今まで深く機械学習や深層学習を学んでいなかったので触れてみようと思いました。今回はとにかく実装することをメインに進めていきたいと思います。
深層学習モデルを扱うにあたって
まず、目的を明確にする必要があります。今回は動画像の状況を文章に起こしたいと考えています。また、1からモデルを組み立てる技術はないので、構築済みのモデルを使いたいと考えています。
大規模言語モデル(LLM)について
今回は入力動画像を大規模言語モデルに入れて、現在の状況を説明するものを作りたいなと考えています。そもそも、大規模言語モデル(LLM)とは以下のようなものです。
大規模言語モデル(Large Language Models、LLM)とは、非常に巨大なデータセットとディープラーニング技術を用いて構築された言語モデルです。ここでいう「大規模」とは、従来の自然言語モデルと比べ、後述する3つの要素「計算量」「データ量」「パラメータ数」を大幅に増やして構築されていることに由来します。大規模言語モデルは、人間に近い流暢な会話が可能であり、自然言語を用いたさまざまな処理を高精度で行えることから、世界中で注目を集めています。
しかし、大規模言語モデルはあくまで言語に焦点を当てているため、画像を扱うことができません。故にBLIPというモデルに着目しました。
BLIP(Bootstrapping Language-Image Pre-training)について
BLIPとはBootstrapping Language-Image Pre-trainingの略です。簡単に言えば画像を言語に変換できるモデルです。主な相違点としては以下の通りです。
- Multimodal mixture of Encoder-Decoder(MED)
MEDは、画像に基づいたエンコーダー・デコーダーとして動作し、視覚言語理解、視覚言語生成に対して柔軟な転移学習を可能にするアーキテクチャです。- Captioning and Filtering (CapFilt)
ノイズの多い画像とテキストのペアから学習するための新しいデータセットブーストラッピング法です。
事前トレーニングされたMEDを2つのモジュールに微調整します。1つはWeb画像に基づいて合成キャプションを生成するキャプション作成者、
もう1つは元のWebテキストと合成テキストの両方からノイズの多いキャプションを削除するフィルターです。
さらに別の手法をもったBLIP-2というモデルが存在している。
BLIP-2 について
概略
- 大規模モデルの訓練のため、Vision-Language(V&L)事前訓練がますます高コストになっているので、減らしたい
- 言語モデル、特に大規模言語モデル(LLM)は、強力な言語生成能力とゼロショット転移能力がある
- 事前学習中にLLMを凍結したい理由:破滅的忘却、計算コスト
- ユニモーダルなモデルを、V&L事前学習に活用するには、クロスモーダルアライメントの促進が重要
- LLMは画像を見ていないため、V&Lのアライメントが困難
- 既存の手法(FrozenやFlamingo)はテキスト生成の損失関数に頼っていて、アラインメント機能が不十分
- BLIP-2では、このアラインメントを取るためにクエリ変換器(Q-Former)を提唱
- 画像エンコーダーとLLMの渡しの役割のボトルネックモジュール。両者間の表現のギャップを埋めたい
- Q-Formerは学習可能なクエリベクトル群
- 学習するのはQ-Formerの部分

- BLIP-2は、事前学習済みの画像エンコーダーと、固定の大規模言語モデルからV&Lのブートストラップすることで事前学習を効率化。2段階からなる
- 1段階目:固定の画像エンコーダーから、V&Lの表現をブートストラップ
- 2段階目:固定の言語モデルから、画像→言語の生成をブートストラップで学習
- 既存の手法より、学習パラメーターが著しく少ないが、様々なV&LタスクでSoTA。
- ゼロショットVQAv2では、Flamingo80Bより、54倍少ない学習パラメーターで、8.7%上回る性能
- 言語の指示に従った、画像→テキストのゼロショット生成ができ、画像をインプットとした対話も可能
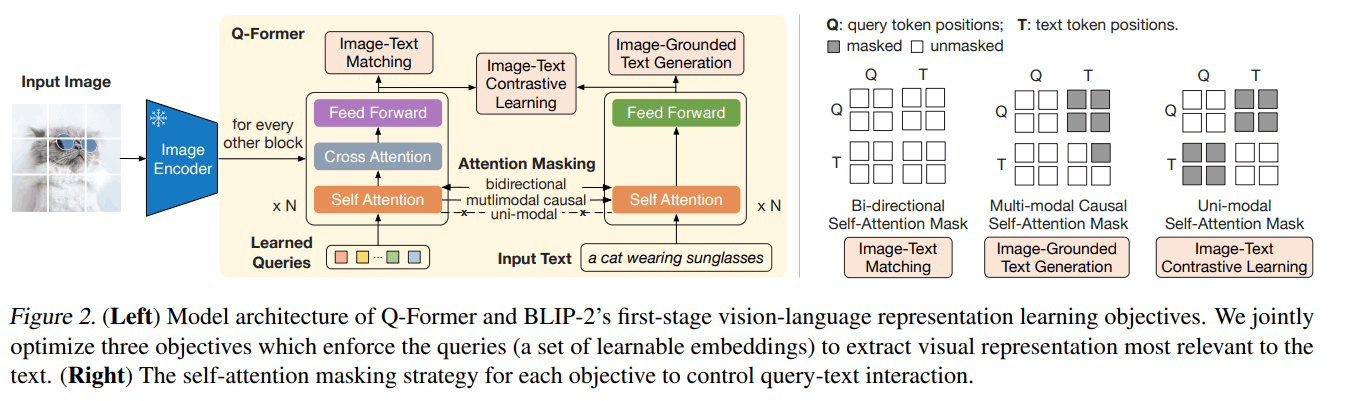
Q-Formerの構造
Q-Formerは2つのサブモジュールからなる
- 画像変換器(左):画像エンコーダーと対話して視覚特徴抽出
- テキスト変換器(右):入力テキストをエンコードし、デコーターとして機能

ということでBLIP-2モデルを今回は使用していきたいと考えています。
学習済みBLIPモデルをさわる
しかし、前述したように今までモデルの構築の知識がないので悩んでいます。
色々調べているとこのような学習済みモデルを見つけました。
このモデルは、入力画像について会話できる視覚言語モデルでありheronライブラリを用いて学習されたものでした。
実際さわってみるととても面白いと思います。これはあくまで画像ベースなので動画像ベースにしなければなりません。しかし、今回はいいことにHugging FaceというAI開発プラットフォームを見つけることができました。
次回について
- Hugging Faceにあるモデルの使い方の確認
- 動画像をどのようにして扱うか...

Discussion
素晴らしい記事をありがとうございます😊
今後、画像や動画の検索にこのような大規模言語モデルを用いた仕組みが一般化すると思い注目しています。実にタイムリーな記事だと思いました✨