フロントで扱うAPIをGraphQLからRESTに移行し始めた複雑な事情
開発に関わっているプロダクトでAPIの取得仕様をGraphQLからRESTに変更する方針で動いています。
RESTからGraphQLへの移行を検討している場合もあると思いますが、再度RESTに戻すといった労力が発生しないための参考になったらと思います。
▼事前に知っておくと良さそうなこと(GPT生成)
GraphQLとは?
GraphQLは、Facebookが2015年に公開したデータクエリと操作用のオープンソースのデータ通信プロトコルとランタイムです。GraphQLを使用すると、クライアントが必要なデータの形状とセットを指定し、サーバーから厳密にその要求に従ったデータを取得することができます。
これにより、データの過剰転送を防ぎ、ネットワークの効率を向上させることができます。
コード例:
{
user(id: "1") {
id
name
}
}
Apolloクライアントとは?
Apollo Clientは、GraphQLクエリを構築、要求、キャッシングするための高度に柔軟な、フル機能のGraphQLクライアントです。
React、Vue、Angular等のJavaScriptフレームワークとの統合が容易で、APIからデータを取得してUIを更新するための複雑なロジックを抽象化します。
サーバーサイドレンダリング(SSR)やページングなどの高度な機能もサポートしています。
コード例:
import React from 'react';
import { ApolloClient, InMemoryCache, gql } from '@apollo/client';
const client = new ApolloClient({
uri: 'https://your-graphql-endpoint.com/graphql',
cache: new InMemoryCache()
});
client.query({
query: gql`
{
user(id: "1") {
id
name
}
}
`
}).then(result => console.log(result));
REST APIとは?
REST (Representational State Transfer) APIは、ウェブサービスとのインターフェースを提供する一連の規則や原則を指します。
RESTfulなAPIは、HTTPプロトコルを利用し、そのメソッド(GET、POST、PUT、DELETEなど)を使用してリソースの作成、読み取り、更新、削除(CRUD)操作を行います。これは、リソースの状態がクライアントとサーバー間で遷移する方法を提供します。
コード例:
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(response => response.json())
.then(json => console.log(json))
useSWRとは?
useSWRは、Reactアプリケーションでデータフェッチを行うための軽量なフックライブラリです。SWRとは、HTTPキャッシュ無効化の戦略「Stale While Revalidate」の頭文字を取ったものです。
useSWRはこの戦略を使用して、可能な限り最新のデータを提供し、同時にパフォーマンスと体験を向上させます。つまり、データの読み込みにより良い体験を提供するため、一度取得したデータはキャッシュされ、後続のリクエストはそのキャッシュから取得されます。
そして、バックグラウンドで静かにデータの更新を行います。
コード例:
import useSWR from 'swr'
function Profile() {
const { data, error } = useSWR('/api/user', fetch)
if (error) return <div>Failed to load</div>
if (!data) return <div>Loading...</div>
return <div>Hello, {data.name}!</div>
}
移行前後のAPI取得方法
- 移行前
-
- API:GraphQL
-
- クライアント:Apollo
- 移行後
-
- API:REST API
-
- クライアント:useSWR
フロントはリアーキを進めていて、主にNext.jsを使っています。Next.js x Apolloクライアントで開発を進めるのもモダンな感じで良いですが、今回はRESTに移行する形になりました。
追って理由を説明します。
前提として、GraphQLは悪くない
GraphQL自体は個人的に結構好きでした。感覚的にどこからでも好きな情報を楽に取得でき、開発体験は良かったです。(十分使いこなすほど理解できたわけではないですが...)
