ADKでローカルLLMを使う: Agent作成と評価まで
概要
- Google Agent Development Kit (ADK)を使って、AIエージェントを実行、評価する方法を試す。
- エージェントの実行はWebUIからもできるが、ここではPythonコードから実行する方法も紹介する。
- エージェントの評価については、WebUIから評価セットを作成し、実行する方法を紹介する。
Google Agent Development Kitとは
AIエージェントの開発とデプロイのためのフレームワーク。
GeminiやGoogle Cloudに最適化されてはいるが、他社のLLMを利用したり、Google Cloud以外の環境でも実行できる。
幅広いAIエージェントアーキテクチャ(直列、並列、ループ、カスタム)に対応している。
Google Agent Development Kitの特徴
他のAIエージェントフレームワーク(CrewAIやAutoGenなど)との違いとして、以下の機能があることがあげられる。
- WebUI経由でのエージェント実行
- エージェントの評価
Python Quickstart for ADK
以下を参考にクイックスタートをやってみる。
まずは開発環境を構築する。
uv init .
uv add google-adk
次にエージェントのテンプレートを作成。
uv run adk create my_agent
my_agent/
├── .env
├── __init__.py
└── agent.py
from google.adk.agents.llm_agent import Agent
root_agent = Agent(
model='<FILL_IN_MODEL>',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
modelにローカルLLMを設定
ADKでGemini以外のLLMを使いたい場合は、LiteLLMを使ってモデルを指定できる。
今回はLM Studioで立ち上げたgpt-oss-20bを使う。
import os
from google.adk.agents.llm_agent import Agent
from google.adk.models.lite_llm import LiteLlm
os.environ["LM_STUDIO_API_BASE"] = "http://127.0.0.1:1234/v1"
root_agent = Agent(
model=LiteLlm(model="lm_studio/gpt-oss-20b"),
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
adk web --port 8000
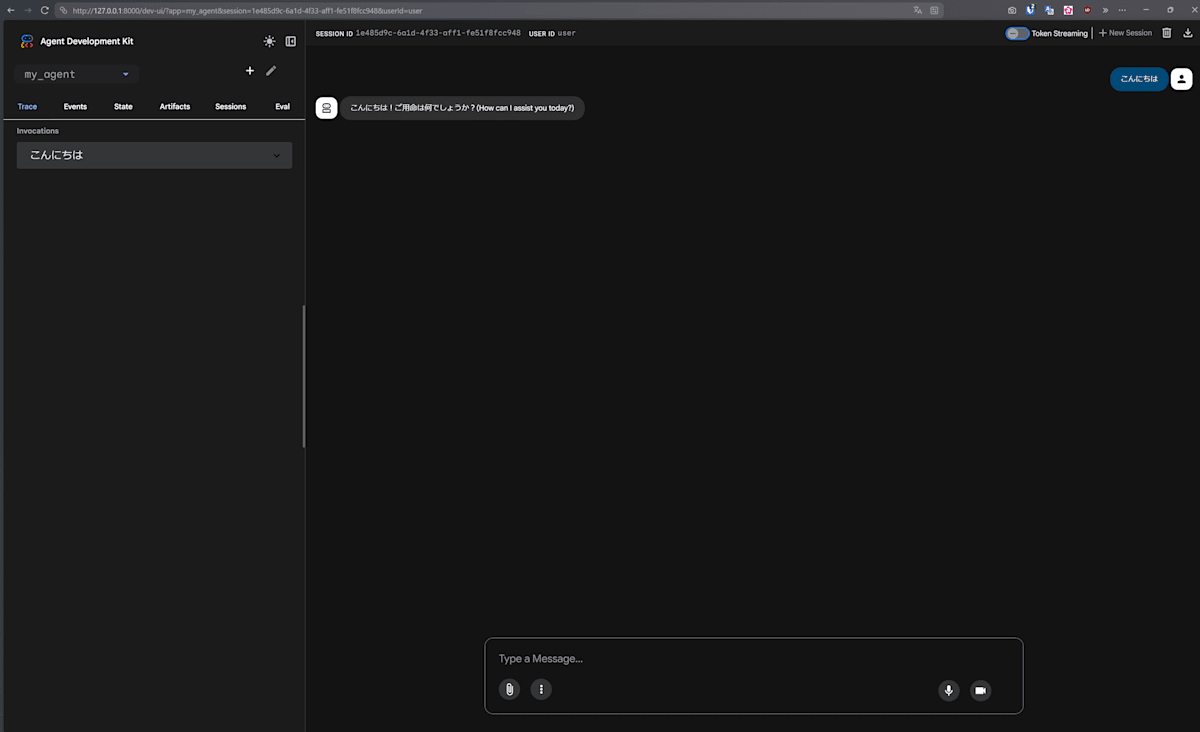
エージェントをアプリケーションとして実行する
App, Runnerクラスを使えば、先ほど作成したエージェントをPythonスクリプト上で呼び出して実行できる。
import asyncio
from google.adk.apps import App
from google.adk.runners import InMemoryRunner
from my_agent.agent import root_agent
# Appクラスのオブジェクトを作成
# root_agent: App起動時に最初にクエリを受け取るエージェント
app = App(name="app", root_agent=root_agent)
# Runnerクラスのオブジェクトを作成
# app: 実行するAppオブジェクト
runner = InMemoryRunner(app=app)
async def main():
await runner.run_debug("こんにちは")
