インデックス(Index)とは?
インデックス(Index)とは?
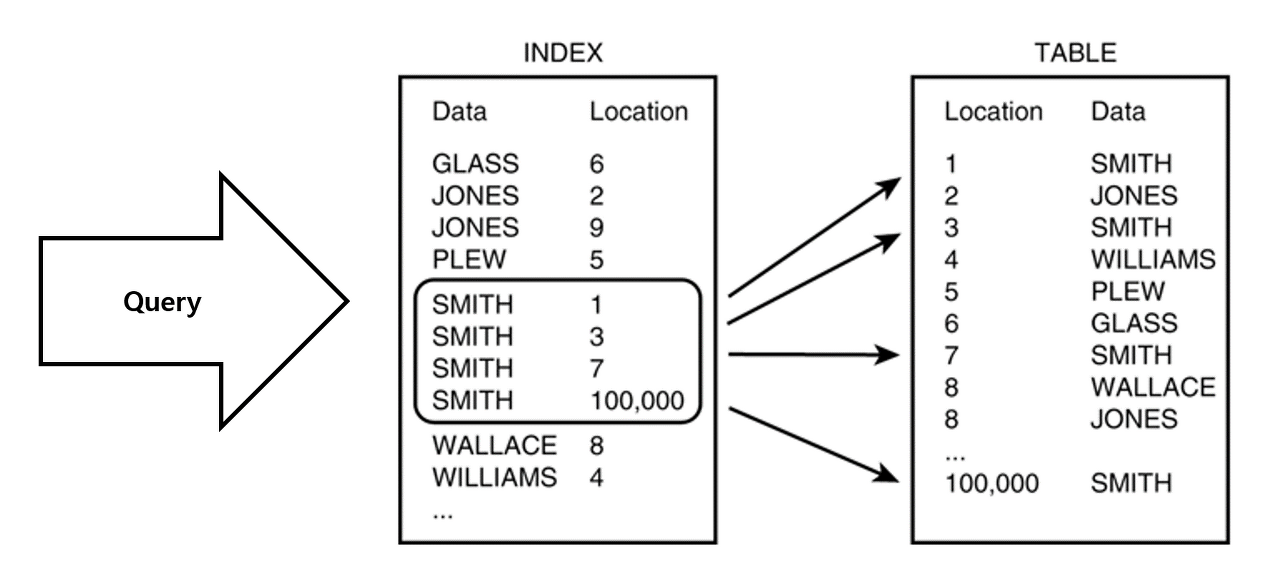
インデックスは、データベースのテーブルに対する検索性能の速度を高める資料構造です。特定のカラムにインデックスを作成すると、該当カラムのデータを並べ替えて別途のメモリ空間にデータの物理アドレスとともに保存されます。 また、インデックス作成時に昇順に整列するため、整列されたアドレス体系と表現することができます。
インデックスを本での目次と考えるとわかりやすいです。 本で望む内容を探す時、目次や索引を利用すればはるかに早く見つけることができるように、テーブルで望むデータを探すためにインデックスを利用すれば早く見つけることができます。 ですから、データ=本の内容、インデックス=本の目次、物理的アドレス=本のページ番号と考えればよいのです。
インデックスの構造
インデックスは様々な構造を利用することができますが、代表的な構造としてハッシュテーブルとB+Treeがあります。
ハッシュテーブル(Hash Table)
ハッシュテーブルは、カラムの値と物理アドレスを(key、value)のペアとして保存する構造です。 しかし、ハッシュ テーブルは実際にはインデックスであまり使用されません。
その理由は、ハッシュテーブルは等号(=)演算に最適化されているからです。 データベースでは不等号(<,>)演算がよく使われるが、ハッシュテーブル内のデータは整列されていないため、特定の基準より大きいか小さい値を早い時間内に見つけることができません。
B+Tree
B+Treeは、ほとんどのDBMS、特にオラクルで重点的に使用している最も普遍的なインデックスです。 構造はRoot Node(基準)/Branch Node(中間)/Leaf Node(末端)で構成され、階層的構造を持っています。
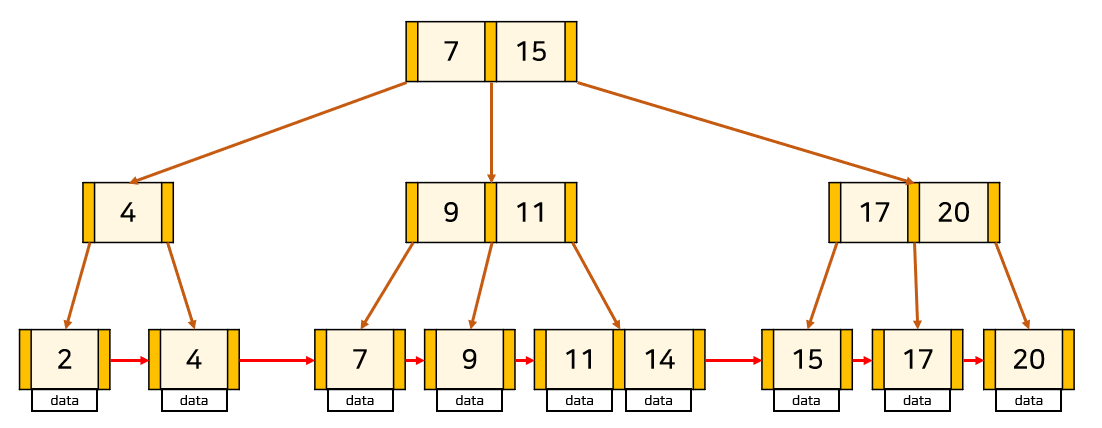
- Nodeはデータが存在する空間です。
- Leaf Nodeだけがインデックス(Key)と共にデータ(Value)を持っており、残りのRoot NodeとBranch Nodeはデータのためのインデックス(Key)だけを持っています。
- Leaf Nodeにのみデータを保存し、Leaf Node同士がLinked Listに接続されているため、線形時間が消耗して時間効率が上がります。
- Root Nodeで経路を確認した後、それに適したNodeに移動して最終的に希望するデータがあるLeaf Noteに到達します。
インデックスのメリットとデメリット
インデックスを使用する理由
データがソートされているため、テーブルでの検索とソート速度を向上します。
