Snowflake Cortex の使い方 ~LLM関数編~
はじめに
Snowflake Arcticのハッカソン参加に伴い、Snowflake Cortexを使用したアプリ実装を経験しました。
この記事では、そこで得たCortexに関する内容をまとめていきたいと思います。
参加したハッカソン:THE FUTURE OF AI IS OPEN
Snowflake Cortexとは
Snowflake Cortexには大きく2つの機能が存在します。
- LLM関数
- ML関数
Cortexの良いところは、それぞれの関数をSQL(SELECT文など)で簡単に呼び出せることです。
LLM関数
大規模言語モデル(LLM)を利用して、ユーザーのプロンプトに応答したり、文章の要約、翻訳などが行えます。それぞれの用途に応じた関数が用意されており、一部関数では自身で使用するモデルも選択できます。(ArcticやRekaなど)
LLM関数についてはSQLの他にPython(Snowpark)でも利用可能です。
ML関数
Snowflake上でモデルをトレーニングし予測や異常検出、分類などが行えます。
※今回の記事では詳細は取り上げません。
各LLM関数と使い方
2024年5月末現在、LLM関数は以下が用意されています。
- COMPLETE
- EMBED_TEXT_768
- EXTRACT_ANSWER
- SENTIMENT
- SUMMARIZE
- TRANSLATE
1. COMPLETE
ユーザーが入力したプロンプトに対して応答を生成する関数です。(Chat-GPTみたいな)
呼び出し方が2つあります。
単一の応答を取得
モデル名とプロンプトを引数に渡すだけで、モデルの応答結果が出力されます。簡単すぎる!
過去の応答やシステムプロンプトなどを考慮しない場合はこれでも十分です。
SELECT SNOWFLAKE.CORTEX.COMPLETE('snowflake-arctic', '日本の人口は何人ですか?') as response;
過去のプロンプトやオプション指定して取得
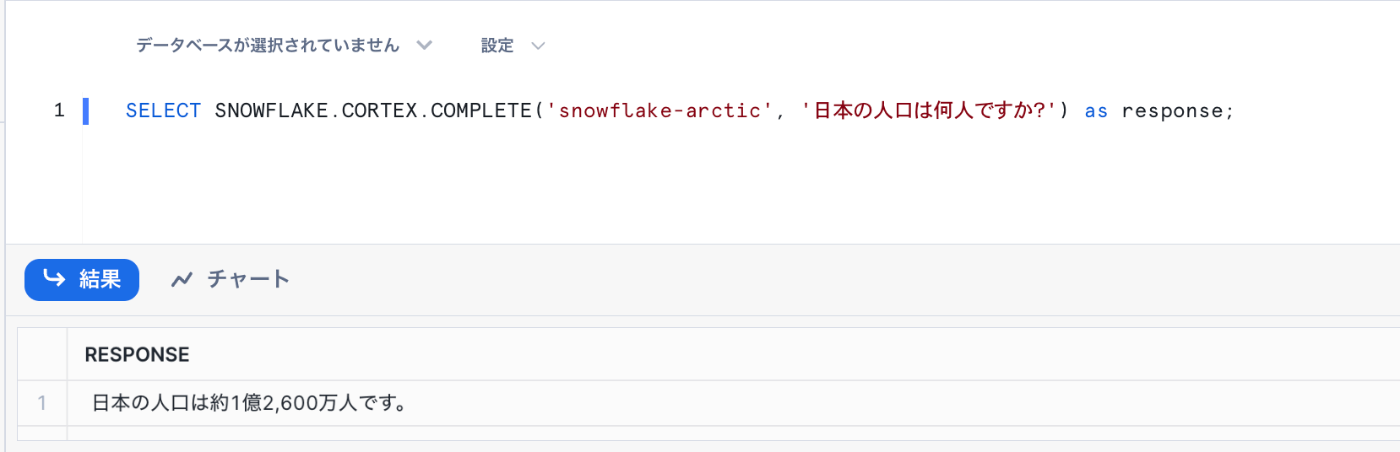
過去のユーザーとの会話やtemperatureなどのオプションを指定したい場合は、この形式で利用します。
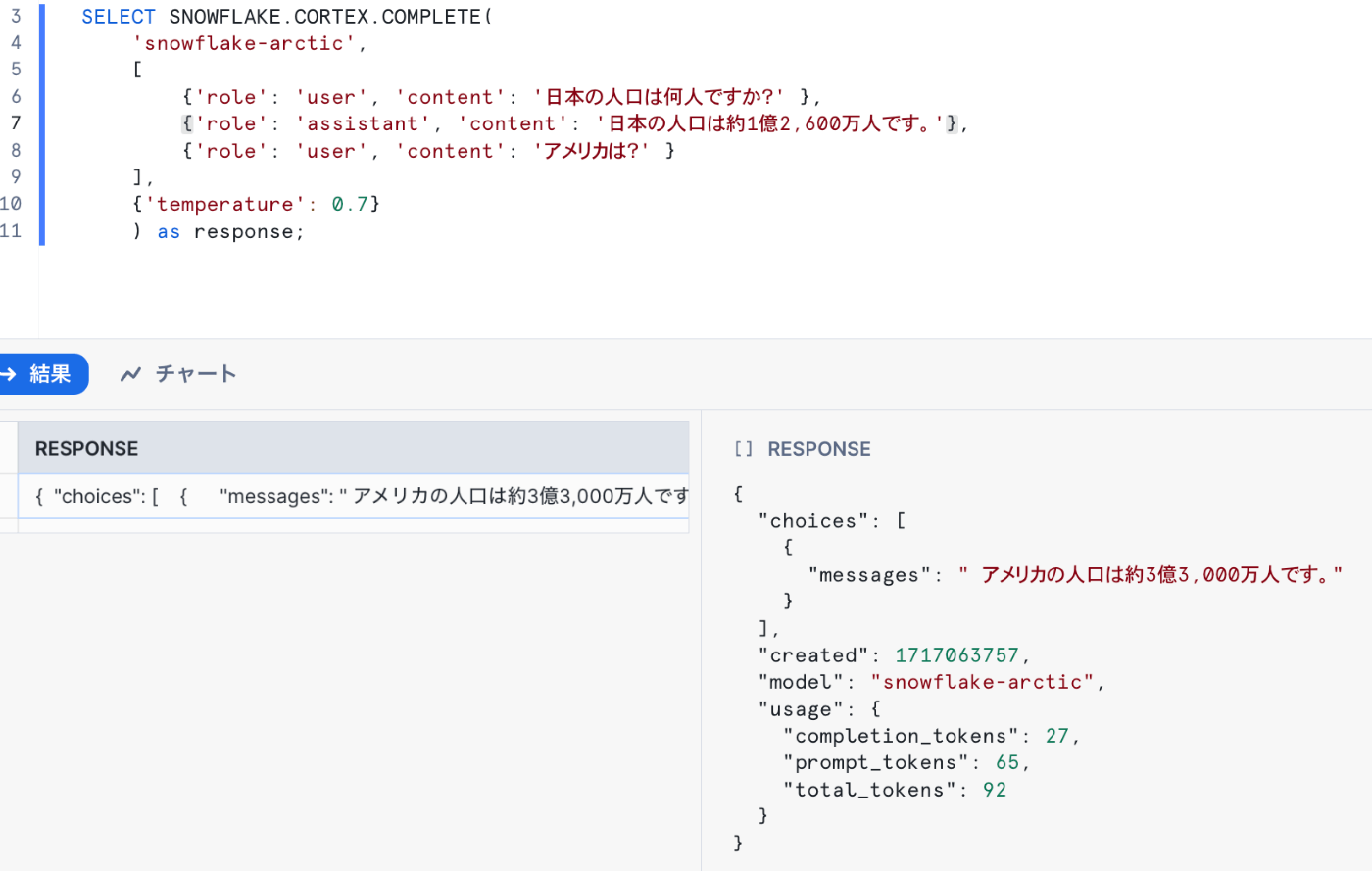
単一の場合と異なり出力はJSONオブジェクトになるため、messagesの抽出が必要です。
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'snowflake-arctic',
[
{'role': 'user', 'content': '日本の人口は何人ですか?' },
{'role': 'assistant', 'content': '日本の人口は約1億2,600万人です。'},
