無限の可能性を引き出す!Kubernetesクラスタ拡張入門
この記事について
Kubernetesはコンテナオーケストレーションを行うためのOSSツールです。
OSSであることからベンダに縛られることなく、AWSやGoogle Cloud, Azureといったパブリッククラウド、果てにはオンプレやそのハイブリッド環境まで、Kubernetesをホストし動作させる環境は要件に応じて自由に選ぶことができます。
クラスタをどこにホスティングするかは人それぞれであり、求められる様々なネットワーク・ハードウェア・クラウドベンダ要件に応じてクラスタの設定をカスタマイズする必要が出てきますが、Kubernetesはそんな様々な環境に適応できるようにするための拡張機能がところどころに用意されています。
また、「クラスタにおけるリソースの数や設定を、applyされたマニフェストファイルで宣言された状態に保ち続ける」というKubernetesのエコシステムを、PodやServiceといったKubernetesに元から用意されたリソースだけではなく、自ら定義したカスタムリソースに対しても適用させるような拡張も実は可能です。
このように、Kubernetesというツールはかなり高い拡張性を持っています。
本記事では、Kubernetesに用意されている主たる拡張機能を紹介し、クラスタに対して我々がどのようなカスタマイズを施すことが可能なのかをお見せします。
使用する環境・バージョン
- 執筆時におけるKubernetes最新バージョン(v1.33)の情報をもとに記述
読者に要求する前提知識
-
Kubernetesのアーキテクチャがわかっていること
- 以下の用語は説明なしに使います
- kube-api-server
- kubelet
- scheduler
- Node
- 以下の用語は説明なしに使います
- 基礎的なKubernetesのオブジェクトを知っていること
- Pod, Deployment, LoadBalancer, Ingress, PersistentVolume, ServiceAccountなど
- kubectlやhelmを使ったマニフェストファイルapplyの流れをわかっていること
kubeletに加えるカスタマイズ
ここからは、Kubernetesクラスタに加えることができるカスタマイズ種別を紹介していきます。
方法は様々ですが、まずはNode上にデーモンとして動くkubelet設定を調整することで行うカスタマイズ手法について触れていきます。
Container Runtime
ワーカーノード上に稼働しているkubeletは、コントロールプレーンから常々「こんなPodを立ち上げて」「このPodを終了させて」といった命令を受け取ることになります。
その命令を実行するために、kubeletはノード内で稼働しているコンテナランタイムに対してコンテナの作成・開始・停止・削除といったコンテナライフサイクル管理操作をリクエストすることになります。
世の中にはいくつかのコンテナランタイムが存在するため、Kubernetesクラスタ管理者は自クラスタでどのランタイムを利用するかを選択し構築することになります。
- containerd: Dockerから分離したプロジェクトであるDockerとの互換性が高い
- cri-o: KubernetesのCRIに準拠した軽量なコンテナランタイム
以下にcontainerd / cri-oそれぞれのランタイムでKubernetesクラスタを構築するコマンド概要を示します。
# 例1: containerdの場合
## container runtimeのインストール & 起動
$ sudo apt-get install -y containerd.io
$ sudo mkdir -p /etc/containerd
$ sudo containerd config default | sudo tee /etc/containerd/config.toml
$ sudo systemctl restart containerd
## Kubernetesクラスタの起動
$ sudo kubeadm [init/join] --cri-socket=/run/containerd/containerd.sock
# 例2: cri-oの場合
## container runtimeのインストール & 起動
$ sudo apt-get install cri-o cri-o-runc
$ sudo systemctl start crio
## Kubernetesクラスタの起動
$ sudo kubeadm [init/join] --cri-socket=/var/run/crio/crio.sock
Kubernetesを動作させるNode上でどのようなコンテナランタイムが動作していたとしても問題なくkubeletが役割を果たすために、kubelet - コンテナランタイム間で行われるやりとりはContainer Runtime Interface (CRI)という規格で標準化されています。
そのため、CRIを満たすように作られたコンテナランタイムなのであれば、例外なくKubernetesを動作させることができます。言い方を変えると、CRIによってKubernetesは個別のコンテナランタイムへの依存を引き剥がすことができたのです。
CNI Plugin (Container Network Interface Plugin)
The Kubernetes network modelにて規定された、Kubernetesクラスタが満たさなければならないネットワーク要件には以下のようなものがあります。
- 各Podがクラスタ内で一意のIPアドレスを持ち、同一Podに属するコンテナ同士はlocalhostで通信可能
- クラスタ内のPodはNATを介することなく、割り当てられたIPアドレスを用いて直接通信可能
- システムデーモンやkubeletのようなNode上のエージェントは、同一Node内にあるすべてのPodと通信可能
