ブラウザから起動したカメラでTCGのカードを識別する方法
この記事について
最近、TCG(トレーディングカードゲーム)も遊戯王はマスターデュエル、ポケモンはポケポケとデジタル化されたカードゲームのものが増えてきましたね!
最近自分がハマってやっているカードゲームは英傑大戦というゲームセンターのアーケード機で遊ぶカードゲームで、個人ツールとして英傑大戦ツールというのを作っているのですが、デッキ構成するときにカメラから作成できるものもあったら便利そうと思い、実践してみたという記事になります。(このゲーム、土方歳三がイラスト違いで複数あったり、姓が源、平、北条、島津が多くて画像で検索できるもの作った方が助かると思ったのもある)
できたもの

上記は自分のPixel 8aで撮った最新の英傑カメラUIでのスクショになります。
黒が多いイラストの識別や、ERカードのようなホログラム印刷やスリーブやローダなどのカードのカバーで光沢のあるカードあっても識別できるようになっています。

上記は友人のiPhoneのスクショで、古いUIの英傑カメラのバージョンになりますが、
暗い場合に試してもカード検出することに成功しました。
解説
ここからは画像認識するための実装を記載しますが、使用した学習モデル作成とWebフロントエンドの実装を分けて解説していきます。
学習モデル作成
学習モデル作成に必要なスクリプトとしてimport_cardtfmodel.tsを作成しました。
学習モデルに必要な画像データ作成
$ node --experimental-strip-types import_cardtfmodel.ts --cardImageTFModelForImage
というコマンドを実行を元に生成しています。
グラデーションなどの画像加工処理
for (const general of GeneralJSON) {
const dirName = `data/generals/${general.color.name}/${general.no}_${general.name}`;
const input2Path = `${dirName}/2.jpg`;
let i = 6;
await glossGradientHorizonTop({ dirName, inputPath: input2Path, i: i++ });
...省略
await createDarkenedImageGlossGradientRightBottom({
dirName,
inputPath: input2Path,
i: i++,
});
}
というコードからは元のカード画像に対して、いろんな角度で光があったかのようなグラデーションの付いた画像をnode-canvasで生成しています。
グラデーション画像としては以下のような、

縦、横、斜めにグラデーションを入れたような12枚のパターンを生成しています。
他には友人のiPhoneのスクショのように暗いカメラ環境考慮として、元のカードに黒でマスク化したものにグラデーションを入れた画像を生成しました。
GitHubに保存されている画像の6~80.jpgは学習モデルの考慮によって生成された画像になります。
前回のImageHashを用いた画像識別の記事とは違い、カメラの環境による入力の画像が異なるため、検出するためのカードの画像も多めになりました。
学習モデル作成
$ node --experimental-strip-types import_cardtfmodel.ts --cardImageTFModel
こちらの学習モデルは@tensorflow/tfjs-nodeを使った学習モデルになります。
実装方法とか最初わかりませんでしたがChatGPTで聞きながら実装し、理解していきました。
画像データのテンソル化とラベル付け
async function loadImageToTensor(imagePath: string) {
const image = (await Canvas.loadImage(
imagePath,
)) as unknown as HTMLImageElement;
const canvas = Canvas.createCanvas(
image.width,
image.height,
) as unknown as HTMLCanvasElement;
const ctx = canvas.getContext("2d");
if (!ctx) return;
ctx.drawImage(image, 0, 0);
const tensor = tf.browser
.fromPixels(canvas)
.resizeNearestNeighbor([cardSize.width, cardSize.height])
.toFloat()
.div(tf.scalar(255.0));
return tensor;
}
async function loadImagesFromDirectories() {
const generalsJSON: General[] = JSON.parse(
fs.readFileSync("data/json/generals.json", "utf8"),
);
const classNames = [];
const images: tf.Tensor<tf.Rank>[] = [];
const labels = [];
for (const general of generalsJSON) {
const className = `${general.color.name}_${general.no}_${general.name}`;
classNames.push(className);
// モデルに使用する画像の読み込みループ
for (const i of Array(81).keys()) {
// モデルに使用しない画像をスキップ
if (i === 0) continue;
if (i === 1) continue;
if (i === 3) continue;
const filePath = `data/generals/${general.color.name}/${general.no}_${general.name}/${i}.jpg`;
const tensor = await loadImageToTensor(filePath);
if (!tensor) continue;
images.push(tensor);