{'role': 'user', 'content': 'アメリカは?' }
],
{'temperature': 0.7}
) as response;
-- 応答(messages)のみ抽出したい場合
SELECT response:"choices"[0]:"messages" FROM(
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'snowflake-arctic',
[
{'role': 'user', 'content': '日本の人口は何人ですか?' },
{'role': 'assistant', 'content': '日本の人口は約1億2,600万人です。'},
{'role': 'user', 'content': 'アメリカは?' }
],
{'temperature': 0.7}
) as response
);
2. EMBED_TEXT_768
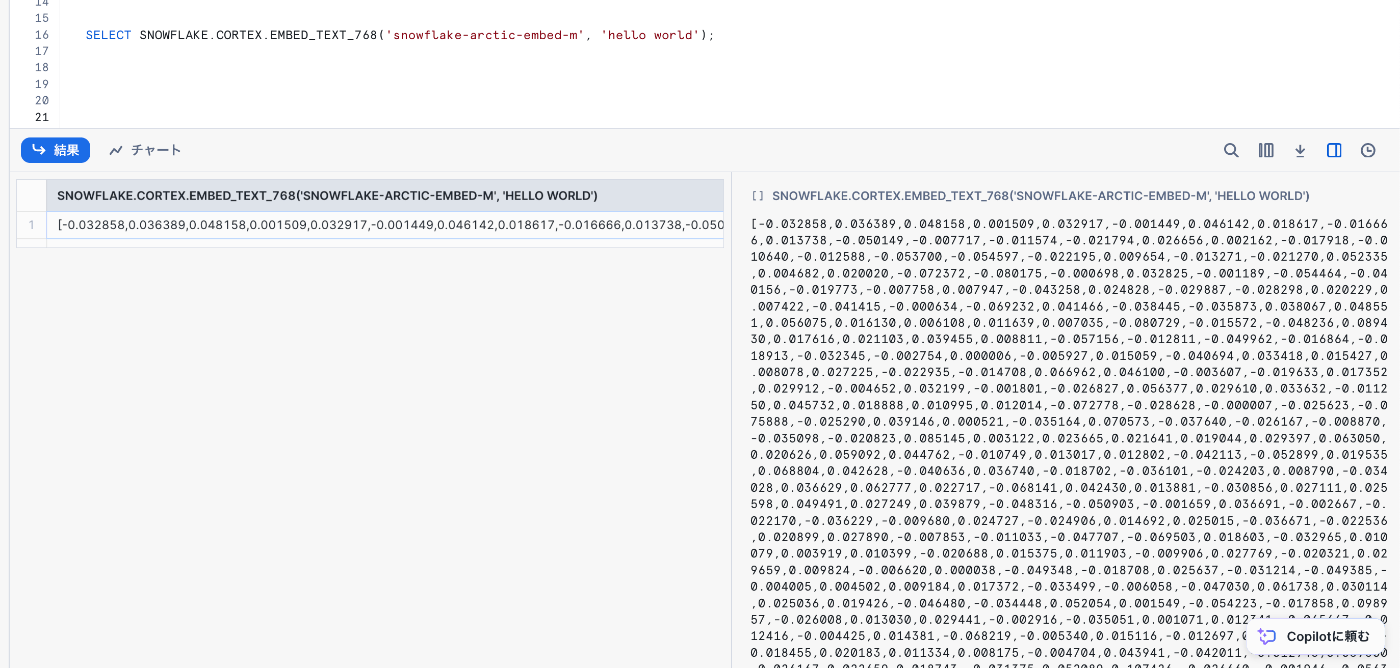
引数で渡したテキストをベクトルに変換してくれる関数です。
2024年5月末現在は英語のみ対応しているようなので、日本語をベクトル化する際は事前に翻訳しておきましょう。
(ベクトル化の原理はわからないが、とりあえずtext渡せばベクトル化できてしまう...すごい...)
