/mnt/data/とは?ChatGPTコード実行環境を深堀りしてみた
はじめに
ChatGPTにはコードインタープリターという機能がありますよね。これは、LLMがpythonのコードを自動生成して会話を補助してくれるというものです。複雑な計算をしてくれるとかグラフを出力するとかを解決してくれるものとして有名です。これを有効活用したいとおもったとき、どうすれば良いでしょうか。
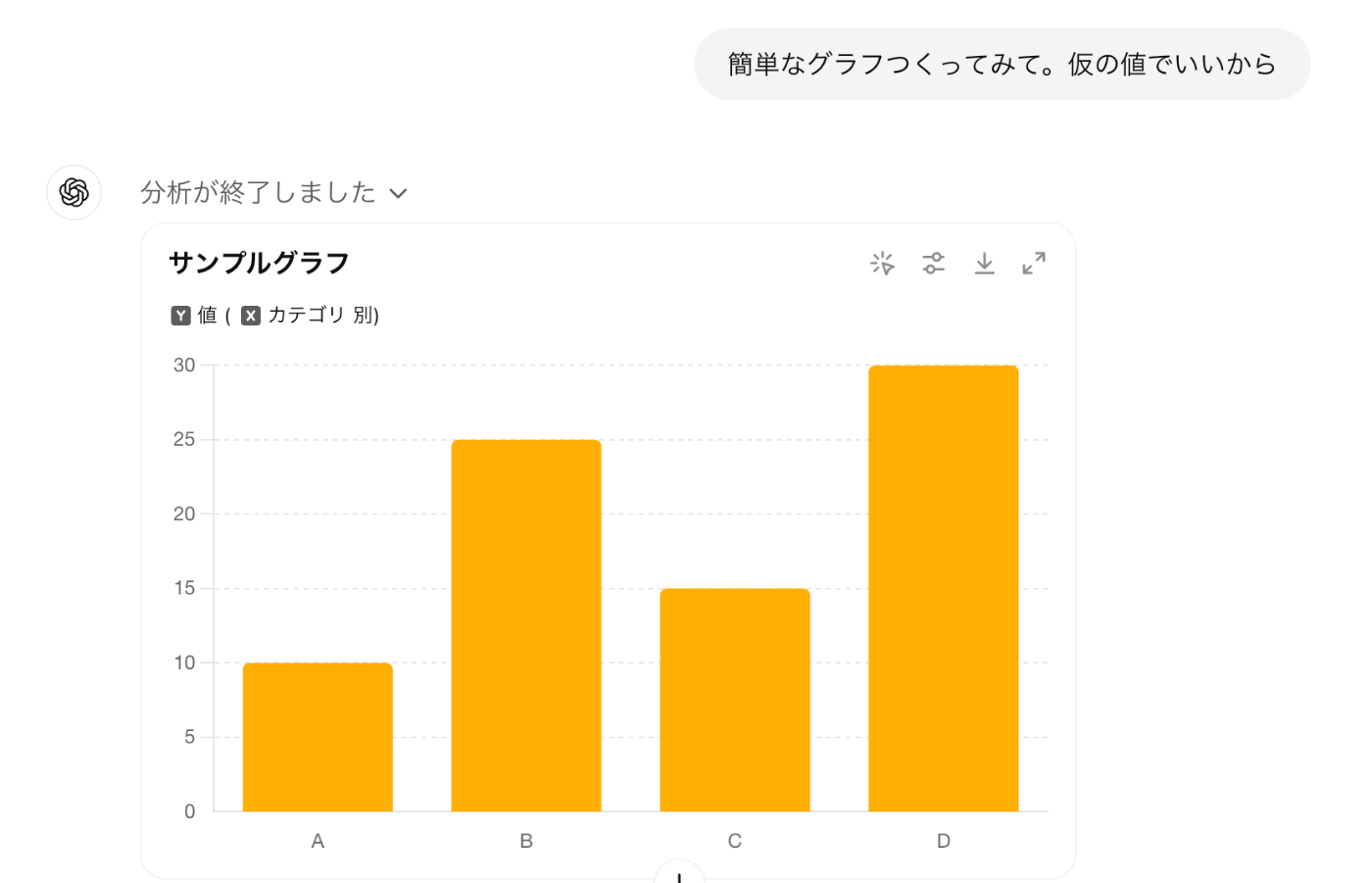
このようなコードが自動生成され、グラフが表示されています。
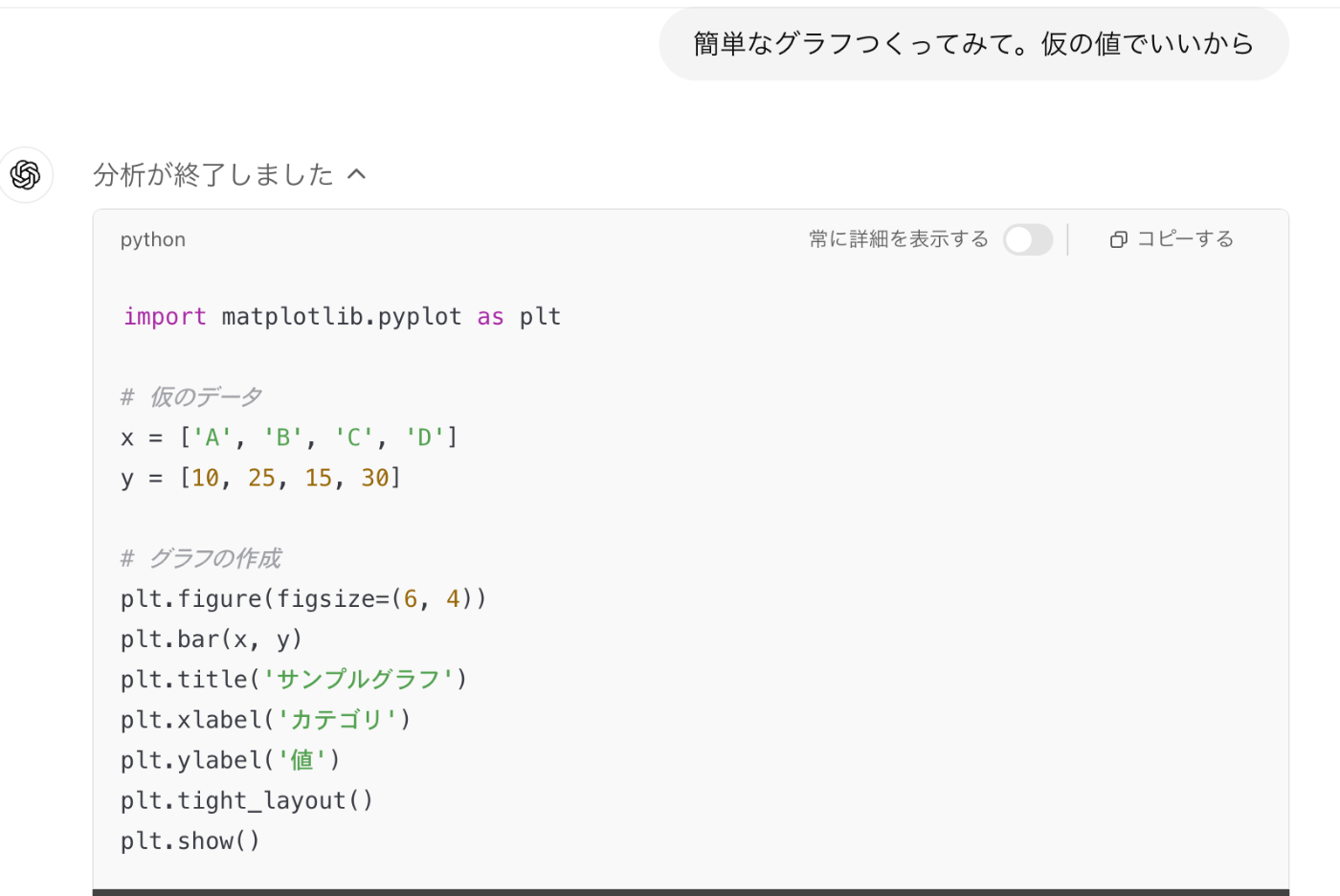
性能を知る
一時ディレクトリ
ChatGPTのブラウザは私たちにどう提供されているのか?という疑問が湧いたことがありました。きっかけはファイルを添付してコードインタープリターが動いたときのソースコードを見たときです。
input_path = "/mnt/data/test.mp4"
この実装をみて、各個人にコンテナのようなものが割り当てられているのではという仮説を立てました。例えばAWS Lambdaも裏はコンテナですよね、/tmpのような一時領域を使えます。とても似ています。少なくとも個人に/mnt/data/が割り当てられているのは事実のようです。ChatGPTに問いただすとコードインタープリターは隔離されたサンドボックスと言うので概ね当たっていると思います。
OS, バージョン
ChatGPTでCanvasというモードがありますよね。適当にPythonでHello Worldするようにお願いし、エディタを開きます。。編集可能&実行可能なので以下のコードに差し替えて実行してみましょう。もちろんコードインタープリターで実行ことも可能です。
with open("/etc/os-release", "r") as file:
content = file.read()
print(content)
実行結果を見てみましょう。
PRETTY_NAME="Debian GNU/Linux 12 (bookworm)"
NAME="Debian GNU/Linux"
VERSION_ID="12"
VERSION="12 (bookworm)"
VERSION_CODENAME=bookworm
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
Debian GNU/Linux 12 (bookworm)を私たちはサンドボックスで動かすことができるのだと理解できたと思います。
どのようなパッケージがインストールされているのか理解する
サンドボックス環境ではどのようなpythonのパッケージが入っているのでしょうか?pipでインストールされているのだろうと仮定します。こちらはCanvasでうまく動かないのですが、コードインタープリターで実行しリスト出力するようにプロンプト指示してみましょう。
import subprocess
result = subprocess.run(["pip", "list"], capture_output=True, text=True)
installed_packages = result.stdout
installed_packages
実行結果は長いので折りたたみます
Brotli==1.1.0
CairoSVG==2.5.2
Cython==0.29.36
Faker==8.13.2
Fiona==1.9.2
Flask-CacheBuster==1.0.0
Flask-Cors==5.0.0
Flask-Login==0.6.3
Flask==3.1.0
Jinja2==3.1.4
MarkupSafe==3.0.2
