RustでX68000のラスタースクロールを頑張る
今回は前回の記事[1]でコーディングしたRust版ラスタースクロールをパフォーマンスチューニングします。
トライアンドエラーでパフォーマンスチューニングを進めることで、wasm経由でビルドした実行ファイルの処理能力の限界を探っていきます。
パフォーマンスチューニングの進め方
現在、RustからX68000の実行形式をビルドするのに下記のダイアグラムで示すようにwasmを経由してビルドを行っています[2]。
今回パフォーマンスチューニングを行うにあたっていきなりRustのコードやwasm2cを改修するのではなく、変換後のC言語のソースに手を加えて効果を確認し、効果のあったものをダイアグラムの左側にあるwasm2cに取り入れていくという戦略を取りたいと思います。
パフォーマンスチューニングの鉱脈
今回パフォーマンスチューニングの余地があると目をつけているのは下記の2か所になります。
- IOへのpeek, poke処理
- リニアメモリに対するリトルエンディアンでのアクセス
ラスタースクロールの処理では水平同期信号をポーリングする部分の処理速度を改善する必要があります。前回の実装ではアクセスするたびにpeek関数を呼び出すことになるためこの部分で求められるパフォーマンスが得られない状態となっていました。
リニアメモリに対するアクセスに関してはリトルエンディアンでアクセスする必要がありこれがボトルネックとなっています。wasmはリニアメモリ上にリトルエンディアンでデータを格納する仕様となっておりこれ自体を覆すことは難しいですが、変換処理を工夫してなるべくペナルティの少ない処理を目指していきます。
IOへのpeek, poke処理の改善
まず、peek, pokeの改善に取り掛かります。
これまでは外部関数として定義していた関数を呼び出していましたが、下記のようにvolatileアクセスをインライン埋め込みするコードにしてしまいます。
// uint32_t __wbg_x68kbpeek_a51a25fcf8ed5e80(uint32_t);
static inline uint8_t __wbg_x68kbpeek_a51a25fcf8ed5e80(uint32_t adr) {
return *(volatile uint8_t*)adr;
}
//void __wbg_x68kwpoke_3a423ab8e048655d(uint32_t, uint32_t);
static inline void __wbg_x68kwpoke_3a423ab8e048655d(uint32_t adr, uint16_t value) {
*(volatile uint16_t*)adr = value;
}
いきなりチート感満載の対応ではありますが、水平同期をポーリングするアセンブリコードがどのように変わるのか見ていきたいと思います。
lea ___wbg_x68kbpeek_a51a25fcf8ed5e80,a4 * lea __wbg_x68kbpeek_a51a25fcf8ed5e80,%a4 |, tmp70
_?L225: *.L225:
*| raster.c:4984: l7 = __wbg_x68kbpeek_a51a25fcf8ed5e80(l7);
move.l #15237121,-(sp) * move.l #15237121,-(%sp) |,
jbsr (a4) * jsr (%a4) | tmp70
*| raster.c:4988: if (l7) {
