オブザーバビリティについてまとめる
僕が開発していた小さいWebアプリで問題が発生したとき、クラウドが提供してくれる基本的なメトリクスやログから原因を特定して解決しました。そのWebアプリは少ないコンポーネントで構成されていたため、あまり大変ではありませんでした。しかし、複数のコンポーネントが複雑に絡み合っているようなWebアプリで、単純なメトリクスやログから原因を特定するのは大変そうだと感じました。そういったWebアプリの問題の原因を特定するには、深い知識や経験が求められるため、簡単に行えるものではないと思います。
世の中のサービスはどうしているんだろうと調べていると、どうやらオブザーバビリティというものが関わっていそうでした。シンプルなモニタリングでは原因の調査に深い知識が必要ですが、オブザーバビリティを向上させると事前知識無しで原因の調査が行えるようでした。
この投稿は、オブザーバビリティについて自分の理解のためにまとめたものです。
オブザーバビリティとは
オブザバービリティとは、システムで何が起こっているかを把握する能力のことです。オブザーバビリティは能力のことなので、低い状態から高い状態まで存在します。クラウドサービスでは基本的なメトリクスは表示できることが多いので、オブザーバビリティが0ということは滅多にないと思います。また、オブザーバビリティが100という状況も今の時点では現実的ではありません。あらゆる情報を出力するようになると、情報を保存するコストやパフォーマンスに対するオーバーヘッドが増えてしまうからです。
オブザーバビリティのためのサービスを提供するベンダーでは、オブザーバビリティをどの程度持っているかというオブザーバビリティ習熟度モデルが作られていることが多いです。例えばレベル1~3のように分けられており、各レベルごとにどの程度システムで何が起こっているかを把握できるのかが定められています。このモデルを使用して、サービスにどの程度オブザーバビリティを持たせるのか、そのために何をするべきかを決めることができます。
オブザーバビリティはシステムの内部状況の把握能力なため、システムのライフサイクルの全てのフェーズに関わってきます。例えば、障害対応、パフォーマンスのボトルネックの特定、ユーザー行動の傾向分析によるシステムの改善点の発見などに関わってきます。
モニタリングとオブザーバビリティ
オブザーバビリティと似た文脈でモニタリング (監視)という言葉が使われることもあります。モニタリングとはシステムの振る舞いや出力を観察しチェックし続ける行為のことです。オブザーバビリティは能力のことなので直接比較できるものでは無いと思うのですが、オブザーバビリティとモニタリングの目的が比較されることはよくあります。
モニタリングとオブザーバビリティは目的が異なっており、モニタリングは障害を検出すること、オブザーバビリティは障害を調査することを目的としています。モニタリングは障害が発生した際に様々な出力によって障害を検出することはできますが、その後の原因の発見までをカバーしていません。一方でオブザーバビリティは原因の発見までをカバーしています。モニタリングでは出力された情報をもとに推測を行って原因を見つける必要がありますが、一定のオブザーバビリティを持っている場合には出力された情報のみで原因を発見できるようになります。
また、モニタリングはシステムの状態を事前に定義された閾値と比較して異常を検出するために予測できない障害の対応が難しいのですが、一定のオブザーバビリティを持っていると比較的容易になります。モニタリングは事前に定義された閾値と比較するため、閾値が設定されていない問題を見落とす可能性があります。オブザーバビリティでは詳細なデータを収集することができるため、これに対応できる可能性が高いです。
オブザーバビリティの利点
上述したように、オブザーバビリティはモニタリングにある以下の問題を改善できます。
- 問題の原因を特定するのが難しい
- 予測できない障害の対応が難しい
オブザーバビリティはこれらの障害対応における問題を高カーディナリティと高ディメンションなデータの収集やデータの統合によって改善することができます。カーディナリティはデータセット内の一意の値の数を表し、ディメンション(次元)はデータ内の属性を表します。