labels.push(classNames.indexOf(className));
}
}
const xs = tf.stack(images);
const ys = tf.tensor(labels, [labels.length, 1]);
return { xs, ys, classNames };
}
正直テンソル化の箇所はChatGPTのコピペですが必要な画像だけ読み込みしようとするための処理だけ追加しています。
テンソル化後のモデル構築とトレーニング、保存処理
const { xs, ys, classNames } = await loadImagesFromDirectories();
// モデルの構築
const model = tf.sequential();
model.add(
tf.layers.conv2d({
inputShape: [cardSize.width, cardSize.height, 3],
filters: 8,
kernelSize: 3,
activation: "relu",
}),
);
model.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
model.add(
tf.layers.conv2d({ filters: 16, kernelSize: 3, activation: "relu" }),
);
model.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
model.add(tf.layers.flatten());
model.add(
tf.layers.dense({ units: classNames.length, activation: "softmax" }),
);
// コンパイル
model.compile({
optimizer: "adam",
loss: "sparseCategoricalCrossentropy",
metrics: ["accuracy"],
});
// トレーニング
await model.fit(xs, ys, { epochs: 10 });
// モデルを保存
await model.save("file://./general-image"); // ローカルファイルに保存
console.log("モデルのトレーニングが完了しました");
学習モデルの分割
作成したモデルをWebフロントエンドでも使いやすく、Git LFSを使わずにGit管理するために分割しています。
分割するためにtensorflowjs_converterをインストールします。
Pythonは3.6.8を使っており、
numpyに関しては
AttributeError: module 'numpy' has no attribute 'XXX' エラーの解決ログにある問題があるため決まったバージョンによるインストールをしています。
$ pip install numpy==1.26.4
$ pip install tensorflowjs==3.18.0
必要なものをインストールした後は下記を実行してモデルを分割します。
$ tensorflowjs_converter --input_format=tfjs_layers_model --output_format=tfjs_layers_model --weight_shard_size_bytes=10485760 ./general-image/model.json ../app/public/tensorflow/general-image
weight_shard_size_bytesを変更することで好きなサイズに分割できます。
Webフロントエンド実装
学習モデルの読み込みをContextにする
Contextの作成
"use client";
import * as tf from "@tensorflow/tfjs";
import React from "react";
import { createContext } from "react";
export interface GeneralCardImageTFModelProviderProps {
children: React.ReactNode;
}
const GeneralCardImageTFModelContext = createContext<{
generalCardImageTFModel: tf.LayersModel | null;
}>({
generalCardImageTFModel: null,
});
function GeneralCardImageTFModelProvider({
children,
}: GeneralCardImageTFModelProviderProps) {
const [generalCardImageTFModel, setGeneralCardImageTFModel] =
React.useState<tf.LayersModel | null>(null);
React.useEffect(() => {
const loadModel = async () => {
const loadedModel = await tf.loadLayersModel(
"/eiketsu-taisen-tool/tensorflow/general-image/model.json",
);
setGeneralCardImageTFModel(loadedModel);
};
loadModel();
}, []);
return (
<GeneralCardImageTFModelContext.Provider
value={{
generalCardImageTFModel,
}}
>
{children}
</GeneralCardImageTFModelContext.Provider>
);
}
export { GeneralCardImageTFModelContext, GeneralCardImageTFModelProvider };
const { generalCardImageTFModel } = React.useContext(
GeneralCardImageTFModelContext,
);
から事前に読み込み済みの学習モデルを使いやすくします。
ページのロジック実装
index.tsxは主にUIの実装、logic.tsxは雑に処理を記載しています。
