文字コードとは?~解説とエンコーディングJava実践~
はじめに
繝ゥ繝シ繝。繝ウ鬟溘∋縺溘>
一度はこのような文字化けを見たことがあると思います。では、どうしてこのような文字化けが生じてしまうのでしょうか?この謎を解くカギが文字コードなのです。本記事では、文字化けのメカニズムから実際のJavaでの実装まで、文字エンコーディングについて分かりやすく解説していきます。
文字コードと文字エンコーディングの基礎
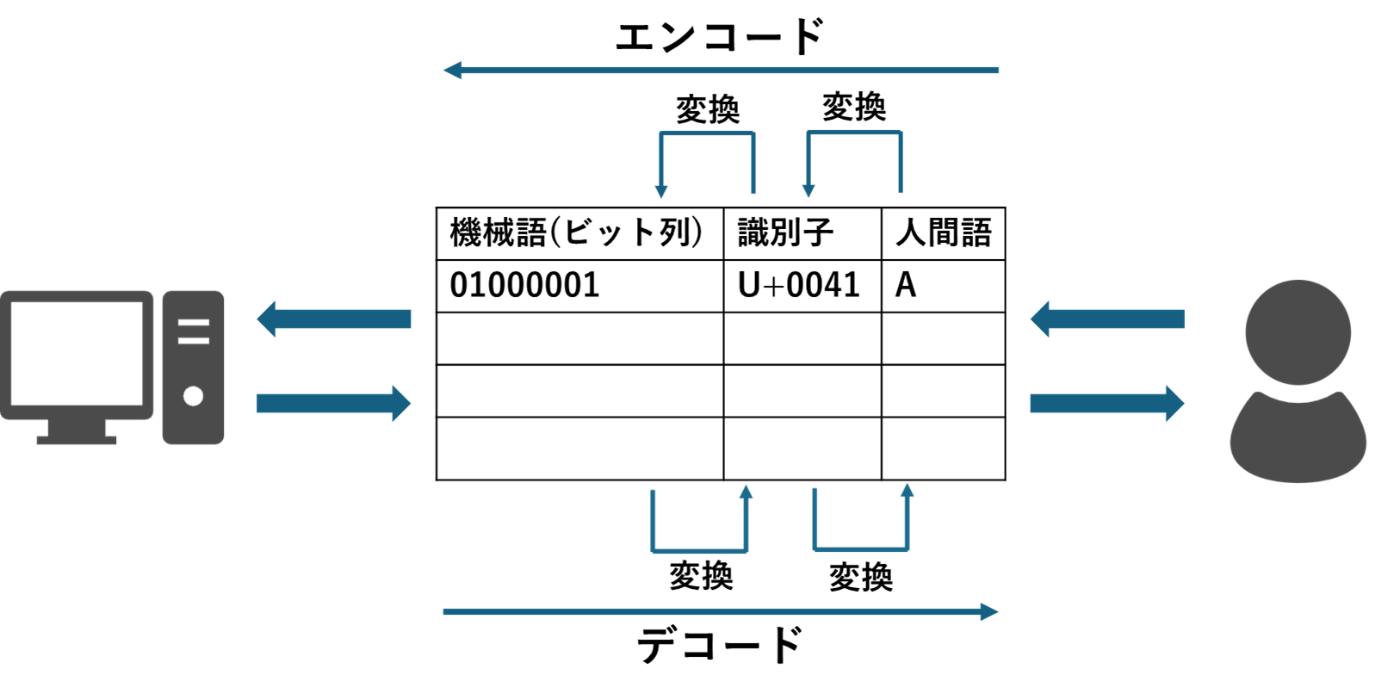
私たち人間は普段、言葉をそのままの形で理解できていますが、コンピュータは0と1の並び、つまり2進数でしか理解できません。そこで言葉を2進数に変換してコンピュータに伝える必要があり、変換する際に用いるものが文字コードというわけです。
例えば、人間語'A' → 機械語'01000001' のように固有の番号を割り当てることで、コンピュータが扱えるようになります。
文字コードの2つの概念
文字コードには二つの重要な概念があります
1. 符号化文字集合(Coded Character Set)
符号化文字集合とは、扱う文字集合そのものと、集合内の各文字と識別子を対応させる規則のことです。
例えば、人間語 'A' はUnicodeにおいて 'U+0041' という識別子と対応します。
2. 文字符号化方式(Character Encoding Scheme)
さらに、この識別子をコンピュータが扱える0と1のビット列の並びに変換する必要があり、変換の方式が文字符号化方式であり、変換することをエンコードと呼びます。
符号化文字集合で扱う集合の大きさに応じてバイト数、可変長・固定長等が決定されます。
例えば、Unicodeにおける人間語 'A' に対応する識別子 'U+0041' をUTF-によりエンコードすると 機械語'01000001' と表せます。この形まで変換して初めてコンピュータが扱えるようになったというわけです。
また逆に機械語を人間語に戻す作業のことをデコードと呼びます。
文字化けが発生する理由
ここで冒頭の謎が解けます。
文字化けとはエンコード時とデコード時で異なる文字符号化方式を使用した際に発生する現象です。
例えば「UTF-8」でエンコードされたテキストデータを「Shift_JIS」でデコードしてしまうと、コンピュータは間違った解釈をしてしまい、意味不明な文字列が表示されてしまうのです。
まるで、日本語で書かれた手紙を英語の辞書で読もうとするようなものですね。
代表的な文字コード一覧
よく利用される文字コードを整理してみましょう。
| 大分類 | 文字集合 | 符号化方式 | 説明 |
|---|---|---|---|
| 半角系 | ASCII | 米国規格。半角英数記号文字を定義したもの。7ビット。 | |
| ISO/IEC 646 | 国際規格。ASCIIを各国語に拡張したもの。7ビット。 | ||
| JIS X 0201 | ISO/IEC 646 の日本カスタマイズ版。英数字・記号・半角カナを定義。旧称 JIS C 6220。 | ||
| ISO-8859 | 欧州系の文字を定めたもの。8ビット。 | ||
| 制御文字 | ISO/IEC 6429 | 制御文字を定義。 | |
| JIS X 0211 | ISO/IEC 6429 の日本版。旧称 JIS C 6223。 | ||
| JIS系 | JIS X 0208 | 平仮名、片仮名、漢字などの日本語を定義。 | |
| ISO-2022-JP | 主に電子メールで利用される。俗にいう JISコード。 | ||
| EUC-JP | 主に Linux 系システムで使用される。 | ||
| Shift_JIS | 主に Windows 系システムで使用される。 | ||
| JIS X 0212 | 通称「JIS補助漢字」。あまり使用されていない。 | ||
| JIS X 0213 | 通称「JIS2000」「JIS2004」。第三水準・第四水準漢字を定義。 | ||
| Unicode系 | Unicode | UTF-8 | Unicode で一番よく利用される形式。ASCIIは1バイト、日本語は3バイトで表現。 |
