先日、友人から「AIってどうやって質問した内容を理解しているの?」と聞かれて答えられずに固まってしまいました。AIに詳しくない相手にどう説明したらよいのやら。昔に読んだ論文Attention Is All You Needの内容を思い出しつつ、まず質問として入ってきた文章をトークンに分けて、ベクトル化して…と言って伝わるわけがない。そもそもちゃんと理解していないから、簡素化して説明できないのではと思い、もう一度読み返してどんな説明をしたらよいのか考えてみました。
1. AIに文章を読ませる前準備
1-1. 文章を細かく区切る(トークン化)
AIは、いきなり長い文章をドーンと渡されても、一気に理解することはできないので、まず「私は|昨日|学校で|友達と|勉強した」のように、文章を単語やそのかけらごとに区切って、「読みやすい一口サイズ」にしていきます。
「よし、まずは文章をバラして、一個ずつちゃんと向き合おう」という、真面目な下準備の段階です。
1-2. 「文字」を「意味つきの数字」にする(埋め込みベクトル)
区切っただけでは、まだ文字の状態でAIからすると何を意味しているのか理解できません。そもそもAIと言っても実態はコンピュータなので、数字でないとなんの処理もできないです。そこで、「私は」「学校」などのトークンひとつひとつに、意味や使われ方をぎゅっと詰め込んだ長い数字の並び(ベクトル)を割り当て、「この数字パターンのやつは、こんな意味のグループだな」と自分なりの感覚を作っていきます。
似た意味のものほど数字パターンも似てくるので、AIの頭の中では「この2つはちょっと雰囲気似てるな」と、関係図の下書きができ始めます。
3次元空間にベクトルで表すとこんな感じ。

図に表すと、意味の近いものはベクトルの向きも近くなるよう設定されます。こうして文章からばらされた文字が意味付きの数字「単語ベクトル」に変換されます。
1-3. 単語の順番情報を与える(ポジショナルエンコーディング)
ところがAIには、放っておくと「順番」を忘れてしまう弱点があります。
「私は昨日学校で友達と勉強した」と「昨日友達と私は学校で勉強した」を、そのままだとほぼ同じものに見てしまうのです。
そこで、「君は1番目」「君は3番目」のような位置情報を、1-2で作った単語ベクトルの並びに足し込んでいきます。
AIは「同じ『友達』って単語でも、前に出てくるときと後ろに出てくるときで役割が違うんだな」と、順番も含めて意味を理解しようと考えているわけです。
ここまでで前準備完了です。
1-4. 前準備のまとめ
まず、入力文章を単語レベルに区切って、それぞれをコンピュータが理解できるよう数字に置き換えて、あとは文章中の順番情報を付け加えます。出来上がったのは、順番情報をもった意味付きの数字の集まりであるベクトルです。各トークンごとに存在します。
2. AIが文脈を理解する手順
2-1. みんなに「ねえ、君とどれくらい関係ある?」と聞き回る(QとKの内積)
ここからがAIの本番、「関係性チェックタイム」です。
前準備で出来上がったベクトルから、一つのベクトル「Query(Q)」とそれ以外のすべてのベクトル「Key(K)」を用意し、QueryがすべてのKeyに向かって片っ端から「あなたとはどれくらい関係ありそう?」と質問していきます。
このとき、QueryもKeyもベクトルですので、ベクトル同士の掛け算である“内積”を使って関係性をスコア化することができます。
結局のところは、1-2の図のようにベクトルの方向が近い者同士は内積を計算すると大きな値になるので意味が近いもの同士に高い点がつくことになります。
AIは、この計算結果を見ながら「この単語には強く注目すべきだな」「これは今回そんなに関係なさそうだな」と、 関連度スコアのリストを作っていきます。

