


初めまして、Hugkunでエンジニアアルバイトをしているもぐもぐです。今回はHugkunとちゅらデータのチームでCVPR2023のAutonomous driving challengeに参加したので、その振り返りを書きます。
CVPRとは

CVPR(Conference on Computer Vision and Pattern Recognition)とは、コンピュータビジョンやパターン認識に関する世界トップレベルのカンファレンスです。2023年はカナダで開催されます。
どんなコンペに参加したのか
今回取り組んだのはこちらのtrack3 3D Occupancy Predictionです。
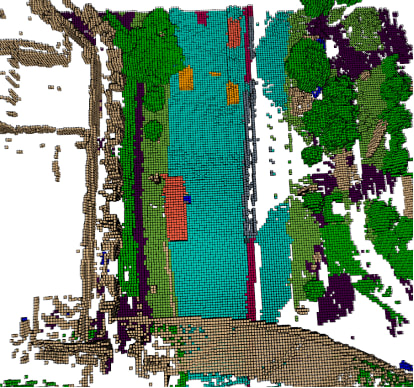
複数のカメラ画像の入力から、3D voxelのセマンティックセグメンテーションを行うというタスクです。下の画像はボクセルを可視化したもので、今回はこのようにボクセルごとにクラスを予測していきます。クラスは全部で18種類あり、何も物体がない場合、つまりvoxelが空であるという意味の"free"というクラスも含まれます。
取り組んだこと(時系列順)
ベースラインを動かす
まず初めに提供されているベースラインのコードを動かしてみることにしました。しかし、ベースラインのBEVFormerのモデルではGPUのメモリサイズが足りず、動かすことができませんでした。そのため、少し小さいサイズのモデルであるBEVFormer-smallを動かすことにしました。
まずはこちらで提供されているv1.0-miniという小さいデータセットで試してみました。学習は7~8時間くらいで終わったのですが、mIoUは8.23しかありませんでした。