SELECT SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m', 'hello world');
VECTOR_COSINE_SIMILARITYとの組み合わせ
この関数の真価は「VECTOR_COSINE_SIMILARITY」関数との組み合わせです。
VECTOR_COSINE_SIMILARITYは、2つのベクトルを引数に渡すと両方のベクトルのCOS類似度を-1~+1で出力してくれます。
つまり、2つのテキストが存在する場合、以下の流れでテキスト同士の類似度を簡単に判別できます。
- EMBED_TEXT_768関数でそれぞれのテキストをベクトル化
- VECTOR_COSINE_SIMILARITYでCOS類似度を出力
- 結果として文章の類似度を判断
(1に近ければテキストが類似、-1なら正反対のテキスト、0なら無関係)

これを応用すればRAGも簡単に実装できますね!
3. EXTRACT_ANSWER
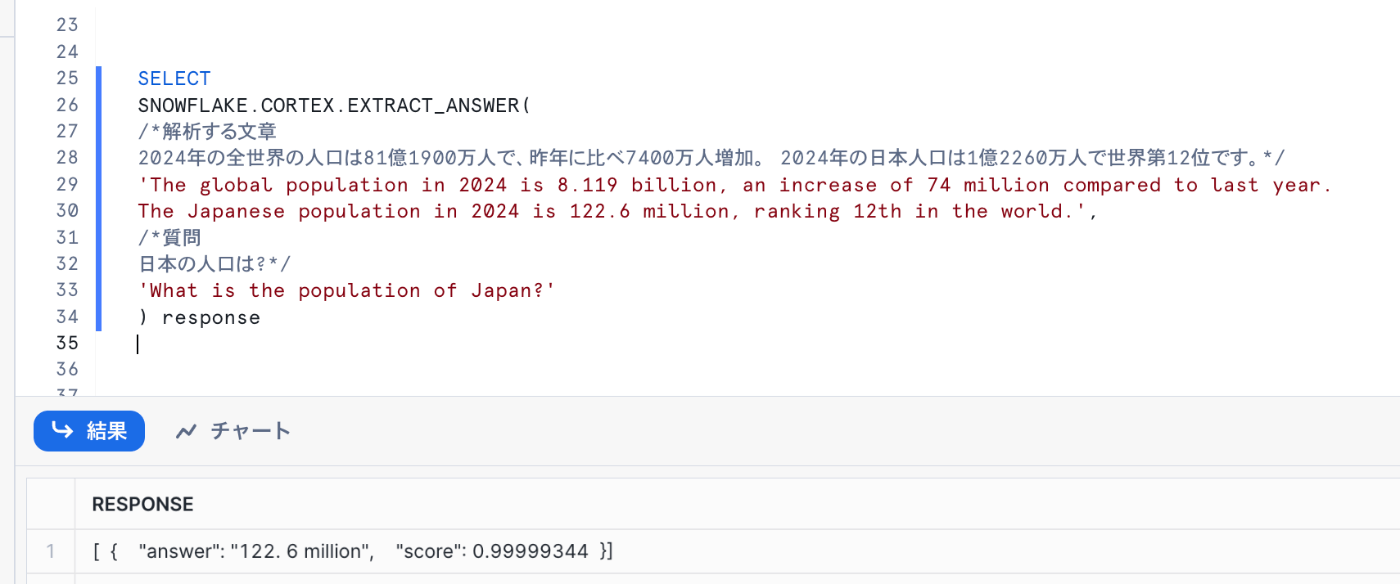
ソースのテキストと質問文を引数に渡すと、その回答と正確度がJSON形式で出力されます。
正確度は0~1で出力され、1に近いほど確度が高い回答ということになります。
サンプルは1文ですが、テーブル列に対しても実行できるので特定列からデータを抽出することも可能です。
SELECT
SNOWFLAKE.CORTEX.EXTRACT_ANSWER(
/*解析する文章
2024年の全世界の人口は81億1900万人で、昨年に比べ7400万人増加。 2024年の日本人口は1億2260万人で世界第12位です。*/
'The global population in 2024 is 8.119 billion, an increase of 74 million compared to last year.