| UTF-16 | Unicode を 16ビットで表現。 | ||
| UTF-32 | Unicode を 32ビットで表現。 |
注意: 符号化方式が空欄の文字コードについて
現代では、符号化文字集合と文字符号化方式が分離しているという考え方が一般的ですが、一昔前は分離の概念がなく、一つの文字コードで両者を指していました。したがって、実質的には文字集合+符号化方式の統合的な文字コードとなっています。
主要な文字コードの詳細解説
ここからは、主要な文字コードについて詳しく見ていきましょう。
1. 符号化文字集合
ASCII
特徴
- 文字集合と符号化方式が統合されたような文字コード
- 1963年に制定された7ビット(128文字)の固定長エンコーディング
- 英数字と基本記号をエンコードする最初期の標準であり現在でも多くのシステムの基盤となっている
メリット
- シンプルで高速処理
- メモリ効率が良い
- 多くのシステムとの互換性が高い
デメリット
- 英語の文字と基本的な記号しか表現できない
- 拡張性がない
JIS X 0208
特徴
- 1978年に制定された日本語文字集合の標準規格
- ひらがな、カタカナ、漢字(第一・第二水準)を定義
- 2バイト固定長の文字集合
- 漢字は使用頻度順に第一水準(2,965字)・第二水準(3,390字)に分類
- 複数の符号化方式(ISO-2022-JP、EUC-JP、Shift_JIS)で利用可能
メリット
- 日常的な日本語文書に必要な文字をほぼカバー
- JIS規格として公的に標準化され信頼性が高い
- 第一・第二水準の分類で効率的な実装が可能
デメリット
- 集合が限定され、人名漢字等で不足
- 新しい文字の追加が困難
- 日本語以外の文字との組み合わせが困難
2. 文字符号化方式
ISO-2022-JP(JISコード)
特徴
- 1987年にRFC1468で標準化された日本語メール用エンコーディング
- 7ビット環境で日本語を表現するためのエスケープシーケンス方式
- JIS X 0208文字集合をISO-2022規格で符号化
- エスケープシーケンスで文字セットを切り替え
- 俗に「JISコード」と呼ばれる
メリット
- 英数字部分はそのままASCIIであり、ASCIIに互換がある
- ISO規格ベースで信頼性が高い
- 8ビット目を使わないため通信経路での化けが少ない
デメリット
- エスケープシーケンス分だけ容量が増えてしまう
- エスケープシーケンスの処理が複雑
Shift_JIS
特徴
- Microsoft社が定めた、Windows系で使用される符号化方式
- ASCIIで表現される半角文字・記号に日本語のひらがな・カタカナ・漢字などを加えた
- 1バイト文字(ASCII)と2バイト文字(日本語)が混在した可変長エンコーディング
- 第1バイトの値で1バイト/2バイト文字を判別
メリット
- ASCII互換で既存システムとの親和性が高い
- 日本語Windowsで広く採用
- 1バイト文字の処理効率が良い
- エスケープシーケンスが不要で実装が簡単
デメリット
- 文字の途中でデータが切れると文字化けしてしまう
- 新しい文字の追加が困難
- 日本語以外の文字と組み合わせが困難
- 可変長であるため、文字境界の判定が複雑
3. Unicode
Unicodeは世界中のあらゆる文字を統一的に扱うために開発された国際標準であり、符号化文字集合とそれをエンコードするUTF-8/UTF-16/UTF-32などの符号化方式を含む包括的な文字処理標準です。
現在では多言語対応の必要性からUTF-8がWebサイトの大多数で採用され、新規システム開発における事実上の標準となっています。
UTF-8
特徴
- 1~4バイトの可変長であり、ASCII文字は1バイト、日本語は3バイトで表現
- 様々な言語の文字を扱え、世界的に最も普及
- ASCII互換で既存システムとの親和性が高い
メリット
- 世界中の様々な文字に対応している
- ASCII互換で既存システムとの親和性が高い
- 任意のバイトから文字の開始位置を検出できるため、データの途中で切断された場合もエラーを最小限に抑えられる
- 現在、非常に広範なシステムで標準的にサポートされており、互換性が非常に高い