Pillow==9.2.0
PyJWT==2.10.1
PyMuPDF==1.21.1
PyNaCl==1.5.0
PyPDF2==1.28.6
PyWavelets==1.8.0
PyYAML==6.0.2
Pygments==2.18.0
Send2Trash==1.8.3
Shapely==1.7.1
SoundFile==0.10.2
Wand==0.6.13
Werkzeug==3.1.3
XlsxWriter==3.2.0
absl-py==2.1.0
ace-tools==0.0.1
aeppl==0.0.31
aesara==2.7.3
affine==2.4.0
aiohttp==3.9.5
aiosignal==1.3.1
analytics-python==1.4.post1
annotated-types==0.7.0
anyio==3.7.1
anytree==2.8.0
argon2-cffi-bindings==21.2.0
argon2-cffi==23.1.0
arviz==0.20.0
asn1crypto==1.5.1
asttokens==3.0.0
attrs==24.2.0
audioread==3.0.1
babel==2.16.0
backoff==1.10.0
basemap-data==1.3.2
basemap==1.3.9
bcrypt==4.2.1
beautifulsoup4==4.12.3
bleach==6.2.0
blinker==1.9.0
blis==0.7.11
blosc2==2.0.0
bokeh==2.4.0
branca==0.8.0
cachetools==5.5.0
cairocffi==1.7.1
camelot-py==0.10.1
catalogue==2.0.10
certifi==2024.8.30
cffi==1.17.1
chardet==3.0.4
charset-normalizer==2.1.1
click-plugins==1.1.1
click==8.1.7
cligj==0.7.2
cloudpathlib==0.20.0
cloudpickle==3.1.0
cmake==3.31.1
cmudict==1.0.31
comm==0.2.2
confection==0.1.5
cons==0.4.6
contourpy==1.3.1
countryinfo==0.1.2
cryptography==3.4.8
cssselect2==0.7.0
cycler==0.12.1
cymem==2.0.10
databricks-sql-connector==0.9.1
debugpy==1.8.9
decorator==4.4.2
defusedxml==0.7.1
dlib==19.24.2
dnspython==2.7.0
docx2txt==0.8
einops==0.3.2
email_validator==2.2.0
entrypoints==0.4
et_xmlfile==2.0.0
etuples==0.3.9
exchange-calendars==3.4
executing==2.1.0
fastapi-cli==0.0.5
fastapi==0.111.0
fastjsonschema==2.21.1
fastprogress==1.0.3
ffmpeg-python==0.2.0
ffmpy==0.4.0
filelock==3.16.1
folium==0.12.1
fonttools==4.55.3
fpdf==1.7.2
frozenlist==1.5.0
future==1.0.0
fuzzywuzzy==0.18.0
gTTS==2.2.3