addq.l #4,sp * addq.l #4,%sp |,
tst.b d0 * tst.b %d0 | tmp89
jbpl _?L225 * jpl .L225 |
インライン版では関数呼び出しや引数のスタック操作、戻り値の検査のコードが省略されmove.bとbccだけのコードになっているのがわかります。
_?L224: *.L224:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _45
*| raster.c:5002: if (l7) {
jbpl _?L224 * jpl .L224 |
これで実行してみると下記のようになります。sin波が2周期まで表示されるようになりました。4周期が目標ですが前回に比べるとかなりの前進です。
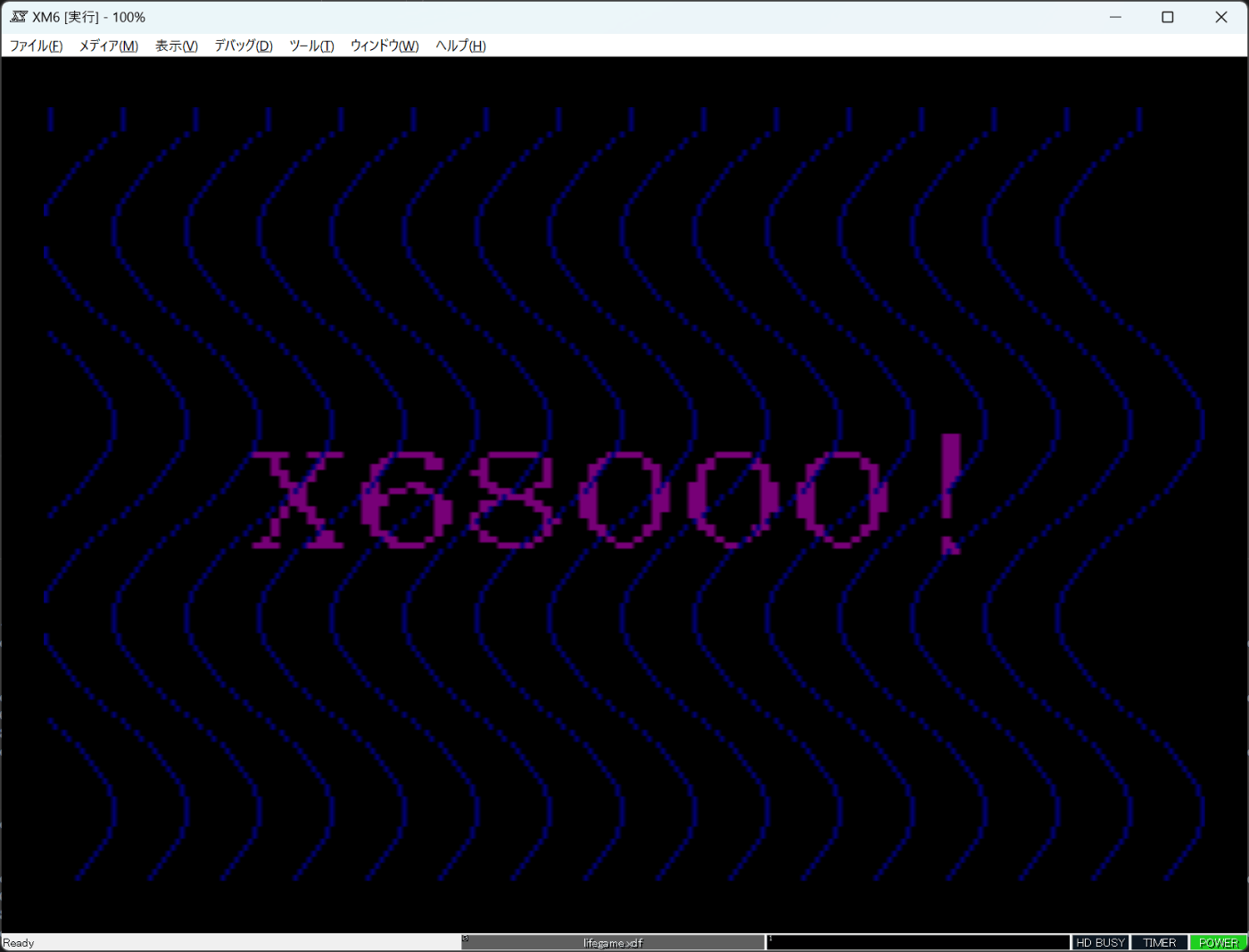
リトルエンディアンアクセスの改善
続いてリニアメモリに対するリトルエンディアンアクセスを改善していきます。
ラスターごとのループの中の処理を改善することが目的となります。
当該箇所のRustのコードはこのようになっています。
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) == 0x00 {
}
x68k_wpoke(X68K_MMIO_CRTC_GRAPH_X0, wave_table[phase]);
y_posizion += 1;
if y_posizion >= 256 { break; }
phase = (phase + 1) & 0x3F;
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) != 0x00 {
}
ビルドするとこの部分は下記のアセンブリコードになります。
_?L224: *.L224:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _45
*| raster.c:5002: if (l7) {
jbpl _?L224 * jpl .L224 |
*| raster.c:5008: if (l10) {
cmp.l d4,d3 * cmp.l %d4,%d3 | l5, l0
jbcc _?L225 * jcc .L225 |
*| raster.c:5013: l15 <<= l16 & 0x1F;
move.l d3,d0 * move.l %d3,%d0 | l0, l15
add.l d3,d0 * add.l %d3,%d0 | l0, l15
*| raster.c:5014: l14 += l15;
add.l d5,d0 * add.l %d5,%d0 | l5, l14
*| raster.c:5015: l16 = load16_align1((const uint16_t *)&m0[l14 + UINT32_C(0)]);
add.l _m0,d0 * add.l m0,%d0 | m0, l14
move.l d0,-(sp) * move.l %d0,-(%sp) | l14,
jbsr (a4) * jsr (%a4) | tmp77
*| raster.c:189: *(volatile uint16_t*)adr = value;
move.w d0,15204376 * move.w %d0,15204376 | _15, MEM[(volatile uint16_t *)15204376B]