kubeletがPodを立ち上げるときには、これらKubernetesのネットワーク要件を満たすようIPアドレスの割り振りが行われます。
しかしここでポイントとなるのは、この要件を満たすための内部実装が決まっているわけではないということです。
例えば、AWS上にホストしているKubernetesクラスタとオンプレでホストしているKubernetesクラスタではこれら要件の実現方法が異なってくるでしょう。これら異なる環境での動作保証をするために、Kubernetesとしてネットワークの統一実装を提供しているわけではないのです。
このIPアドレスの払い出し、および当該IPをうまく使えるようにホストNodeを設定するなど、Podネットワークの具体実装を担うのがCNI Plugin(Container Network Interface Plugin)と呼ばれるプラグインです。
各クラスタの管理者は、自クラスタのホスティング条件および使用用途に一番適切なCNI Pluginを選択して導入することになります。
具体的には、例えば以下のようなCNI Pluginが存在します。
-
AWS VPC CNI:
- EKSクラスタで標準導入されているCNI Plugin
- クラスタがホストされているVPCのCIDR範囲内からPodにIPアドレスを割り振る[1]
-
Azure vNET CNI:
- クラスタがホストされているvNETのCIDR範囲内からPodにIPアドレスを割り振る
-
Flannel CNI:
- 一つのKubernetesクラスタ内で、XVLANをバックエンドに用いたL2 overlayネットワークを構築することでPod間通信要件を実現する
- 異なるノード上にあるPod同士が通信する際は、VXLAN(UDP8472番)でパケットをカプセル化してパケットを送受信する
- Network Policyに未対応
-
Calico CNI:
- BGPを用いて異なるノード間で経路情報を交換し、1つのKubernetesクラスタ内でのPod間通信を疎通させる
- Network Policyに対応
-
Cilium CNI:
- eBPFを用いてパケット送受信時にフィルタリング・Network Policyの適用といった処理を挿入する
CNI Pluginの導入は、kubeletの実行オプションを適切に設定することで実現します。
$ kubelet \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin
ここで設定しているオプションの中で重要なのは以下の2つです。
-
cni-conf-dir: CNI Pluginの設定ファイルを配置するディレクトリ -
cni-bin-dir: CNI Pluginのプログラムバイナリを配置するディレクトリ
kubeletの起動オプションで指定したこの2つのディレクトリ配下に、CNI Pluginを適切に配置することで導入ができるようになります。
例えばFlannel CNIを導入する場合、以下のようにマニフェストファイルをapplyします。
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
このマニフェストファイルapplyによってDaemonSetやConfigMapがデプロイされます。
DaemonSet Pod内にはCNI Plugin実体が含まれており、これらがホストNodeのcni-conf-dirとcni-bin-dirにマウントされることによって、適切にプラグイン資源が配置されるという仕組みです。
ちなみに、どのようなCNI Pluginを用いたとしても問題なくKubernetesが動作するのは、kubeletとCNI Plugin間のやりとりがContainer Network Interface(CNI)という規格で標準化されているからです。
Image Credential Provider
kubeletがPodを起動する際に、Podを構成するコンテナイメージがDocker Hubのようなパブリックレジストリ内に存在するのであれば何ら不都合は生まれません。
しかし、ECRやACRのようなプライベートレジストリ上にあるコンテナイメージを利用するPodなのであれば、kubeletはPodを起動するためにはそれらプライベートレジストリからイメージをpullする権限を持つ必要があります。
これを実現するための仕組みがImage Credential Providerです。これを導入することによって、特定のURLのコンテナイメージを利用する際にはイメージpullに必要なクレデンシャルを取得する前処理が自動で入るようになります。
具体的には以下のようなProviderが存在します。
Image Credential Providerの導入は、kubeletの実行オプションを適切に設定することで実現します。
まず、Image Credential Providerの設定を書いたConfigファイルを以下のように記述し、ノード内の/etc/kubernetes/image-credential-provider/config.yamlに配置します。[2]
# (例) ECRからのイメージpull権限を取得する設定
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
providers:
- name: ecr-credential-provider
matchImages:
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
defaultCacheDuration: "12h"
apiVersion: credentialprovider.kubelet.k8s.io/v1
次に、AWS Credential ProviderのページからProviderバイナリをビルドし、それをノード内の/opt/kubernetes/image-credential-provider/bin/ecr-credential-providerに配置します。
