ここさえ抑えればGitHub API v4がわかる! GraphQL入門
この記事について
今年の7/27にGitHub Projectベータと呼ばれていたものがGAになりました。
新しくGAになったProject(以下ProjectV2と書きます)は、
- フィールドを用いて、アイテムに様々なメタデータを追加できる
- カードに設定した様々なメタデータごとにかんばんを作ることができる
- アイテムのグループ化・ソート・フィルタが簡単にできる
- 日付・各種メタデータを軸として指定したグラフを作ることができるので可視化が簡単
といった、classic Projectではできなかったあれこれが一つのProjectでできるようになっており、とても便利になりました。
そしてProjectV2がGAした今、一部例外を除いてclassic Projectを新規作成するというのはできなくなっています。
そのため、ProjectV2への移行というのは今後どんどん進んでいくと思われます。
You can only create a new classic project board for an organization, user, or repository that already has at least one classic project board.
If you're unable to create a classic project board, create a project board instead.(訳) 既に一つ以上のclassic projectを所有しているOrganization・ユーザー・レポジトリでのみ、Organization所有・ユーザー所有・レポジトリ所有のclassic projectを新規に作成することができます。
もしこれらの条件に該当しない場合には、ProjectV2を作成してください。
しかし、ProjectV2を操作するためのAPIエンドポイントは、RESTで提供されているGitHub API v3には用意されておらず、GraphQLで提供されているAPI v4にしか備わっていません。
ProjectV2への自動起票や、プログラムを用いてProjectV2上にあるアイテムの集計・操作を行いたいという場合には、必然的にGraphQLを理解し、使いこなす必要があります。
とはいえ、GraphQLというのはRESTに比べるとまだまだマイナーなAPIです。
そのため、「ProjectV2に移行したはいいものの / classic Projectが作れなかったのでProjectV2を作ったが、GraphQLの使い方がわからないから各種自動化ができない」という悩みを抱える方もいるのではないでしょうか。
この記事では、「GraphQLが一切わからない」という方が、GraphQLで提供されているGitHub API v4を使えるようになるまでに最低限必要な知識を解説していきたいと思います。
使用する環境・バージョン
- GitHub GraphQL API v4: 2022/8/14時点でのスキーマを使用
- gh version 2.14.4 (2022-08-10)
読者に要求する前提知識
- Issue, PRといったGitHubでの基本用語がわかっていること
- 例え話として「RESTでいう〇〇に該当します」というフレーズを使うので、RESTについての基礎知識があることが望ましい
GraphQLとは何か?
GraphQLとは、API規格の一つです。
「RESTのやり方で作られたAPI」があるように、「GraphQLのやり方で作られたAPI」というものが存在します。
GitHub APIですと、v3がRESTで、v4がGraphQLで作られています。
RESTとの違い
RESTと比べてよく語られるGraphQLの利点としては、「クエリを用いて、必要なデータのみを一回のAPI呼び出しで得られるようになる」という点です。
一つ具体例を出して詳しく説明していきたいと思います。
RESTの場合
例えば、「とあるレポジトリに関する情報を取得する」操作を考えてみましょう。
RESTで提供されているGitHub API v3には、GET /repos/{owner}/{repo}というエンドポイントがあるので、それを呼び出せばパスパラメータで指定したレポジトリの情報を得ることができます。
// GET /repos/{owner}/{repo}
// Default Response (抜粋)
{
"id": 1296269,
"node_id": "MDEwOlJlcG9zaXRvcnkxMjk2MjY5",
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"owner": {
"login": "octocat",
"id": 1,
"node_id": "MDQ6VXNlcjE=",
"url": "https://api.github.com/users/octocat",
"html_url": "https://github.com/octocat",
"type": "User"
},
"private": false,
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"url": "https://api.github.com/repos/octocat/Hello-World",
"default_branch": "master",
"has_issues": true,
"has_projects": true,
"has_wiki": true,
"visibility": "public",
"created_at": "2011-01-26T19:01:12Z",
"organization": {
"login": "octocat",
"id": 1,
"node_id": "MDQ6VXNlcjE=",
"url": "https://api.github.com/users/octocat",
"html_url": "https://github.com/octocat",
"type": "Organization"
}
}
RESTのエンドポイントから得られるレスポンスは、対象となったレポジトリに関する情報が網羅的に入ったものとなります。
例え「created_at(作成日時)のフィールド情報だけ得られれば十分なのに」といった場合にも、それだけを取得するということはできません。
フィールド絞り込みを行いたい場合には、レスポンスを受け取った後クライアント側で「必要な情報のみを抜き出す」という処理を追加で実装してやる必要があります。
また、「そのレポジトリ上にあるIssue一覧も追加で使いたい」という状況も考えてみましょう。
GET /repos/{owner}/{repo}のレスポンスには、レポジトリに紐づくIssue一覧に対応するフィールドは存在しません。
そのため、Issue一覧を得るためには別のエンドポイントGET /repos/{owner}/{repo}/issuesを追加で呼び出してやる必要があります。
// GET /repos/{owner}/{repo}/issues
// Default Response (抜粋)
[
{
"node_id": "MDU6SXNzdWUx",
"url": "https://api.github.com/repos/octocat/Hello-World/issues/1347",
"repository_url": "https://api.github.com/repos/octocat/Hello-World",
"number": 1347,
"state": "open",
"title": "Found a bug",
"body": "I'm having a problem with this.",
"user": {
"login": "octocat",
"node_id": "MDQ6VXNlcjE="
},
"labels": [
{
"node_id": "MDU6TGFiZWwyMDgwNDU5NDY=",
"url": "https://api.github.com/repos/octocat/Hello-World/labels/bug",
"name": "bug",
"description": "Something isn't working",
"color": "f29513",
}
],
"assignees": [
{
"login": "octocat",
"node_id": "MDQ6VXNlcjE=",
"url": "https://api.github.com/users/octocat",
"type": "User",
}
],
"closed_at": null,
}
]
GraphQLの場合
GraphQLを用いた場合には、上記の「とあるレポジトリのcreated_atとIssue一覧情報だけを入手」という操作を、一度のリクエストで実現させることができます。
// リクエストに使うクエリ
query{
repository(name: "Hello-World", owner: "octocat"){
createdAt
issues(first: 3){
nodes{
url
title
closed
number
}
}
}
}
// Response
{
"data": {
"repository": {
"createdAt": "2011-01-26T19:01:12Z",
"issues": {
"nodes": [
{
"url": "https://github.com/octocat/Hello-World/issues/7",