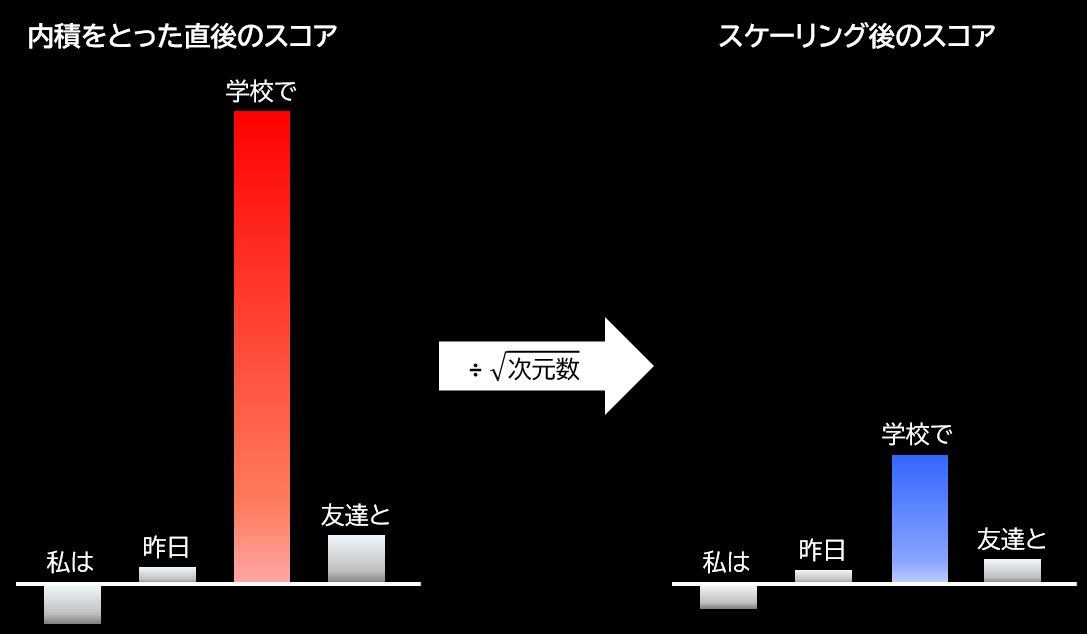
2-2. 興奮しすぎたスコアを落ち着かせる(スケーリング)
ところが、この関連度スコアは、ベクトルの中にある数字の数「次元数」が大きいとものすごく大きな数値になってしまうことがあります。これが起きると、他にある程度大きなスコアのものがいくらかあっても、ものすごく大きなスコアが一つあるだけで、他のものは相対的にほぼ0とみなしてもよいようなサイズ感になり、まるで一つだけ超興奮状態に見えてしまいます。
2-1の図で言うならば、「勉強した」×「学校で」は関連性が高い単語ベクトル同士なのでスコアが非常に高くなりすぎて、「勉強した」×「友達と」がそれなりに高いスコアだったとしても、相対的に見れば、他の低いスコアと大差がない状態になります。
こんな大きく偏った状態を避けるために、AIは冷静に「次元数の多さの目安となる数字(次元数の平方根)」でスコアを割って、みんなを同じ土俵に整えます。
「ちょっとみんな、一回深呼吸しようか」と、興奮気味の数字にクールダウンをかけて、後続の処理がちゃんと働くように気を配っているイメージです。
2-3. 「誰をどれだけ見るか」をきちんと配分する(ソフトマックス)
スコアも落ち着いたところで、AIは「ソフトマックス」という関数を使って、それぞれの単語にどれだけ注目するかを決めます。
バラバラだった関連度スコアを、「この単語にはこれくらいの割合で集中しよう」という“注目度の確率分布”(合計100%になる重み)に変換するのです。
AIの頭の中では、「この単語は重要だから視線多め」「これは少し気にする程度」「これは今回はほぼスルーでOK」という内心会議が開かれていて、その結果がこの注目度として数字になって表れています。

ここで行っていることは、文章内において重要な部分は確率値として大きくし、そうでないものは小さくし、文章内における言葉に強弱をつけていることです。
人間が文脈を理解するときは、与えられた文章の中からキーワードとなる単語を拾って文章全体の意味を捉えていることに近いと思います。
2-4. AIが文脈を理解する手順のまとめ
Attentionでやることは、注目する単語とそれ以外のすべての単語との関係性を数値化し、大きくなりすぎることもあるので全体のサイズ感をそろえ、そこから文脈を理解するうえでどの単語が重要かを数字の大小で出しています。
3. 全体のまとめ
まず、前準備として、文章を単語レベルに区切ったら数字にして文章内における順番も覚えさせておきます。
そのあと、内積計算によってお互いの関係性を聞き回ってスコア化し、スコアが大きすぎるものの対策としてスケーリングすることで全体のサイズ感を合わせ、最後に文章内における重要度を確率値によって配分します。
4. 友人に何と答えるか
友人はAIについてまったく詳しくないので、そんな相手に答えるならこんな感じかなと思います。
「AIは、まず質問の文章を単語レベルに細かく区切って、それぞれを数字に変えて、『この言葉はこの言葉と仲がいい・あまり関係ない』みたいな関係を全部計算してるんだよ。その関係をもとに、文章内においてどの単語が重要なのかを判断して文章としての概要をとらえているね。」
5. 最後に
理解できていても相手に説明するには、より深いところまで理解しておかないと、簡略化したり比喩表現を使ったりはできないなとつくづく思いました。
6. ちょっとだけエンジニアの方向けに
今回は、難しい計算式や、計算途中で行う細かいチューニングについては省略しましたので、Attention Is All You Needを読んだ方は、説明が不十分と感じられる方もいらっしゃるかと思います。
私の簡単な理解ですが、以下のように考えていただければよいかなと思います。
-
前準備: 文章内の各トークンを位置情報も含めたベクトルに変換
- 入力文章をトークン化
- エンベディングしてベクトル化
- ベクトルにポジショナルエンコーディングで文章内の位置情報を追加
-
文脈理解: 前準備でできた各ベクトルからどの単語が重要か確率分布を作る
-
まず、前準備でできた各ベクトルの3つの分身Query(Q)、Key(K)、Value(V)を作る。
前準備でできたベクトルすべての組み合わせ(Query × Key)を内積計算して類似度を見る。
Q*K^T -
極端に内積の値が大きくなってしまうと、あとでソフトマックス関数にかけたときに、一つだけでほぼ1に近い値になってしまい、他の要素がほとんど0になってしまうことがあるので、次元数のルートで割ることで正規化する。
Q*K^T/\sqrt{d_k} -
ソフトマックス関数にかけて確率値にする。
softmax(Q*K^T/\sqrt{d_k}) -
最後に前準備でできた各ベクトル(Value)と内積をとり、どこにAttentionが向けられているかを表現する。
softmax(Q*K^T/\sqrt{d_k})*V
-

Discussion