そして最後に、これらの設定を利用するようにkubeletの起動オプションを変更します。
$ kubelet \
--image-credential-provider-config=/etc/kubernetes/image-credential-provider/config.yaml \
--image-credential-provider-bin-dir=/opt/kubernetes/image-credential-provider/bin
Device Plugins
ワークロードによっては、特定ベンダのGPUやNIC、FPGAをPodに割り当てたいという場合もあるかと思います。
Podコンテナ作成時に行われるそれらの特殊デバイスの割り当て要求を処理するためのプラグインがDevice Pluginです。
代表的なDevice Pluginを以下に示します。Kubernetesの公式Docにはこれ以外にも様々なプラグインが紹介されています。
- NVIDIA device plugin for Kubernetes
- AMD GPU Device Plugin for Kubernetes
- SR-IOV Network Device Plugin for Kubernetes
Device Plugin導入前に、まず各ベンダデバイス特有のセットアップをNode上で行う必要があります。GPUやGPUドライバが載っていないNode上でGPU Device Pluginのみを導入したところで正しく動作しないといえばイメージできるかと思います。
どのようなセットアップが必要になるのかは扱うデバイスごとにそれぞれです。PluginのPrerequisitesとして記述されていることが多いかと思いますので、そこを参照すると良いでしょう。
オーソドックスなDevice Pluginですと、各クラウドベンダーがそれに対応したインスタンスイメージを提供してくれていることもありますので、そのNodeを用いてクラスタを構成すると一番簡単です。
例えば、NVIDIA device plugin for Kubernetesを使おうとすると、PrerequisitesとしてNVIDIA driversとnvidia-container-runtimeが必要になります。AWSではこれをあらかじめ含んでいるAMIをMarketplaceで提供しています。
Podコンテナ作成時にこれらプラグイン経由で特殊デバイスを調達するのはkubeletの役割です。
kubeletが認識して扱うことができるDevice Pluginの設定は/var/lib/kubelet/device-pluginsディレクトリ直下にまとめられることになっています。
ホストNodeの/var/lib/kubelet/device-pluginsディレクトリ直下に必要な設定ファイルを配置させるようなDaemonSetマニフェストファイルを各プラグインが用意していることが多いので、これをapplyすることでプラグイン導入を行います。
# (例) NVIDIA device plugin for Kubernetesのインストール
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
ちなみに、どのようなCNI Pluginを用いたとしても問題なくKubernetesが動作するのは、kubeletとDevice Plugin間のやりとりがgRPCインターフェースとして標準化されているからです。すべてのDevice Pluginは、Kubernetesで定義されたこの決められたインターフェースを満たすように実装されています。
また、kubeletによるPod作成処理を深ぼっていくと、コンテナランタイムが特殊デバイスをコンテナにアタッチする処理に辿り着きます。
このとき、デバイスドライバの違いによらずコンテナランタイムがそれらのリソースを扱うことができるのは、コンテナランタイムとデバイスドライバ間のやりとりがContainer Device Interface(CDI)という規格で標準化されているからです。
kube-schedulerに加えるカスタマイズ
次に、スケジューラーに対して行えるカスタマイズ手法について紹介します。
プラグインのon/off
Kubernetesにおけるスケジューラーは、クラスタ上で作成されたPodをどのNode上で動かすのかを決める役割を果たしています。スケジューラーによってPodを動かすNodeが確定した後、それを検知したアサイン先Nodeのkubeletが実際にPodコンテナを作成するという流れです。
このPod-Node間のマッピングロジックは、以下のステップに分解して理解することができます。
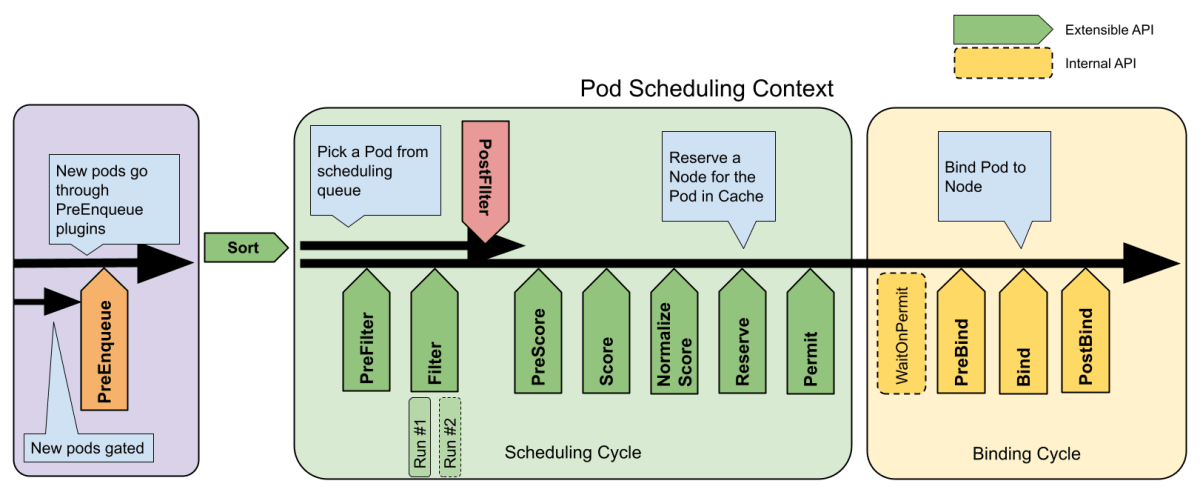
主たるステップはFilterとScoreです。
- Filter: Podを実行することが不可能なNodeを検知して、Pod割り当て先の候補から外す
- Score: Pod割り当て先の候補となっているNodeに対して、決められた判断基準で点数をつける (一番高得点なNodeにPodが配置される)
このフィルタ基準やスコアリング基準を、自分たちの機能要件に応じてカスタマイズしたいということも十分考えられます。
このようなカスタマイズ要望に応えるために、Kubernetesにはスケジューラープラグインというものが用意されており、有効・無効をコントロールできるようになっています。
デフォルトで組み込まれているプラグインのうち、代表的なものをいくつか例示します。デフォルトプラグインの全量はこちらでご確認ください。
- ImageLocality: Podが実行するコンテナイメージを既に持っているNodeに優先してPodを配置するようにスコアリングする
- EBSLimits: NodeのAWSのEBSボリューム制限を満たすかどうかをチェックして、満たさない場合は割り当て先候補から外す
