llama2のアーキテクチャを変更してpre trainingしてみる
LLM Advent Calendar 2023の記事です
はじめに
以前、llama2のpre trainingを行いました。できるだけ小さいサイズで日本語を喋れるモデルを作りたいということで、さらなる改善のためいくつかのアーキテクチャを考えてみます。
llama2をpre trainingした記事はこちら
比較のベースとなる標準的なモデルと、新たに3つのモデルを作成して比較します。
transformerのattention部分に対して修正や変更を加えたものはEfficient Transformerと呼ばれます。attentionの計算では、keyとvalueの行列積の計算のコストが高く、この部分を近似や次元削減を行い、計算効率やメモリ効率の向上を目指したものがいくつか提案されています。
pytorchで実装されたsampleが以下で公開されており眺めるのも楽しいです
今回は、今回はメモリや計算の効率化というより、性能向上を目指してattentionに修正を行ってみます。大きいサイズのモデルだと学習に時間がかかりすぎるので100Mのサイズを学習しました。絶妙に日本語が喋れるか喋れないかのモデルが完成したので、結果の比較が難しく、苦戦している記事になるので注意
モデル
ベースのモデルに対し少しづつ複雑さを増したモデルを作成する。
ベースのモデル
head数1、layer数10のモデルをベースモデルとする。
attentionの部分を簡単に表すと以下のようになる。attentionへの入力は全結合層を通り、queryとkey, valueに分割される。queryとkeyの積を取りscaleした後softmaxを取ったものとvalueの積を取る。(実際にはhead数の次元やgrouped queryが含まれるが省略)
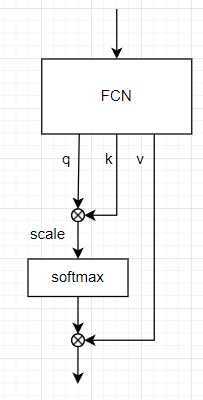
このベースのモデルに対していくつかの修正を行う
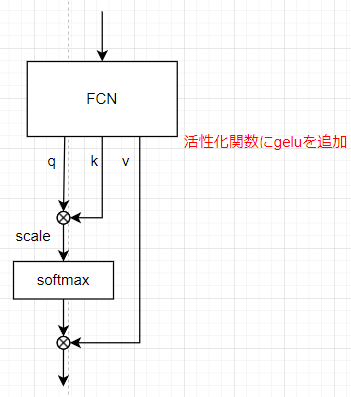
モデル1(非線形活性化関数+bias)
通常、全結合層に活性化関数やbiasは含まれないがここにbiasと活性化関数geluを追加する。
head数やlayer数はベースモデルと同様
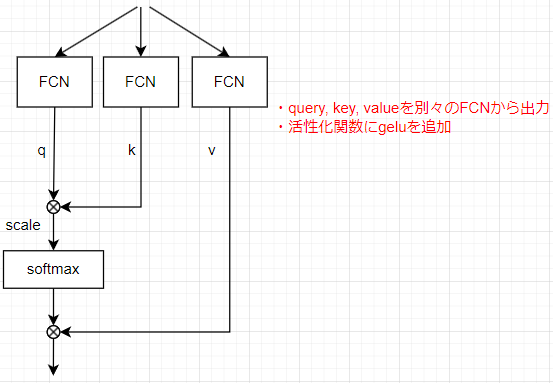
モデル2(query, key, valueの生成を分ける)
query, key, valueは一つのFCNの出力を分割して作られていたが、これを別々のFCNで計算させる。head数やlayer数はベースモデルと同様
queryとkeyで別々の特徴を捉えてほしいという期待
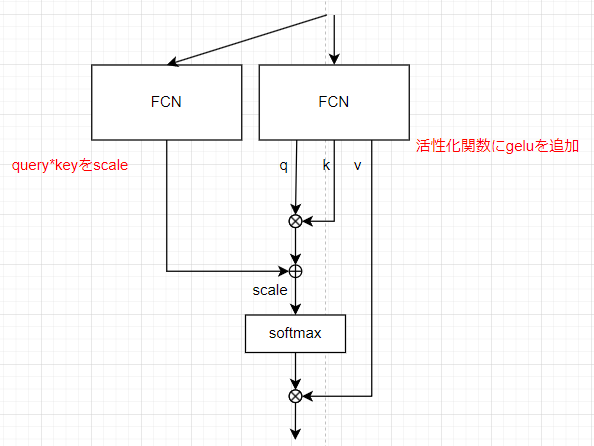
モデル3(query*keyにscaleを追加)
通常のattention weightでは、queryとkeyの積をsoftmaxを取り、valueとの積を取る。これに対し、queryとkeyの積に対して、別のFCNを追加しその出力を足し合わせて、softmax、valueとの積を取るようにする。head数やlayer数はベースモデルと同様
queryに対応するkeyを取り出す通常の処理に対し、query,keyの積以外の観点で注意を行ってほしいという期待
実装
実装は以下のコードを参考にする
attention部分はここ
attentionへの入力は全結合層を通った後、query, key, valueに分割される。
qkv = self.attn(x)
query, key, valueに対し、head数に対する次元操作や、grouped queryの操作を行った後、attentionを計算している。
y = self.scaled_dot_product_attention(q, k, v, mask)
attentionは、queryとkeyの積を計算し、maskを適応、softmaxを取り、attention_weightを算出する。主にこの部分を修正する。
attn_weight = query @ key.transpose(-2, -1) * scale_factor
attn_weight += attn_bias
attn_weight = torch.softmax(attn_weight, dim=-1)
...