"title": "Hello World in all programming languages",
"closed": true,
"number": 7
},
{
"url": "https://github.com/octocat/Hello-World/issues/10",
"title": "test100",
"closed": true,
"number": 10
},
{
"url": "https://github.com/octocat/Hello-World/issues/11",
"title": "test100",
"closed": true,
"number": 11
}
]
}
}
}
}
欲しい情報のみを過不足なく、一度のリクエストで得られている様子がお分かりいただけるかと思います。
サポートする操作
GraphQLには、大きく分けて3つの操作を行うことができます。
- query
- mutation
- subscription
GitHub API v4で用意されているのはqueryとmutationですので、ここからはこの2つに絞って説明していきたいと思います。
query
RESTでいう「GETのエンドポイントに対して行う操作」に該当します。
既にサービスが持っているデータの情報を取得するという操作は、GraphQLではqueryで行うことになります。
mutation
RESTでいう「POST/PUT/PATCH/DELETEのエンドポイントに対して行う操作」に該当します。
サービスにデータを新規登録する・データを更新・削除するといった冪等性のない操作に関しては、GraphQLではmutationで行うことになります。
GitHub API v4を実行してみよう
それでは実際にGitHub API v4を実行する様子をお見せしたいと思います。
一番簡単なのは、GitHub CLIに用意されているgh api graphqlコマンドを使うことです。
// HomeBrewを使ってインストールする場合
$ brew install gh
queryの場合
まずはqueryを実行してみましょう。
今回は例として
- ユーザー名
mynameのプロフィールBio - そのユーザーが持つ番号1番のProjectV2のタイトルとURL
を取得するクエリを実行してみましょう。
$ gh api graphql -f query='
query {
user(login: "myname") {
bio
projectV2(number: 1) {
title
url
}
}
}
'
// 実行結果
{
"data": {
"user": {
"bio": "Hello! This is my Bio.",
"projectV2": {
"title": "MyTestProject",
"url": "https://github.com/users/myname/projects/1"
}
}
}
}
ここからは、このクエリを書くために必要な情報をどこで手に入れたかについてご説明したいと思います。
クエリの選択
GitHub API v4に用意されているクエリにはいくつかの種類が存在します。
例えば、レポジトリの情報を得たい場合にはrepositoryクエリ、Organizationの情報を得たい場合にはorganizationクエリ……といった具合です。
今回の場合「ユーザーに紐づいた」ProjectV2の情報が欲しかったため、ルートとなるクエリはuserを選択しました。
query {
user(引数) {
// (略)
}
}
どのようなクエリが用意されているかは、公式Docの中の以下のページを参照してください。
クエリの記述
userクエリはUserオブジェクトを返却します。
私たちはそのUserオブジェクトの中からどのフィールドが欲しいのかをクエリの中に書いていきます。
query {
user(login: "myname") { // 引数に login: myname で得られるUserオブジェクトのうち
bio // bioフィールドが欲しい
projectV2(number: 1) { // 引数に number: 1 を与えて得られたprojectV2フィールド(ProjectV2オブジェクト)のうち
title // titleフィールドと
url // urlフィールドが欲しい
}
}
}
各オブジェクトにどのようなフィールドが存在するかは、公式Docの中の以下のページを参照してください。
mutationの場合
次にmutationを実行してみましょう。
今回は例として
- ProjectV2(プロジェクトID:
PVT_BBBBBBB)内にあるカード(アイテムID:PVTI_AAAAAAAAA)につけていたメタデータフィールド(フィールドID:PVTSSF_CCCCCCC)の値を、オプションIDddddddddの値に変える - 更新に成功した場合には、更新したそのカードのIDを出力する
という処理を行うクエリを実行してみましょう。
$ gh api graphql -f query='
mutation{
updateProjectV2ItemFieldValue(input: {
itemId: "PVTI_AAAAAAAAA",
projectId: "PVT_BBBBBBB",
fieldId: "PVTSSF_CCCCCCC",
value: {
singleSelectOptionId: "dddddddd"
}
}) {
projectV2Item {
id
}
}
}
'
// 実行結果
{
"data": {
"updateProjectV2ItemFieldValue": {
"projectV2Item": {
"id": "PVTI_AAAAAAAAA",
}
}
}
}
引き続き、このクエリを書くために必要な情報をどこで手に入れたかについてもご説明したいと思います。
ミューテーションの選択
GitHub API v4に用意されているミューテーションにはいくつかの種類が存在します。
例えば、あるIDのオブジェクトをProjectV2に追加したい場合にはaddProjectV2ItemById、逆にProjectV2からカードを削除したい場合にはdeleteProjectV2Item……といった具合です。
今回の場合「あるProjectV2カードのフィールド値を更新したい」ためupdateProjectV2ItemFieldValueを選択しました。
mutation{
updateProjectV2ItemFieldValue
}
どのようなミューテーションが用意されているかは、公式Docの中の以下のページを参照してください。
Inputのセット
ミューテーションupdateProjectV2ItemFieldValueを実行するためには、適切なInput値(引数)をセットする必要があります。
Inputとして指定されているのはUpdateProjectV2ItemFieldValueInput型です。
そのため、UpdateProjectV2ItemFieldValueInputオブジェクトに必要なフィールドをセットしながらInputを作ります。
mutation{
updateProjectV2ItemFieldValue(input: {
itemId: "PVTI_AAAAAAAAA",
projectId: "PVT_BBBBBBB",
fieldId: "PVTSSF_CCCCCCC",
value: {
singleSelectOptionId: "dddddddd"
}
}) {
// (略)
}
}
ミューテーションのInputに必要になるオブジェクト定義については、公式Docの中の以下のページを参照してください。
GitHub API v4で出てくるGraphQLの用語
これにて、GitHub API v4を実行するために最低限必要な知識は説明できました。
そのためここからは発展的な内容、「これも知っていればよりスムーズになる」という事項について紹介していきたいと思います。
クエリ内で変数を使う
クエリ実行の際に引数を指定することがありましたが、その引数の値を外から変数として与えてやることもできます。
// Int型の変数$projectNoを導入した様子
$ gh api graphql -F projectNo=1 -f query='
query($projectNo: Int!) {
user(login: "myname") {
bio
projectV2(number: $projectNo) {
title
url
}
}
}
'
正しいクエリを書く - スカラの把握
GraphQLのルール: クエリフィールドは全てスカラ型にする必要がある
例えば、以下のようなクエリを考えてみます。
query {
user(login: "myname") {
projectV2
}
}
「mynameという名前のユーザーが持つProjectV2が欲しい」という意味に見えるかと思います。
しかしこのクエリ、実行してみるエラーが発生します。
{
"errors": [
{
"path": [
"query",
"user",
"projectV2"
],
"extensions": {
"code": "selectionMismatch",
"nodeName": "field 'projectV2'",
"typeName": "ProjectV2"
},
"locations": [
{
"line": 4,
"column": 3
}
],
"message": "Field must have selections (field 'projectV2' returns ProjectV2 but has no selections. Did you mean 'projectV2 { ... }'?)"