次にフルデータセット(miniの80倍くらいのデータ数)で試してみました。すると、なんと学習が終わるまでに13日もかかってしまいました。(ちょうどGW期間だったのでGW中ずっと学習させていました!)
ベースラインは8台のGPUを使って学習させることを想定されていたため、私たちのRTX3090 1台ではかなりの時間がかかってしまうということがわかりました。
また、InternImageをバックボーンとしたモデルも公開されたのですが、そちらは32日かかる見込みだったため使用しないことになりました。
学習回数を増やすために
BEVFormer-smallでフルデータセットを学習させると1回の学習で13日もかかってしまうため、何とか1~2日で学習が終わるようにできないかと考えました。学習が短い時間で終わると、色々なAugmentationを試すことができるからです。mIoU改善に有効なAugmentationを見つけて、最後に大きいモデルで学習させるという計画でした。
学習を早く終わらせるため、もう一段階小さいモデルであるBEVFormer-tinyを使用することにし、フルデータセットとミニデータセットの中間のデータ数を持つデータセットを作成しました。これらの学習は2日くらいで終わるようになりました。しかし、かなりmIoUが下がってしまったため、別の方法を探すことになりました。
TPVFormerを使用してみる
24GBのメモリサイズでも動かせるいい感じのモデルを探していたところ、TPVFormerが24GBで動くという情報を見つけました。早速使ってみることにしたのですが、コンペのアノテーションに合わせると、モデルサイズが大きくなってしまったのか、残念ながら学習ができませんでした。