return attn_weight @ value
学習
1Bの日本語と英語のデータセットで2epoch学習行う。学習率などその他のパラメタはすべてのモデルで同じものを使う。
モデルのサイズは100Mとなるように調整。(モデル3のみ追加の層があるので120M)
学習はPaperspace Gradientを使う
lossと学習時間の結果
lossとval lossの比較
2epoch学習させた最終的なlossとval lossを表にまとめる
| model | loss | val loss |
|---|---|---|
| ベースモデル | 4.0861 | 4.8150 |
| 非線形活性化関数+bias | 4.2262 | 4.6753 |
| query, key, valueの生成を分ける | 4.8802 | 4.7191 |
| query*keyにscaleを追加 | 4.9979 | 4.7278 |
ベースモデルについて、他のモデルと比べlossは一番低いが、val lossは高くなっており、過学習の可能性がある。val lossについては、非線形活性化関数+biasが一番低く、query, key, valueの生成を分けるとquery*keyにscaleを追加 は近い値となった。
今回のモデルサイズとデータセット的にベースモデルより少し複雑なモデルのほうが適していそう。 ただし、query, key, valueの生成を分けるやquery*keyにscaleを追加ほどの複雑さは不要かもしれない
学習にかかった時間
| model | 学習にかかった時間 (h) |
|---|---|
| ベースモデル | 13.6 |
| 非線形活性化関数+bias | 13.3 |
| query, key, valueの生成を分ける | 12.2 |
| query*keyにscaleを追加 | 14.6 |
ベースモデルと非線形活性化関数+biasは同じくらいの学習時間であり、非線形の計算やbiasは大きなコストではないことがわかる。query, key, valueの生成を分けるはベースモデルより学習時間は短くなっている。これは、query, key, valueの計算が効率的に行われた可能性がある。query*keyにscaleを追加ではparameterが増えている分、より多くの時間が必要となったと考えられる。
まとめると、複雑過ぎるモデルでは学習時間が長くなりlossやval lossにおいても良い結果とはならなかった。一方で、非線形活性化関数+biasやquery, key, valueの生成を分けるではlossや学習時間の面でベースモデルよりよい結果となった。ある程度の複雑性は必要だが、そのバランスは注意する必要がある。
