【ベクトル検索】ベクトル検索の精度改善を検証してみた
初めに
OpenAIのEmbeddingsで誰でも簡単に単語や文章をベクトル化することが可能になり、ベクトル検索が手軽になったことで注目度が高まっているように思われます。Azure Cognitive Searchでもベクトル検索と従来の検索をハイブリットさせて検索する技術が使えるようになり話題になっています。
今回の記事では、LangChainを使ったベクトル検索方法と、その上で検索の精度を向上させる策の紹介、また実際のデータを使った検証結果について紹介します。
対象とする読者
- ベクトル検索に興味ある人
- ベクトル検索の精度を向上させたい人
- タイトルで気になった人
そもそもベクトル検索って何?
ベクトル検索は機械学習(ML)を活用して、テキストから意味とコンテキストを取り込み、数値表現に変換し、近似近傍アルゴリズムを使用して類似データを検索する手法のことです。
セマンティック検索との違いと位置付け
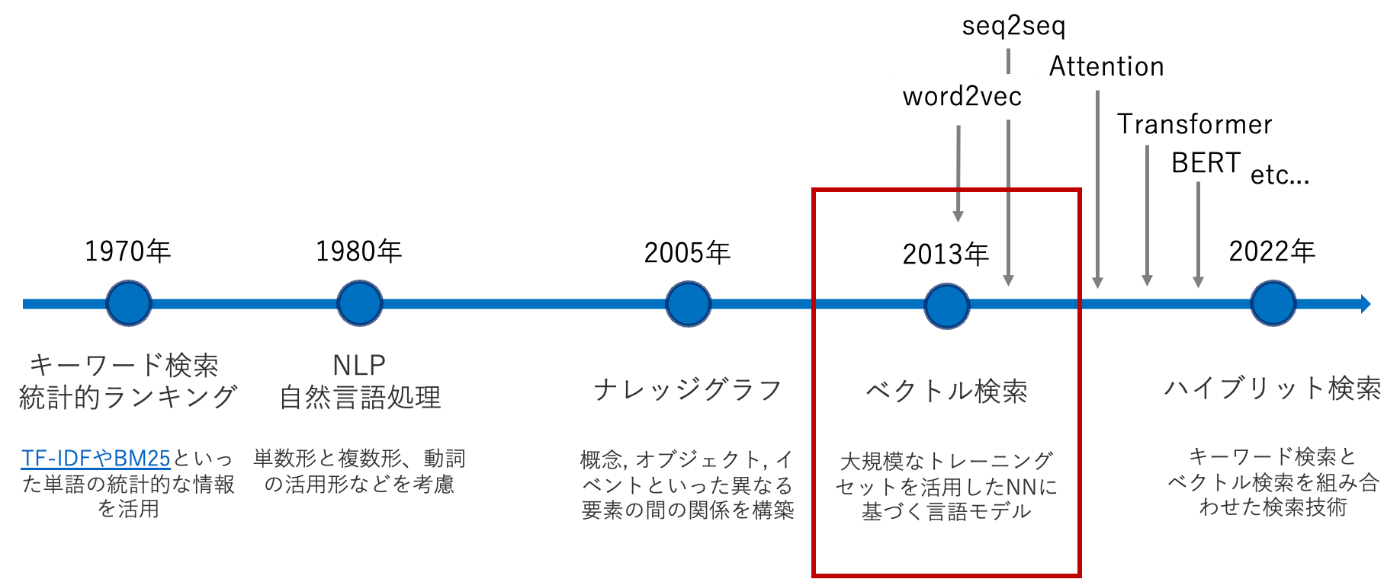
セマンティック検索という言葉も同じ文脈でよく出てきますが、これは検索エンジンが検索文の意味を理解しその意味(=semantic)に沿った検索結果を提供する技術の総称のことです。その歴史は1970年まで遡り、初めは統計学的な情報を扱って検索するTF-IDFなどが主流でした。そこからだんだんとNLPや言語モデルが発展し、2013年ごろのword2vecが出た頃にベクトル検索という技術が生まれました。
Embeddingとの違い
同じ文脈で Embedding(埋め込み) という単語もよく出現します。こちらは自然言語を計算が可能な形(=ベクトル)に変換することを意味しており、やっていることは結局ベクトル化とは全く変わりません。意図を持ってベクトルに変換することをEmbeddingというと考えて問題ないと思います。
ベクトル検索の流れ
ベクトル検索の実装には2つの登場人物が必要になります。一つはテキストなどをEmbeddingするモデル、もう一つはEmbeddingしたものを登録したり、類似度を計算しベクトル検索を実現するベクトルストアです。またその2つを使って自力で実装するのもできますが、LangChainというLLMフレームワークを使うと2つを非常にうまくつなげることができ、楽に実装できます。
EmbeddingモデルはWord2vecやfastTextなどさまざまありますが、OpenAIのEmbeddingsを使うのが近年では一般的でしょう。(Azure OpenAIでも同じです)
またベクトルストアは、有名どころだとChromadb、Faiss、pgvector、Qdrantなどがあります。それぞれメリットでメリットがありますが、軽量かつ高機能で使えるのはQdrantかなと思います。