}
]
}
これはどういう意味かというと、
-
projectV2フィールドはProjectV2オブジェクト型 - ProjectV2オブジェクトの中のどのフィールドが欲しいのかクエリに記述しないとダメ
という意味です。
実はGraphQLのクエリというのは、「取得対象となっているフィールドが、全てスカラ型になっていなくてはいけない」というルールがあります。
GraphQL APIを呼ぶ際には、スカラだけが返されるようになるまでネストしたサブフィールドを指定していかなければなりません。
出典: GitHub Docs - スカラ
そのため、「何がスカラ型で、何がオブジェクト型なのか」を把握した上でクエリを書くことがとても重要です。
// NG
query {
user(login: "myname") {
projectV2 // オブジェクト型
}
}
// OK
query {
user(login: "myname") {
projectV2(number: 1) {
title // スカラ型(String)
url // スカラ型(URI)
}
}
}
組み込みスカラ
GraphQLには、組み込みで5つのスカラが用意されています。
- Int: 符号あり32bit整数
- Float: 符号あり倍精度浮動小数点数
- Boolean:
trueまたはfalse - String: UTF‐8の文字列
- ID: 実態としてはStringですが、unique identifierとしての機能を持ったフィールドであればこのID型にするのが望ましいです。
カスタムスカラ
5つの組み込みスカラ以外にも、GitHub API v4で使えるカスタムスカラというものが定義されています。
以下、代表的なものを紹介します。
- DateTime: 日時の文字列
- URI: URL用の文字列
カスタムスカラの全量は、公式Docの中の以下のページを参照してください。
ノード(Node)
GitHubには、レポジトリ、ユーザー、Issue, PRといった様々なオブジェクトが存在します。
そしてそれらの間には、
- とあるユーザーが、複数個のレポジトリを持っている
- とあるレポジトリが、複数個のIssue、PRを持っている
- とあるIssueには、複数人のAssigneeがいる
といったように何らかの繋がりが存在します。
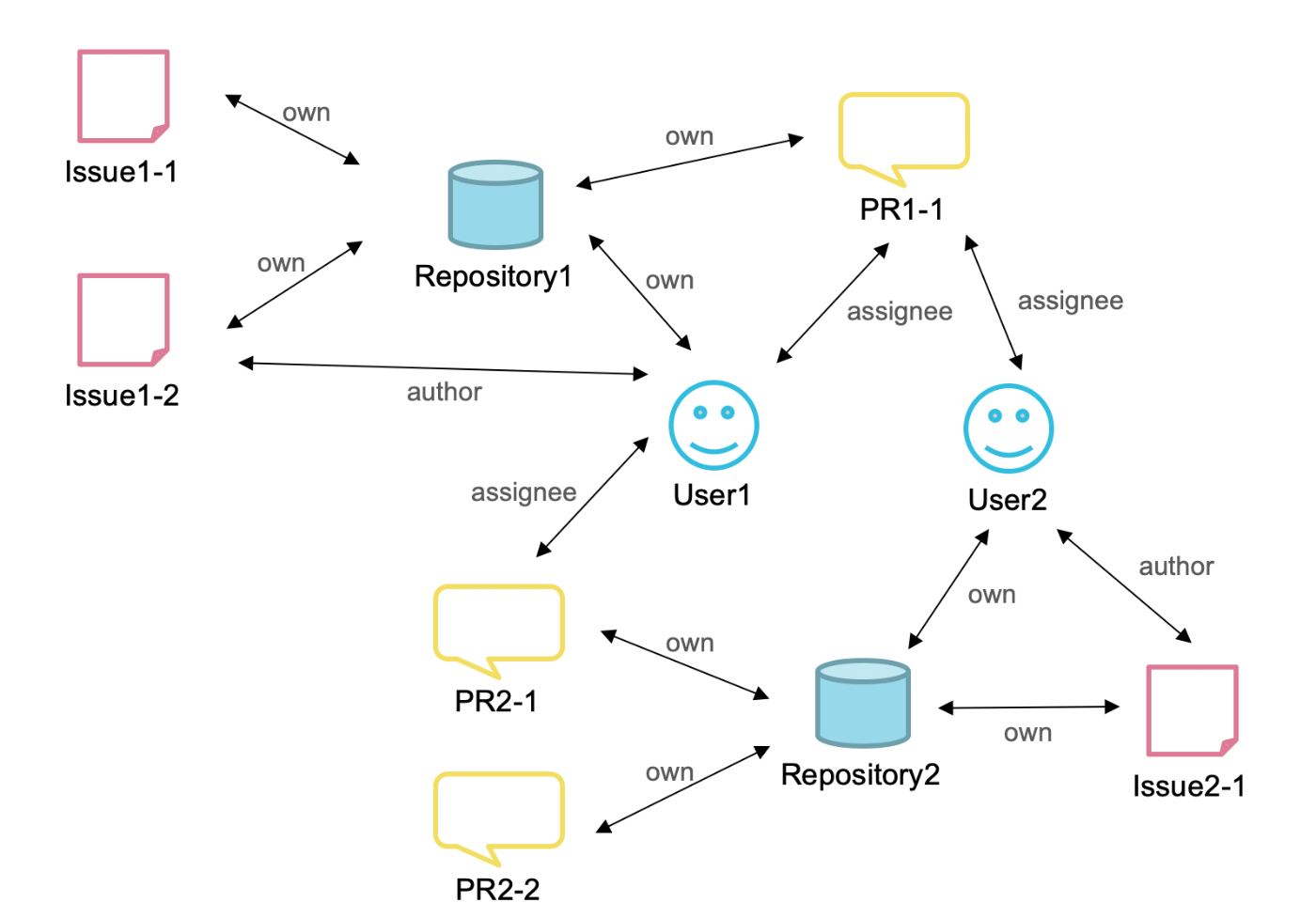
GitHub APIでは、これら一つ一つのオブジェクトのことをノードと呼んでおり、それらに一意のグローバルノードIDを割り振っています。
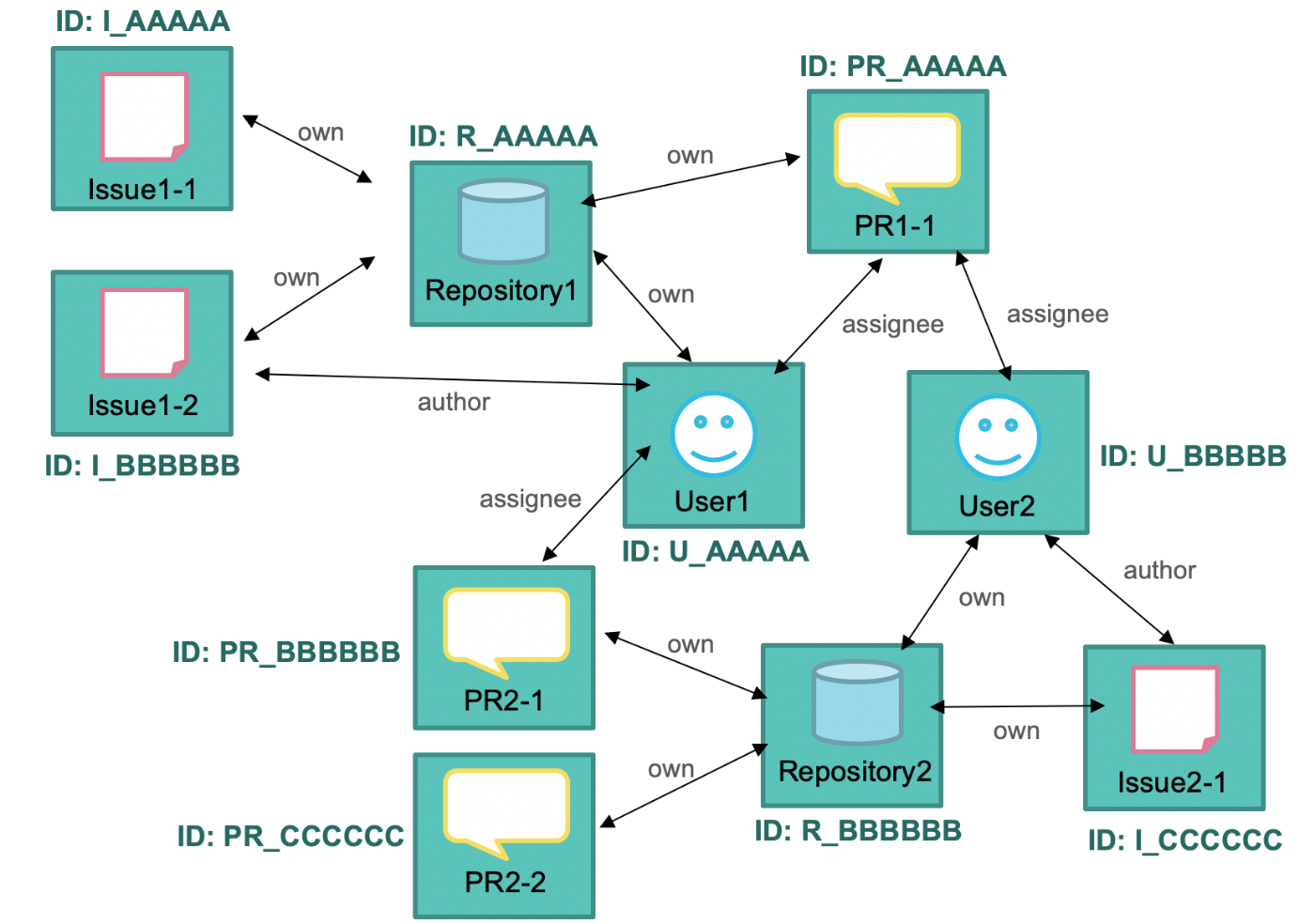
GitHub API v4の中には、「指定されたノードIDを持つオブジェクト」を直接取得するためのnodeクエリが存在し、
- 何らかの形でNodeIDを特定する
-
nodeクエリで関心のあるオブジェクトのデータを直接取得する
というやり方をとることができます。
インターフェース型の利用
インターフェースとは
GraphQLではインターフェースというものを定義することができます。
インターフェースとは何かについては、具体例を出した方がわかりやすいかと思うのでそれで説明したいと思います。
例えばGitHub API v4にはNodeというインターフェースがあります。
Nodeインターフェースは「ID型のidフィールドを持つ」というように定義されています。
つまり、「idフィールド(型: ID)を持つオブジェクトは全てNodeインターフェースを実装している」ものとして扱うことができるのです。
具体的に述べるならば、Issue型オブジェクトもUser型オブジェクトもProjectV2型オブジェクトもidフィールドを持っています。
そのため、これらは全てNodeインターフェースを実装しています。
GitHub API v4内で定義されているインターフェース一覧は、公式Docの中の以下のページを参照してください。
インターフェース型を用いたクエリ
実際にインターフェースが関連するクエリを紹介したいと思います。
例えば、「IDがI_AAAAAAAであるIssueの情報を取得する」というクエリを作りたいと思います。