- NodePorts: 要求されたPodのポートに対して、Nodeが空きポートを持っているかチェックして、満たさない場合は割り当て先候補から外す
- NodeResourcesBalancedAllocation: よりバランスの取れたリソース使用量となるNodeにPodを優先的に配置する
スケジューラープラグインの有効・無効を調整するためには、まずKubeSchedulerConfigurationのフォーマットでConfigファイルを記述します。
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: non-multipoint-scheduler
plugins:
score:
enabled:
- name: NodeAffinity
disabled:
- name: PodTopologySpread
filter:
enabled:
- name: NodeAffinity
このConfigファイルのパスを指定しながらkube-schedulerを起動することで、プラグインのon/offを指定することができるようになります。
$ kube-scheduler --config [上記configファイルのパス]
自作プラグイン/自作スケジューラーの利用
Kubernetesで用意されたデフォルトのプラグインでは実現できないようなPodのスケジューリングを行いたい場合もあるかと思います。
その場合には、自作のプラグインを組み込んだスケジューラーを作ることになります。
デフォルトスケジューラーのコードはKubernetesのGitHubレポジトリの中にあり、エントリポイントはcmd/kube-scheduler/app/server.goに存在します。
func main() {
command := app.NewSchedulerCommand()
code := cli.Run(command)
os.Exit(code)
}
プラグインそのものをどのように実装するかについては割愛しますが、このエントリポイント部分にWithPluginメソッドを用いて自作プラグインをスケジューラーに組み込みます。
func main() {
- command := app.NewSchedulerCommand()
+ command := app.NewSchedulerCommand(
+ app.WithPlugin(/* 自作プラグインをここで指定 */)
+ )
code := cli.Run(command)
os.Exit(code)
}
このソースコードをビルドしてコンテナ化して、クラスタにDeploymentとしてデプロイします。
# (一部抜粋)
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-kube-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 1
template:
metadata:
labels:
component: scheduler
tier: control-plane
spec:
serviceAccountName: my-scheduler
containers:
- command:
# 自作プラグインを有効化するKubeSchedulerConfigurationを指定
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
# 自作スケジューラーイメージを指定
image: gcr.io/my-gcp-project/my-kube-scheduler:1.0
name: kube-second-scheduler
ソースコード出典: Kubernetes公式ドキュメント - 複数のスケジューラーを設定する
こうすることで、自作プラグインが入ったスケジューラーをクラスタ上で動かすことができます。
このスケジューラーを用いてPodをスケジューリングしたい場合は、Podマニフェストファイル上のschedulerNameフィールドにスケジューラー名を指定します。
apiVersion: v1
kind: Pod
spec:
schedulerName: my-kube-scheduler # 自作スケジューラーを指定
containers:
- name: my-pod
image: my-image
マニフェストファイルのデプロイで加えるカスタマイズ
次は、マニフェストファイルのapplyによって適用できるプラグイン・カスタマイズを紹介します。
CSI Driver (Container Storage Interface Driver)
Podに永続ストレージを割り当てたい場合、PersistentVolume(PV)をデプロイすることになります。
HostPathとしてホストノードの特定のパスをマウントすることやNFSサーバーをマウントすることはKubernetesネイティブの機能としてサポートされています。
# HostPathを利用する例
apiVersion: v1
kind: PersistentVolume
metadata:
name: hostpath-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /mnt/data
---
# NFSサーバーを利用する例
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
path: /data
server: nfs-server.example.com
しかし、AWS環境上でホストしているクラスタにおいてEFSをマウントしたい・Azure上でホストしているクラスタにおいてAzure Diskをマウントしたいといった場合には話が異なります。