学習コストは若干あるものの、多くのプロダクトにとってはGraphQLは利点の方が大きいかもしれません。ただ、この記事の内容は一例ですが構造的に向いていない場合もあるかと思います。
GraphQLとRESTの比較
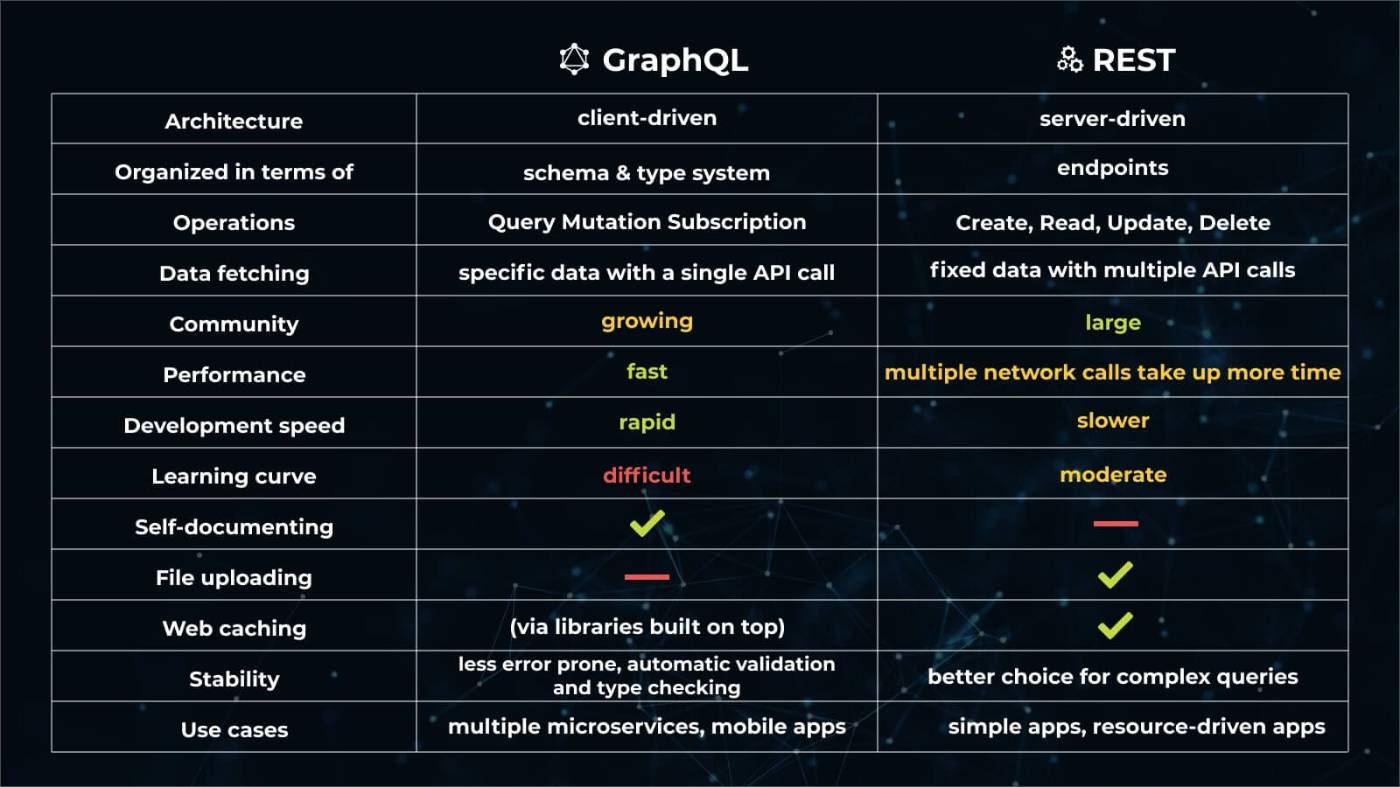
GraphQLとRESTの比較で分かりやすかったので貼りました。クライアントドリブンかサーバードリブンかなど一通り整理されてますね。
日本語の記事だとこちら分かりやすかったです。
なぜ、GraphQLからRESTに移行するのか?