ノードのIDがわかっている状態なので、先ほど紹介したnodeクエリを使います。
query {
node(id: "I_AAAAAAA") {
id
}
}
{
"data": {
"node": {
"id": "I_AAAAAAA",
}
}
}
nodeクエリからは、Nodeインターフェースを得ることができます。
しかし、Nodeインターフェースはidフィールドしか持っていません。
そのため、以下のように「Issue型にはあるけどNodeインターフェースにはないurl・title・closed・numberフィールドを取得しようとする」とエラーが発生します。
// ダメな例
query {
node(id: "I_AAAAAAA") {
id
url
title
closed
number
}
}
// (一部抜粋)
{
"errors": [
{
"message": "Field 'url' doesn't exist on type 'Node'"
},
{
"message": "Field 'title' doesn't exist on type 'Node'"
},
{
"message": "Field 'closed' doesn't exist on type 'Node'"
},
{
"message": "Field 'number' doesn't exist on type 'Node'"
}
]
}
これを回避するには「もしもIssueオブジェクト型だった場合には、以下のフィールドを取得する」という記述をしてやる必要があります。
GraphQLにおいて、実行時に型を解決させるようなクエリはインラインフラグメントというものを使って実現させます。
// インラインフラグメントを使って型解決させた例
query {
node(id: "I_AAAAAAA") {
id
... on Issue {
url
title
closed
number
}
}
}
{
"data": {
"node": {
"id": "I_AAAAAAA",
"url": "https://github.com/myname/myrepo/issues/1",
"title": "Issue1",
"closed": false,
"number": 1
}
}
}
ユニオン型の利用
GraphQLにはユニオン型というものがあり、GitHub API v4の中でもこれが多数利用されています。
実際にどこで利用されているのか、ユニオン型の説明もしながら具体例を出してみます。
ユニオン型が使われる例
例えばProjectV2に登録するアイテム(カード)を考えてみてください。
ProjectV2では、IssueやPRを管理対象として、Statusフィールドを付与したり一覧表を作ったりすることができます。
つまり、Issue型とPullRequest型という2つのオブジェクトがProjectV2のカードになりうるのです。
実際にProjectV2Itemオブジェクトのcontentフィールドを確認してみましょう。
contentフィールドはProjectV2ItemContentという型だと定義されていますが、このProjectV2ItemContentこそがユニオン型です。
ProjectV2ItemContentの定義を確認してみると、これは「Issue型かPullRequest型(かDraftIssue型)」になりうると書いてあります。
つまり、ProjectV2Itemオブジェクトのcontentフィールドは、Issueオブジェクトが入るかもしれないし、PullRequestオブジェクトが入るかもしれないということなのです。
ユニオンを用いたクエリ
それではこのユニオン型が絡んだクエリをどう書くべきかを説明していきたいと思います。
今回の例では「ユーザーmynameが持つ、番号1番のProjectV2が持つカード(アイテム)を3つ取得する」というクエリを書きたいと思います。
query {
user(login: "myname") {
projectV2(number: 1) {
title
url
items(first: 3) {
nodes {
type
content {
... on Issue {