if __name__ == "__main__":
asyncio.run(main())
> python main.py
### Created new session: debug_session_id
User > こんにちは
root_agent > こんにちは!ご質問やお手伝いしたいことがあれば、遠慮なくどうぞ。
(Appのnameは本来任意の文字列が設定できるはずだが、"agents"以外を指定すると警告が出るバグがある[1]。)
run_debug()は、Appの実行に必要なセットアップを内部的に行ってくれている(Sessionの生成など)。
Sessionとは
- ユーザとエージェント間のやり取りの単位。
- やり取りの中でエージェントが行った出力、動作など(Event)の時系列データを含む。
- Sessionごとに一時的なデータ(State)を保持できる。
参考:
- Introduction to Conversational Context: Session, State, and Memory:
https://google.github.io/adk-docs/sessions/ - Session: Tracking Individual Conversations
https://google.github.io/adk-docs/sessions/session/
あくまでデバッグ用なので、実際のアプリケーションとして動かすにはrun()かrun_async()を使う。
from google.genai.types import Content, Part
...
async def main():
user_id = "user_id_1"
session = await runner.session_service.create_session(
app_name="agents", user_id=user_id
)
input = "こんにちは"
content = Content(role="user", parts=[Part.from_text(text=input)])
print(f"User: {input}")
async for event in runner.run_async(
user_id=user_id, session_id=session.id, new_message=content
):
if event.content and event.content.parts and event.content.parts[0].text:
print(f"{event.author}: {event.content.parts[0].text}")
> python main.py
User: こんにちは
root_agent: こんにちは!今日はどんなご質問がありますか?お手伝いできることがあれば教えてくださいね。
エージェントの評価
エージェントの最終的な出力に至るまでの軌跡(trajectory)と、エージェントの最終的な出力の両方を評価できる仕組みが提供されている。
Evalsetというファイルを作成して、その中に以下の項目を記載する。
- user_content
エージェントへのユーザーの入力 - intermediate_data
- tool_uses
期待するツール使用の軌跡。どの順番でどのツールを使ったかを検証できる - intermediate_responses
期待するエージェントの中間出力。マルチエージェントアーキテクチャでサブエージェントが出力した内容を検証するために使う
- tool_uses
- final_response
期待するエージェントの最終出力
Evalsetファイルのフォーマットの参考資料
サンプル
入力項目
評価対象のエージェントの作成
以下のようなエージェントを作成する。
...