*| raster.c:5020: if (l14) {
subq.l #1,a3 * subq.l #1,%a3 |, ivtmp_17
addq.l #4,sp * addq.l #4,%sp |,
cmp.w #0,a3 * cmp.w #0,%a3 |, ivtmp_17
jbeq _?L223 * jeq .L223 |
_?L227: *.L227:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _46
*| raster.c:5031: if (l21) {
jbmi _?L227 * jmi .L227 |
中盤でスクロールレジスタに書き込む値をload16_align1関数をつかってリニアメモリからロードしている部分が見つかります。
この関数を下記のインライン関数に変更してしまいます。元の処理内容は比較のためにコメントで残してあります。
static inline uint16_t load16_align1(const uint16_t *ptr) {
// uint16_t val;
// rmemcpy(&val, ptr, sizeof(val));
// return val;
return __builtin_bswap16(*ptr);
}
load関数やstore関数の名称後半につけられているalignN接尾辞はwasmのload, store命令のalignヒントからつけられています。これはこの命令でアクセスするリニアメモリ上のアドレスが2のN乗にアラインメントされていることを教えてくれています。
つまりalign0の関数は奇数アドレスにアクセスしうることを表しており、逆にalign1以上のアラインメントヒントを持つ関数はwordアラインメントが保証されていることを表しています。m68kではワードアラインメントが保証されているならば直接アクセスしてしまえばよいので上記のようにポインタの指すアドレスから読み出してバイトスワップを行うコードとしています。
変更の前後で生成されるアセンブリコードは下記のように変化します。
*| raster.c:5015: l16 = load16_align1((const uint16_t *)&m0[l14 + UINT32_C(0)]);
add.l _m0,d0 * add.l m0,%d0 | m0, l14
move.l d0,-(sp) * move.l %d0,-(%sp) | l14,
jbsr (a4) * jsr (%a4) | tmp77
*| raster.c:28: return __builtin_bswap16(*ptr);
moveq #0,d2 * moveq #0,%d2 | MEM[(const uint16_t *)_14]
move.w (a0,a1.l),d2 * move.w (%a0,%a1.l),%d2 | MEM[(const uint16_t *)_14], MEM[(const uint16_t *)_14]
ror.w #8,d2 * ror.w #8,%d2 |, _46
早速実行してみましょう。
あれ?全然効果がないみたいですね。
FnとFnOnce, FnMut
首を傾げていても進展がないのでデバッガをつかって時間のかかっている処理を探していきます。
ステップ実行をしていくとあることに気づきます。
水平同期を検出した後にload関数が何度も呼び出されているようです。
インライン化したのになぜ?