特定のストレージプロバイダーに特化した実装はKubernetes組み込みでは入っていないため、これら固有のボリュームを扱えるようにするためにはCSI Driver(Container Storage Interface Driver)を介することになります。
具体的には、以下のようなものがあります。
- Amazon Elastic Block Store (EBS) CSI driver
- Amazon EFS CSI Driver
- Amazon FSx for Lustre CSI Driver
- Mountpoint for Amazon S3 CSI Driver
- Azure Disk CSI Driver
- Azure File CSI Driver
- Azure Blob Storage CSI Driver
- The Google Compute Engine Persistent Disk (GCE PD) CSI Plugin
- The Google Cloud Filestore CSI Plugin
CSI DriverのインストールはマニフェストファイルやHelm Chartのデプロイで完結して行われることが多いです。
# (例1) Amazon EFS CSI Driverの場合
$ helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver
$ helm install aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver
# (例2) Azure Disk CSI Driverの場合
$ helm repo add azuredisk-csi-driver https://raw.githubusercontent.com/kubernetes-sigs/azuredisk-csi-driver/master/charts
$ helm install azuredisk-csi-driver azuredisk-csi-driver/azuredisk-csi-driver
このドライバインストールを行った上で、以下のようにStorageClass・PersistentVolumeClaim(PVC)をデプロイすると、EBSをバックグラウンドとしたPVが動的に作成されるようになります。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-sc
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-claim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
storageClassName: ebs-sc
resources:
requests:
storage: 4Gi
また、このような動的PV作成時にkubeletはストレージプロバイダーからボリュームを作成・削除、コンテナにボリュームをアタッチ・デタッチなどの作業を行っています。
どのストレージプロバイダーが相手だったとしても問題なくこれらのストレージ管理処理を行えるように、kubeletとCSI Driver間のやりとりがCSI(Container Storage Interface)という規格で標準化されています。
LoadBalancer Controller
Kubernetesでは、LoadBalancerリソースをデプロイすることでL4レベルでのトラフィック分散を実現することができるようになります。
ですが、何の準備もなくLoadBalancerをただデプロイしただけではこのような仕組みが構築されることはありません。
各環境・各クラスタごとに「LoadBalancerオブジェクトがデプロイされたことを検知して、その裏側でLoadBalancerに対応する適したインフラリソースを作成する」ための仕組みを導入する必要があり、この機構のことをControllerといいます。
Kubernetesにおいて、コントローラーはクラスターの状態を監視し、必要に応じて変更を加えたり要求したりする制御ループです。それぞれのコントローラーは現在のクラスターの状態を望ましい状態に近づけるように動作します。
出典: Kubernetes公式Doc - コントローラー
特にLoad Balancerリソースを扱うControllerのことをLoadBalancer Controllerと呼びます。
LoadBalancer Controllerとして、具体的には以下のようなものがあります。
- AWS Load Balancer Controller: LoadBalancerをデプロイしたときにNLBをデプロイする
- Cloud Provider Azure: LoadBalancerをデプロイしたときにAzure Load BalancerをデプロイするControllerを含んでいる
Controllerの実態は、当該機能を持たせたコンテナをDeploymentとして動かしているというものが多いです。そのため、Controllerのインストール自体もmanifestファイルのデプロイやHelmチャートのデプロイで完結させられることが多いです。
# (例) Cloud Provider Azureのインストール
$ helm install \
--repo https://raw.githubusercontent.com/kubernetes-sigs/cloud-provider-azure/master/helm/repo cloud-provider-azure \
--generate-name \
--set cloudControllerManager.imageRepository=mcr.microsoft.com/oss/kubernetes \
--set cloudControllerManager.imageName=azure-cloud-controller-manager \