gensim==4.3.1
geographiclib==1.52
geopandas==0.10.2
geopy==2.2.0
gradio==2.2.15
graphviz==0.17
h11==0.14.0
h2==4.1.0
h5netcdf==1.4.1
h5py==3.8.0
hpack==4.0.0
html5lib==1.1
httpcore==1.0.7
httptools==0.6.4
httpx==0.28.1
hypercorn==0.14.3
hyperframe==6.0.1
idna==3.10
imageio-ffmpeg==0.5.1
imageio==2.36.1
imgkit==1.2.2
importlib_metadata==8.5.0
importlib_resources==6.4.5
iniconfig==2.0.0
ipykernel==6.29.5
ipython-genutils==0.2.0
ipython==8.30.0
isodate==0.7.2
itsdangerous==2.2.0
jax==0.2.28
jedi==0.19.2
joblib==1.4.2
json5==0.10.0
jsonpickle==4.0.0
jsonschema-specifications==2024.10.1
jsonschema==4.23.0
jupyter-server==1.23.5
jupyter_client==7.4.9
jupyter_core==5.1.3
jupyterlab-pygments==0.2.2
jupyterlab==3.4.8
jupyterlab_server==2.19.0
keras==2.6.0
kerykeion==2.1.16
kiwisolver==1.4.7
korean-lunar-calendar==0.3.1
langcodes==3.5.0
language_data==1.3.0
lazy_loader==0.4
librosa==0.8.1
lit==18.1.8
llvmlite==0.43.0
logical-unification==0.4.6
loguru==0.5.3
lxml==5.3.0
marisa-trie==1.2.1
markdown-it-py==3.0.0
markdown2==2.5.2
markdownify==0.9.3
matplotlib-inline==0.1.7
matplotlib-venn==0.11.6
matplotlib==3.6.3
mdurl==0.1.2
miniKanren==1.0.3
mistune==3.0.2
mizani==0.10.0
mne==0.23.4
monotonic==1.6
moviepy==1.0.3
mpmath==1.3.0
msgpack==1.1.0
mtcnn==0.1.1
multidict==6.1.0
multipledispatch==1.0.0
munch==4.0.0
murmurhash==1.0.11
mutagen==1.45.1
nashpy==0.0.35
nbclassic==0.4.5
nbclient==0.10.1
nbconvert==7.16.4
nbformat==5.10.4
nest-asyncio==1.6.0
networkx==2.8.8
nltk==3.9.1
notebook==6.5.1
notebook_shim==0.2.4
numba==0.60.0
numexpr==2.10.2
numpy-financial==1.0.0
numpy==1.24.0