url
title
closed
number
}
... on PullRequest {
title
baseRefName
closed
headRefName
url
}
}
}
}
}
}
}
今回ユニオン型になるのはcontentフィールドです。
そのcontentのブロックの中に、インラインフラグメントを用いて
-
Issue型だったら取得するフィールド -
PullRequest型だったら取得するフィールド
の2つの情報を書き込んでいます。
実際に上記のクエリを実行すると、以下のようにIssue・PR両方の情報を一度に取得することができます。
{
"data": {
"user": {
"projectV2": {
"title": "MyTestProject",
"url": "https://github.com/users/myname/projects/1",
"items": {
"nodes": [
{
"type": "ISSUE",
"content": {
"url": "https://github.com/myname/myrepo/issues/1",
"title": "Issue1",
"closed": false,
"number": 1
}
},
{
"type": "PULL_REQUEST",
"content": {
"title": "add description",
"baseRefName": "main",
"closed": false,
"headRefName": "pr1",
"url": "https://github.com/myname/myrepo/pull/2"
}
},
{
"type": "ISSUE",
"content": {
"url": "https://github.com/myname/myrepo/issues/3",
"title": "Issue2",
"closed": false,
"number": 3
}
}
]
}
}
}
}
}
ページネーションの考え方
Issue一覧やPR一覧のように「オブジェクトの一覧を取得したい」という操作を考えます。
10個20個程度なら一つのレスポンスに全ての情報を詰めてしまっても良いのですが、100個1000個……となってくると「リストをn個ずつに分割してページネーションさせる」ということを考えなくてはいけません。
GitHub API v4ではRelay-Style Cursor Paginationという方式でページネーションを実装しており、IssueやPullRequestといった概念オブジェクト以外にも、IssueConnectionやIssueEdgeといったページネーションのためのオブジェクトが多数定義されています。
概略図
Relay-Style Cursor Paginationのイメージは以下のようになっています。
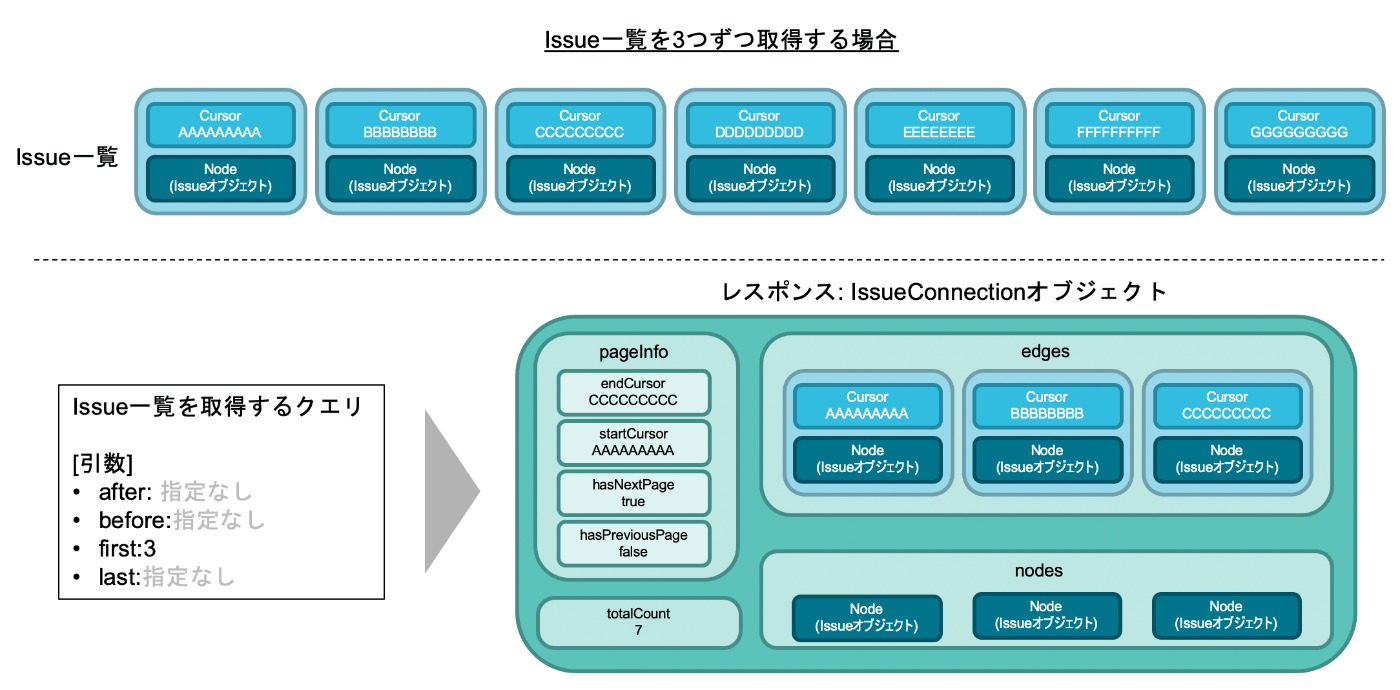
重要になるのは以下の単語です。ここからはこれらについて説明していきます。
- 引数
first・last - Connection
- Edge
- Cursor
- PageInfo
- 引数
after・before
引数first・last
Relay-Style Cursor Pagination方式を採用している場合には、一覧取得時にfirst・lastという引数を指定することになります。
どちらも数値を指定するフィールドで、firstは「(ある位置から)最初のn個を取得」、lastは「(ある位置から)最後のn個を取得」の意味を持ちます。
firstを指定した場合
lastを指定した場合
Connection
一覧を取得した際にレスポンスとして得られるのはConnectionというオブジェクトです。
一度のリクエストに対して1つのConnectionが得られるので、Relay-Style Cursor Paginationにおけるページのようなものだと捉えていいでしょう。
GitHub API v4では、
- Issue一覧 →
IssueConnection - PR一覧 →
PullRequestConnection - ...