生成された文章での比較
「彼女が子供の頃に住んでいた、海の見える小さな町は、」を与えて続く文章を生成する。
ベースモデル
彼女が子供の頃に住んでいた、海の見える小さな町は、その町と隣接し、町は、町が広がる場所にある。
非線形活性化+bias
彼女が子供の頃に住んでいた、海の見える小さな町は、その街の風景を描いた。そしてこの村には「おとな」という名前が残っている
query, key, valueの生成を分ける
彼女が子供の頃に住んでいた、海の見える小さな町は、この村には「山」と呼ばれている。また北部に位置する島として知られる
query*keyにscaleを追加
彼女が子供の頃に住んでいた、海の見える小さな町は、その地形が広がる。この山には「水」の由来がある。
ベースモデルでは、「町」の繰り返しが発生している。非線形活性化+biasでは「おとな」などの追加情報が含まれるようになっている。
query, key, valueの生成を分けるやquery*keyにscaleを追加では「山」や「水」などの新たな単語が追加され、地形の要素など文脈を考慮した文章が生成されている。
ベースモデルではシンプルな文章が生成されたのに対し、query, key, valueの生成を分けるやquery*keyにscaleを追加では創造的なものや文脈を考慮するような文章が生成されている。
ヒートマップ
queryとkeyの積を計算し、scaleを行い、softmaxを取った結果をヒートマップとして表示する。
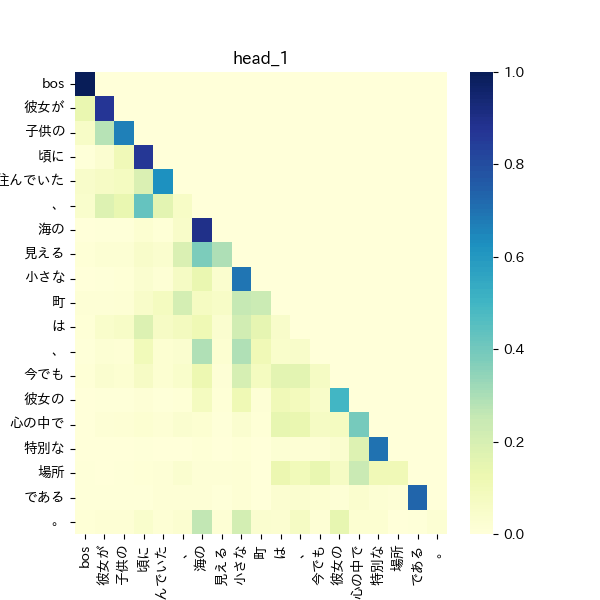
ベースモデル
縦軸がquery、横軸がkeyを表す。値が大きいほど青色が強く表される。
右上の三角形の値が0となっており、これはcausal modelとして先の単語を使って予測しないようなmaskが適応されていることを表す。query「彼女が」に対して、key「彼女が」では高い値となっており、これは自己注意が行われていることを表す。自己注意の高さは文章中でその単語が重要であることを表している。
ベースモデルのヒートマップをみると、文章の前半(queryの前半)部分で自己注意が高くなっている。ただし、中盤では値は小さくなっており文全体は捉えきれてない可能性がある。
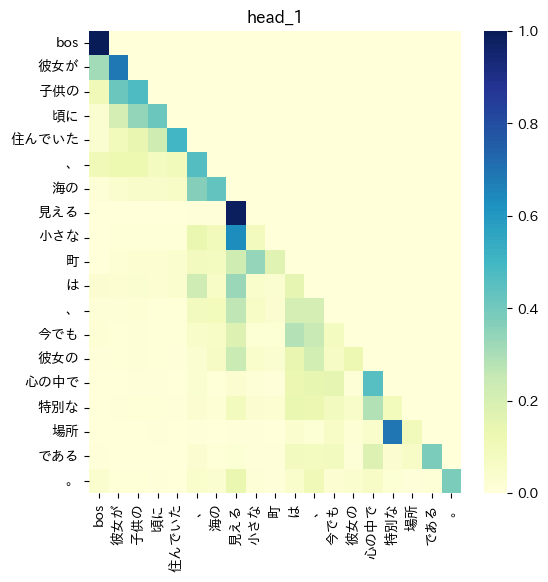
非線形活性化+bias
文章の前半部分で自己注意が高くなっており、後半は値は小さくなっている。また、いずれのqueryに対してもkey「、」の値が高くなるような縦のラインのパターンが見える。これは 「、」の文章の区切りを捉え、さらに文章の前半部分で値が高くなっていることから、文章の前半部分が重要であると捉えている可能性がある。