BEVDet4Dを使用してみる
TPVFormerがダメだったので、次はBEVDet4Dを使用することにしました。(BEVDetはdockerで環境構築されているのですが、全て清華大学のページからダウンロードするように設定されているため、日本から使用する場合はその部分を削除した方が早く終わります。)
BEVDet4DのOccupancyモデルは4種類あったのですが、学習時間の関係でBEVDet-Occ-R50-4D-Stereo-2xという一番小さいモデルを採用することになりました。最終的に、こちらのモデルを使って推論させたものを提出することになりました。
時間的には結構ぎりぎりで、コンペ最終日の2日前にやっとベースラインのmIoUを超えることができました。
使用したモデルについて
BEVFormer
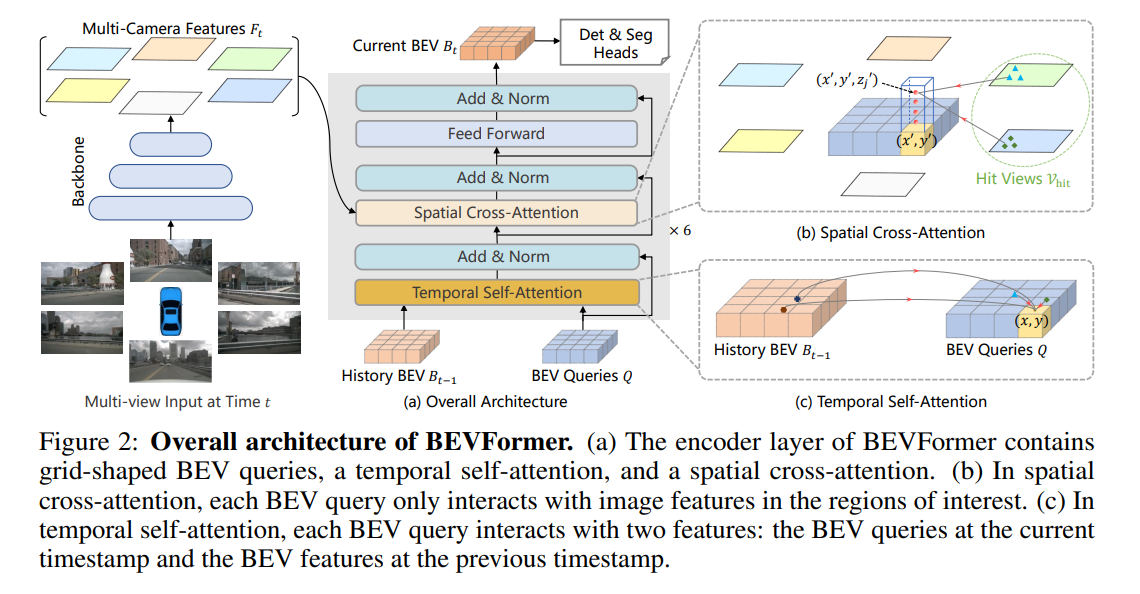
BEVFormerは複数カメラの画像から、BEV(Bird's Eye View)を構築し、物体検出やマップセグメンテーションを行います。BEVFormerは時間情報と空間情報を考慮して推論を行います。複数カメラから空間情報を集約するために、Spatial Cross-Attentionが用いられています。時間情報については、過去のBEV情報を再帰的に融合するTemporal Self-Attentionが用いられています。
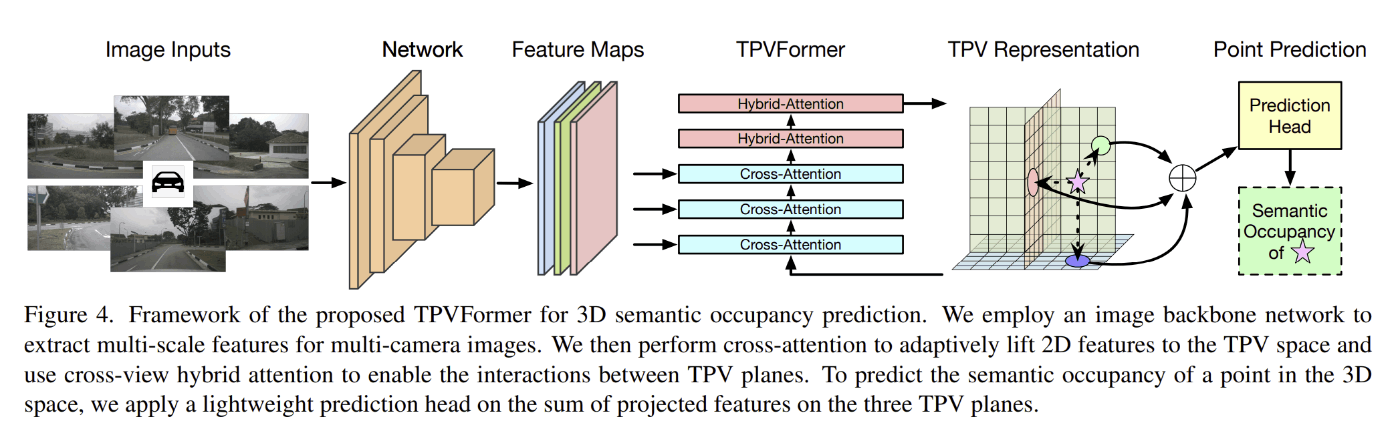
TPVFormer
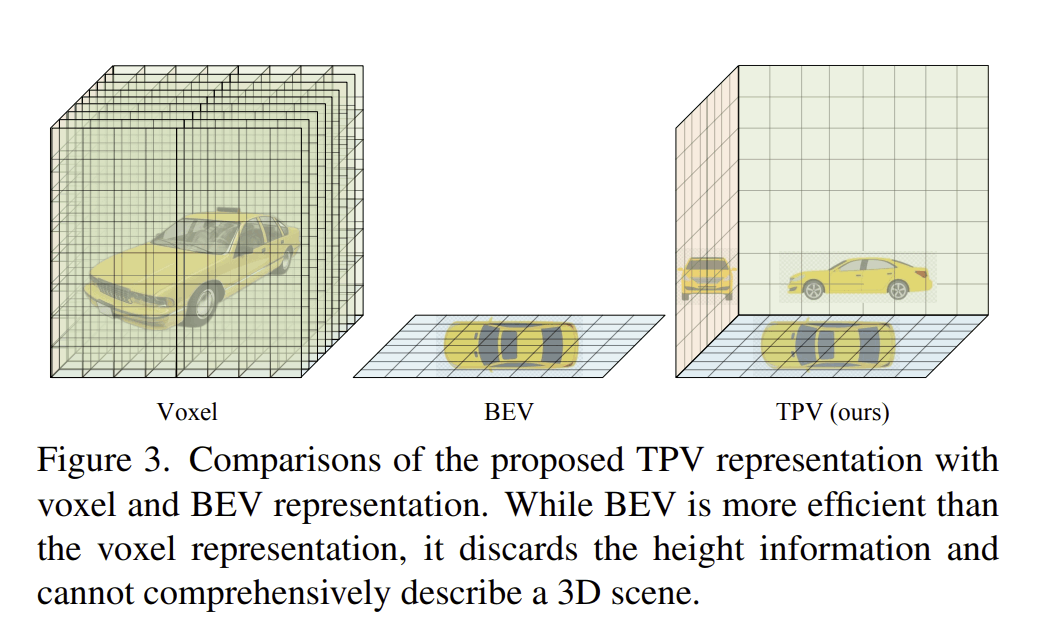