といったように、対象となったオブジェクトごとにそれぞれ対応するConnectionが用意されています。
Connectionの中で特に重要なものは、Edge一覧を含むedgesフィールドとpageInfoフィールドです。
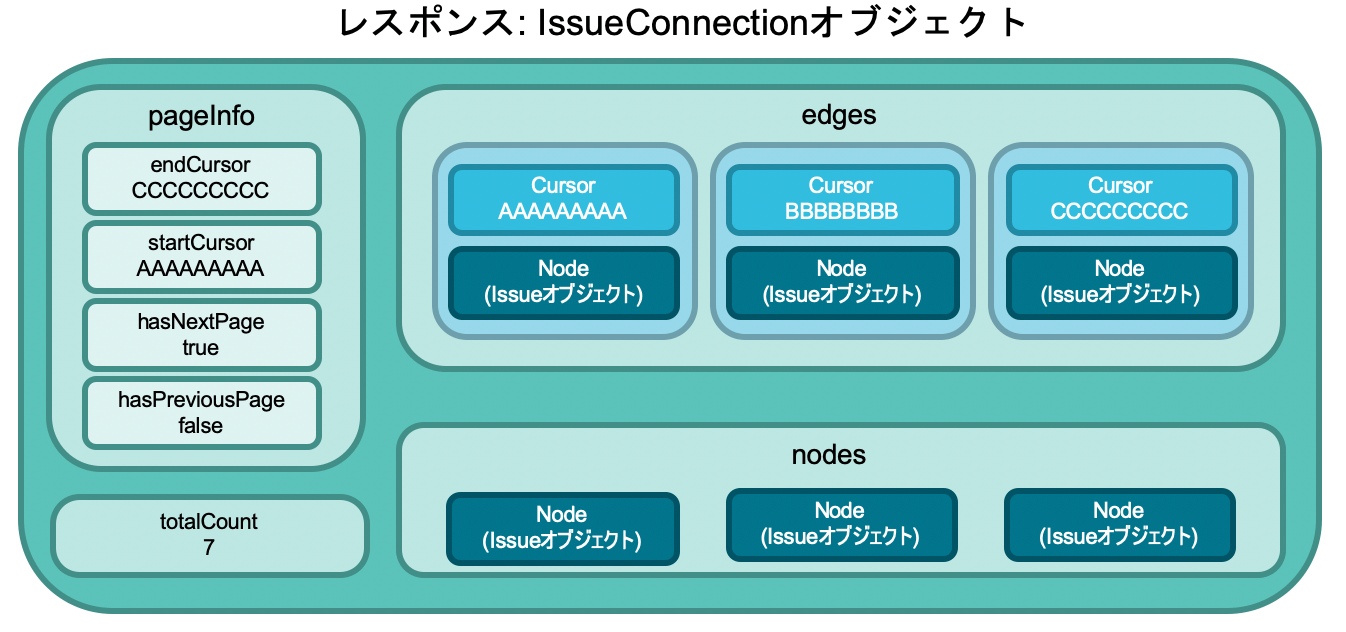
Edge
Connectionのedgesフィールドに含まれているのは、Edgeのリストです。
GitHub API v4では、
- IssueConnection中のEdge →
IssueEdge - PullRequestConnection中のEdge →
PullRequestEdge - ...
といったように、対象となったオブジェクトごとにそれぞれ対応するEdgeが用意されています。
Edgeというのは「CursorとNodeのセット」として捉えることができます。
IssueEdgeにおけるNodeというのはIssueオブジェクト、PullRequestEdgeにおけるNodeというのはPullRequestオブジェクトにあたります。
それではそれとセットになっているCursorとはいったい何者なのでしょうか。
Cursor
Edge内でNodeとセットで扱われていたCursorは、「取得対象となった一覧リストの中で、そのオブジェクトがどの位置にあるものなのか」という位置情報を指し示すものです。
ページネーションで一覧の一部を取得してきたときに、
- 今回取得できたのは、どこからどこまでの情報なのか
- 「次のページ」「前のページ」を取得する際にどうリクエストを送ればいいか
という点でCursorが威力を発揮します。
PageInfo
PageInfoはConnectionオブジェクトの中に含まれるフィールドの一つです。
PageInfoオブジェクトの中には4つのフィールドが含まれており、それぞれ以下の意味を持ちます。
-
endCursor: Connection中に含まれている最後のEdgeが持つCursorの値 -
startCursor: Connection中に含まれている最初のEdgeが持つCursorの値 -
hasNextPage: 次のページ(Connection)があるかどうかを示すbool値 -
hasPreviousPage: 前のページ(Connection)があるかどうかを示すbool値