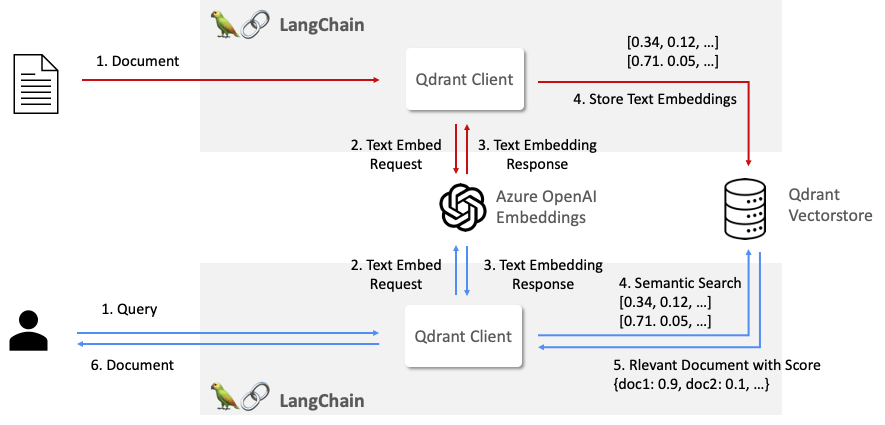
LangChainを使ったベクトル検索の実装
まずはベクトルストアの本体であるQdrantをたてます。dockerを使えば簡単にできるのでお手軽ですね。
version: '3'
services:
qdrant:
container_name: qdrantdb
image: qdrant/qdrant
ports:
- '6333:6333'
- '6334:6334'
適当な文章をEmbeddingして、Qdrantに登録します。今回は桃太郎の一節を入れています。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Qdrant
from langchain.docstore.document import Document
# Embeddingモデルの用意
embeddings = OpenAIEmbeddings(
openai_api_key="YOUR_API_KEY",
openai_api_base="https://xxxxxxxxxxxxxxxxx",
model="gpt-4",
chunk_size=1
)
# ドキュメントの用意
docs = [
Document(page_content="むかし、むかし、あるところに、おじいさんとおばあさんがありました。まいにち、おじいさんは山へしば刈かりに、おばあさんは川へ洗濯せんたくに行きました。"),
Document(page_content="ある日、おばあさんが、川のそばで、せっせと洗濯せんたくをしていますと、川上かわかみから、大きな桃ももが一つ、「ドンブラコッコ、スッコッコ。ドンブラコッコ、スッコッコ。」と流ながれて来きました。")
]
# Qdrantに保存
qdrant = Qdrant.from_documents(
docs=docs,
embedding=embeddings,
url="http://localhost:6333",
prefer_grpc=True,
collection_name="test",
)
そして、検索をします。
from qdrant_client import QdrantClient
from langchain.vectorstores import Qdrant
# Qdrantに接続
qdrant = Qdrant(
client=QdrantClient(url="http://localhost:6333"),
collection_name="test",
embeddings=embeddings,
)
# 検索文字列
query = 'おじいさん'
top_k = 1
# 検索
result = qdrant.similarity_search_with_score(query=query, k=top_k)