BEV表現だとZ座標の値を捨ててしまっているという問題点があり、Voxel表現だと計算量が多いという問題があります。そのため、BEVに2つの平面を加えたTri Perspective View(TPV)を提案しています。Voxelの計算量がO(HWD)なのに対して、TPVではO(HW+DH+WD)となります。
TPVFormerはimage backbone networkで複数のカメラ画像から特徴を取り出した後、cross-view hybrid attentionと image cross-attentionからなるhybrid-cross-attention blockを数回繰り返します。その後、cross-view hybrid attentionのみからなる hybrid-attention
blockを数回繰り返すことで、TPV特徴を取り出しています。
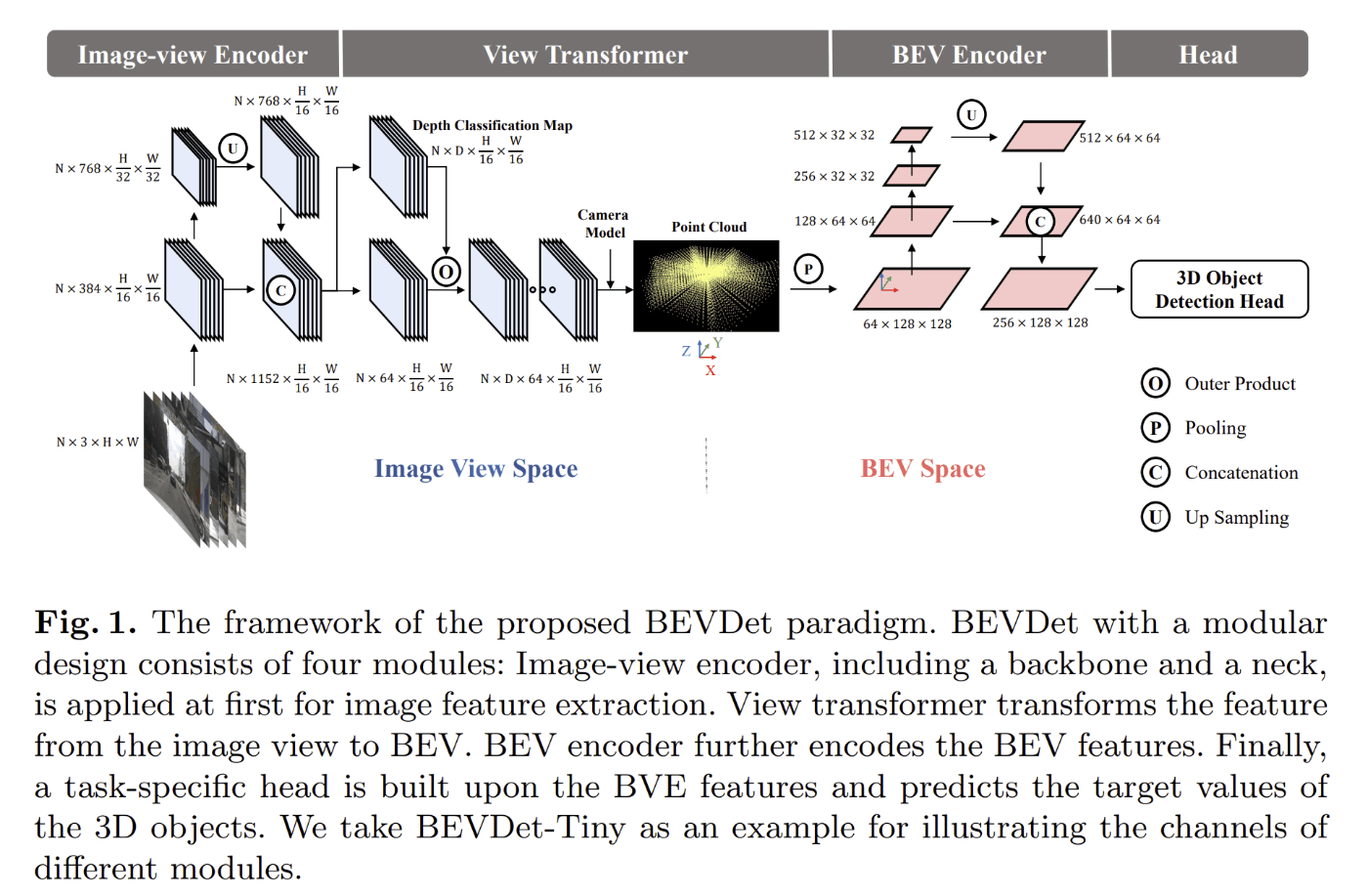
BEVDet
BEVDetはImage-view Encoder、View Transformer、BEV Encoder、Headという4つの構造でできています。
Image-view Encoderは画像から特徴を求めている部分で、そこで抽出した特徴から、View TransformerでBEVを構築します。BEV Encoderでは、BEV空間でさらに特徴を抽出しており、この特徴量を使用して、物体検出やマップセグメンテーションのタスクを行います。データ拡張としては、反転、スケーリング、回転などが行われています。
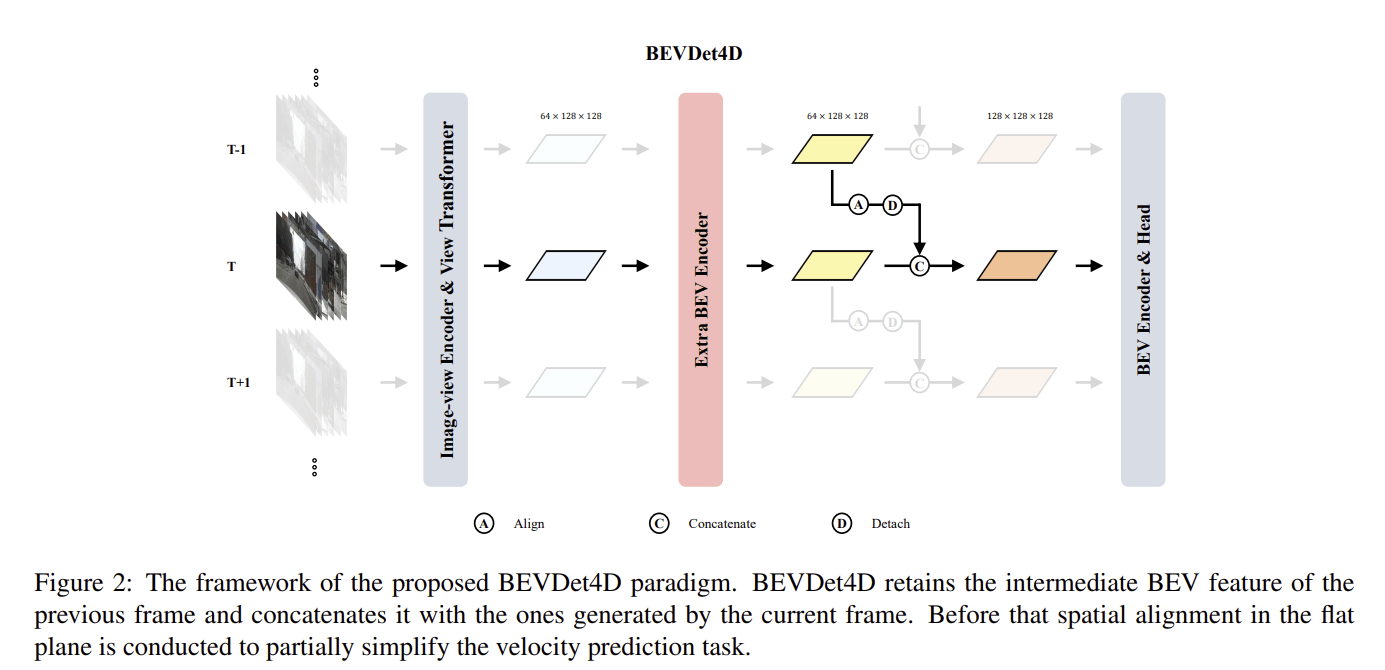