具体例を挙げますので、それぞれPageInfoの値がどうなっているのか見てみましょう。
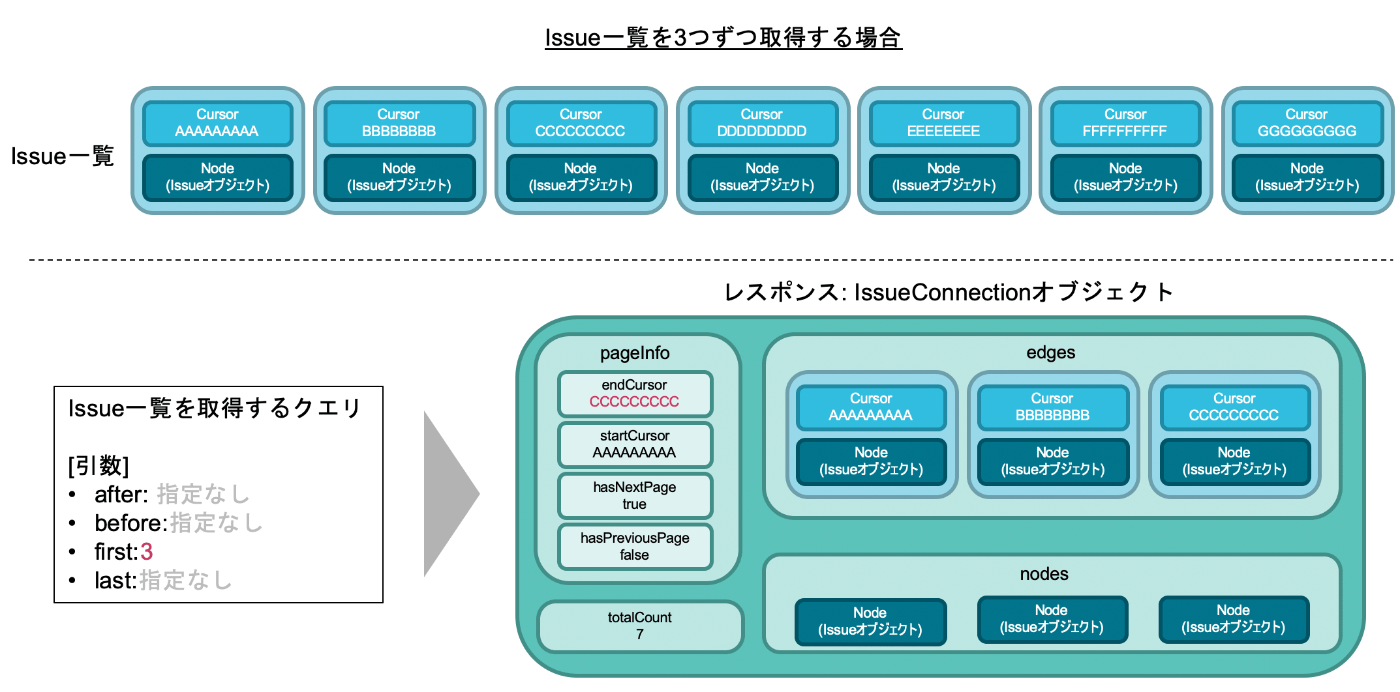
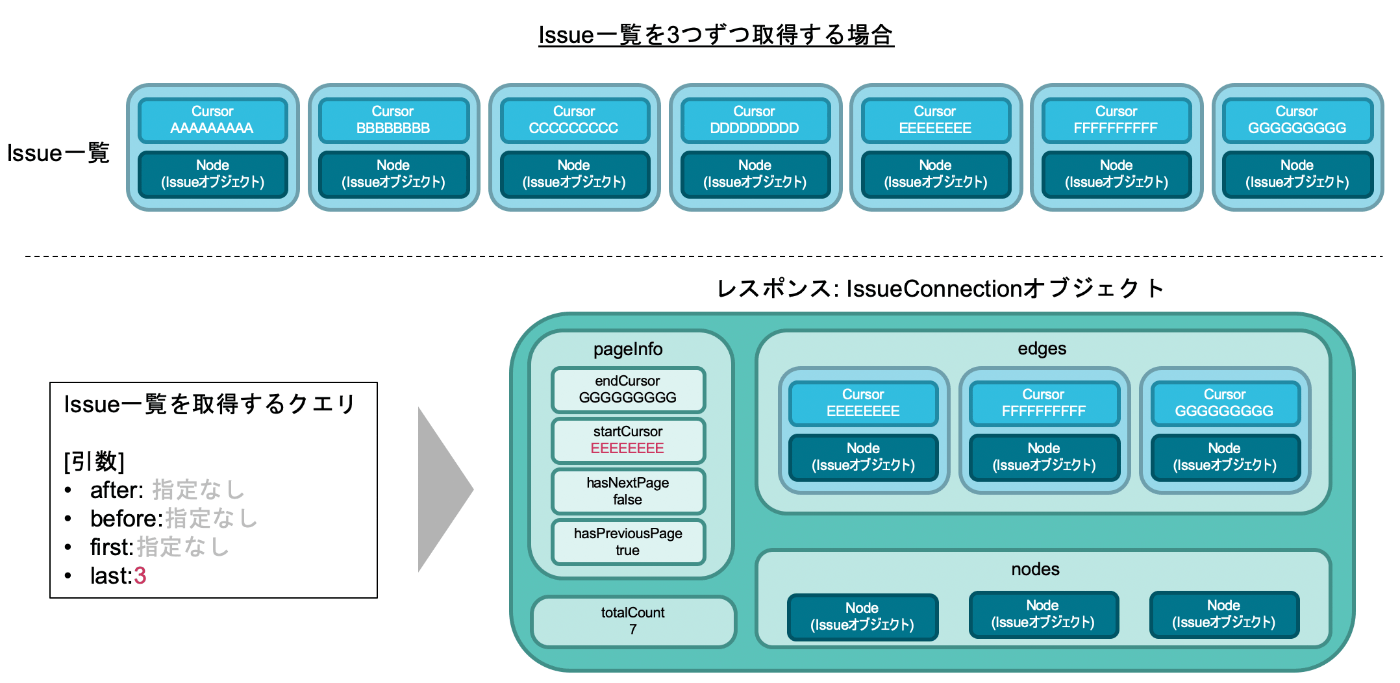
まずは、「最初の3つを取得」した場合です。
Issue一覧の中で最初の3つのEdgeというのは、順番にCursorの値が「AAAAAAAA, BBBBBBBB, CCCCCCCCC」のものです。
そのため、このConnectionのendCursorにはCCCCCCCCCが、startCursorにはAAAAAAAAが格納されています。
また、Cursorの値がCCCCCCCCCのEdge以降にも、このConnectionの取得範囲には入っていない後続のEdgeが存在します。逆に、Cursorの値がAAAAAAAAのEdgeよりも前には何もデータ(Edge)が存在しません。
そのため、hasNextPageの値はtrue、hasPreviousPageの値はfalseとなっています。
もう一つ、「最後の3つを取得」した場合です。
Issue一覧の中で最初の3つのEdgeというのは、順番にCursorの値が「EEEEEEEEE, FFFFFFFF, GGGGGGGG」のものです。
そのため、このConnectionのendCursorにはGGGGGGGGが、startCursorにはEEEEEEEEEが格納されています。
また、Cursorの値がEEEEEEEEEのEdge以前にも、このConnectionの取得範囲には入っていない前座のEdgeが存在します。逆に、Cursorの値がGGGGGGGGのEdgeよりも後には何もデータ(Edge)が存在しません。
そのため、hasNextPageの値はfalse、hasPreviousPageの値はtrueとなっています。
引数after・before
一覧を取得する際に指定する引数first・lastはそれぞれ「(ある位置から)最初のn個を取得」「(ある位置から)最後のn個を取得」の意味であるということは前述した通りです。
その時のある位置からという部分を指定するための引数がafterとbeforeです。
これも具体例を出して説明したいと思います。
1~3個目のIssueを手に入れて、次ページの4~6個目のIssueを取得するという状況を考えましょう。