print(result)
>>> [(Document(page_content='むかし、むかし、あるところに、おじいさんとおばあさんがありました。まいにち、おじいさんは山へしば刈かりに、おばあさんは川へ洗濯せんたくに行きました。', metadata={}), 0.8391879)]
「おじいさん」という単語が入っている方の文章が検索できました。
ベクトル検索の精度向上施策
単にベクトル検索するだけでは、欲しい回答が得られない場合が多いです。そこでベクトル検索の精度を向上させる施策を3つ考えました。
1. Queryの前処理を工夫する
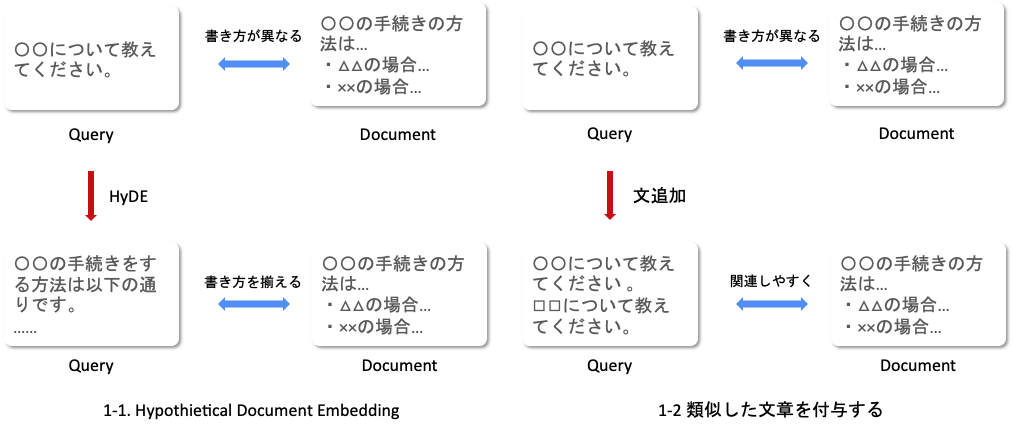
1. QueryのHyDEと類似文付与
1-1のHypothetical Document Embeddingは2023年1月に発表された論文で、仮説的に答えを与えることで検索の精度を上げる方法です。これで与えられた答えと検索対象のそれぞれのベクトルを比較して検索します。
1-2の類似した文章を付与するのは、私が個人で考えたアイデアでqueryの情報を増やして上げることで精度を上げるという狙いです。
queryを工夫する考えは、chatgptのプロンプトエンジニアリングの考えと全く同じです。質問の仕方を改善しないと使うモデルが良くても良い答えが返ってこないことが往々にしてあるので、聞き方(query)を変えてあげようということです。
2. Documentの前処理
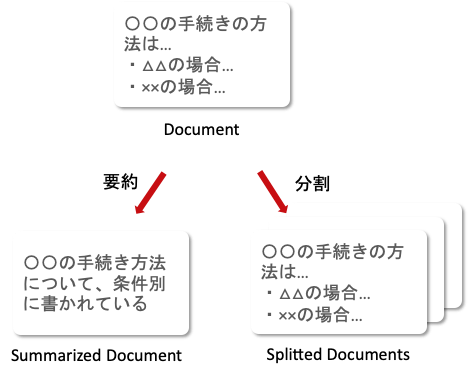
2. Documentの要約と分割
2-1の要約は、Documentを要約することで情報を圧縮し、より重要な内容だけをEmbeddingすることでベクトルを尖らせる狙いです。
2-2の分割は、Documentを分割して情報を削らずに分けてEmbeddingしてベクトルを尖らせる狙いです。
Documentを工夫する考えは、大きな情報量をEmbeddingするとベクトルが全体の意味の平均的なものになってしまうという推測から得たもので、処理を加えることで短くし情報の質を高めます。
3. ハイブリット検索
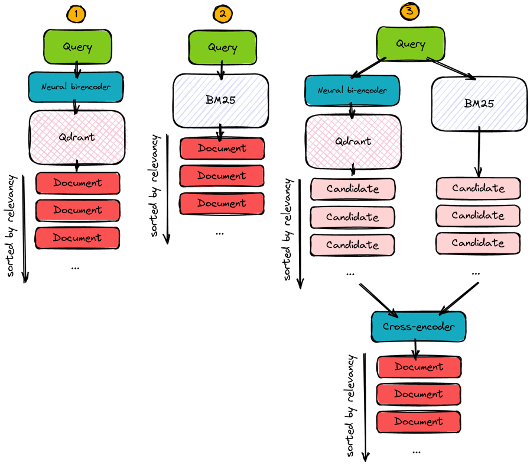
3. ハイブリット検索(Qdrant公式から引用)
ハイブリット検索とは、ベクトル検索だけではなく、従来の手法であるフルテキスト検索と併用し、スコアを合算することで検索精度を向上させようという方法です。
精度検証
ここからは実際に今まで上げた改善策を検証する。使うテストデータとそれらの情報は以下のとおりです。
テストデータ
WANDS
- 電子商取引用の検索エンジンを評価するデータセット
- 製品
- データ数:42,994件

- データ数:42,994件
- Query
- データ数:488件