使用できるカメラ情報の取得
カメラ情報取得
const { generalCardImageTFModel } = React.useContext(
GeneralCardImageTFModelContext,
);
const [devices, setDevices] = React.useState<MediaDeviceInfo[]>([]);
React.useEffect(() => {
if (!generalCardImageTFModel) return;
const getDevices = async () => {
try {
await navigator.mediaDevices.getUserMedia({
video: true,
audio: false,
});
const enumerateDevices =
await window.navigator.mediaDevices.enumerateDevices();
setDevices(
enumerateDevices.filter(
(device) => device.kind === "videoinput" && device.label,
),
);
} catch (_) {}
};
getDevices();
}, [generalCardImageTFModel]);
使用できるカメラの情報は全てセレクトボックスから選択できるように取得しています。
最初はOBS Virtual Cameraでテストしていたという開発ネタもありました。(色々ノイズのない画像でも正しく検知できるか確認したいときに便利)
カメラ選択処理
const refVideo = React.useRef<HTMLVideoElement>(null);
const [device, setDivice] = React.useState<MediaDeviceInfo | null>(null);
const [isVideo, setIsVideo] = React.useState(false);
React.useEffect(() => {
if (!device) return;
if (!refVideo) return;
if (!refVideo.current) return;
const video = refVideo.current;
const check = async () => {
try {
if (!window.navigator.mediaDevices.getUserMedia) return;
const stream = await window.navigator.mediaDevices.getUserMedia({
audio: false,
video: {
deviceId: device.deviceId,
},
});
video.srcObject = stream;
video.addEventListener("loadedmetadata", () => {
setIsVideo(true);
});
} catch (e) {
console.error(e);
}
};
check();
}, [device]);
video.addEventListener("loadedmetadata")して初めてカメラの映像がvideoに読み込まれるため別でisVideoを状態管理しています。
選択したカメラの映像をcanvas化する
後にカメラの映像に対して選択範囲指定の枠を描画するためにcanvas化しています。
そのため、カメラの映像はvideoタグで映していますが、
<video muted autoPlay playsInline ref={refVideo} className="h-0" />
と見えないようにしています。
canvas化と選択範囲の描画
const refVideoCanvas = React.useRef<HTMLCanvasElement>(null);
const [selectedVideoCanvasPosition, setSelectedVideoCanvasPosition] =
React.useState({
from: {
x: 0,
y: 0,
},
to: {
x: 0,
y: 0,
},
});
const detectAndResizeCard = () => {
if (!generalCardImageTFModel) return;
if (!isVideo) return;
if (!refVideo.current) return;
const video = refVideo.current;
if (!refVideoCanvas.current) return;
const videoCanvas = refVideoCanvas.current;
const videoCanvasContext = videoCanvas.getContext("2d", {
willReadFrequently: true,
});
if (!videoCanvasContext) return;
try {
const frameWidth = video.videoWidth;
const frameHeight = video.videoHeight;
videoCanvas.width = frameWidth;
videoCanvas.height = frameHeight;
videoCanvasContext.drawImage(video, 0, 0, frameWidth, frameHeight);
// 矩形選択に基づいた線を描画
const { from, to } = selectedVideoCanvasPosition;
videoCanvasContext.beginPath();
videoCanvasContext.rect(from.x, from.y, to.x - from.x, to.y - from.y);
videoCanvasContext.strokeStyle = "red"; // 線の色を設定
videoCanvasContext.lineWidth = 2; // 線の太さを設定
videoCanvasContext.stroke();
} catch (e) {
console.error(e);
}
};
React.useEffect(() => {
