📒
Youtube⇒mp3⇒文字起こし⇒要約(LLM活用)





概要
- Youtubeの動画からmp3音声を抽出(yt-dlp)
- mp3音声をテキストに変換(whisper)
- テキストを要約(LangChain)
2と3のLLM技術要素を使いたいというのが目的です。Youtube文字起こしするにはもっと簡単な手段がありますが、whisperを使ってみたかったという事になります。
環境、前提
Google Colabで動かします。OPENAI_API_KEYはシークレットに設定されているものとします。
動かしてみた(1つずつコピペしていけば動きます)
1. Youtubeの動画からmp3音声を抽出(yt-dlp)
- パッケージインストール
!pip install yt-dlp
- 要約したいyoutubeの動画URLをmp3でダウンロード(短いものがおすすめこれは3分動画です)
!yt-dlp -x --audio-format mp3 https://www.youtube.com/watch?v=bDzWyu8dZX8
2. mp3音声をテキストに変換(whisper)
- パッケージインストール
!pip install git+https://github.com/openai/whisper.git
-
ダウンロードしたファイルのパスを取得します。ファイルが一時保存されているので右クリックからパスをコピー
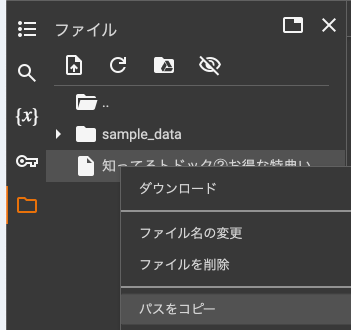
-
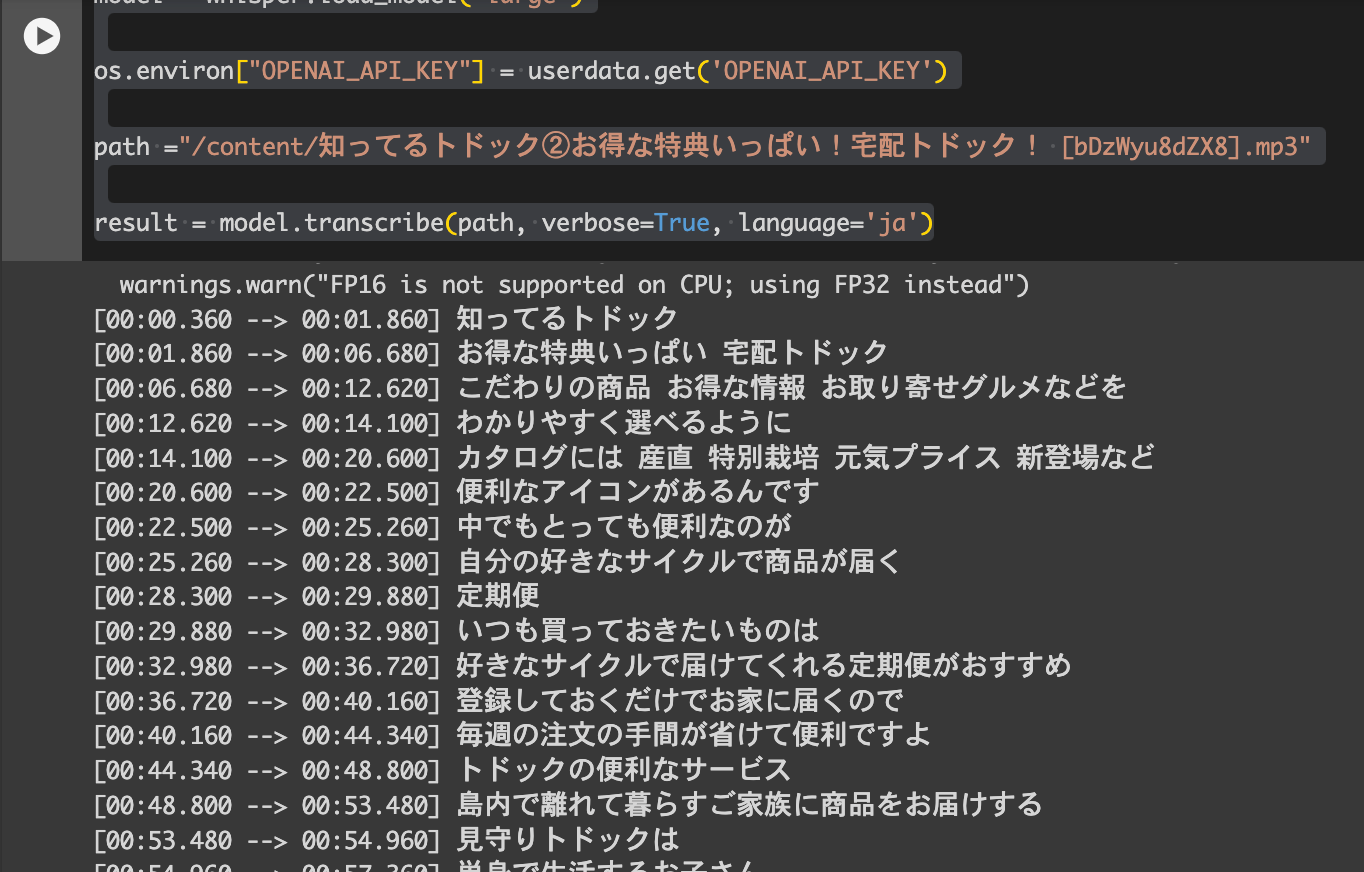
whisperを使って文字起こし(3分の動画でもそれなりに時間がかかりました)
import os
import whisper
from google.colab import userdata
model = whisper.load_model("large")
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
path ="/content/知ってるトドック②お得な特典いっぱい!宅配トドック! [bDzWyu8dZX8].mp3"
result = model.transcribe(path, verbose=True, language='ja')
- 実際にはJSONです。colabのコンソール上とは見え方が違います。
3. テキストを要約(LangChain)
- パッケージインストール
!pip install langchain_openai
- MarkDownで文字起こしを指示します。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4-turbo-2024-04-09")
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("""あなたは要約することが得意です。
inputを箇条書きなど駆使し、みやすくmarkdown記法を使って要約します
input: {input}""")
chain = prompt | llm
ans = chain.invoke({"input": result})
ans.content
- このような出力になりました。良い感じです。

さいごに
mp3⇒LLMでなにかする。が実現できました。応用してなにか作ろうかなと思います。
会議から議事録作成、録音したものから日報作成みたいなものが思いつきますがそれ以外もできそうな予感がします。
Discussion