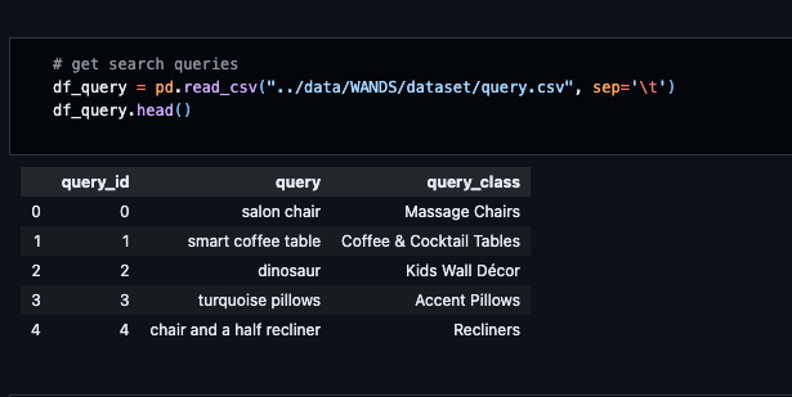
- データ数:488件
- 関連性ラベル
- データ数:233,000件
- 1つのQueryに対して、複数の製品IDが対応
- 関連性は正確、部分的、無関係
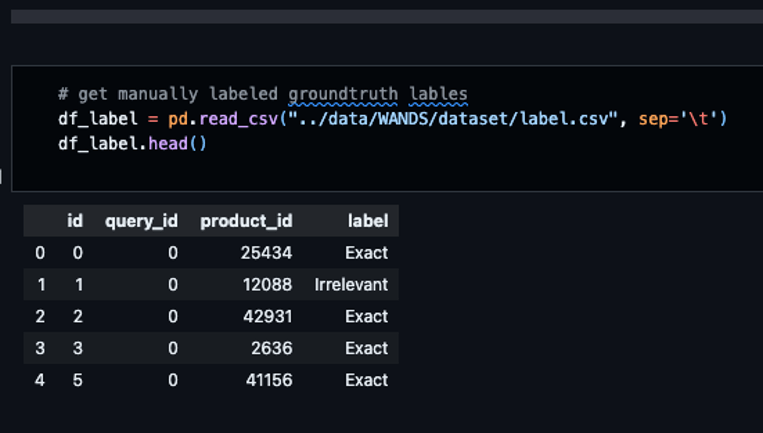
- EDA

評価指標
- 評価指標(値域: [0, 1])
- NDCG (Normalized Documented Cumulative Gain)
- ドキュメント検索タスクにおける評価指標の一つ
- ランキングに割引率を適用して、ランキングの適合率をスコアにしたもの
- MRR (Mean Reciprocal Rank)
- ひとつの検索結果において、最初に見つかった適合文書のランクの逆数をスコアとする
- MAP (mean Average Precision)
- 適合率(precision)の平均値
- NDCG (Normalized Documented Cumulative Gain)
検証結果(施策1: Queryの前処理)
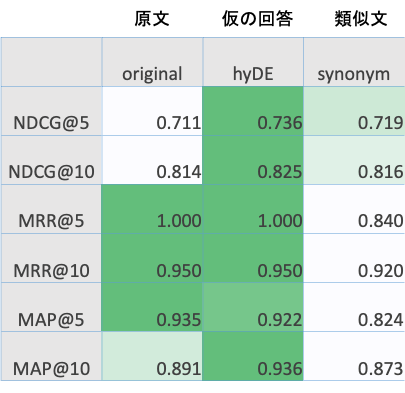
- HyDE > original > synonym の順にスコアが高い
- HyDEが最も高い
→ QueryとDocumentの関連度を高める狙いがうまく働いたと考えられる
(※promptを変えると最も低くなることも…) - synonymがoriginalより低い
→ 類似の文章が追加されたことでQueryの情報が曖昧になった可能性がある
検証結果(施策2: Documentの前処理)
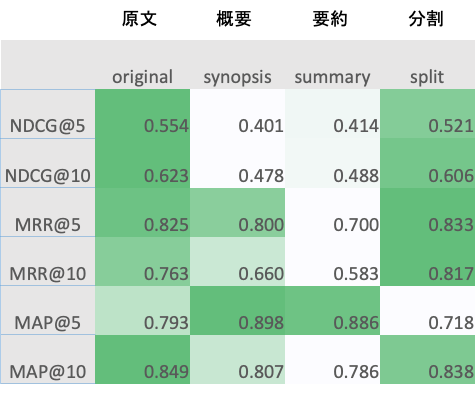
- original > split > synopsis > summary の順にスコアが高い
- 要約(synopsisとsummary)が比較的低い
→ Document自体が上書きされているため、情報が損失したと考えらえる
→ ただしMAP@5は高く出ているので、ランキングは合っていなくてもカバー率は高い傾向 - splitがoriginalより低い
→ Docuemntが長文でなかったため、分割することのメリットがあまりなかった可能性がある
検証結果(施策3: ハイブリット検索)
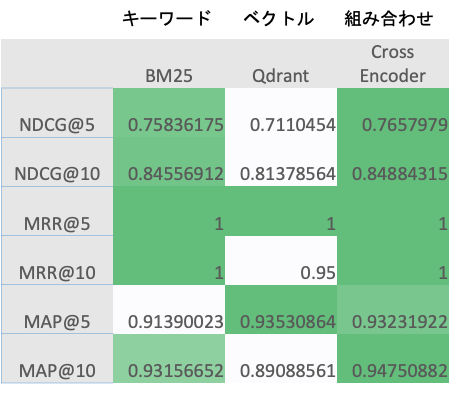
- Cross Encoder > BM25 > Qdrantの順にスコアが高い
- BM25がQdrantより高い
→ Queryが単語ベースだったので、キーワード検索の方が適していたデータセットだった可能性がある - Cross Encoderが最も高い
→ ハイブリット検索の優秀さが実証
もう少し実用的な話
速度について
- 検索時は施策1のようにQueryをLLMを使って前処理すると、検索に時間がかかります。