高カーディナリティとは、データセット内で一意な値の数が多い状態を指します。ユーザーIDやIPアドレスなどは比較的高いカーディナリティを持っているといえます。高カーディナリティは一般的には詳細度が高いとも言えます。例えばユーザーの年齢を考えたとき、10代や20代という値を持つ属性はカーディナリティが低く、10歳や11歳という値を持つ属性はカーディナリティが高く、詳細なデータと言えます。このように、カーディナリティが高いとデータを詳細に分析することが可能なため、問題の原因を突き止めやすくなります。
高ディメンションとは、データに含まれる属性の数が多い状態を指します。ディメンションとはデータの属性のことをいいます。高ディメンションは一つのデータに様々な観点の情報が含まれていると考えることができるので、データを多角的に分析することが可能になり、問題の原因を突き止めやすくなります。
また、データの統合によって障害対応が更に容易になります。例えばあるデータにIDが含まれている場合、他のデータがそのIDを参照できるようになり、データの統合を行うことができます。これによって複数のデータを関連付け、さらに多角的な分析が可能になります。
このように、高カーディナリティで高ディメンションなデータを収集して探索することで、モニタリングの障害対応における問題は改善することができます。詳細で多角的なデータによって問題の原因を突き止めやすくなったり、予測できなかった問題を発見することができます。
シグナル
オブザーバビリティのためにシステムが出力するデータはシグナルと呼ばれ、いくつかの種類に分類されています。ここまででデータと呼んでいたものはシグナルのことを指しています。
また、このシグナルを生成・収集するための仕組みを実装することを計装といいます。
現時点ではシグナルには主要な3つのシグナルと、その他の2つのシグナルが存在します。主要な3つのシグナルはオブザーバビリティの3本柱と呼ばれることもありますが、3つすべてが必須なわけではなかったり、実際にはシグナル同士の関連も重要なため、別の呼び方も出てきています。
主要なシグナルとしてはメトリクス・ログ・トレースがあり、その他のシグナルとしてはプロファイル・ダンプなどがあります。
メトリクス
メトリクスとは、サービスの実行時に収集された測定値のことで、基本的には時系列データです。例えばCPU使用率、メモリ使用率、ディスクI/O、ネットワークトラフィックなどが該当します。インフラ以外では、リクエスト数、エラーの数、リクエストのレイテンシなどもあります。
メトリクスは名前、ラベルのセット、数値で構成されます。ラベルはメトリクス分析の切り口となるもので、ラベルのキーと値のセットになっており、分析したい切り口によって最適なラベルを決める必要があります。数値は実際の測定値を表しています。
メトリクスには一般的にサポートされる以下の3つのタイプが存在します。
-
ゲージ
- 現在の値を示すメトリクス
- 各種使用率やトラフィックなど
-
カウンター
- 増加する値を示すメトリクス
- リクエストの数やエラーの数など
-
ヒストグラム
- 値の分布を示すメトリクス
- リクエストのレイテンシなど
メトリクスは正しく使用することで、予測可能な障害に対する最も効率の良いシグナルになります。基本的には時系列データなのでトラフィック量の増加に対してシグナルの量が変わらなく、コストの効率が良いです。また、メトリクスは測定値という注目すべき値が明確なため、状況を簡単に把握しやすいという利点があります。
一方で、メトリクスに高カーディナリティのラベルを含めるとデータの肥大化が発生する可能性があるため、コストとそのラベルによる分析の価値のバランスを取る必要があります。
メトリクスの用途としてはアラートや分析があります。メトリクスは測定値を持っているため、事前に設定したしきい値を超えた場合にアラートを出して障害を知らせることができます。また、システムのパフォーマンスや動作の傾向を把握することもできます。
ログ
ログとは、サービスで発生したイベントを記録するものです。ログは、アプリケーションログ、セキュリティログ、システムログ、監査ログ、インフラログなどのカテゴリに分類できます。
ログの形式は特に定められていないのでテキスト形式でもよいのですが、構造化ログはオブザーバビリティを向上させることができます。構造化ログでは、JSONやlogfmt形式のログが一般的に使用されています。ログが構造化されていると機械が解析することが容易なため、オブザーバビリティ向上の役に立ちます。