instruction = """\
「hello」と言われたら、必ず「hi!」と返答してください。
それ以外のことを言われたら、「すみません、私は'hello'にしか返答できません。」と出力してください。\
"""
root_agent = Agent(
model=LiteLlm(model="lm_studio/gpt-oss-20b"),
name="root_agent",
description="ユーザの挨拶に応えるエージェント",
instruction=instruction,
)
以下の2点が期待通りに動作するかを評価する。
- ユーザが「hello」と言ったときに「hi!」と返答する
- それ以外の挨拶に対しては「すみません、私は'hello'にしか返答できません。」と返答する
Evalsetの作成と評価の実行
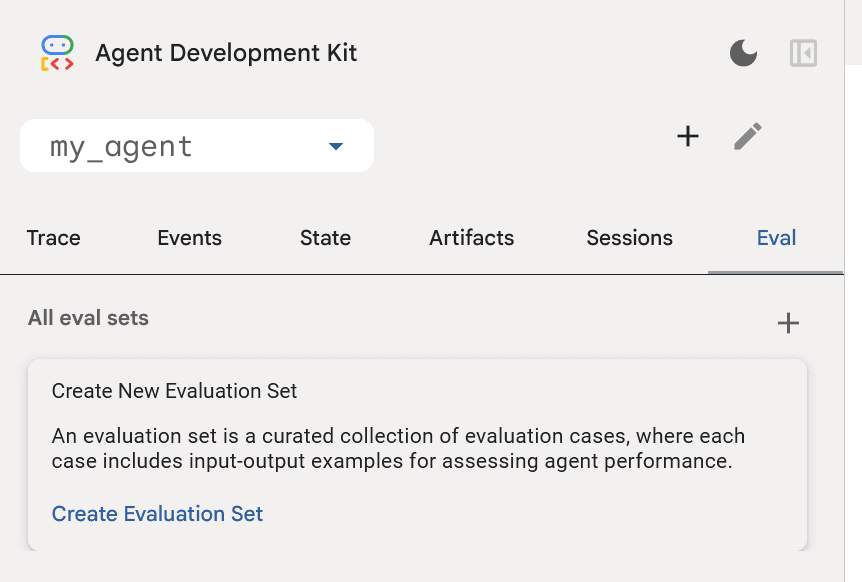
マルチターンのテストや複数のセッションのテストを手動で作成するのは手間がかかるため、WebUI上からテストファイルを作成、評価を実行する機能がある(前述のフォーマットにもとづいて手動でEvalsetファイルを作成、編集することも可能)。
サイドバーの「Eval」タブをクリックし、「Create Evaluation Set」ボタンを押して評価セットを作成。
新しいセッションを開始して、エージェントとやり取りを行い、「Add current session to <Evalsetlの名前>」を押すと、やり取りの内容がEvalsetに追加される。以下では2つのやり取りを追加。
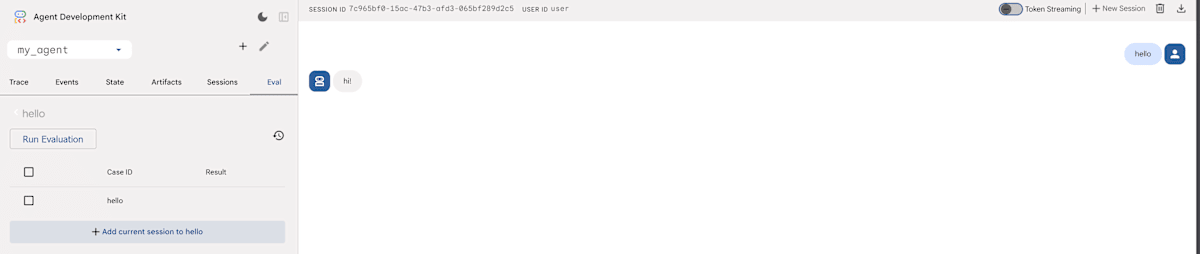
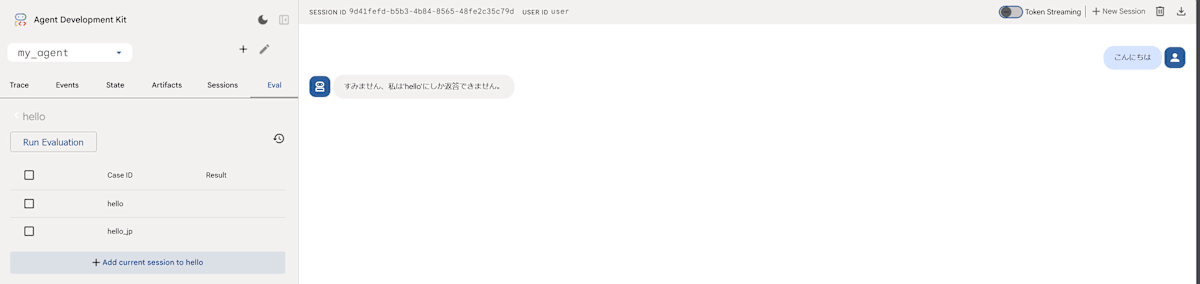
Evalsetファイルの内容
{
"eval_set_id": "hello",
"name": "hello",
"eval_cases": [
{
"eval_id": "hello",
"conversation": [
{
"invocation_id": "e-a73cf3e9-46c7-4689-b5aa-e0e0dc39230e",
"user_content": {
"parts": [
{
"text": "hello"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "hi!"