- Documentをベクトル化する時、施策2のようにLLMを使って要約などをすると時間がかかります(しかも精度良くない…)
- 上記2つのうち、Documentの方は圧倒的にデータ量が大きいので相当な時間が必要です(平均1,000文字の文を1,000個の時で、大体1.5hくらい)
検索精度について
- Promptを修正することで、多少は検索精度が改善する余地あり
- 特にQueryの前処理はデータに合った変換をすれば、効果あるかも
まとめ
今回筋が良さそうなのは以下の2つという結果になりました。
- HyDEによるQueryの前処理 (ただし検索に時間がかかる + Prompt工夫必須)
- ハイブリット検索
Queryの工夫は扱う文章に大きく依存します。今回の製品を検索するような単純なものだったのでHyDEがうまく当てはまったような気がしますが、これがもっと長文の社内文書などになれば、どのような質問が来るかなどを想定してQueryを前処理しないといけません。一般的に答えが得られない場合はむしろHyDEでは仮の答えが出せず検索精度が悪化します。
一方で、ハイブリット検索に関しては文章の性質に大きく依存せず使える手法で、かつ精度も一番高い結果になっているので(あくまで今回のケースですが)、かなり有用なのではないかと思います。Qdrantの公式でも推奨している方法で、最近(2023年7月)Azure Cognitive Searchでも導入されています。
というわけで今回はベクトル検索の精度を上げる施策をいろいろ試してみました。
ここまで読んでいただきありがとうございます。
参考文献
- セマンティック検索
セマンティック検索とは? | エンタープライズサーチ QuickSolution
- ベクトル検索
LangChainで HyDE による質問応答を試す|npaka
LangChain でより高い vector 検索精度が期待できる HyDE 仮説をやってみる
blog - LangChain Hypothetical Document Embeddings (HyDE) 全面解説
ベクトル検索で欲しい情報が得られないときの問題点と改良方法を考えてみた | DevelopersIO
- ハイブリット検索
Recommender Systems: Machine Learning Metrics and Business Metrics
Elasticのサーチエンジンビジネスの責任者にインタビュー。ビヘイビア分析の未来とは?
- 評価指標
レコメンドつれづれ ~第3回 レコメンド精度の評価方法を学ぶ~ - Platinum Data Blog by BrainPad
scikit-learnでMean Average Precisionを計算しようと思ったら混乱した話 - 唯物是真 @Scaled_Wurm
Discussion