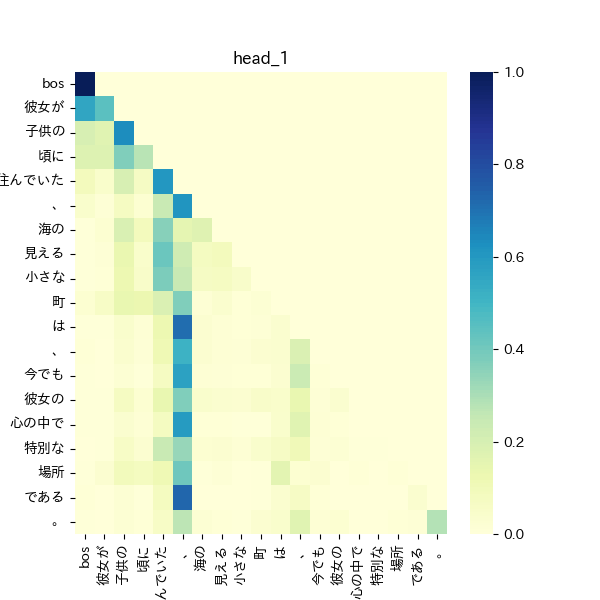
query, key, valueの生成を分ける
自己注意は全体的に少ないが「彼女が」、「子供の」、「海の」などいくつかの単語では自己中が高くなっており、文章中でこれらの単語が重要なものであると捉えている。また、多くのqueryで、key「子供の」やkey「海の」が値が高くなっており、文脈における重要な単語として捉えている可能性がある。文章後半のquery「彼女の」に対し、中盤部分のkey「海の」の値がわずかに高く、後半部分でも前半の内容を考慮しようとしている。
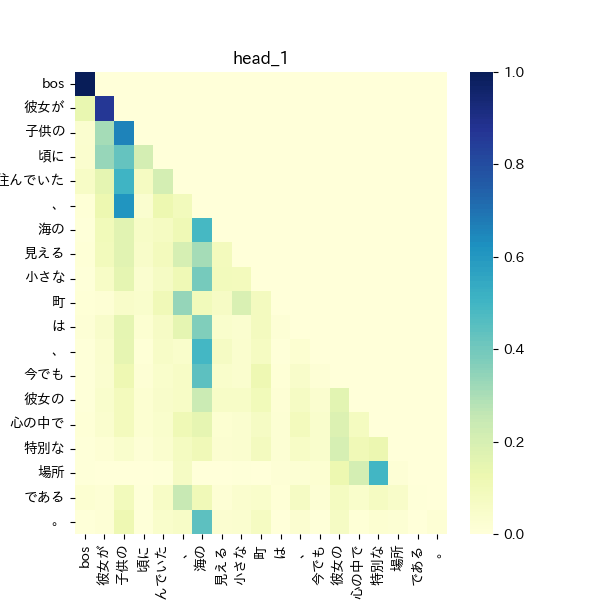
query*keyにscaleを追加
全体的に値が高く、自己注意も全体にわたり、文章全体を捉えようとしている可能性がある。
また「彼女が」や「海の」などのいくつかの単語に対しては自己注意が高くなっており、文脈において重要な単語についても関心を示している。一方で、文章の後半にある単語では、文章の前半部分に注意を行っておらず、長い文章は得意でない可能性がある。
まとめると、非線形活性化+biasでは文章の前半部分に強く注意を行い、query, key, valueの生成を分けるでは特定の単語に高い注意を行っている。
query*keyにscaleを追加では全体的な文章や特定の単語への注意を行っており、文章の意味理解としては優秀かもしれない
まとめと所感
非線形活性化関数+biasはモデルの複雑性は他のモデルと比べ低いものの、ベースモデルに比べ単純な変更で一般化性能を向上させた。文章中の重要な単語への注意は行えていたものの、文脈を考慮した文章の生成などは難しかった。
query, key, valueの生成を分けるモデルでは、文章に対して広範囲に注意を向けており、重要な単語の抽出も行えていた。
query*keyにscaleを追加するモデルでは文脈を捉え、重要な単語へ注意を向けており、その他のモデルに比べ優秀な文章理解が行えていた。一方で、学習時間が増え、lossやval lossは低い値とならなかったため、さらなる調整が必要である。
シンプルなモデルでは、文脈理解が難しかったものの、複雑にしたモデルでは文章全体や単語に対する注意など注意の幅は広がっていた。一方で複雑過ぎるモデルでは、学習時間の増加やlossやval lossは大きくなっており複雑性のバランスは必要である。
小さいモデルを前提とすると学習時間の増加はあまり大きな問題ではなく、query, key, valueの生成を分けるモデルやquery*keyにscaleを追加するモデルのバランスを調整して更に比較を行ってみたい
Discussion