下記に実際に実行されていた部分のアセンブリコードを示します。
_?L214: *.L214:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _39
*| raster.c:5151: if (l7) {
jbpl _?L214 * jpl .L214 |
*| raster.c:5156: l12 = load32_align2((const uint32_t *)&m0[l12 + UINT32_C(8)]);
move.l _m0,d0 * move.l m0,%d0 | m0,
add.l d6,d0 * add.l %d6,%d0 | tmp69,
move.l d0,-(sp) * move.l %d0,-(%sp) |,
jbsr (a3) * jsr (%a3) | tmp82
*| raster.c:5159: if (l11) {
addq.l #4,sp * addq.l #4,%sp |,
cmp.l d3,d0 * cmp.l %d3,%d0 | l0, l12
jbls _?L215 * jls .L215 |
*| raster.c:5162: l15 = load32_align2((const uint32_t *)&m0[l15 + UINT32_C(0)]);
move.l _m0,d0 * move.l m0,%d0 | m0,
add.l d4,d0 * add.l %d4,%d0 | l5,
move.l d0,-(sp) * move.l %d0,-(%sp) |,
jbsr (a3) * jsr (%a3) | tmp82
*| raster.c:28: return __builtin_bswap16(*ptr);
move.l _m0,a1 * move.l m0,%a1 | m0, tmp77
add.l d0,a1 * add.l %d0,%a1 | tmp87, tmp77
*| raster.c:28: return __builtin_bswap16(*ptr);
move.l d3,a0 * move.l %d3,%a0 | l0, l16
add.l d3,a0 * add.l %d3,%a0 | l0, l16
moveq #0,d0 * moveq #0,%d0 | MEM[(const uint16_t *)_14]
move.w (a1,a0.l),d0 * move.w (%a1,%a0.l),%d0 | MEM[(const uint16_t *)_14], MEM[(const uint16_t *)_14]
ror.w #8,d0 * ror.w #8,%d0 |, _47
*| raster.c:189: *(volatile uint16_t*)adr = value;
move.w d0,15204376 * move.w %d0,15204376 | _47, MEM[(volatile uint16_t *)15204376B]
*| raster.c:5172: if (l15) {
subq.l #1,d5 * subq.l #1,%d5 |, ivtmp_17
addq.l #4,sp * addq.l #4,%sp |,
jbeq _?L221 * jeq .L221 |
_?L216: *.L216:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _48
*| raster.c:5185: if (l19) {
jbmi _?L216 * jmi .L216 |
どうやらほぼ同じことをする処理が2つ生成されているようです。
今回のコードでは割り込み禁止期間をRustのコードで表すのに下記のように無名関数を使っています。
