事例紹介: データ基盤の役割とdbtの効果
はじめに
これは dbt adventcalendar20日目の記事です。
はじめまして、都内で新卒データサイエンティストとして活動している稲葉と申します。
今回は、構築したデータ基盤が育ててから1年間が経ち、学びが多かったので1年間のまとめとして書きます。
私たちのチームとデータ基盤の役割について
チームとチームを取り巻く環境について

私たちのチームはデータサイエンティスト4人で構成されており、メインタスクとしては協業先のアプリグロースをデータ分析やデータ活用といった手段で推し進めるためのチームになっています。また、密接に関わる協業先が存在しているためデータ分析の結果や集約した指標を基に意思決定をする場面が多々存在している状況でした。
自分達の理想のデータ基盤
私たちのチームには、データエンジニアが存在せず、データサイエンティストがサブタスクとしてデータエンジニアリングにリソースを割く場面がしばしば存在していた背景がありました。データ基盤を時と場合に応じて適切な形に変化させることは重要なタスクであるものの多くの時間を割くことは避けたいという状況がありました。
そのため「データ基盤に割く時間と必要としてるデータ基盤のスペックとの接点を上手く見つけながらデータ基盤を状況に応じてスケールさせられる土台作り」が重要でした
実際に上記を満たす土台を作るためにdbtがどのように役立ったかを紹介しようと思います。
dbtを導入するに至った課題と実問題
自分達のデータ基盤の課題感としては3つほど挙げられます。
- データ基盤のメンテナンス性が低いことによる保守・運用コスト肥大化
- データ品質が担保された状態での安定的なデータ供給体制
- データ基盤に関するメタ情報の継続的な更新と共有
上記の課題で起こる実問題としては
- データ基盤に変更を加えるまでの速度が遅い
- ex. クエリ作成→再現性テスト→レビュー(ここでも再現性をテスト)→デプロイ
- データの異常に気づくまで時間を要する
- ex. 集計結果がずれた際に気づくが時間がかなり経っている
- データを扱う人間によって持っている情報量やその質がまちまちであること
- ロジックを理解し改修できる、利用できるユーザは限定的
- 集計の過程はクエリを見なければ把握できない
といったことが起こっていました。
dbtを導入してどのように変わったか
課題1. データ基盤のメンテナンスコストが高いことによる保守・運用コスト肥大化
既存のデータ基盤では、下記のようなデプロイフローが採用されていました。
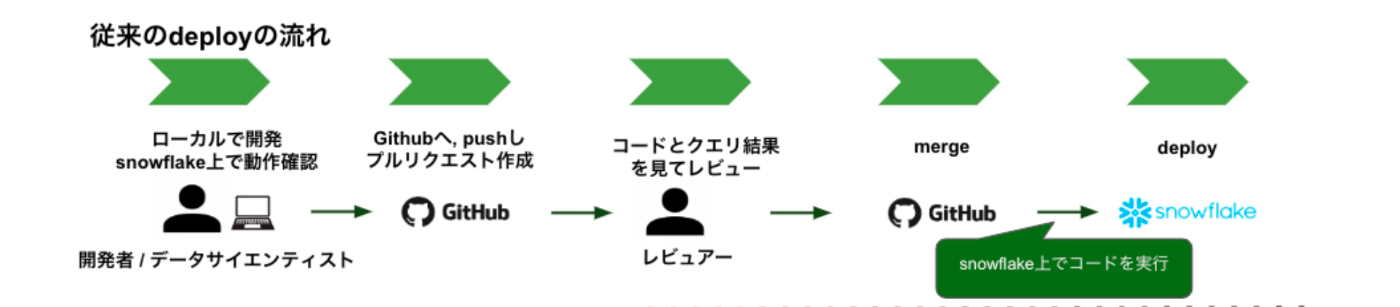
このデプロイフローでは開発サイクルが極端に遅くなるといった問題が発生していました。
この問題を引き落とすボトルネックになっていた部分としては