GraphQLからRESTに移行することになった理由を整理しました。
理由①:権限が複雑でGraphQLを扱いづらくなった
データを効率かつ柔軟に取得できるのはGraphQLの大きな利点ですが、プロダクトの中でユーザーのロールに対して数十の権限が存在し、GraphQLでその権限に対応したレスポンスを常に返す及びエラーハンドリングやどのデータは取得できて何がダメなのかといったデータの管理が困難でした。
例えば、管理ユーザーであれば、dataAにアクセスできるが、通常ユーザーであれば権限Aを保持してなければdataAもアクセスできない。また、アクセスできないデータがある時、権限が不整合であれば権限エラーを返し、そうでない場合はnullを返すといった処理があったりと、それをGraphQLの自由な取得構造で行うのがカオスになっていました。
情報が上手く整理できていればGraphQLでも扱えるかもしれません。ただ、権限管理する項目が多いプロダクトであれば、同じような問題に直面する可能性は高い気はしています。
理由②:データの正確性が担保できなくなった
GraphQLはどこからでも概ね求めるデータにアクセスできます。ただ、どのパラメータを渡すかで返すデータは変わりますよね。
GPTに生成してもらった極端な例ですが、GraphQLでは次のようなクエリも記述できます。
query: gql`
users {
id
name
posts {
title
comments {
text
author {
name
posts {
title
comments {
text
author {
name
# さらに深くネストしたクエリが続く...
}
}
}
}
}
}
}
`
固定的な値であれば多少融通が効くものの、パラメーターによって変動する値を呼び出す際の挙動や、複雑な権限とデータベース構造が相まって、ネストが深くなる時に正しいデータが返されていることを保証するのが困難になっていました。
バックエンド側の開発はまだよくわかってないですが、多様なデータに対してそれらがGraphQLでどの階層から呼び出されても正確に意図した形で取得できるようにする、または常に適切な階層から呼び出すのは骨が折れそうですね。
この点はデータ取得方法を工夫することでもしかすると対応できる部分はあったかもしれません。ただ、深刻な悩みの種でした。
理由③:技術負債が溜まっていて改修困難であった
初期開発から数年経って構造もかなり複雑になり開発メンバーもだいぶ入れ替わっていく中で多様なコードが増え、技術負債が溜まっていました。
新規機能を開発するにも開発が複雑になったり、リアーキも進めている中で、改修だけでは対応困難な状況が増え、現在の仕様に対してGraphQLで対応するイメージが沸かなかったためRESTに移行することになりました。
その他:N+1問題
一般的にGraphQLの欠点として、N+1問題があるようです。詳しくないのでGPTに聞いてみました。
N+1問題とは?
N+1問題は、データベースを中心としたプログラミングにおいてよく見られるパフォーマンスの問題です。この問題は、一つの"親"レコードに対して複数の"子"レコードを取得する際に生じます。例えば、ブログ投稿とそれに対するコメントを考えてみましょう。
ー
N+1問題が発生する典型的なシナリオは次のようなものです:
最初に、あるブログの全ての投稿(N個の投稿)をデータベースから取得します。これが「1」の部分です。
次に、それぞれの投稿に対して、それに関連するコメントをデータベースから取得します。これが「N」の部分です。つまり、各投稿ごとに別々のクエリがデータベースに発行されます。
結果として、全体でN+1回のクエリがデータベースに発行されることになります。データベースへのクエリ回数が多いほどパフォーマンスに悪影響を及ぼすため、このN+1問題は大きな問題となることがあります。
この問題を解決するためには、一般的には「イーガーローディング(eager loading)」というテクニックが使われます。イーガーローディングでは、投稿とそれに関連するコメントを1つのクエリでまとめて取得します。この方法であれば、データベースへのクエリ回数は大幅に減少し、パフォーマンスも向上します。
GraphQLではN+1問題が頻発しやすいです。なぜなら、GraphQLはクライアントが要求するデータの形状を柔軟に指定できるため、予期せぬN+1問題を引き起こす可能性があるからです。
ー
これを解決するために、一部のGraphQLサーバーではデータローディング戦略を最適化するためのツールを提供しています。例えば、Facebookの「dataloader」がその一つです。
要するに、ネストが深くなる時にパフォーマンスの問題が起こりやすいということですかね。N+1問題はBEサイドでしばしば話題には上がってるのは聞いてました。
どうREST化したのか?
