最近流行りのマルチモーダルを少し経験してみようと思い、視覚的および言語的な指示を使ったマルチモーダル チャットボットを実際に動かそうと思います!!
Setup
とりあえずドキュメントの通り行いました!!
pythonで実行する場合
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
pip install -r requirements.txt
pip install -v -e .
condaで実行する場合
conda env create -f environment.yml
ローカル環境で実行
色々ダウンロードして下記のような構造を作成します。
checkpoints
├── llama-7b_hf
│ ├── config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── ......
│ └── tokenizer.model
├── OpenFlamingo-9B
│ └──checkpoint.pt
├──mmgpt-lora-v0-release.pt
まずは、llsms-7b_hfの関連からダウンロードします。下記のコマンドを入力するとダウンロードできると思います。ダウンロードにはしばらく時間を要します!!
# if you don't have git-lfs
git lfs install
cd ~/Multimodal-GPT/checkpoints
git clone https://huggingface.co/decapoda-research/llama-7b-hf
mv llama-7b-hf/ llsms-7b_hf/
次に、OpenFlamingo-9Bをダウンロードします。方法は以下を入力してください。
git clone https://huggingface.co/openflamingo/OpenFlamingo-9B-deprecated
最後に、mmgpt-lora-v0-release.ptをダウンロードします。こちらは、直接ダウンロードするためここをクリックして、上記の構造になるように移動させてください。
動かしてみた
起動方法は以下のコマンドを実行します。
cd ~/Multimodal-GPT
python ./app.py
これで以下のようなものが表示されれば問題ありません。
実際に生成されたLinkに移動してみます。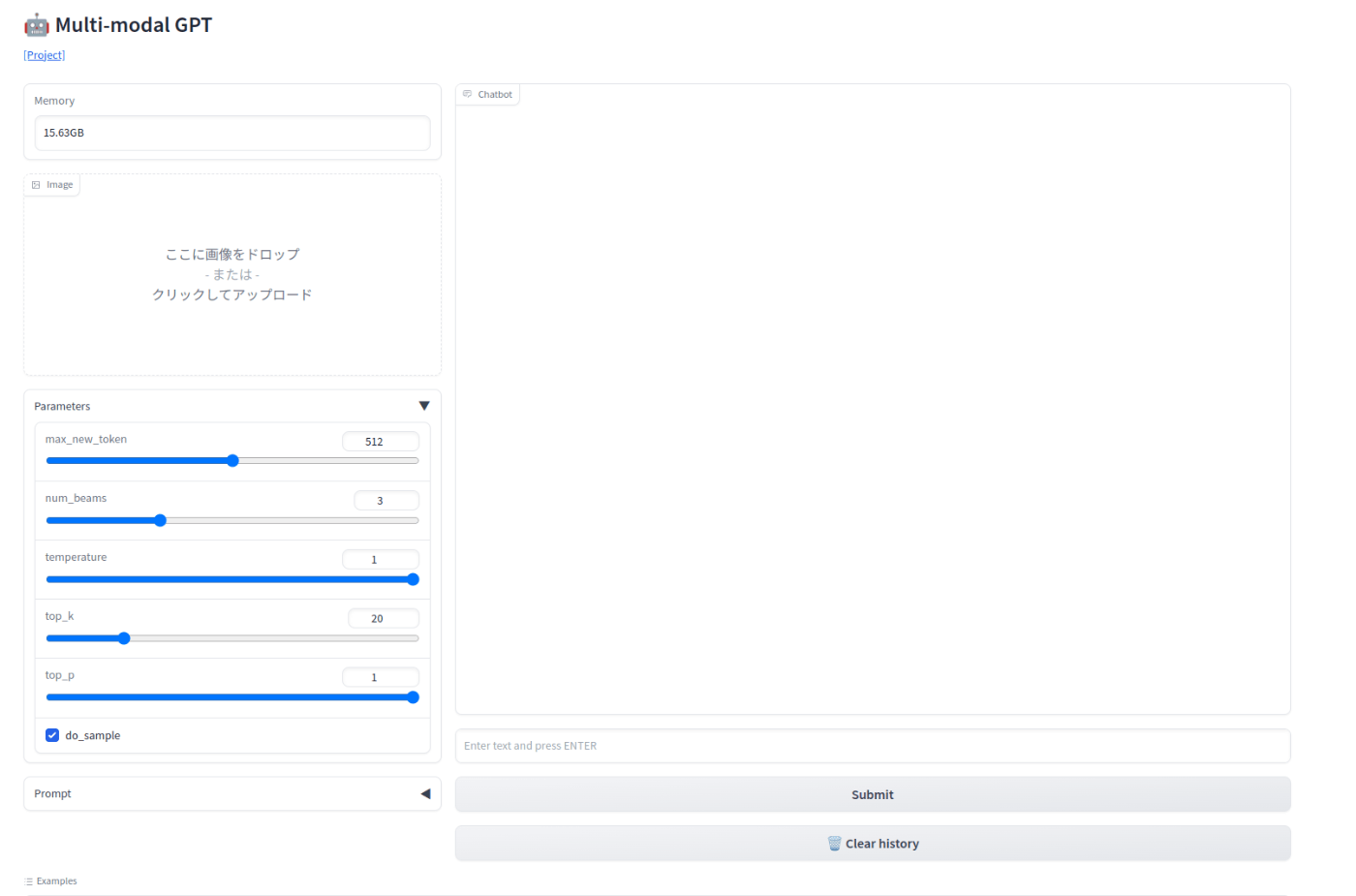
実際の挙動 例
アメリカの町並みを入れてみて、この画像には何が写っているのか?と聞いてみると...