デメリット
- レガシーシステムとの互換性が低い場合がある
- 日本語のみを使う場合はShift_JIS等の方が容量が小さくなる
Javaでの文字エンコード・デコード
理論を理解したところで、実際にJavaでどのように文字エンコーディングを扱うのかを見ていきましょう。
Javaでは以下のように対応付けがなされています。
| 言語 | Java上の表現 | 説明 |
|---|---|---|
| 人間語 | String型 |
「こんにちは」など、人が読める文字列 |
| 機械語 | byte型配列 |
コンピュータが処理する数値データ |
| 操作 | Java上のメソッド | 説明 |
|---|---|---|
| エンコード | getBytes() |
String → byte[] への変換 |
| デコード | new String(bytes) |
byte[] → String への変換 |
byte型について理解しよう
まず、Javaのbyte型について理解しておきましょう。
Javaのbyte型は8ビット(1バイト)の符号付き整数で、範囲は -128 から 127です。最上位ビットが符号を表すため(0=正、1=負)、128以上の値は負数として表示されます。これは表示上の問題で、実際のデータ(ビットパターン)は正しく保存されています。
エンコード(人間語 → 機械語)
getBytesメソッド
人間語(String)を機械語(byte配列)に変換するにはgetBytes()メソッドを使用します。
String humanText = "こんにちは世界"; // 人間語
// デフォルトエンコーディング
byte[] defaultMachineCode = humanText.getBytes();
// 特定のエンコーディングを指定
byte[] utf8MachineCode = humanText.getBytes("UTF-8");
byte[] sjisMachineCode = humanText.getBytes("Shift_JIS");
getBytesメソッドの実践
それではgetBytes()メソッドを用いてエンコードを実践してみましょう。このメソッドを用いる際にはtry&catch文が必須です。
public class EncodingExample {
public static void main(String[] args) {
String humanText = "こんにちは世界"; // 人間語
try {
// UTF-8で機械語に変換
byte[] utf8MachineCode = humanText.getBytes("UTF-8");
// Shift_JISで機械語に変換
byte[] sjisMachineCode = humanText.getBytes("Shift_JIS");
System.out.println("人間語: " + humanText);
System.out.print("UTF-8機械語: ");
for (byte b : utf8MachineCode) {
System.out.print(b + " ");
}
System.out.println();
System.out.print("Shift_JIS機械語: ");
for (byte b : sjisMachineCode) {
System.out.print(b + " ");
}
System.out.println();
} catch (Exception e) {
e.printStackTrace();
}
}
}
実行結果:
人間語: こんにちは世界
UTF-8機械語: -29 -127 -109 -29 -126 -109 -29 -127 -85 -29 -127 -95 -29 -127 -81 -28 -72 -106 -25 -107 -116
Shift_JIS機械語: -126 -79 -126 -15 -126 -71 -126 -65 -126 -66 -90 -90 -138 69
同じ「こんにちは世界」という人間語でも、UTF-8とShift_JISでは全く異なる機械語になることが分かりますね!