ログは以下のようなレベルで分類されることが多いです。
-
ERROR
- 障害の発生とその理由の詳細を伝えるメッセージ
- スタックトレースや実行の結果などの問題の診断情報を十分に出力する
-
WARN
- 障害ではないが、注意を必要とするレベルのメッセージ
- 将来なにか問題があった際に見返してほしいメッセージ
-
INFO
- システムがどのように機能するのかを理解するためのメッセージ
- サーバーの起動やリクエストの到着などのメッセージを出力する
-
DEBUG
- デバッグ中に使用されるメッセージ
- プロダクション環境で通常は無効化しておき、問題が起きたときに有効化する
ログは基本的に何でもできるのですが、効率性を考えて他のシグナルと併用する必要があります。例えばサービスで発生するイベントとその詳細をすべてログに出力することで、オブザーバビリティを向上させることができます。しかし、データの量が多くなり、ストレージのコストの増加や検索のパフォーマンスの低下が発生するため、現実的ではありません。
トレース
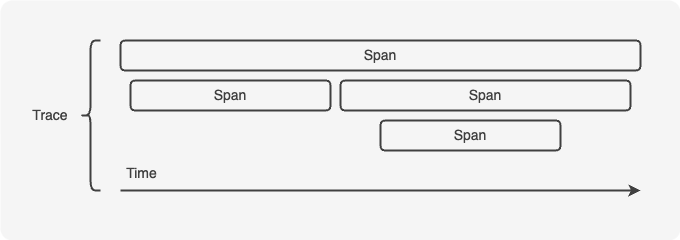
トレースとは、リクエスト処理の全体像をスパンの集合として表現したものです。例えば1つのリクエストで、いつ、どの処理が呼ばれ、どれくらい時間がかかったかをなどを表しています。一つのリクエストの開始と終了までの単位をトレースと呼び、リクエスト内の各操作がスパンとして表現されています。
トレース内のスパンは、トレースID、スパンID、親スパンID、タイムスタンプ、期間などで構成されます。トレースのルートのスパンがトレースIDを作成し、トレース内のスパンで共有します。スパンはネストすることができるので、その場合には親スパンIDを使用します。スパンにはステータスが存在するので、操作にエラーがあったかを確認することもできます。
また、トレースはコンテキストを伝播させることで分散システムのトレーシング (分散トレーシング) を可能にします。トレースのコンテキストはW3Cによって定義されたものが使われることが多く、トレースIDやスパンIDなどをシステム間で伝播させます。
トレースはサンプリングによって必要なトレースだけを収集することができます。これは収集するスパンを制御することになり、コストを削減したりノイズを減らすのに役に立ちます。サンプリングには、確率などによってできるだけ早く判断を行うヘッドサンプリングと、すべてのデータを取得したあとに判断を行うテールサンプリングがあります。
スパンに関連してスパンイベントと呼ばれる、スパンに紐づくログのようなデータも存在します。後述するシグナルの相関でも少し触れるのですが、ログにはトレースIDやスパンIDを含めることができ、このスパンイベントにもそれらを含めることができます。
スパンイベントはログと違い、トレースのサンプリングの恩恵を受けることができます。例えばサンプリングによってトレースが収集されなかった場合、そこに含まれるスパンイベントも収集されないため、コストの削減につながるかもしれません。
トレースを使用することによって、サービス内で遅延が発生している処理をより詳細に把握することができます。例えば関数呼び出しごとにスパンが作成されている場合には、遅延が発生している関数を具体的に把握できます。
その他のシグナル
主要なシグナル以外にも、プロファイルとダンプというシグナルも存在します。
プロファイルは、サービスの実行中に収集された詳細なデータのことです。このデータを使用して、メトリクスで示されるCPU使用率やメモリ使用率などの原因をより詳細に把握することができるようになります。そのためにはプロファイルを継続して収集する必要があり、昔はオーバーヘッドが大きいと考えられていたのですが、サンプリングという仕組みによって少ないオーバーヘッドで収集することができます。
ダンプは、サービスがクラッシュした際のメモリの内容を記録したものです。クラウドネイティブな環境ではOSの設定へのアクセスが制限されるため、ダンプの収集が難しくなっています。
シグナルの相関
オブザーバビリティ向上のためには、目的に応じて収集されたシグナル同士を関連付けて連携させる事が重要であり、その連携状態のことをシグナルの相関 (Signal Correlation) と呼びます。