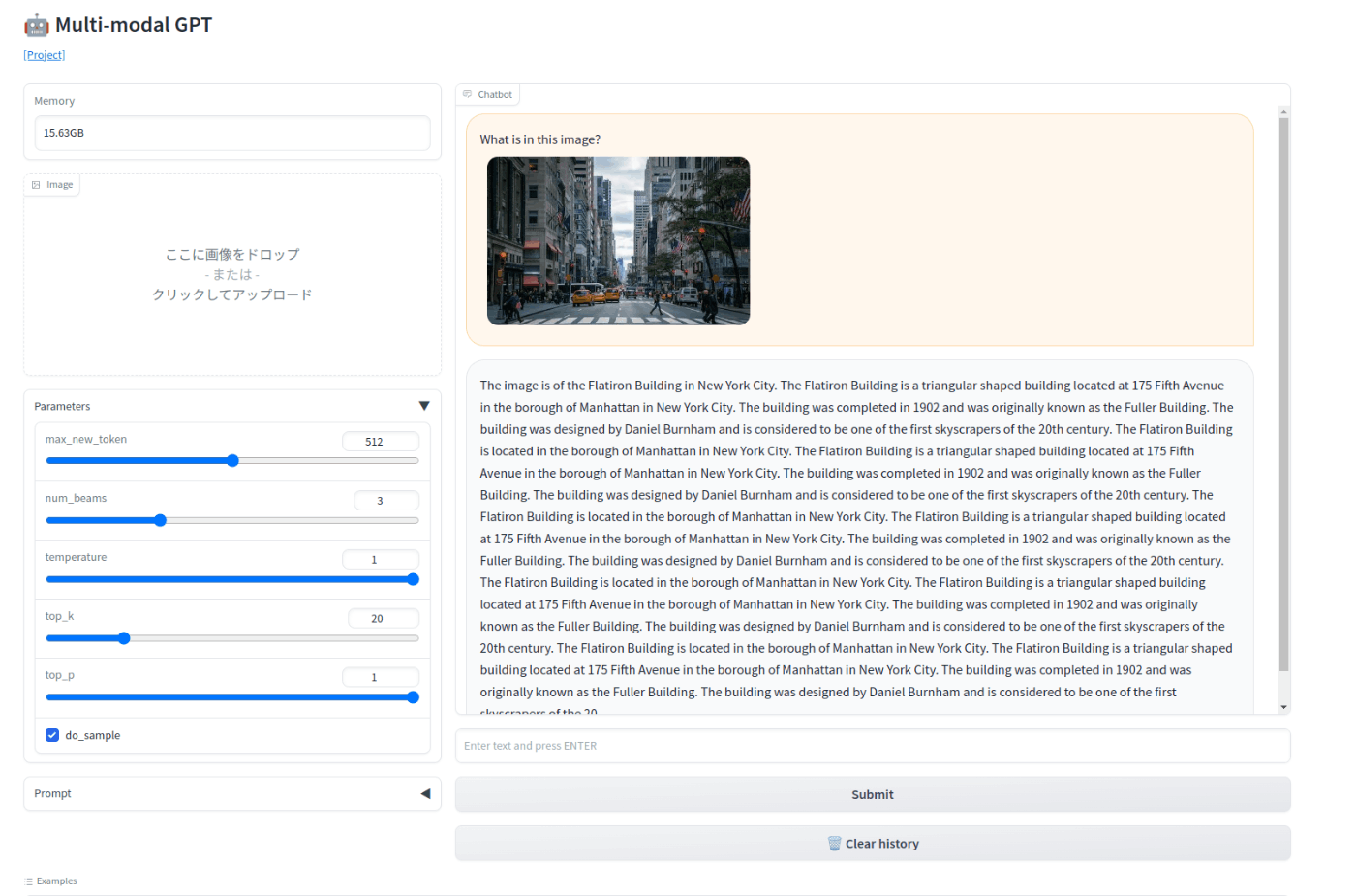
実際動かしてみると、とても面白かったです。トレーニング次第で結果が変わるので、何か使えることがあったら色々触ってみようと思います。

Discussion