- レビュワー、開発者の連携コストが必然と生じることによるコミュニケーションコストの増加
- 再現性を検証するためのテストを設計するコストが高い
- 本番データに反映させた後の継続モニタリングが一定期間必要である長期的な時間コスト
が挙げられます。
これらの課題を解決するためdbtとCI/CDを組み合わせることで以下のようなデプロイフローに変更しました。
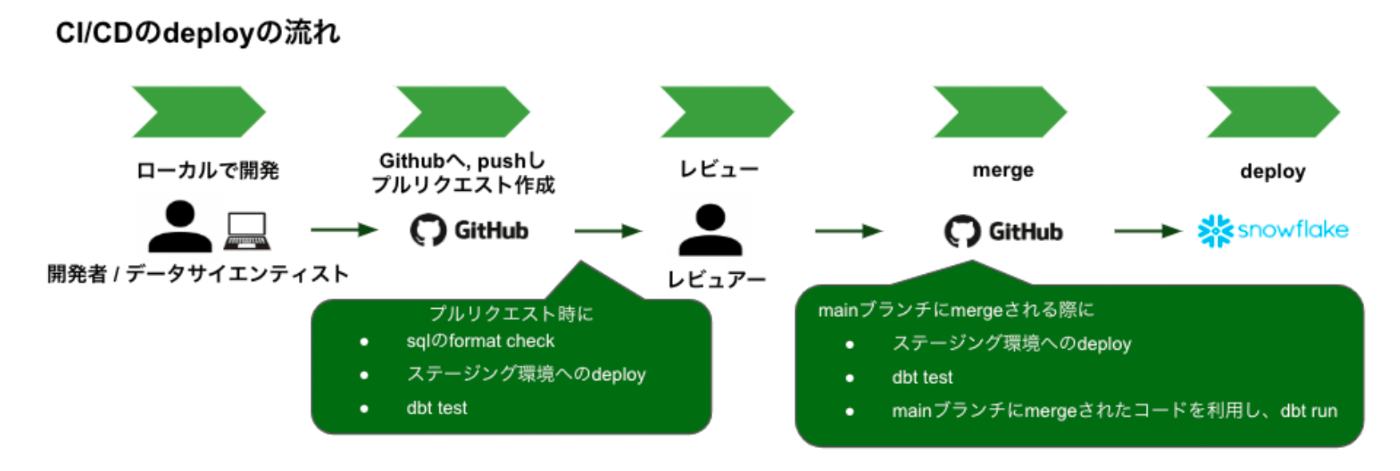
CI/CDのざっくりとした流れ
- commitごとの差分を検知し、CI/CDを走らせるべき場合は実行する
- 本番環境にある一定期間分のデータを利用してSTG DBと生データを扱うSchemaを作成する
- dbt runを行い、変更差分が反映された状態のテーブル・ビューを作成する
- 2で作成されたSTG DB全体に対してテストを実施する
CI/CDはPR作成時とデプロイ時に走るようになっており、デプロイ時にはデータ共有設定やドキュメントの更新、Prod環境への反映も実行されるようになっています。
このようにデプロイフローを改修したことでレビュワー、開発者の連携コストやデプロイ元の統一化をしたことによる更新差分の透明性向上といったメリットにもつながり、結果として開発サイクルを格段に高速化することができました。
課題2. データ品質が担保された状態での安定的なデータ供給体制
私たちのチームではデータを元に施策の実施や意思決定をおこなっている場面が多々ありました。
データ品質が担保されていない状態では
- 過小/過大評価した結果でレポーティング・意思決定をしてしまう
- クライアントがデータ基盤内の不備に気づく
- 実験からレポーティングまでの無駄な金銭的・時間的コストの増加
といったように、データの品質がクライアントからの信頼に直結するほど重要なものになっています。またこういったデータ品質が悪いデータの蓄積は負債といった形で将来的な金銭的・時間的コストの増加や数値的な不一致による損失に繋がりかねないため事前にそれらを解消したいといった狙いもありました。
dbtを導入する前は、日時的な自動テストが上手く機能しないことによるモニタリング不足とモニタリングを手動sqlで行うといったモニタリングコストが高いといった課題がありました。
dbtを導入してデータ品質部分で実際に変わったこととしては
- データの異常性発見に気づく、直すまでのサイクルの高速化
- 原因発見するまで、発見してからの対応が高速化された
- データをモニタリング不足の解消
といったところで、上記を解消したことでデータ品質の担保だけでなくデータ基盤にリソースを割く量を減らすことができたと考えています。
余談