if (!isVideo) return;
const intervalId = setInterval(detectAndResizeCard, 1000 / 120);
return () => clearInterval(intervalId);
}, [isVideo, selectedVideoCanvasPosition]);
setInterval(detectAndResizeCard, 1000 / 120);しているのは体感120fpsで処理してみようかなという意図です。
カメラの映像と共にcanvasの表示が変わるため、選択範囲の描画の処理も入れています。
範囲選択の座標取得処理
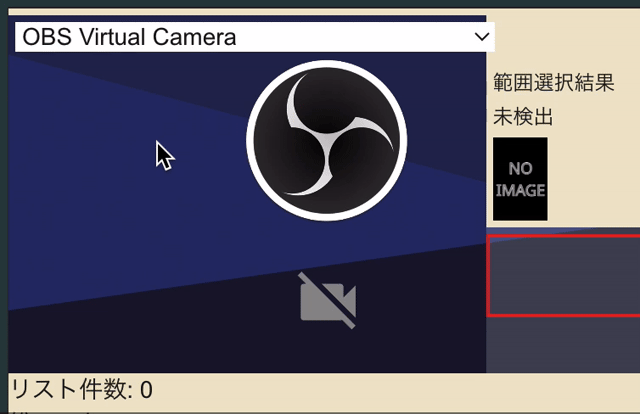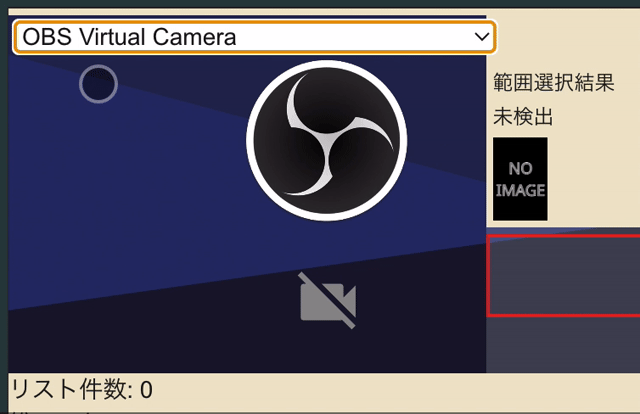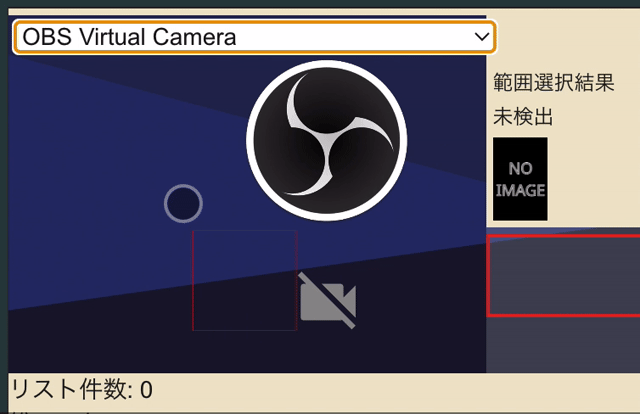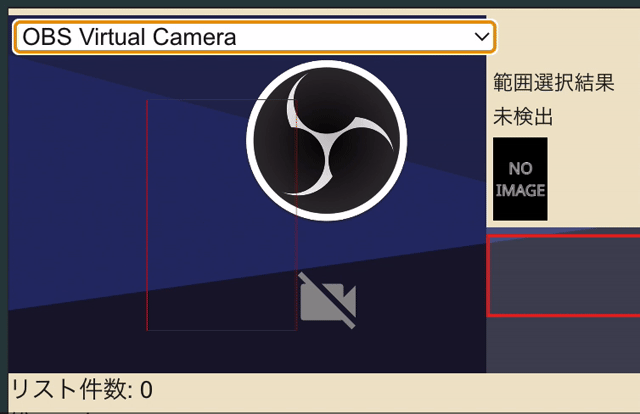
カメラを映しているcanvas上をドラッグするとみょーんと選択範囲が指定されるやつです。
範囲選択の座標取得処理
// キャンバス内の位置を実際の解像度に合わせるための関数
const adjustForCanvasScale = (clientX: number, clientY: number) => {
if (!refVideoCanvas.current)
return {
x: 0,
y: 0,
};
const videoCanvas = refVideoCanvas.current;
const rect = videoCanvas.getBoundingClientRect();
const scaleX = videoCanvas.width / rect.width;
const scaleY = videoCanvas.height / rect.height;
return {
x: (clientX - rect.left) * scaleX,
y: (clientY - rect.top) * scaleY,
};
};
/**
* モバイルスクロール禁止処理
*/
const scrollNo = React.useCallback((e: TouchEvent) => {
if (e.cancelable) {
e.preventDefault();
}
}, []);
const onTouchStartVideoCanvas: React.TouchEventHandler<HTMLCanvasElement> = (
e,
) => {
const touch = e.touches[0];
const position = adjustForCanvasScale(touch.clientX, touch.clientY);
document.addEventListener("touchmove", scrollNo, { passive: false });
document.body.style.overflow = "hidden";
setSelectedVideoCanvasPosition({
from: position,
to: position,
});
setIsSelectingVideoCanvasPosition(true);
};
const onMouseDownVideoCanvas: React.MouseEventHandler<HTMLCanvasElement> = (
e,
) => {
const position = adjustForCanvasScale(e.clientX, e.clientY);
document.addEventListener("touchmove", scrollNo, { passive: false });
document.body.style.overflow = "hidden";
setSelectedVideoCanvasPosition({
from: position,
to: position,
});
setIsSelectingVideoCanvasPosition(true);
};
const onTouchMoveVideoCanvas: React.TouchEventHandler<HTMLCanvasElement> = (
e,
) => {
if (!isSelectingVideoCanvasPosition) return;
const touch = e.touches[0];
const position = adjustForCanvasScale(touch.clientX, touch.clientY);
setSelectedVideoCanvasPosition((prevSelection) => ({
...prevSelection,
to: position,
}));
};
const onMouseMoveVideoCanvas: React.MouseEventHandler<HTMLCanvasElement> = (
e,
) => {
if (!isSelectingVideoCanvasPosition) return;
const position = adjustForCanvasScale(e.clientX, e.clientY);
setSelectedVideoCanvasPosition((prevSelection) => ({
...prevSelection,
to: position,
}));
};
const onTouchEndVideoCanvas: React.TouchEventHandler<
HTMLCanvasElement
> = () => {
document.body.style.overflow = "auto";
document.removeEventListener("touchmove", scrollNo);
setIsSelectingVideoCanvasPosition(false);
};
const onMouseUpVideoCanvas: React.MouseEventHandler<
HTMLCanvasElement
> = () => {
document.body.style.overflow = "auto";
document.removeEventListener("touchmove", scrollNo);