x68k_disable_intrupt(&mut ||{
let mut y_posizion = 0;
let mut phase = offset;
loop {
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) == 0x00 {
}
無名関数はクロージャとして扱われます。
この処理でx68k_disable_intruptに渡される無名関数はFnトレイトを実装したクロージャとして関数に渡されます。Fnトレイトのcall関数の実装は無名関数内の処理が反映されます。
Fnトレイトの定義はFnMutやFnOnceを継承する関係となっています。このため無名関数の処理がこれらのトレイトの実装としてもwasm内に生成されているようです。
先ほどload16_align1関数のインライン化により改善できたと思っていた関数はこれらFnOnceなどのトレイトの実装なのだと思われます。
実際に実行されている関数内ではload32_align2が使われているようなのでこちらも下記のようにインライン化してしまします。
static uint32_t load32_align2(const uint32_t *ptr) {
// uint32_t val;
// rmemcpy(&val, ptr, sizeof(val));
// return val;
return __builtin_bswap32(*ptr);
}
変更後の該当箇所のアセンブリコードは下記のようになります。
バイトスワップのコードがなかなか存在感のあるコードとなっていますがこれまでに比べれば改善見込めそうです。
*| raster.c:44: return __builtin_bswap32(*ptr);
move.l 8(a0,d2.l),d1 * move.l 8(%a0,%d2.l),%d1 | MEM[(const uint32_t *)_10], _37
ror.w #8,d1 * ror.w #8,%d1 |, _37
swap d1 * swap %d1 | _37
ror.w #8,d1 * ror.w #8,%d1 |, _37
実行してみましょう。
4周期出るようになりました。
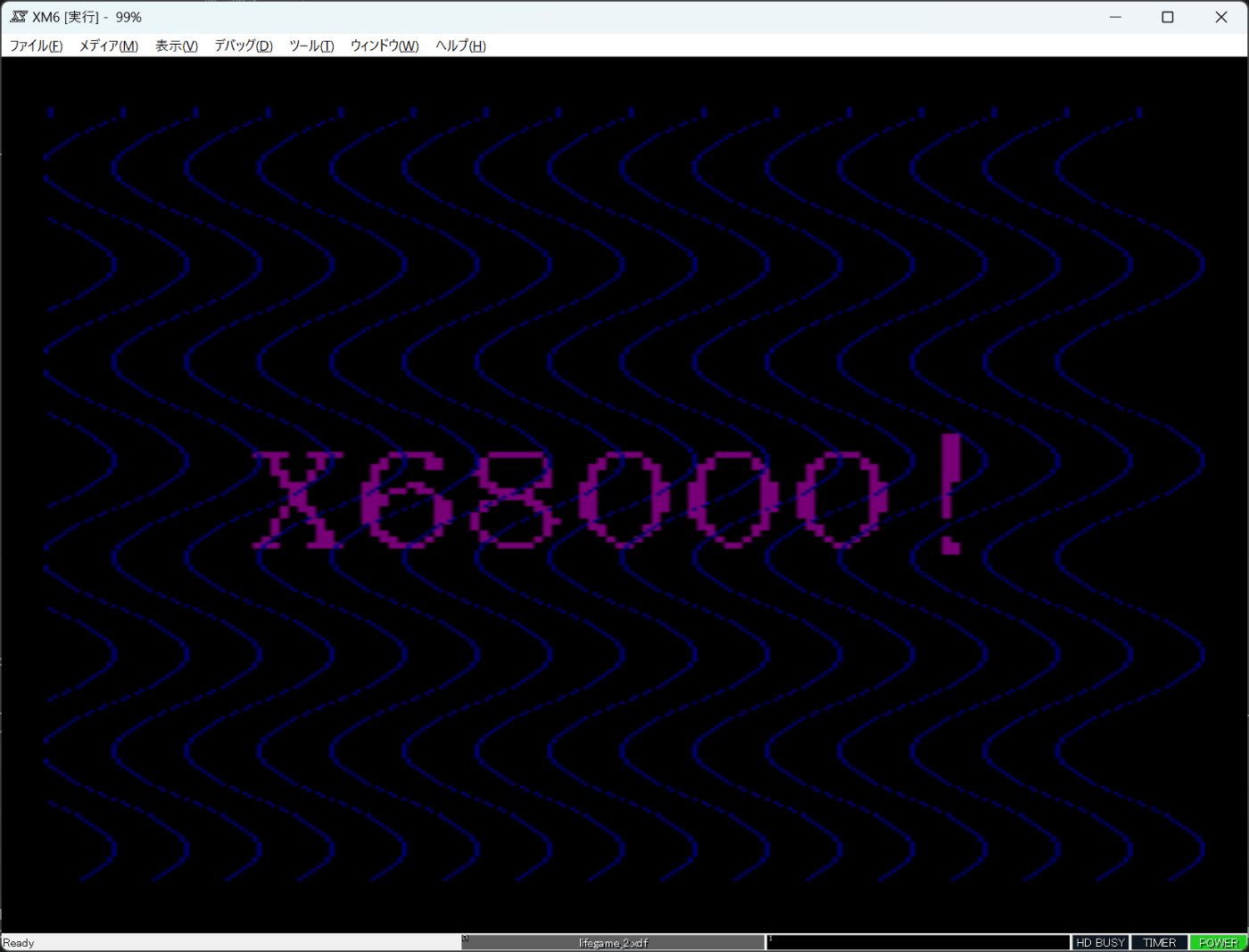
4周期出るようにはなったもののよく見ると先頭の数ラスターはスクロールできていないですね。
割り込み禁止区間の改善
状況的に垂直帰線の終了検出後に割り込み禁止区間に入るところでもたついて数ラスター取り逃しているようです。
これまで割り込みを禁止にして無名関数をコールバックする関数はC言語の外部関数として実装していました。しかし、このやり方ではこれ以上の最適化望めなさそうなので、無名関数のコールバック自体をRustで実装してRustコンパイラに最適化してもらう戦略をとりたいと思います。
x68k_disable_intruptを下記のようにRust側で実装します。
fn x68k_disable_intrupt(f: &dyn Fn()) {
x68k_disable_interrupt();
f();
x68k_enable_interrupt();
}
割り込みの禁止、許可自体はC言語のインラインアセンブラで実装します。
// void __wbg_x68kdisableinterrupt_df22111bc28c2e8a(void);
static inline void __wbg_x68kdisableinterrupt_df22111bc28c2e8a(void) {
asm volatile(
"ori.w #$0700, sr\n"
);
}
// void __wbg_x68kenableinterrupt_97c45efdb434642c(void);