}
],
"role": "model"
},
"intermediate_data": {},
"creation_timestamp": 1765003739.630076
}
],
"session_input": {
"app_name": "my_agent",
"user_id": "user"
},
"creation_timestamp": 1765003748.0300913
},
{
"eval_id": "hello_jp",
"conversation": [
{
"invocation_id": "e-21e5701f-be50-4d24-a5c4-d129da6fc015",
"user_content": {
"parts": [
{
"text": "こんにちは"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "すみません、私は'hello'にしか返答できません。"
}
],
"role": "model"
},
"intermediate_data": {},
"creation_timestamp": 1765003766.184129
}
],
"session_input": {
"app_name": "my_agent",
"user_id": "user"
},
"creation_timestamp": 1765003780.640022
}
],
"creation_timestamp": 1765003718.7195678
}
実行したいテストケースにチェックを入れて「Run Evaluation」をクリック。
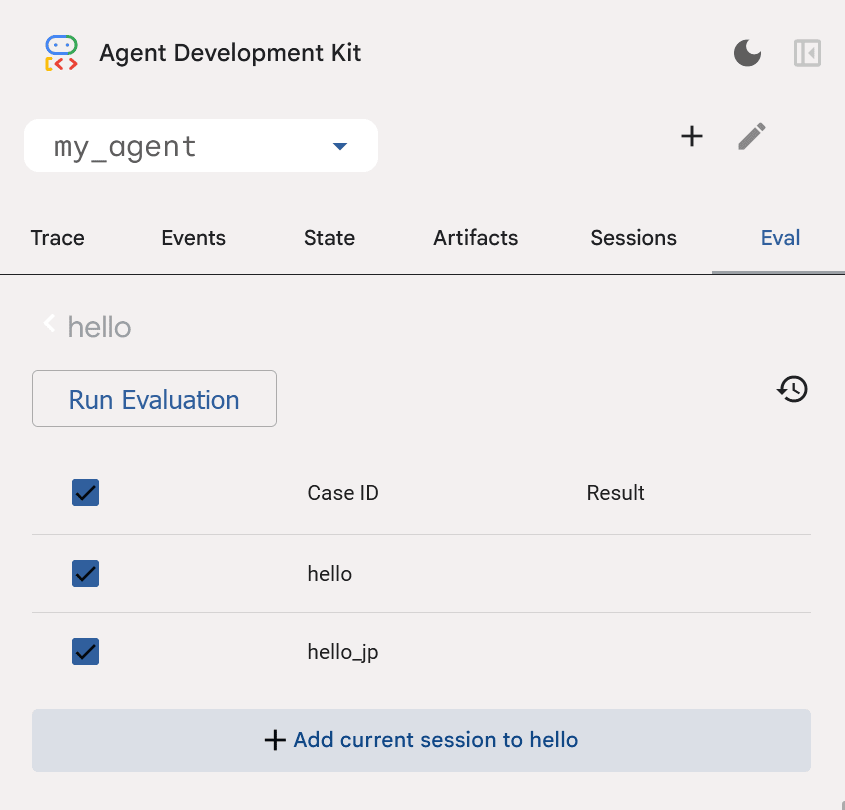
評価指標の閾値を設定する画面が出てくるので、適当に設定して「Start」をクリック。
