metric learning と関係のある分野まとめ
この記事の目的は?
以下の分野と metric learing の繋がりをざっくり説明します。
- fine-grained image classification
- 顔認識
- few-shot learning
- マルチモーダル学習
- 異常検知
- learning to rank
- カーネル法
- 自己教師あり学習
- 推薦
- 自然言語処理
fine-grained image classification
metric learning 手法が主に提案される分野は fine-grained image classification だと思います。 fine-grained image classification とは、車や犬というように大雑把に分類するのではなく、車種や鳥の種類など細かいクラスに分類する問題です。このように、 クラス数が多く、1クラスあたりのサンプル数が少ない 分類問題に metric learning は適しています。
metric learning のサーベイは、 以下の GitHub リポジトリが参考になると思います。
また、実装は以下のライブラリにまとまっています。
ちなみに、extreme classification という似たような問題があります。こちらはマルチラベルの(1つの画像が複数のクラスに所属する)場合の話が多い気がしますが、以下の Ranked List Loss の論文では、 instance-to-instance な metric learning は extreme classification において良い解決策だと主張しています。
extreme classification の概要については以下のブログ記事にまとまっています。
数えきれないほどの分類を行うExtreme Classification - Technical Hedgehog
顔認識
fine-grained image classification の他に、metric learning の手法がよく提案されるのは顔認識の分野だと思います。 人物をクラスと考えると、クラス数が多く、1クラスあたりのサンプル数が少ない状況なので、 fine-grained image classification の一例と考えられます。
出典:https://arxiv.org/abs/1704.08063
ちなみに顔認識の分野では Softmax Cross-Entropy ベースの手法が話題になっているようです。
- モダンな深層距離学習 (deep metric learning) 手法: SphereFace, CosFace, ArcFace - Qiita
- Softmax関数をベースにした Deep Metric Learning が上手くいく理由 - Qiita
few-shot learning
1クラスあたりのサンプル数が少ない といった意味では、 few-shot learning も関連しています。実際に metric learning ベースの手法が提案されています。
参考
マルチモーダル学習
マルチモーダル学習とは、画像とテキスト、画像と音など、異なるドメインのデータ間の関係を学習する手法です[1]。例えば、 visual-semantic embeddings という分野では対応する画像とテキストの特徴量が近くなるように学習します。 この論文 では以下のような損失関数で学習します[2]。
-
B -
\bm{x_i} i -
\bm{v_i} i -
s -
\Theta -
m
対応する画像と文のペアの類似度を、対応しないペアの類似度より
このようにマルチモーダル学習でも metric learning が使われています。
異常検知
あまり調べられてないのですが、異常検知でも metric learning が使われているようです。
learning to rank
learning to rank とは、 主に検索のための学習方法で、 あるクエリに対する検索結果の適切な順位を学習します。詳細は以下のアドベントカレンダーが参考になると思います。
ランク学習(Learning to Rank) Advent Calendar 2018 - Adventar
ポイントワイズとペアワイズの損失関数は、 metric learning の損失関数に近いと思います。
ポイントワイズの一例[3]:
-
q -
d -
y_{q,d} q d -
\bm{x}_{q,d} q d -
f(\cdot)
ペアワイズの一例(※3):
-
i, j
どちらも関連度を類似度ととらえれば、それぞれ metric learning の contrastive, triplet 系の損失関数に似ています。
また、 metric learning の手法で learning to rank のしくみを取り入れた手法も提案されています。 learning to rank の評価指標である Average Precision の近似を損失関数とした FastAP という手法です。
カーネル法
metric learning はカーネル法と等価らしいです。詳細は以下のブログ記事が参考になると思います。
距離計量学習とカーネル学習について - a lonely miner
自己教師あり学習
自己教師あり学習もかなり近いことをやっているようです。

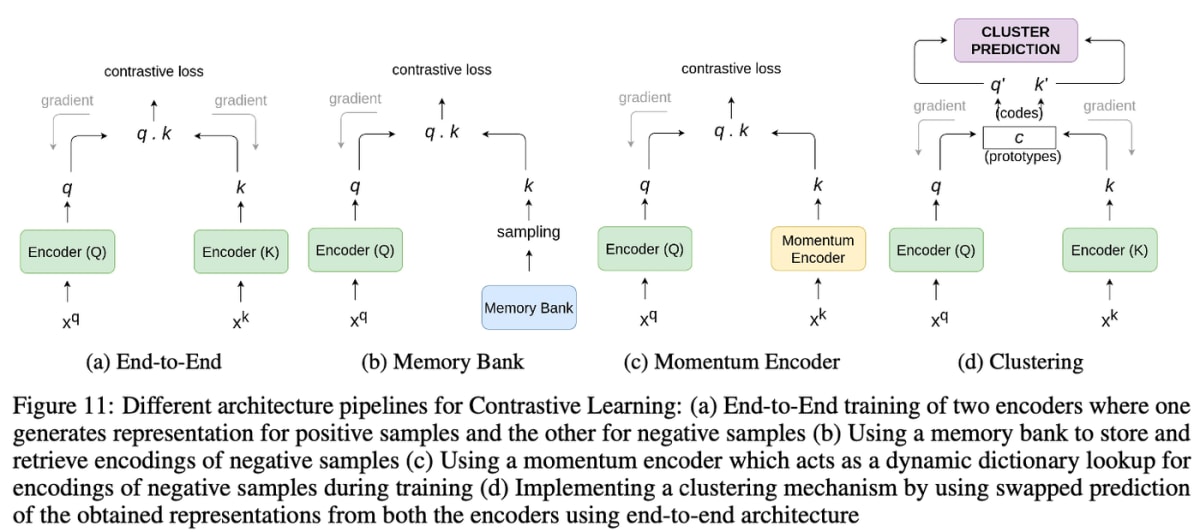
出典・参考:2020年超盛り上がり!自己教師あり学習の最前線まとめ! - Qiita
負例の獲得方法を工夫した4つアーキテクチャなどは、自己教師あり学習だけに限らず、他の分野でも活かせそうです。
推薦
推薦モデルを metric leaning の観点からとらえる で、 MF (Matrix Factrization) や BPR (Bayesian Personalized Ranking) が metric learning の手法に似ていることや、 metric learning を使った推薦手法を紹介しました。
自然言語処理
自然言語処理のモデルを metric learning の観点からとらえる で、 Word2Vec や RNN による言語モデル (RNNLM) が metric learning であることを説明しました。
まとめ
metric learning と関係のある分野をリストアップしました。このように多くの分野と関係がありますが、 metric learning すごい!というより、 metric learning によって各分野の繋がりが強くなり、 ある分野の知見を他の分野でも活かしやすくなる ということが metric learning の面白さかなと思っています。
例えば、 Word2Vec や RNNLM の負例には、他の文では正例である単語が来る可能性もあります(「I have a pen」「I have a dog」という文は両方ともありえますが、前者において「dog」、後者において「pen」は負例になってしまいます)。 このように正例になる可能性がある負例は、推薦分野における implicit feedback の負例に近いと考えています。そこで Word2Vec や RNNLM の Softmax Cross-Entropy の代わりに BPR や triplet loss などを使ってみても面白いのかなと考えています。
次回は?
次回は、 metric learning の既存手法がそれぞれ 「ミニバッチ内の情報をどくらい活用できているか」をグラム行列の観点から可視化 してみます。
Discussion