static inline void __wbg_x68kenableinterrupt_97c45efdb434642c(void) {
asm volatile(
"andi.w #$f8ff, sr\n"
);
}
この変更を加えると割り込み禁止から水平同期のポーリング開始までのアセンブリコードは下記のようなコードが生成されるようになりました。
良さそうですね。
* APP ON (APP) asm_mode=has *#APP
*| 190 "raster.c" 1
ori.w #$0700,sr * ori.w #$0700, sr
*
*| 0 "" 2
*| raster.c:5021: l17 = load32_align2((const uint32_t *)&m0[l17 + UINT32_C(8)]);
* APP OFF (NO_APP) asm_mode=gas *#NO_APP
move.l _m0,a2 * move.l m0,%a2 | m0, m0.851_3
*| raster.c:5021: l17 = load32_align2((const uint32_t *)&m0[l17 + UINT32_C(8)]);
lea (a2,d2.l),a3 * lea (%a2,%d2.l),%a3 | m0.851_3, tmp97, _5
*| raster.c:5027: l20 = load32_align2((const uint32_t *)&m0[l20 + UINT32_C(0)]);
lea (a2,d1.l),a4 * lea (%a2,%d1.l),%a4 | m0.851_3, _72, _7
*| raster.c:5009: goto l12;
move.w #256,a0 * move.w #256,%a0 |, ivtmp_40
*| raster.c:5006: l0 = l8;
moveq #0,d3 * moveq #0,%d3 | l0
_?L205: *.L205:
*| raster.c:180: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _79
*| raster.c:5016: if (l13) {
jbpl _?L205 * jpl .L205 |
実行してみます。
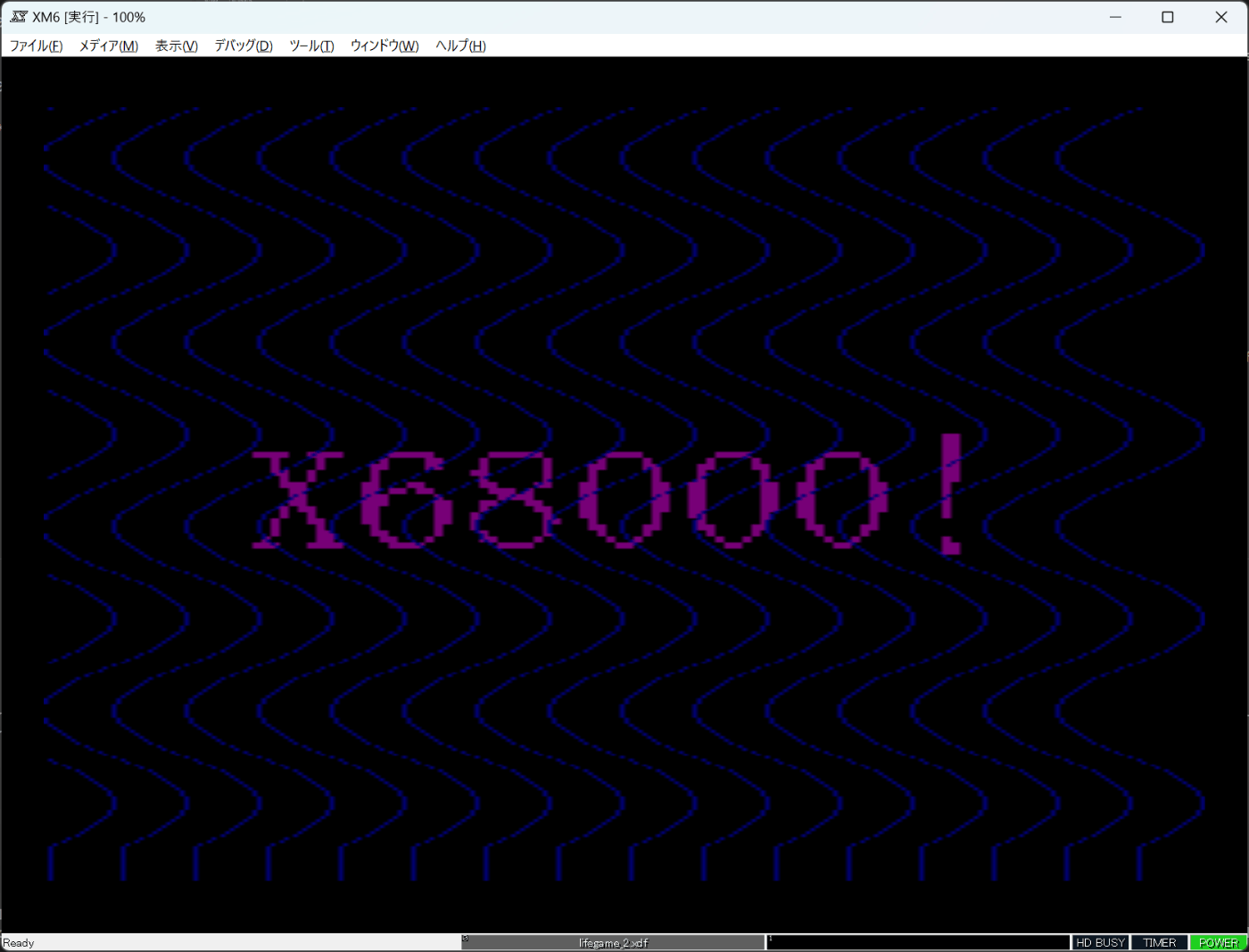
先頭部分の問題は解決されましたが、4周期出した後の謎区間が登場しましたね。
256ライン表示での水平同期回数
実は256ライン表示でも高解像度モードでは水平同期は1画面当たり512回発生しています。
これまでは中の処理が遅いことをいいことにスクロールレジスタを変更するたびに1回しか水平同期をとっていませんでした。本来は水平同期2回ごとにスクロールレジスタ1回変更があるべき処理となります。
先ほどの画面下部のスクロールしない区間は、ある程度パフォーマンスが出てきたことにより露呈してきた区間ということになります。
とはいえもう少し処理速度を上げないと本来の処理にはならなそうです。
ここからはRustの処理を改善していく必要があります。
最終的なRustコードは下記のようになりました[3]。
mod utils;
use core::f32::consts::PI;
use wasm_bindgen::prelude::*;
const X68K_MMIO_CRTC_GRAPH_X0: u32 = 0xE80018;
const X68K_MMIO_GPIP: u32 = 0xE88001;
const X68K_MMIO_GPIP_BIT_HSYNC: u8 = 0x80;
const X68K_MMIO_GPIP_BIT_VDISP: u8 = 0x10;
#[wasm_bindgen]