各シグナルはそれぞれの目的に特化しており、一つのシグナルであらゆる状況をカバーしようとすると無駄にコストがかかるため、相関が重要になってきます。メトリクスはトラフィック量に影響を受けない計測に使うのは良いのですが、詳細なデータを取得しようとするとカーディナリティが高すぎてデータが増えてコストがかかります。ログやトレースのスパンイベントは基本的にトラフィック量が増えるとデータが増えるため、トラフィック量に影響を受けない計測に使うと無駄なコストがかかります。また、その他のシグナルは目的外の利用が難しいです。
シグナルを相関させるためには、関連付けたいシグナルを示すメタデータをシグナルに含める必要があります。例えばログとトレースでは、ログにトレースやスパンのIDを埋め込むことで相関させることができます。一方で、集約されたメトリクスやログには膨大な数のシグナルが含まれている可能性があります。異常なメトリクスからトレースやログを取得することは需要が高いのですが、コストの面で特定の時点のシグナルをすべて含めることはできないため、代表的なシグナルを含めることが多く、このシグナルをエグザンプラー (exemplar)と呼びます。
より基本的な相関を持たせるために、同じターゲット(同じアプリなど)からのシグナルをまとめるためのターゲットメタデータがあり、これとタイムスタンプを合わせて大まかに連携させることもできます。例えばターゲットメタデータとしてはcluster、environment、pod、container_nameなどがあります。これとタイムスタンプを合わせることで、特定の時間の範囲に発生したシグナルを相関させることができます。
シグナルの相関によって、事前知識に頼らずに客観的なデータに基づいて根本原因の調査を行う、第一原理からのデバッグができるようになります。例えば、異常なメトリクスを発見した後に、相関しているトレースを取得して遅延やエラーのある操作を特定できます。更に詳細を知るために、トレースやスパンに紐づくログを見ることもできます。このようにシグナルが相関していると、シグナルの情報だけから根本原因を突き止められる可能性が上がります。
第一原理からのデバッグのためには、可視化ツールも重要になってきます。すべてのシグナルを統合して表示できる可視化ツールがないと、シグナルが相関していても辿るのが難しくなります。
OpenTelemetry
OpenTelemetryとは、オブザーバビリティ向上のためのフレームワークやツールキットです。これには、ベンダーに依存しないシグナルのデータモデルと処理方式の仕様や、その実装であるライブラリなどが提供されています。
オブザーバビリティ向上のためにシグナルとその相関は重要なのですが、オブザーバビリティツールが独自でそれらの仕様を決めていると、ベンダーロックインが発生します。各シグナルで別のツールを使っている場合に連携や可視化が手間になったり、ツールの移行も難しくなります。
そういった問題を解決するためにOpenTelemetryがあります。OpenTelemetryではメトリクス、ログ、トレースなどの主要なシグナルと相関の仕様などが決められているため、連携がそこまで手間にはなりません。また、OpenTelemetryに対応しているツールであれば移行も容易になります。
OpenTelemetryはAPIとSDKという主要なコンポーネントで構成されており、この分離によって柔軟な計装が可能になります。APIは計装のためのインターフェースであり、トレースの開始やスパンの作成、メトリクスの記録など、計装を行うための統一的な方法を提供します。一方で、SDKはAPIの具体的な実装を担い、シグナルを処理・収集して外部のツールに送信する役割を果たします。例えばライブラリ開発者がAPIにだけ依存することで、ライブラリの使用者がアプリに最適な設定でSDKを使用でき、柔軟な計装が可能になります。
さいごに
オブザーバビリティについてまとめました。
オブザーバビリティを向上させると、客観的なデータのみに基づいて根本原因の調査が行えるようになることがわかりました。また、そのためには各シグナルの相関や可視化ツールが重要であることも理解できました。モニタリングだけでは複雑なアプリケーションの原因を調査することが難しいので、世の中のサービスはオブザーバビリティを向上させて第一原理からのデバッグを行えるようにしているんだろうなぁと思っています。
この投稿がオブザーバビリティの概要の理解の助けになることを願っています。
Discussion