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-cupti-cu11==11.7.101
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
nvidia-cufft-cu11==10.9.0.58
nvidia-curand-cu11==10.2.10.91
nvidia-cusolver-cu11==11.4.0.1
nvidia-cusparse-cu11==11.7.4.91
nvidia-nccl-cu11==2.14.3
nvidia-nvtx-cu11==11.7.91
odfpy==1.4.1
opencv-python==4.5.5.62
openpyxl==3.0.10
opt_einsum==3.4.0
orjson==3.10.12
oscrypto==1.3.0
packaging==24.2
pandas==1.5.3
pandocfilters==1.5.1
paramiko==3.5.0
parso==0.8.4
patsy==1.0.1
pdf2image==1.16.3
pdfkit==0.6.1
pdfminer.six==20220319
pdfplumber==0.6.2
pdfrw==0.4
pexpect==4.9.0
pip==24.0
platformdirs==4.3.6
plotly==5.3.0
plotnine==0.10.1
pluggy==1.5.0
pooch==1.8.2
preshed==3.0.9
priority==2.0.0
proglog==0.1.10
prometheus_client==0.21.1
prompt_toolkit==3.0.48
pronouncing==0.2.0
propcache==0.2.1
psutil==6.1.0
ptyprocess==0.7.0
pure_eval==0.2.3
py-cpuinfo==9.0.0
py==1.11.0
pyOpenSSL==21.0.0
pycountry==20.7.3
pycparser==2.22
pycryptodome==3.21.0
pycryptodomex==3.21.0
pydantic-extra-types==2.10.1
pydantic-settings==2.6.1
pydantic==2.9.2
pydantic_core==2.23.4
pydot==1.4.2
pydub==0.25.1
pydyf==0.11.0
pygraphviz==1.7
pylog==1.1
pyluach==2.2.0
pymc==4.0.1
pypandoc==1.6.3
pyparsing==3.2.0
pyphen==0.17.0
pyproj==3.6.1
pyprover==0.5.6
pyshp==2.3.1
pyswisseph==2.10.3.2
pytesseract==0.3.8
pytest==6.2.5
pyth3==0.7
python-dateutil==2.9.0.post0
python-docx==0.8.11
python-dotenv==1.0.1
python-json-logger==2.0.7
python-multipart==0.0.19
python-pptx==0.6.21
pyttsx3==2.90
pytz==2024.2
pyxlsb==1.0.8
pyzbar==0.1.8
pyzmq==26.2.0
qrcode==7.3
rarfile==4.0
rasterio==1.3.3
rdflib==6.0.0
referencing==0.35.1
regex==2024.11.6
reportlab==3.6.12