extern "C" {
fn x68k_sv(f: &dyn Fn());
fn x68k_sv_mut(f: &mut dyn FnMut());
fn x68k_disable_interrupt();
fn x68k_enable_interrupt();
fn x68k_bpoke(address:u32, value: u8);
fn x68k_wpoke(address:u32, value: u16);
fn x68k_lpoke(address:u32, value: u32);
fn x68k_bpeek(address:u32) -> u8;
fn x68k_wpeek(address:u32) -> u16;
fn x68k_lpeek(address:u32) -> u32;
fn puts(s: &str);
}
fn x68k_disable_intrupt(f: &dyn Fn()) {
x68k_disable_interrupt();
f();
x68k_enable_interrupt();
}
fn build_sin_table() -> Vec<u8> {
let mut sin_table = Vec::new();
for i in 0..64 {
unsafe {
sin_table.push((16.0 + 16.0 * ((i as f32) / 32.0 * PI).sin()).round().to_int_unchecked());
}
}
for _i in 0..4 {
for j in 0..64 {
sin_table.push(sin_table[j]);
}
}
sin_table
}
#[wasm_bindgen]
pub fn main() {
let wave_table = build_sin_table();
x68k_sv(&||{
let mut offset: u16 = 0;
loop {
let wave_table_slice = &wave_table[(offset as usize)..(offset+256) as usize];
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_VDISP) != 0x00 {
}
x68k_disable_intrupt(&||{
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_VDISP) == 0x00 {
}
for x_posizion in wave_table_slice.iter() {
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) == 0x00 {
}
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) != 0x00 {
}
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) == 0x00 {
}
x68k_wpoke(X68K_MMIO_CRTC_GRAPH_X0, *x_posizion as u16);
while (x68k_bpeek(X68K_MMIO_GPIP) & X68K_MMIO_GPIP_BIT_HSYNC) != 0x00 {
}
}
});
// offset = (offset + 1) & 0x3F;
}
});
}
これで実行するとある程度安定して4周期出るようになりました。

しかし表示しているとジッタがあります。水平同期を取りこぼすことがまれにあるようです。
水平同期の取りこぼし対策
現在水平同期のポーリング処理は32ビット絶対アドレッシングのmove.b命令とbcc命令の組み合わせとなっています。