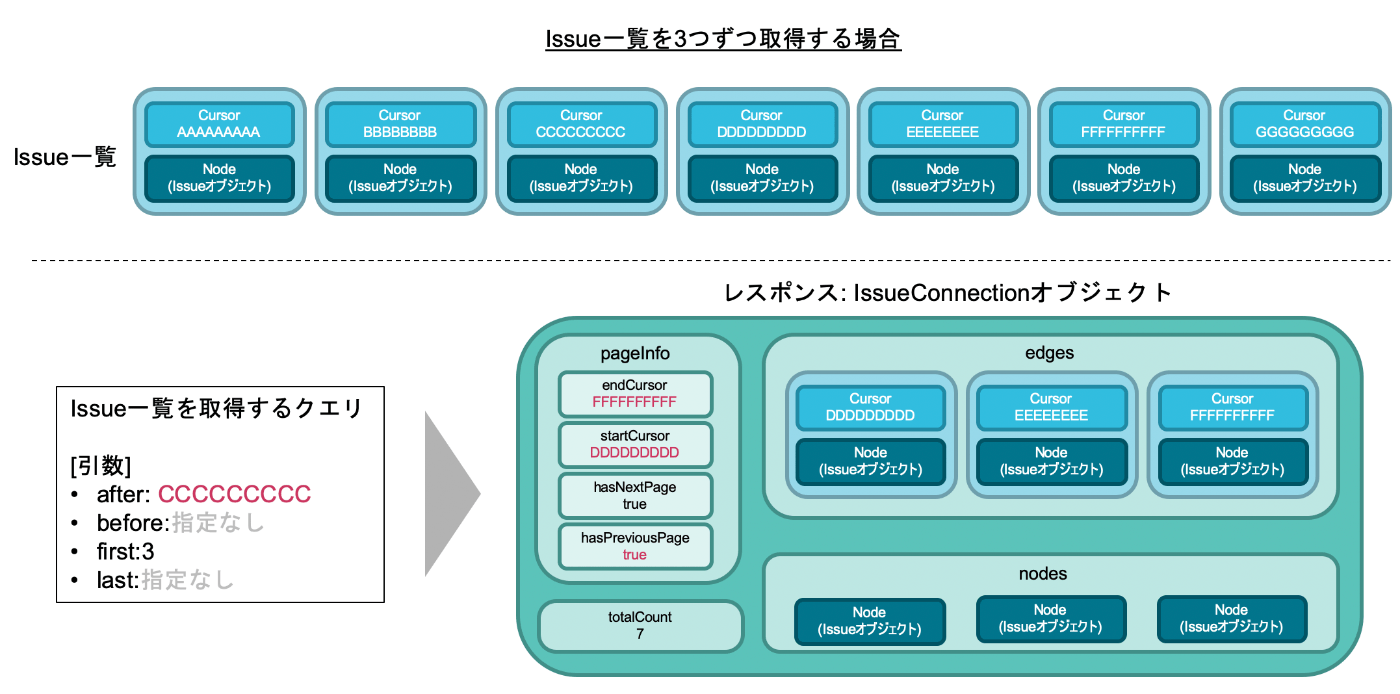
これは言い換えると「CursorがCCCCCCCCC以降のIssueが3つ欲しい」ということです。そのため、afterにCCCCCCCCCを指定してリクエストを送ることになります。
また、5~7個目のIssueをを手に入れて、前ページの2~4個目のIssueを取得するという状況を考えましょう。
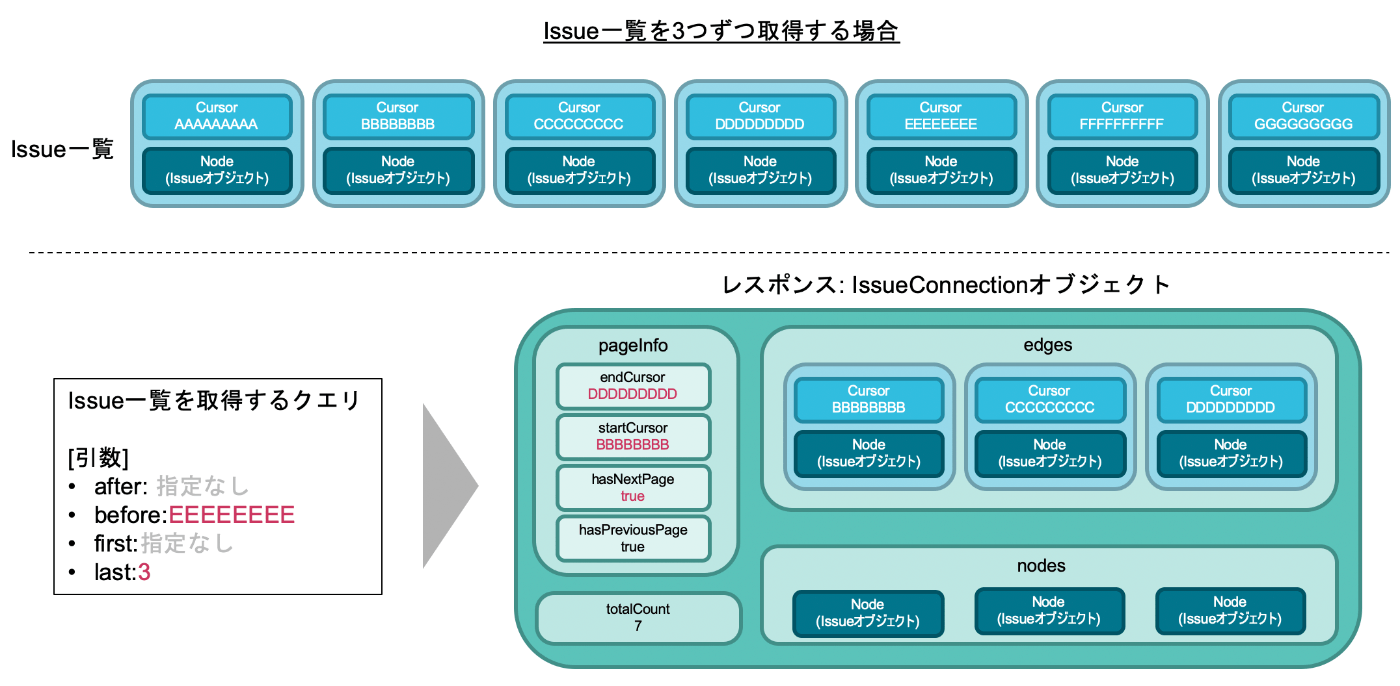
これは言い換えると「CursorがEEEEEEEEEより前のIssueが3つ欲しい」ということです。そのため、beforeにEEEEEEEEEを指定してリクエストを送ることになります。
まとめ
というわけで、GitHub API v4を使うために知っているべきGraphQLの知識をまとめてみました。
私自身、ProjectV2をプログラムで扱う必要が出たために今までスルーしてきたGraphQLから逃げられなくなったといういきさつがあるのですが、ここに書いた内容を全て理解できた段階で、ようやくエラーを出さず自由にクエリできるようになったなと感じられたのを覚えています。
GitHub API v4に対応する各言語のSDKが出てしまえばそれを使うのが一番手っ取り早く簡単なのですが、少なくともGo(私の主要言語)ではProjectV2対応まで完了したSDKは現段階で存在しないようです。
それまでは、GraphQLの仕組みを理解した上でクエリを書き、そのクエリをghコマンドや他のGraphQLクライアント[1]で実行していくというやり方をとる必要があり、ゆえに「GraphQLわからないとGitHub API叩けないよやばいよ」という人は出続けるのかなと思います。
もし皆さんの周りにまさにそういう方がいらっしゃったらこの記事を送っていただければと思います。
-
Goでのおすすめは
hasura/go-graphql-clientです。GitHub API v4対応のGo SDKとして現状有力なのはshurcooL/githubv4なのですが、それと同じ作者さんが作ったshurcooL/graphqlからフォークされて作られたライブラリなので、将来shurcooL/githubv4がProjectV2対応して完成された際に移行にスムーズなのかなという印象です。 ↩︎
Discussion