requests==2.31.0
resampy==0.4.3
rich==13.9.4
rpds-py==0.22.3
scikit-image==0.20.0
scikit-learn==1.1.3
scipy==1.9.3
seaborn==0.11.2
sentencepiece==0.2.0
setuptools==65.5.1
shap==0.39.0
shellingham==1.5.4
six==1.17.0
slicer==0.0.7
smart-open==7.0.5
sniffio==1.3.1
snowflake-connector-python==2.7.12
snuggs==1.4.7
soupsieve==2.6
spacy-legacy==3.0.12
spacy-loggers==1.0.5
spacy==3.7.5
srsly==2.5.0
stack-data==0.6.3
starlette==0.37.2
statsmodels==0.13.5
svglib==1.1.0
svgwrite==1.4.1
sympy==1.8
tables==3.8.0
tabula==1.0.5
tabulate==0.9.0
tenacity==9.0.0
terminado==0.18.1
text-unidecode==1.3
textblob==0.15.3
thinc==8.2.5
threadpoolctl==3.5.0
thrift==0.21.0
tifffile==2024.9.20
tinycss2==1.4.0
toml==0.10.2
tomli==2.2.1
toolz==1.0.0
torch==2.0.1
torchaudio==2.0.2
torchtext==0.6.0
torchvision==0.15.2
tornado==6.4.2
tqdm==4.64.0
traitlets==5.14.3
trimesh==3.9.29
triton==2.0.0
typer==0.15.1
typing_extensions==4.10.0
ujson==5.10.0
urllib3==1.26.20
uvicorn==0.19.0
uvloop==0.21.0
wasabi==1.1.3
watchfiles==1.0.3
wcwidth==0.2.13
weasel==0.4.1
weasyprint==53.3
webencodings==0.5.1
websocket-client==1.8.0
websockets==10.3
wheel==0.43.0
wordcloud==1.9.2
wrapt==1.17.0
wsproto==1.2.0
xarray-einstats==0.8.0
xarray==2024.3.0
xgboost==1.4.2
xml-python==0.4.3
yarl==1.18.3
zipp==3.21.0
zopfli==0.2.3
何がインストールされているかわかりましたね。これがコードインタープリターで実現可能なことだと明確に理解できました。余談ですが、この作業はGeminiでも行うことができるので出来ることの差分も理解することができます。(Geminiはパッケージはpipではないようですのでコードは変わります)
性能を理解した上でGPTsを作ってみる
例えばffmpegが入っていることに着目し、カスタムGPT(GPTs)を作ってみます。指示文はこのようにします。使えるパッケージも一時ディレクトリもわかっているので与えるコードサンプルも具体的に行います。
Use the python code interpreter to convert mp4 to mp3 and then download it.
