



前回は、使いたいモデル(BLIP-2)を見つけることができ、それらがAIプラットフォームであるHugging Faceにたくさんあることが分かりました。今回はまずHugging Faceについてまとめたいと思います。
Hugging Faceについて
前述のとおりAIプラットフォームであり、特に自然言語生成モデルがたくさんあります。
Hugging Faceの主な目的は、AIコミュニティの協力と共有を促進することです。プラットフォームは、AIモデルやデータセットをユーザーがアップロードし、共有することができるようになっています。また、他のユーザーがアップロードしたモデルやデータセットを検索して利用することもできます。
つまり、公開されているモデルは使うことが可能なので1からモデルを構築する必要ない!なので、利用方法をまとめていきたいと思います。
利用方法について
Hugging Faceで扱えるライブラリとして、以下があります。
- Transformers
- Tokenizers
- Datasets
今回はTransformersを使っていきます。ここからは実際にコードを書いていきたいと思います。
開発
言語はPythonで書いていきます。ros2 humble pkgとして実行したいのでそこも視野にいれて進めていきます。
使うライブラリ
# Blip import
import torch
import torchvision
import numpy as np
import decord
from PIL import Image as PIL_Image
from decord import cpu
from transformers import Blip2Processor, Blip2ForConditionalGeneration
from cv_bridge import CvBridge,CvBridgeError
decord.bridge.set_bridge('torch')
# ros2 import
import rclpy
from rclpy.node import Node
from rclpy import qos
from std_msgs.msg import String
from sensor_msgs.msg import Image as Sensor_Image
| Library | 説明 |
|---|---|
torch |
Pythonの機械学習プロセスで頻繁に使われるライブラリ,データ型を使用するため |
numpy |
数値計算を効率的に行うための拡張モジュール |
PIL |
画像処理ライブラリ |
decord |
Deep Learning 向け動画読み込みライブラリ |
transformers |
huggingfaceが公開している機械学習ライブラリ |
cv_bridge |
rosの画像データをopencvで扱うためのライブラリ |
ソースコード開発
モデルの読み込み
まずは、モデルを読み込む関数を以下のように作ります。今回は学習済みのモデルを読み込むのでfrom_pretrainedを使用します。公式のコードを読むとわかりやすいです。
def load_model():
'''
Load BLIP2 model
'''
print('Loading model')
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained(model_name)
model = Blip2ForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16
)
model.to(device)
print('Loading end')
画像読み込み
今回はros2のSensor_msg::msg::ImageをPIL::Imageに変換したいです。いままで画像処理をopencvでやってきた経験を活かし、sensor_msg -> cv::Mat -> PIL という変換をすることにしました。cv_bridgeを使えば、容易にcv::Matに変換できます。
# input_image -> cv_image input_image: ros sensor_msg::msg::Image
bridge = CvBridge()
try:
cv_image = bridge.imgmsg_to_cv2(input_image, "bgr8")
except CvBridgeError as e:
print(e)
ここで、openCv用にbgr8でエンコードしたものをPIL用に変更します
pil_image = cv_image[:, :, ::-1]
これで変換の流れは終了です
モデルを実行
公式のコードを参考にすると以下のような感じになります。
inputs = processor(images=pil_image, return_tensors="pt").to(device, torch.float16)
generated_ids = blip_model.generate(**inputs)
generated_text = processor.batch_decode(
generated_ids,
skip_special_tokens=True)[0].strip()
inputsで入力するデータを決めます。Questionがある場合は以下のように変更してください。
prompt = "Question: <聞きたい内容> Answer:"
inputs = processor(images=pil_image, text=prompt, return_tensors="pt").to(device, torch.float16)
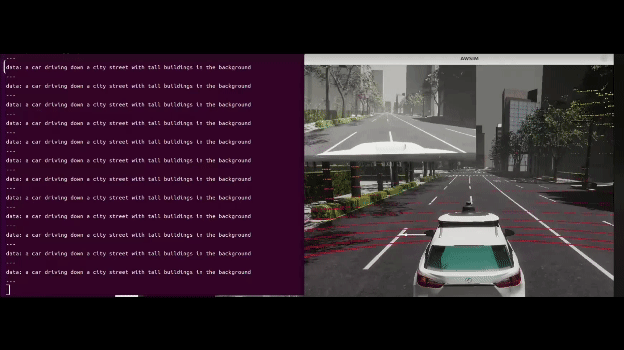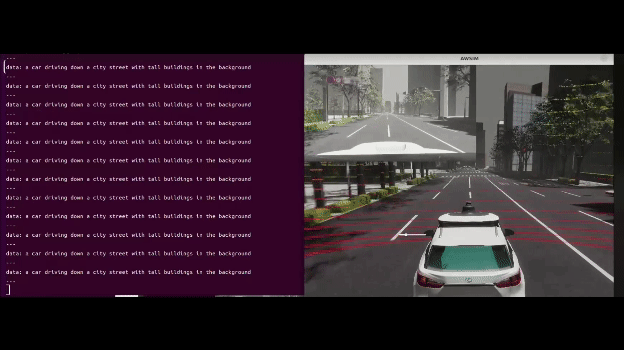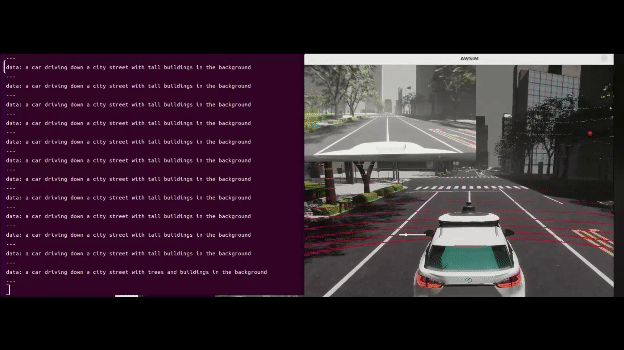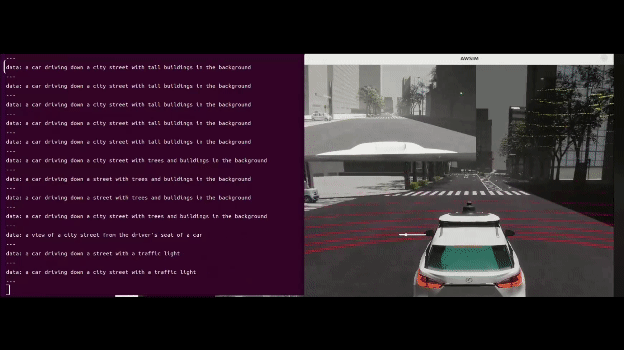
実際に動かしてみた
AWSIMで動かしてみました。
↓デモの様子(input_imageは左上)

Discussion