BEVDet4D
3次元の空間情報しか持たなかったBEVDetに対し、時間情報をもつように拡張したものです。1つ前のBEV特徴を現在のBEV特徴と統合することで時間情報を組み込んでいます。
苦戦したこと
RTX3090 1台で学習できるモデルサイズで短い時間で学習できるものを探すのに時間がかかりました。また、GPUメモリが足りなくて
RuntimeError: CUDA out of memory.
というエラーが出た際は
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:200
のように指定して動かすと動く場合もあるので、試してみても良いかもしれません。
また、ご存知の方も多いかもしれませんが、モデルを探す際にはpapers with codeが参考になりました。
時間があったら取り組みたかったこと
今回は時間の関係上、モデルを動かして、コンペの提出フォーマットで出力するよう変更することしかできませんでした。もっと時間があったらAugmentationなどにも取り組みたかったです。
例えば、BEVDet4Dでは、入力画像の回転や反転、スケーリングが行われていますが、明るさ、彩度、露光、コントラストなどは変動させていません。そのため、それらを変動させてみて、mIoUが改善するかどうか試してみたかったです。
おわりに
最終的には順位は41/48位という残念な結果になってしまいました(順位表)。
しかし、最初はベースラインのスコアも超えられないのではないかと思っていたので、ベースラインのスコアを超えられたときはとてもうれしかったです。また、別のコンペにも参加してみたいです!
Discussion