You can lower the sound quality if you want to process it faster.
Below is a code sample.
---
import subprocess
# Define input and output paths
input_path = "/mnt/data/test.mp4"
output_path = "/mnt/data/test_audio_ffmpeg.mp3"
# Run ffmpeg command to extract audio
# -y: overwrite without asking
# -vn: no video
# -ab 64k: audio bitrate (lower for faster, smaller file)
command = [
"ffmpeg",
"-i", input_path,
"-vn",
"-ab", "64k",
"-ar", "44100", # sample rate
"-y",
output_path
]
# Execute the command
subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Return output path
output_path
mp4をmp3へコンバートするというGPTsができました。簡単ですね。もちろん、コードはChatGPTに自動生成させています。
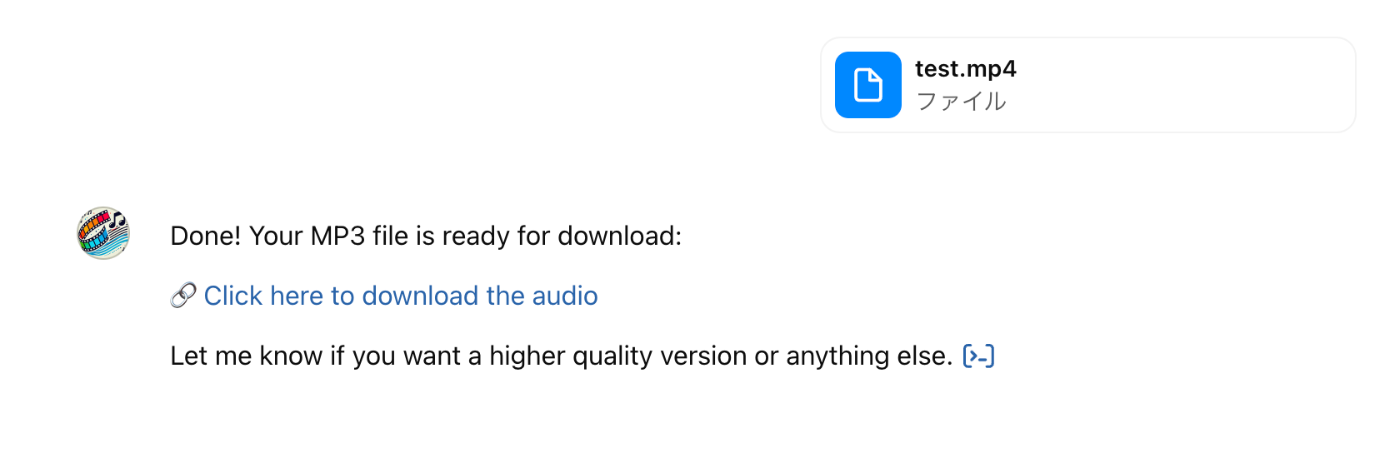
さいごに
ChatGPTのコードインタープリターは理解を深めれば、より深い世界で乗りこなすことができます。
皆様のお役に立てれば幸いです。
本記事はOpenAIが提供する公式機能の範囲内での検証結果であり、
セキュリティリスクや脆弱性の開示を目的としたものではありません
Discussion