The Japanese population in 2024 is 122.6 million, ranking 12th in the world.',
/*質問
日本の人口は?*/
'What is the population of Japan?'
) response
4. SENTIMENT
引数で渡したテキストが肯定的か否定的かを-1~+1のスコアで出力してくれる関数です。(-1が否定的、+1が肯定的です)
ユーザーのレビューコメントの解析などに使えそうですね!
SELECT SNOWFLAKE.CORTEX.SENTIMENT('I enjoyed this film very much!') as response /*この映画はとても楽しかったです!*/
UNION ALL
SELECT SNOWFLAKE.CORTEX.SENTIMENT('I don''t like this movie because of the sad scenes.') as response /*この映画は悲しいシーンが多くて好きじゃないです。*/

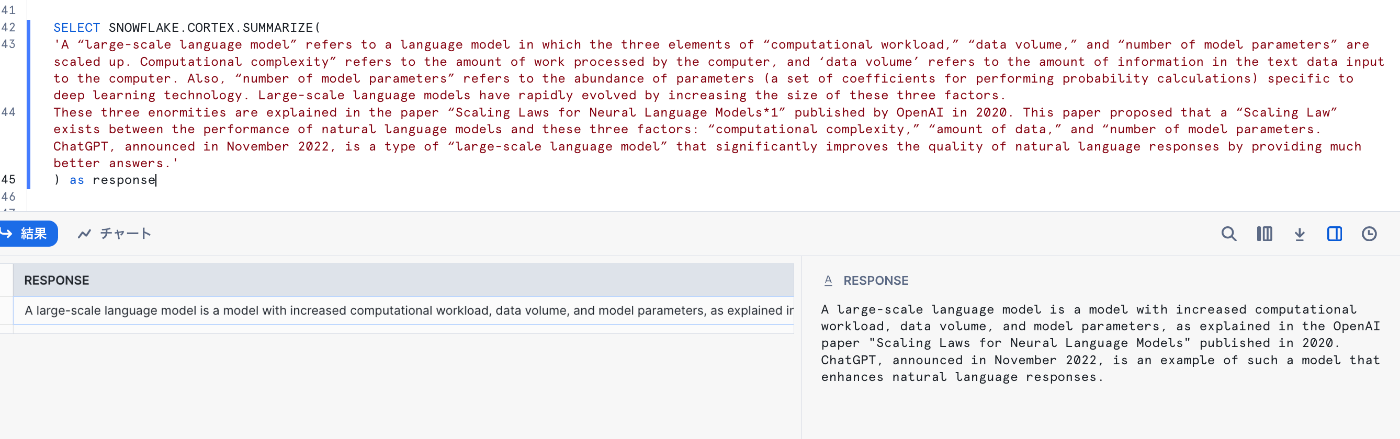
5. SUMMARIZE
引数で指定したテキストを要約してくれます。
日本語の文章も要約はしてくれますが、出力は英語でした。
SELECT SNOWFLAKE.CORTEX.SUMMARIZE(<text>)
6. TRANSLATE
引数でテキスト、翻訳前の言語名、翻訳後の言語名を渡すと翻訳結果を出力してくれます。
サポートされている言語は公式ドキュメントをご確認ください。
ただ文字数制限なのか途中で出力が切れてしまうので、自分はあまり利用していません。
SELECT SNOWFLAKE.CORTEX.TRANSLATE(<text>,'en', 'ja') as response

おわりに
LLM関数と聞くと難しい印象がありましたが、実際に触れてみるとすべて慣れ親しんだSQLで扱うことができます。
ぜひLLM関数を活用してさらにデータ活用を推進していきましょう!
(好評であればML編も記事にしてみようと思います😇)
参考ドキュメント
Discussion