具体的なバックエンドの開発については書けないので方針を簡単に説明すると、ページ単位でエンドポイントを作成する形でバックエンドの開発を行う形になりました。(共通化されている部分などは専用のエンドポイントを用意)
これによりエンドポイントは増えるものの、悩みの種であった権限と権限に応じた取得データの確認が正確にできるようになりました。また、ページごとに必要なデータを返すことでオーバーフェッチングも回避していて、パフォーマンスを意識した開発ができています。
また、モーダルを開いた時に取得するデータなど、アクションに応じて取得するものは別途エンドポイントを用意しています。
移行のための開発工数はある程度取る必要はあるものの、移行前の問題は全面的に解消された感があって良い感じです。
REST化して解決したこと
では、具体的にREST化して何が解決したのか。
利点①:APIの責務分離が明確になり、必要なデータを正確に扱えるようになった
REST APIのエンドポイントごとに取得可能なデータが決まったので、データを正確に操作・管理できるようになりました。
改修時もどのAPIのコードを直すのかが明確なのでコード修正もしやすくなったのではと思います。
利点②:レスポンス内容を整理したことでフロントの記述量が減った
GraphQLを使っていた時代は、GraphQLから取得したデータをフロントでよしなに加工して使ってましたが、REST化に伴ってフロント側に必要なデータ形式でレスポンスを返す形になりました。
これによってフロント側はコードの記述量が減り、表示部分の開発に専念できるようになりました。
利点③:データの扱いがシンプルになった
GraphQLではフラグメントを使って取得するデータを整理してリクエストを送ってました。
ちょっとしたことですが、このフラグメントの扱いがなかなか慣れなかったので、個人的にREST化されたことで考えることが減って楽になりました。
RESTの方がGrapQLよりも学習コストは低いので、フロント経験が浅くても開発しやすいのも大きいかもですね。
RESTに移行する上で大変なこと
前のセクションでも書いてありますが、概ねこんな感じです。
①:移行工数の問題
単純にAPIの開発工数が結構かかります。
ただ、技術負債はどこかで解消しなければならないので、今の段階で移行を進められて良かったと思います。
②:レスポンスの仕様を定義する必要がある
GraphQLの取得形式をそのままRESTに置き換えるのではなく、バックエンド側で処理できる値は事前に加工した形でレスポンスを返すといった形で最適化を行っています。
APIの仕様を考えるのは慣れていないので少し頭がこんがらがっていました。
③:エンドポイントが増えることによる複雑性の発生
REST運用の場合、APIのエンドポイントが増えるのでAPIの管理面は多少複雑になります。
この点は、情報設計の得意なできるエンジニアがいれば良い感じになるはずですが、今回はそもそものデータ構造がかなり複雑だったので、エンジニア不足だったり設計を蔑ろにすると別の技術負債ができあがってしまうかもしれません。
話題になった意見
Meta社の元エンジニアのジェフリー氏は、旧Twitterで次のように投稿していました。(埋め込みだと十分なテキストが表示されなかったため引用してます。)
Metaでは、GraphQLは仕事の重要な一部でした。他のエンジニアにおすすめするかどうかはスケール次第です。GraphQLのQueryやスキーマを書くには多くのオーバーヘッドがあって、REST APIで設計して書いた方がシンプルです。
GraphQLは、常に変化し、複数のプラットフォームを対象にする巨大なコードベースで働く数百人以上の開発者の環境を開発しやすい環境にすることを目的としています。
ただし、小規模から中規模のプロジェクトでは、データが単純なCRUD操作ではなく、データのクエリが必要なほど複雑な場合を除いては、逆の効果かもしれません。
引用: titter.com
エンジニア側の共感が結構あった印象です。T3の考え方に「Bleed Responsibility」というのがあるのですが、新しい技術を採用する際は、それに伴ってどういった血が流れるのかは気にした方が良さそうです。
結果、REST化して良い感じ
フロント視点では、REST化によって取得・表示するデータ構造が明確になって、開発しやすさは非常に向上しました。まだREST化途中なので問題は出てくるかもですが、さほど怖い感じはしていません。
RESTからGraphQLに変更する話はあっても、GraphQLからRESTに切り替える話は少ないのではと思っていて何かしら参考になったら幸いです。
他に記述するような事項があれば、追加したりしていきます。
Discussion