デコード(機械語 → 人間語)
Stringコンストラクタ
機械語(byte配列)を人間語(String)に変換するにはStringのコンストラクタを使用します。
// 機械語データ
byte[] utf8MachineCode = {-29, -127, -109, -29, -126, -109}; // 「こん」のUTF-8
// デフォルトエンコーディングでデコード
String defaultText = new String(utf8MachineCode);
// 特定のエンコーディングを指定してデコード
String utf8Text = new String(utf8MachineCode, "UTF-8");
String sjisText = new String(utf8MachineCode, "Shift_JIS");
Stringコンストラクタの実践
今度は先ほどエンコードした機械語を、元の人間語に戻してみましょう。今回も、try&catch文が必須です。
public class DecodingExample {
public static void main(String[] args) {
// 事前に準備した機械語データ
byte[] utf8MachineCode = {-29, -127, -109, -29, -126, -109, -29, -127, -85, -29, -127, -95, -29, -127, -81, -28, -72, -106, -25, -107, -116};
byte[] sjisMachineCode = {-126, -79, -126, -15, -126, -71, -126, -65, -126, -66, -90, -90, -138, 69};
try {
// 機械語から人間語に復元
String decodedFromUtf8 = new String(utf8MachineCode, "UTF-8");
String decodedFromSjis = new String(sjisMachineCode, "Shift_JIS");
System.out.println("UTF-8機械語から復元: " + decodedFromUtf8);
System.out.println("Shift_JIS機械語から復元: " + decodedFromSjis);
} catch (Exception e) {
e.printStackTrace();
}
}
}
実行結果:
UTF-8機械語から復元: こんにちは世界
Shift_JIS機械語から復元: こんにちは世界
正しいエンコード方式でデコードすれば、完璧に元の人間語が復元されることが確認できました!
文字化けの例
それでは、実際に文字化けを発生させてみましょう。異なるエンコード方式でデコードすると文字化けが発生してしまいます:
public class CharacterCorruptionExample {
public static void main(String[] args) {
String originalText = "こんにちは";
try {
// UTF-8でエンコード
byte[] utf8Bytes = originalText.getBytes("UTF-8");
System.out.println("元の人間語: " + originalText);
// 正しいデコード
String correctDecode = new String(utf8Bytes, "UTF-8");
System.out.println("正しいデコード: " + correctDecode);
// 間違ったデコード(文字化け発生)
String wrongDecode = new String(utf8Bytes, "Shift_JIS");
System.out.println("間違ったデコード: " + wrongDecode);
} catch (Exception e) {
e.printStackTrace();
}
}
}
実行結果:
元の人間語: こんにちは
正しいデコード: こんにちは
間違ったデコード: ใใใซใกใฏ
エンコードと異なった方式でデコードしたことで、文字化けを確認することができましたね!
実践例:エンコーディング変換
理論と基本的な使い方を理解したところで、実際の開発現場でよくある場面を想定した実践例を見てみましょう!

今回は、上図のように長年稼働しているレガシーシステムから出力されたShift_JISのCSVファイルを、新しく導入したモダンシステムで読み込み、データ連携をするためにUTF-8のデータに変換することを想定しています。
public class CsvProcessor {
// Shift_JISのCSVファイルをUTF-8に変換
public void convertCsvEncoding(String inputPath, String outputPath) throws IOException {
// 入力ファイルをShift_JISで読み込むためのBufferedReader作成
BufferedReader reader = Files.newBufferedReader(
Paths.get(inputPath), Charset.forName("Shift_JIS"));
// 出力ファイルをUTF-8で書き込むためのBufferedWriter作成
BufferedWriter writer = Files.newBufferedWriter(
Paths.get(outputPath), StandardCharsets.UTF_8);
// 一行ずつ読み込むための変数
String line;
// ファイルの終端まで一行ずつ処理
while ((line = reader.readLine()) != null) {
// 読み込んだ行をそのままUTF-8で書き出し
writer.write(line);
// 改行文字を追加
writer.newLine();
}
// ファイルを閉じる(Shift_JIS読み込み用)
reader.close();
// ファイルを閉じる(UTF-8書き込み用)
writer.close();
}
}
適切なエンコーディングを指定することで、レガシーシステムとモダンシステム間でのデータ連携が可能になりましたね!
Discussion