「Response match score」ではROUGE-1スコアが利用されている。

利用可能な評価指標
バージョン1.19.0時点ではWebUI上だと、ツール使用の軌跡と最終応答それぞれ固定の評価指標しか選択できないが、実際には何種類か用意されており、adk cliやpytestからの実行なら指定できる。
ただし、2025/11/30現在、日本語で出力された内容を柔軟に評価することは難しそう。
- 理由1: LLM-as-a-Judgeは現状Geminiしかサポートしてない。
https://github.com/google/adk-python/issues/3400 - 理由2: ROUGE-1スコアのデフォルトトークナイザでは日本語をトークン化できない。
https://github.com/google/adk-python/blob/0094eea3cadf5fe2e960cc558e467dd2131de1b7/src/google/adk/evaluation/final_response_match_v1.py#L128
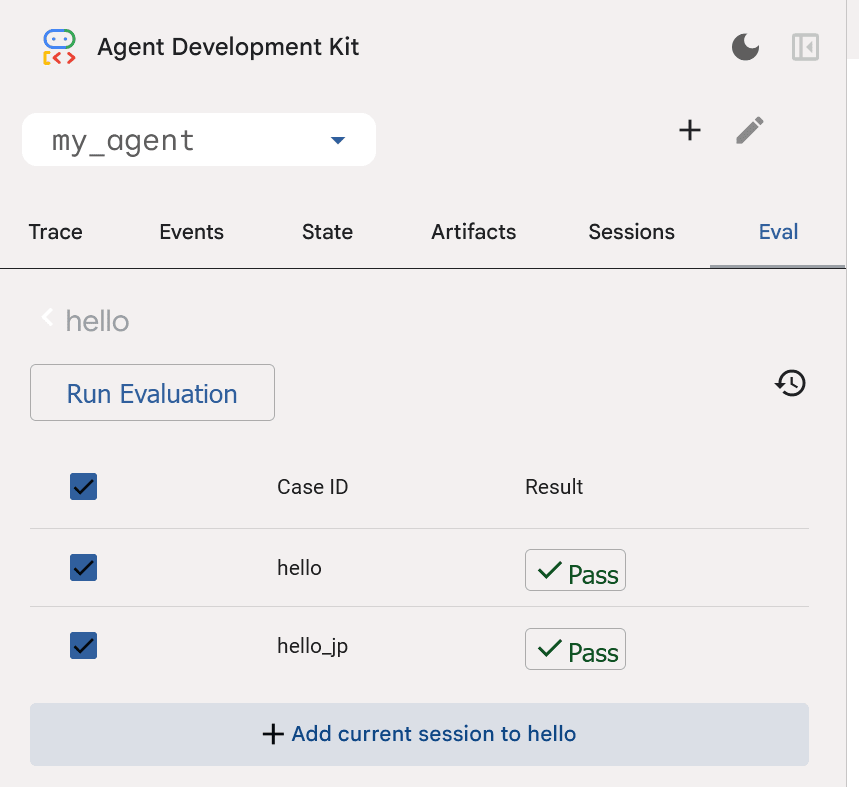
試しに、片方のテストが失敗するようにエージェントへの指示を変更して、改めて評価を実行してみる。
instruction = """\
「hello」と言われたら、必ず「hi!」と返答してください。
「こんにちは」と言われたら、必ず「hi!」と返答してください。
それ以外のことを言われたら、「すみません、私は'hello'にしか返答できません。」と出力してください。\
"""
2行目の指示を追加した。期待する返答は「すみません、私は'hello'にしか返答できません。」だが、実際には「hi!」と返答するようになったためテストに失敗するようになった。

Discussion