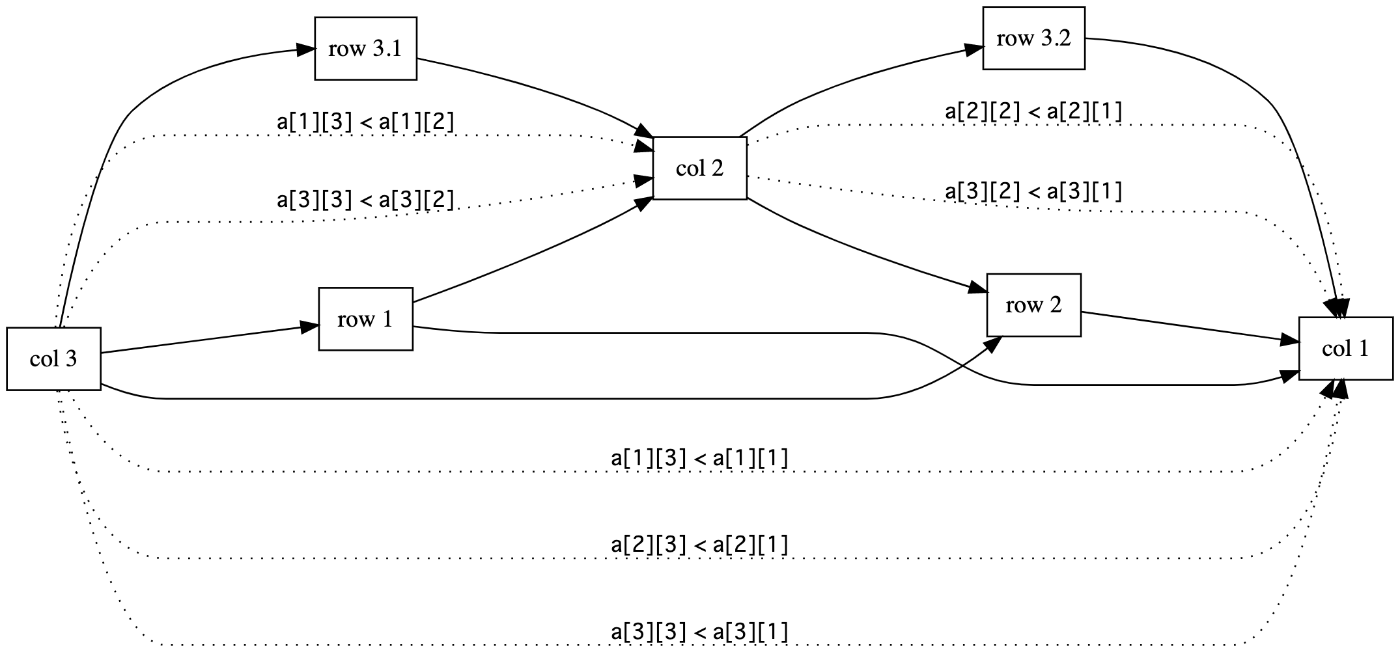
ABC 277 F - Sorting a Matrix
列の入れ替え操作によって各行をソート済みにできるか、という問題の解法をメモ。
A が
3 3 1
5 4 4
9 8 6
であるケースを考える。
たとえば 1 行目 [3, 3, 1] について、列の入れ替えによって
- 1 列目は 3 列目より後
- 2 列目は 3 列目より後
に動かす必要がある。このような制約が 2 行目, ...., H 行目についても同様に課される。
この問題は以下のグラフが DAG かどうか、つまり、トポロジカルソートができるかを判定すれば解ける。
- 頂点
- 頂点 1: 「1 列目」を表す頂点
- ︙
- 頂点 W: 「W 列目」を表す頂点
- 辺
- 「u 列目は v 列目より後」という制約に対して有向辺 u -> v を張る
たとえば上の A においては次のグラフが対応する。この場合、頂点 3 → 頂点 2 → 頂点 1 がトポロジカル順序とわかる。

ただ、「u 列目は v 列目より後」という制約の個数 = 辺の本数は Ω(HW^2) になる。そこで、必要な辺のみを含むグラフを構築して DAG 判定をする。
素朴な (上に書いた) グラフ構築手順では A の 3 列目 [9, 8, 6] から、以下の制約
- (α) 1 列目は 2 列目より後
- (β) 2 列目は 3 列目より後
- (γ) 1 列目は 3 列目より後
に対応する辺を張ることになる。しかし、この例だと (α), (β) のみでよく (γ) は不要。
この要領 (くわしくは公式解説) でグラフを構築すると頂点数と辺数が O(HW) に抑えられる。上の A に対応するグラフは次の図の実線部分になる。
ABC 283 E - Don't Isolate Elements
PAST の過去問 https://atcoder.jp/contests/past202010-open/tasks/past202010_n と同様の DP
ARC 153 B - Grid Rotations