_?L224: *.L224:
*| raster.c:184: return *(volatile uint8_t*)adr;
move.b 15237121,d0 * move.b 15237121,%d0 | MEM[(volatile uint8_t *)15237121B], _45
*| raster.c:5002: if (l7) {
jbpl _?L224 * jpl .L224 |
一方で参考としたMicroPythonのサンプルコード[4]ではこのループは下記のようにアドレスレジスタ間接のmove.b命令とbcc命令の組み合わせになっています。
# wait for HSYNC
label(loop3)
moveb([a1],d1)
bpls(loop3)
M68000のマニュアル[5]を見ると32ビット絶対アドレッシングのmove.bが16クロック、bcc命令での分岐が10クロックかかるようなので、現状のループは26クロックでポーリングするようになっています。これがアドレスレジスタ間接のmove.bだと8クロックで実行できるのでMicroPythonのサンプルでは18クロックでポーリングできることになります。
何とかアドレスレジスタ間接アドレッシングモードを使いたいのでpeek関数を下記のように書き換えました。変数adrをアドレスレジスタ制約で渡すために"a"制約を指定しています[6]。
static inline uint8_t __wbg_x68kbpeek_a51a25fcf8ed5e80(uint32_t adr) {
uint8_t output;
asm volatile(
"move.b (%1), %0\n"
:"=r"(output):"a"(adr)
:
);
return output;
}
結果として出力されるアセンブリコードは下記のようになりました。
アドレスレジスタ間接になりましたがtst.b命令が追加されてしまいましたね。
この命令は4クロックなので結果ループは22クロックでポーリングできるようになりました。(ノーウェイトの前提のクロック数となります)
_?L11: *.L11:
* APP ON (APP) asm_mode=has *#APP
*| 204 "raster.c" 1
move.b (a1),d2 * move.b (%a1), %d2 | tmp63, output
*
*| 0 "" 2
*| raster.c:5117: if (l11) {
* APP OFF (NO_APP) asm_mode=gas *#NO_APP
tst.b d2 * tst.b %d2 | output
jbge _?L11 * jge .L11 |
4クロックの削減ですが、XM6で確認する限りではジッタがなくなりました。
なお、X68000Zでも4周期のラスタースクロールになることが確認できましたが、残念ながら現状定期的に表示が破綻してしまうようです。この原因については解析できていません。
wasm2cの改修
ここまでの内容をwasm2cで変換するときに出力されるC言語のソースに反映されるように改修を行いました。下記のコミットが改修内容となります。
まとめ
今回は前回用意したラスタースクロールのコードのパフォーマンスチューニングに挑戦しました。
結果としてある程度納得できるスピードにできたのではないかと思います。
IOアクセスのインライン化とリニアメモリアクセスの改善についてはwasm2cへの反映も行っています。今回と同じ方法でIOアクセスする場合はこの記事での対応が入った状態のコードが生成されます。
次回予告
次回はIOCSコールとDOSコールをできるようにしてRustからできることを増やしていきたいと思います
-
3分間クッキング方式 ↩︎
Discussion