- 条件検索Where節の効率性
Where節を使用する際に特定の条件に合ったデータを探すためにデータを最初から最後まで比較しなければなりませんが、インデックスを通じてデータが整列されていれば、早く見つけることができます。 - 整列Orderby定義効率性
インデックスを使用するとOrderbyによるSort過程を避けることができます。 本来、Order by は非常に負荷がかかる作業のため、インデックスを通じて既に整列されていれば負荷がかからない可能性があります。 - MIN、MAXの効率的な処理が可能
これもインデックスを通じてデータが整列されているため、最初から最後まで探しているのではなく、インデックスで整列されたデータからMIN、MAXを効率的に抽出することができます。
インデックスを使用すると、テーブル行の固有性を強化できます。
システム全体の負荷を軽減できます。
インデックス使用時の注意点
インデックスの最大の問題は、並べ替えられた状態を維持し続ける必要があることです。
インデックスが適用されたカラムに整列を変更させるINSERT、UPDATE、DELETEコマンドが実行されると、整列し続け、それに伴う負荷が発生します。 このような負荷を最小限に抑えるために、インデックスはデータ削除という概念でインデックスを使用しません。
- INSERT: 新しいデータに対するインデックスを追加します。
- DELETE: 削除するデータのインデックスを使用しないという作業を進めます。
- UPDATE: 既存のインデックスを無効にし、更新されたデータに対してインデックスを追加します。
インデックススキャンが必ずしも良いわけではありません。
検索を中心とするテーブルにインデックスを生成するのが良いが、無条件にインデックスが検索に良いわけではない。 たとえば、1 つのデータがあるテーブルと、100 万のデータが入っているテーブルがあるとします。 100万個のデータが入っているテーブルならフルスキャンよりはインデックススキャンが有利ですが、1個のデータが入っているテーブルはエクデックススキャンよりフルスキャンの方が早いです。
スピードアップのためにインデックスをたくさん作るのは良くありません。
インデックスを管理するには、データベースの約 10% に相当するストレージ容量が追加で必要です。 そのため、インデックスを作成しすぎると、1 つのクエリ文をすばやく作成できますが、代わりに全体的なデータベースのパフォーマンス負荷をもたらします。 そのため、無条件のインデックス作成よりもSQL文を効率的に組み込み、インデックス作成は最後の手段として使用する必要があります。
Discussion