そのほかにも、複雑なクエリを作成した際にロジックの分割単位の妥当性を探るためにも利用していました。分析・レポーティング用のクエリは、ロジックが盛り込まれているため複雑化しやすい傾向にあると感じています。
自分達の場合、アプリ上のログデータとPOSデータを結合する際に複雑なロジックを盛り込んでおり、それらを分割する際の妥当性チェックに利用しています。

課題3. データ基盤に関するメタ情報の継続的な更新と共有
データ基盤に触れるユーザの属性は、新規メンバーから協業先、ビジネスサイドといった多種多様になっていました。こういった時に出てくる実問題は以下のようなものになっています。
- データを扱う人間によって持っている情報量やその質がまちまちであること
- ex. 〇〇IDは、このIDと突合できる, ▲▲カラムはこの情報を持っていない
- 新メンバーへのキャッチアップコストなどが肥大化していく
- 自分達が想定した集計と相手が想定していた集計が違うといったロジックの乖離
- ex. 自分達の意図と相手の意図が違う
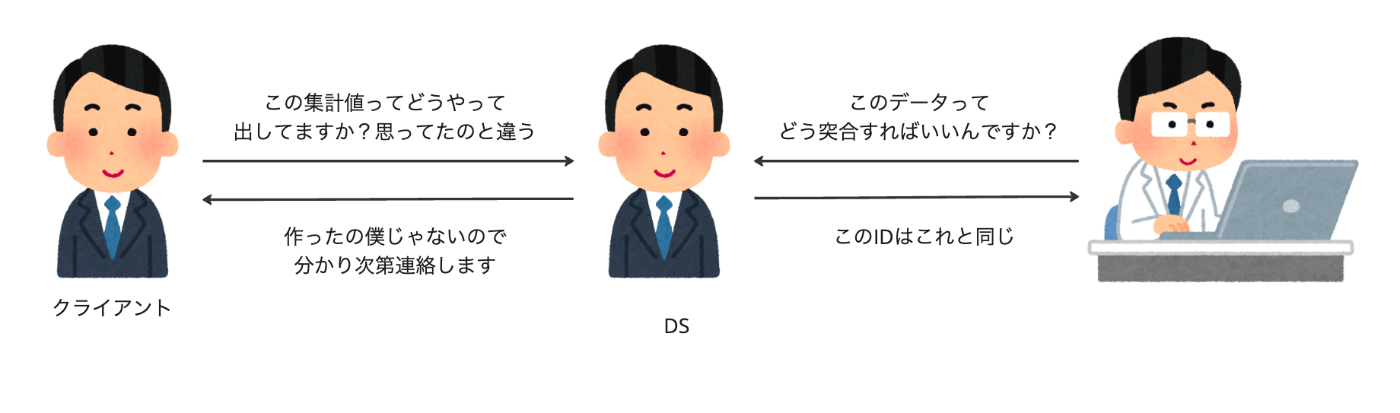
- ex. 自分達の意図と相手の意図が違う
この実問題はコミュニケーションコストが増加し結果としてオンボーディングに時間がかかりすぎた、意思決定に遅れがでたといった問題を引き起こしかねません。
これらを上手く解消してくれたのが、dbtのLineage Graphやdbt docsでした。dbtでは dbt-osmosisなどメタ情報の管理を行えるパッケージもあり、これらもdbtが他のデータ変換サービスより秀でている点の1つであるとも考えています。
また課題1でも述べたようにデータ基盤への変更と連動させて更新できるため更新忘れなどがなくなり継続的なドキュメントの共有体制ができたことは、情報の伝達漏れの解消にもつながるといったメリットにも繋がります。
所感
実際に使うまでは導入が難しいツールなのかもしれないといった考えもありましたが、導入してみると多くのメリットが得られ導入してよかったなと思います。
またdbtのいいところは柔軟性にあると考えています。今回挙げさせていただいたように一定水準のサービスを提供してはいますが、利用者側がどのような目的を持って利用するかによって利用効果は絶大になります。例を挙げると、マクロを利用したロジックの統一といったようにtips的な利用の仕方は多くあり、それらに気づく・キャッチアップし続けることが重要だと思いました。
まとめ
今回の記事では、データ基盤の役割からdbtの大まかな強みについて書きました。
dbtを導入したことにより、データエンジニアリングに割く時間を削減しつつも必要としているデータ基盤にスケールさせる土台が作成できました。
まだ構築から運用合わせて1年と短いので今後もdbtを活用したデータ基盤の整備を進めていこうと思います
Discussion