setIsSelectingVideoCanvasPosition(false);
};
onMouseDownとonTouchStartと似たような処理がありますがPCのときはonMouse、スマホのときはonTouchでイベントが実行されるので2つの処理があります。
後はドラッグ中は妙なスクロールが発生しないようにする処理を記載しています。
範囲選択から別のcanvasに描画と学習モデルによる識別処理
ここからがようやくWebフロントエンドで作成した学習モデルを使って画像認識する処理になります。
範囲選択から別のcanvasに描画と学習モデルによる識別処理
const refSelectedCardCanvas = React.useRef<HTMLCanvasElement>(null);
const onClickSelectedCardButton: React.MouseEventHandler<
HTMLButtonElement
> = async () => {
if (!generalCardImageTFModel) return;
if (!refSelectedCardCanvas.current) return;
const selectedCardCanvas = refSelectedCardCanvas.current;
const selectedCardCanvasContext = selectedCardCanvas.getContext("2d", {
willReadFrequently: true,
});
if (!selectedCardCanvasContext) return;
if (!refVideoCanvas.current) return;
const videoCanvas = refVideoCanvas.current;
const videoCanvasContext = videoCanvas.getContext("2d", {
willReadFrequently: true,
});
if (!videoCanvasContext) return;
// 矩形選択の箇所を取得
const { from, to } = selectedVideoCanvasPosition;
const width = from.x < to.x ? to.x - from.x : from.x - to.x;
const height = from.y < to.y ? to.y - from.y : from.y - to.y;
const x = from.x < to.x ? from.x : to.x;
const y = from.y < to.y ? from.y : to.y;
selectedCardCanvas.width = width;
selectedCardCanvas.height = height;
selectedCardCanvasContext.drawImage(
videoCanvas,
x,
y,
width,
height,
0,
0,
width,
height,
);
if (width === 0 || height === 0) return;
const imageData = selectedCardCanvasContext.getImageData(
0,
0,
selectedCardCanvas.width,
selectedCardCanvas.height,
);
setSelectedCard({
loading: true,
general: undefined,
});
await tf.setBackend("webgl");
await tf.ready();
tf.tidy(() => {
const tensor = tf.browser
.fromPixels(imageData)
.resizeNearestNeighbor([cardSize.width, cardSize.height]) // モデルに合わせてリサイズ
.toFloat()
.div(tf.scalar(255.0))
.expandDims(0);
const prediction = generalCardImageTFModel.predict(tensor);
// @ts-ignore
const maxIndex = (prediction.argMax(-1) as tf.Tensor).dataSync()[0];
const general = GeneralsJSON[maxIndex];
setSelectedCard({
loading: false,
general,
});
});
};
await tf.setBackend("webgl");とawait tf.ready();はWebGLを使うための処理で、tf.tidyはメモリリークを防ぐための処理です。
resizeNearestNeighbor([cardSize.width, cardSize.height])は学習モデル作成で指定したサイズにリサイズしています。
個人的にモヤっている実装として
const prediction = generalCardImageTFModel.predict(tensor);
// @ts-ignore
const maxIndex = (prediction.argMax(-1) as tf.Tensor).dataSync()[0];
const general = GeneralsJSON[maxIndex];
の部分の検出結果の取得なのですが、indexじゃなくてモデル作成時に
const { xs, ys, classNames } = await loadImagesFromDirectories();
とカードの名前をclassNamesに保存していたのでモデルの中にも組み入れて名前でできないかと考えています。
後は、TypeScriptで補完されている様で型がない変数があったりもするので、だいぶ疑心暗鬼なところがありますが、とりあえず動いているのでよしとしています。
感想
- 難しいと思った実装もChatGPTでできました。
- 初めてブラウザで学習モデルを使った画像認識をしたので他にも活用したいなと思いました。
- 学習モデルのモデリングの考慮が大変でした。
- ブラウザ上でもNode.js上でもcanvasが大活躍でした。
Discussion