--set cloudNodeManager.imageRepository=mcr.microsoft.com/oss/kubernetes \
--set cloudNodeManager.imageName=azure-cloud-node-manager
Ingress Controller
Ingressリソースをデプロイすることで、L7レベルでのトラフィック分散を実現することができるようになります。
ですがIngressリソースもLoadBalancerと同様に、Ingress Controllerをインストールしないと対応する実物インフラリソースが作られることはありません。
Ingressリソースに関するControllerとして代表的なものを列挙します。
- AWS Load Balancer Controller: IngressをデプロイしたときにALBをデプロイする
- Application Gateway Ingress Controller: IngressをデプロイしたときにAGWをデプロイする
- GLBC: IngressをデプロイしたときにCloud Load Balancingをデプロイする
- Ingress NGINX Controller: Ingressをデプロイすると、L7で負荷分散をするnginx Podがデプロイされる
# (例) AWS Load Balancer Controllerのインストール
$ helm repo add eks https://aws.github.io/eks-charts
$ helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=<cluster-name> \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller
Kubernetesの公式Docには、他にもIngress Controllerが数多く紹介されているので、興味のある方はこちらからご覧ください。
Gateway Controller
LoadBalancer, Ingressに続くサービス公開方式として、Gateway APIが2023年10月にGAを迎えました。
これによりGatewayClass, Gateway, HTTPRouteという3つのリソースが追加されたわけですが、これらGateway API配下リソースを扱う Gateway API Controllerも各クラウドベンダが用意し始めています。
-
AWS Gateway API Controller for VPC Lattice
- GatewayにはVPC Lattice Service Networkを対応づける
- HTTPRouteにはVPC Lattice Serviceを対応づける
- GKE Gateway Controller
# (例) AWS Gateway API Controllerのインストール
$ helm install gateway-api-controller \
oci://public.ecr.aws/aws-application-networking-k8s/aws-gateway-controller-chart \
--version=v1.1.0 \
--set=serviceAccount.create=false \
--namespace aws-application-networking-system \
--set=log.level=info
Kubernetes Operator
Kubernetesでは、PodやDeploymentといったリソースがマニフェストファイルのデプロイで作成されるとそれをControllerが検知し、マニフェストで定義された状態になるようにリソースの作成・削除といった処理が行われるようになっています。
PodやVolumeといった元々Kubernetesで定義されたリソース以外にも、Custom Resource(CR)と呼ばれる自作リソースを定義し、そのCRのデプロイ管理も上述のKubernetesの仕組みに則って行われるようにクラスタを拡張することができます。
このような拡張のやり方はOperatorパターンと呼ばれています。
具体的には、
- ArgoCDのApplication
- cert-managerのCertificate, Issuer, CertificateRequestなど
が該当します。
これらがカスタムリソースとしてKubernetesのオブジェクトとなることによって、ArgoCDでデプロイするアプリケーションや、cert-managerで発行するTLS証明書の作成・削除もマニフェストのapply/deleteで管理できるようになるのです。
OperatorHub.ioには多くのOperatorが公開されているので、Kubernetesの仕組みで管理したいリソースのOperatorがないかどうか探してみるのもいいでしょう。
Kubernetes Operatorの仕組みに載せる自作リソースを作るためには、以下が必要です。
- Custom Resource Definition(CRD)
- CRのController
ここからは、Custom ResourceであるFooをクラスタ上で扱えるようにするための手順を紹介します。
まず、自作のCRであるFooの定義を記述したCRDを作成します。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
# for more information on the below annotation, please see
# https://github.com/kubernetes/enhancements/blob/master/keps/sig-api-machinery/2337-k8s.io-group-protection/README.md
annotations:
"api-approved.kubernetes.io": "unapproved, experimental-only; please get an approval from Kubernetes API reviewers if you're trying to develop a CRD in the *.k8s.io or *.kubernetes.io groups"
spec:
group: samplecontroller.k8s.io
versions:
- name: v1alpha1
served: true
storage: true
schema:
# schema used for validation
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
deploymentName:
type: string
replicas:
type: integer
minimum: 1
maximum: 10
status:
type: object
properties:
availableReplicas:
type: integer
names:
kind: Foo
plural: foos
scope: Namespaced
コード出典: https://github.com/kubernetes/sample-controller/blob/master/artifacts/examples/crd.yaml
次に、FooリソースがKubernetes上で作成されたことを検知して、それに対応する実インフラリソースをデプロイするカスタムControllerを作成します。
カスタムControllerのソースコードの書き方自体は、多くのフレームワークがあるため省略します。
kubernetes/sample-controllerに、今回のFooリソース用のController実装があるため、興味のある方はこちらをご覧ください。
実用的には、このControllerをコンテナイメージの形にビルドし、Deploymentとしてクラスタにデプロイすることが多いと思います。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-controller
spec:
selector:
matchLabels:
app: foo-controller
replicas: 1
template:
metadata:
labels:
app: foo-controller
spec:
containers:
- name: foo-controller
image: foo-controller-image:latest
CRDとカスタムControllerの2つをapplyすることによって、以下のようなFooリソースをKubernetesクラスタ内でデプロイして扱うことができるようになります。
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 1
コード出典: https://github.com/kubernetes/sample-controller/blob/master/artifacts/examples/example-foo.yaml
その他の方式
最後に、上記パターンのいずれにも当てはまらないカスタムについて紹介します。
Podへの権限割り当て
各パブリッククラウド上でクラスタをホスティングしているのであれば、Podの中から各種クラウドサービスを扱うためのIAM権限/RBAC権限を渡したいとなるかと思います。
Kubernetes APIにアクセスするための権限を制御するためにはサービスアカウントを使うわけですが、クラスタ外部の一般のAPIへの権限付与はどのようにすればいいでしょうか。
この課題に対しては、各クラウドベンダが「Kubernetesのサービスアカウントと自クラウドAPIの権限主体を紐付ける」ための仕組みを用意していることが多いです。
- IAM Roles for Service Account(IRSA)
-
Amazon EKS Pod Identity
- KubernetesのサービスアカウントとAWSのIAM Roleの紐付けを行う
- Workload Identity Federation for GKE
- KubernetesのサービスアカウントとGoogle CloudのIAM Service Accountの紐付けを行う
-
Azure AD Workload Identity
- KubernetesのサービスアカウントとAzure EntraIDアプリケーションの紐付けを行う
まとめ
というわけで、Kubernetesクラスタに組み込める様々なカスタマイズ・プラグインとその導入方法イメージについてご紹介しました。
かなり幅広いことができるため、これらをすべて一から自分でセットアップするということはほとんどないと思います。[3]
とはいえ、Kubernetesの特徴がこの拡張性の高さだと思っているので、この記事を読んだ皆様にもそれが具体性を持って伝わるといいなと思いますし、もしもデフォルトの挙動では実現できない!という要件にぶつかったときに、これを思い出してクラスタカスタマイズしてみよう!という発想に辿り着ける方が増えたら嬉しいです。
-
そのため、AWS VPC CNIを導入したAWS上のKubernetesクラスタは、Node NetworkとPod Networkが同一のものとなります。 ↩︎
-
参考: https://kubernetes.io/docs/tasks/administer-cluster/kubelet-credential-provider/ ↩︎
-
ここをベンダ特有環境に合わせていい感じにセットアップし、さらにそれらプラグインのメンテナンスまでやってくれるのが各クラウドベンダーが提供しているマネージドKubernetes(AWSだとEKS, AzureだとAKS, Google CloudだとGKE)の良さだったりします。 ↩︎
Discussion