縦横独立に考えられるので 1 次元の列に対して区間の反転操作を高速にできればよい。この記事 https://xuzijian629.hatenablog.com/entry/2018/12/08/000452 のデータ構造を使うとできる。
ABC 307 E - Distinct Adjacent
包除原理で解くことを考える。
K 本の辺のつなぎ方に応じて、連結成分数が変わるかと勘違いしていたけどそんなことはなかった。c = N - K で一定。
N = 6, K = 3, c = 3 の例
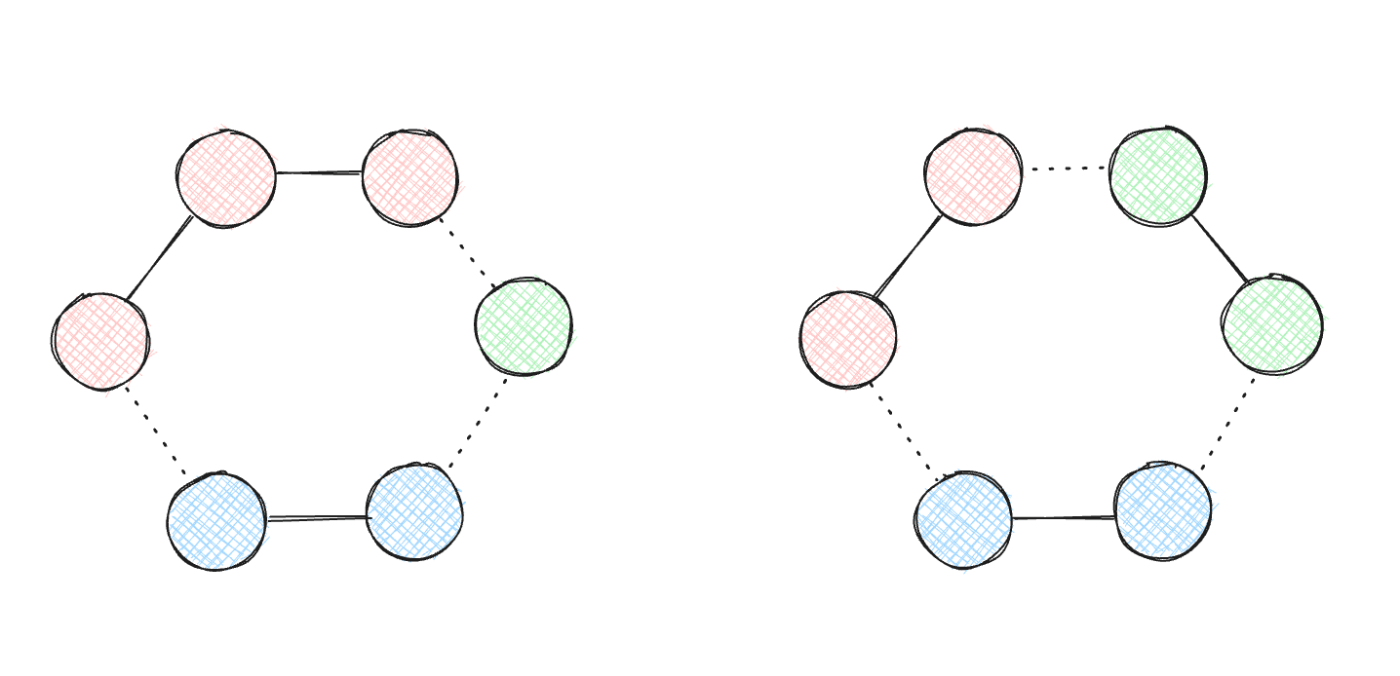
頻出らしいのでメモ。
ふたつの整数列
まず sum(A) = sum(B) が必要。このとき答えは
ARC 167 B - Product of Divisors
「
-
A^B p_i 1 \prod_{j \ne i}(e_jB + 1) -
p_i 0 e_\star B - (よくわからなくなったら小さい
A, B
-
-
p_i^2 \vdots -
p_i^{e_iB}
結局
ABC 328 F - Good Set Query
「頂点 u と頂点 v の『差』が w」の関係を保ちつつ頂点集合をマージする問題。
diff[v] := (親 p の値) - (自身 v の値) を管理する UnionFind で解ける。「値」は「重み」とも呼ばれる。
頂点 v に対する Find 操作後には diff[v] = (根 r の値) - (自身 v の値) となる必要がある。この値は親を辿る過程で diff の累積和をとっておくことで求められる。
Union 操作:TODO あとで図を描く。
提出コード:https://atcoder.jp/contests/abc328/submissions/47511009
ABC 341 E - Alternating String
平方分割。
入力の 0/1 数列を
ブロックごとに
- 全要素を反転させるかのフラグ
flip - 隣接要素が異なる個数 (
S_i \neq S_{i + 1} diff- (オーバーキルな気がするので「隣接要素がすべて異なるか」だけでもいいかも)
を管理する。
- 反転クエリ
- ブロック全体への適用:
flipの真偽を反転させる、diffは変わらない - ブロックの一部への適用:
flipの効果を全要素に伝搬して、あとは要素をひとつずつ処理する、diffを定義通りに再計算する
- ブロック全体への適用:
- 判定クエリ
- 「直前のブロックの最後の要素 (0 or 1)」を持って、クエリ対象のブロックを左から見ていくと答えられる
- ブロックの「境界」の要素が異なる個数 + 各ブロックの
diffの総和を計算できる- → クエリで与えられた区間の幅と比較して Yes or No がわかる
N = 16, 判定クエリが [3, 13] に来たときの例

提出コード:https://atcoder.jp/contests/abc341/submissions/50494167
ABC360 G - Suitable Edit for LIS
変更する場所 x をすべて試して LIS の長さの max を取る。
- A[1] は -∞
- A[N] は +∞
に変更するのが最適なので 1 < x < N を考える。
A[x - 1] と A[x + 1] の間に「隙間」があると LIS を伸ばせそう。
A[x - 1] + 1 < A[x + 1] のとき A[x] を A[x - 1] + 1 とおけば、
- A[1], A[2], ..., A[x - 1] の LIS のうち、A[x - 1] で終わるもの (▲)
- A[x]
- A[x + 1], ..., A[N] の LIS のうち、A[x + 1] で始まるもの (■)
をこの順につないだ列は A[1], ..., A[N] の LIS になる。
LIS (▲) の長さは dp をセグメント木で高速化して LIS を求めるよくあるやり方で分かる。(■) も同じようにして分かる。
ABC366 G - XOR Neighbors
連立方程式のメモ
サンプル4のグラフを隣接行列であらわした。
0 1 1 0
1 0 1 1
1 1 0 1
0 1 1 0
この行列を A として Ax = 0 の解で、成分が全て非零である x が答えになる。
x を 0/1 ベクトルとして解空間の基底を求めよう。掃き出し法をするとこうなる。
1 0 1 1
0 1 1 0
0 0 0 0
0 0 0 0
連立方程式
を考えるとよくなった。
が成り立つように
と分かる。これを並べて