Closed6
llama2 13B LoRA
tokenizer
一応、見ておく
from transformers import AutoTokenizer
model_name ='meta-llama/Llama-2-13b-hf'
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(tokenizer.special_tokens_map)
print(tokenizer.eos_token, tokenizer.eos_token_id)
print(tokenizer.bos_token, tokenizer.bos_token_id)
print(tokenizer.unk_token, tokenizer.unk_token)
{'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}
</s> 2
<s> 1
<unk> 0
add_special_tokensでbosが付与
defaultはTrue
r = tokenizer(["あ"])
{'input_ids': [[1, 29871, 30641]], 'token_type_ids': [[0, 0, 0]], 'attention_mask': [[1, 1, 1]]}
r = tokenizer(["あ"], add_special_tokens=True)
{'input_ids': [[1, 29871, 30641]], 'token_type_ids': [[0, 0, 0]], 'attention_mask': [[1, 1, 1]]}
r = tokenizer(["あ"], add_special_tokens=False)
{'input_ids': [[29871, 30641]], 'token_type_ids': [[0, 0]], 'attention_mask': [[1, 1]]}
padding/attention_mask
paddingが設定されていないのでunk_tokenをpaddingするのが良いかも?
unk_tokenはmaskされてる
padding_sideはdefaultでleft
tokenizer.pad_token_id = tokenizer.unk_token_id
r = tokenizer(["あ", "あいう"], padding=True)
{'input_ids': [[0, 0, 1, 29871, 30641], [1, 29871, 30641, 30298, 30465]], 'token_type_ids': [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0]], 'attention_mask': [[0, 0, 1, 1, 1], [1, 1, 1, 1, 1]]}
statdict
from transformers import AutoModelForCausalLM
import torch
model_name ='meta-llama/Llama-2-13b-hf'
model = AutoModelForCausalLM.from_pretrained(model_name,
device_map='auto',
load_in_4bit=True,
torch_dtype=torch.float16)
for v in model.state_dict().items():
print(v[0])
model.embed_tokens.weight
model.layers.0.self_attn.q_proj.weight
model.layers.0.self_attn.k_proj.weight
model.layers.0.self_attn.v_proj.weight
model.layers.0.self_attn.o_proj.weight
model.layers.0.self_attn.rotary_emb.inv_freq
model.layers.0.mlp.gate_proj.weight
model.layers.0.mlp.up_proj.weight
model.layers.0.mlp.down_proj.weight
model.layers.0.input_layernorm.weight
model.layers.0.post_attention_layernorm.weight
.
.
model.norm.weight
lm_head.weight
7B: config.pretraining_tp=1
13B: config.pretraining_tp=2
pretraining_tpについては以下
pretraining_tp=2だとここでこける
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)]
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1984x5120 and 1x2560)
ただ、splitして全結合に入力しているだけなので並列で計算できるかの違いで、
loraで学習させるときはconfig.pretraining_tp=1にしてしまっても良さそう
以下参照
pretraining_tp=1にしてしまっても良さそう
とりあえず手元で設定するならこう
config = AutoConfig.from_pretrained(base_model)
config.pretraining_tp = 1
base_model = AutoModelForCausalLM.from_pretrained(
'meta-llama/Llama-2-13b-hf',
torch_dtype=torch.bfloat16,
load_in_4bit=True,
config=config
)
マージされてるので気にしないで良さそう
training
meta-llama/Llama-2-13b-hf
colab A100
1epoch
dolly-ja
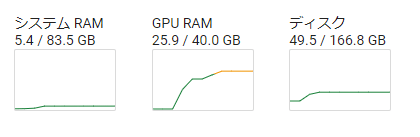
{'loss': 1.2678, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.02}
...
{'loss': 0.5652, 'learning_rate': 1.568627450980392e-05, 'epoch': 0.96}
{'loss': 0.5635, 'learning_rate': 5.88235294117647e-06, 'epoch': 0.98}
{'eval_loss': 0.5745614767074585, 'eval_runtime': 1.2067, 'eval_samples_per_second': 8.287, 'eval_steps_per_second': 1.657, 'epoch': 0.98}
{'train_runtime': 20987.6925, 'train_samples_per_second': 2.477, 'train_steps_per_second': 0.019, 'train_loss': 0.6362269024543574, 'epoch': 1.0}
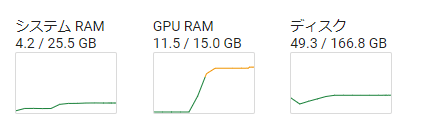
infarence
infarenceはcolab T4でいける
<s> 以下は、ある作業を記述した指示です。要求を適切に満たすような応答を書きなさい。
### 命令:
日本で1番高い山を教えてください。
### 応答:
日本で1番高い山は富士山です。
</s>
<s> 以下は、ある作業を記述した指示です。要求を適切に満たすような応答を書きなさい。
### 命令:
色の三原色はなんですか?
### 応答:
色の三原色は赤、緑、青です。
</s>
このスクラップは2023/07/20にクローズされました