ネットワークコンフィグでIaCを実現するのはなぜ難しいのか
この記事は、NTT Communications Advent Calendar 2022 21日目の記事です。
Infrastructure as Code(以後IaC)は、インフラを管理・運用する技術およびプラクティスとして広く認知され、今ではほとんどの企業で使われています。Terraform、AWS CloudFormation、Kubernetes YAMLなどを使ったことがある方も多いでしょう。インフラをコードで記述しソフトウェア開発のプラクティスを導入することで、コードの汎化と再利用、構成テスト、CI/CDの導入など、様々なメリットを享受できます。
IaCはコンピュートリソースやクラウドインフラに限った話かというとそうではなく、ネットワークにも適用できます。ソフトウェアによるネットワーク装置の管理機能は、コンフィグレーション(設定)とコントロール(制御)に大きく大別されます。コンフィグレーションで構成を宣言的に定義し、その宣言された内容に従いコントロールでスイッチング or フォワーディングする、という形です。前者のコンフィグレーションはIaCで扱うべき領域であり、大規模のネットワークを適切に管理・運用するには、IaCのプラクティスをうまく活用することが求められます。
ところがネットワークコンフィグのIaCは、コンピュートリソースやクラウドインフラのIaCとは異なり、IaCプラクティスの実践が非常にやりにくい、という問題があります。
本記事では、なぜネットワークコンフィグではIaCがやりにくいのかについて深堀りして考察し、その問題を解くための方法を探ります。
クラウドやKubernetesにおけるIaCのデータ構造について
ネットワークコンフィグでIaCがやりにくいことを深堀りするために、まずクラウドやKubernetesのIaCがどのように構成されているか見てみましょう。
IaCのリソースは、宣言的に記述される各リソースが、それぞれ制御対象のリソースとOneToOneもしくはOneToManyに紐づくように構成されることが一般的です。例えばKubernetesなら、DeploymentやPodのような各リソース(カスタムリソース含む)が、etcdの1つのドキュメントにマッピングされます。
一方、1つのリソース定義から複数のリソースを同時に作りたいケースの場合は、OneToManyが選択されます。この場合も、抽象化された高レベルリソースの下に実態のリソースがぶら下がる形になり、抽象化された高レベルリソースとの間にはOneToOneの関係を有することになります。
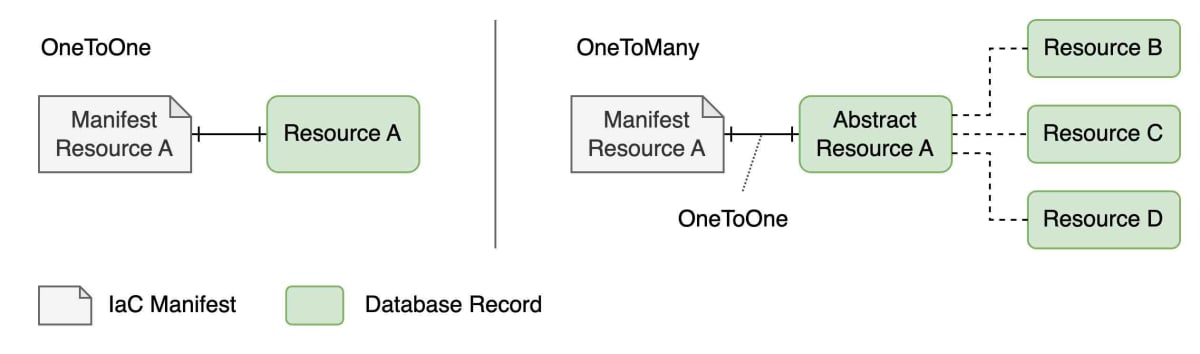
マニフェスト上のリソースと実リソースが常にOneToOneもしくはOneToManyになれば管理が容易なのですが、実際はそうではないケースが出てきます。kustomizeのoverlayが有名な例です。kustomizeでは、baseとして基礎となるマニフェストを定義しつつ、overlayとして各種transformやpatchなどを適用してマニフェストを加工するツールです。コンテナイメージやnamespaceの変更など、頻繁に実行されるケースはtransformが整備されていますが、transformが未整備の変更についてはpatchでマニフェストを合成することになります。以下に示す例の場合、生成されるマニフェストはbaseマニフェストとoverlayマニフェストの計3つを合成したものになります。

複数のマニフェストから1つのドキュメントツリーが生成される場合、それらを整合する形でマージする必要があり、マージのストラテジーが必要になります。複数のドキュメントをマージする方法としては、RFC6902 JSON Patch、 RFC7396 JSON Merge Patch、Kubernetesで用いられるStrategic Merge Patchなどが有名ですが、これらの中からマージ方式を選択しつつ適切にロジックを組まなければなりません。マニフェスト間で値に競合がある場合にどの値を優先するか、も問題になります。baseとoverlayであればoverlayの方を優先すれば良いですが、overlay間で競合がある場合はどうすればよいでしょうか。明示的に序列がある場合は問題にはなりませんが、同列として扱われる場合は、コンフリクトエラーにする、もしくはどれを優先するかをユーザに指定させる、のどちらかの対応が必要です。
このように、複数のマニフェストすなわち複数の入力が1つのドキュメントを構成する形になるManyToOneは、マージ方法、コンフリクトの制御方法、などを考え作り込む必要が生じます。これらを考慮しなくて良いように、
- KubernetesやTerraformのIaC定義では、OneToOneもしくはOneToManyにする(そのために、実リソースの制御を適切に抽象化する)
- ユースケースとしてどうしても避けられないCD(Continuous Delivery)におけるイメージタグや環境情報の更新などについては、kustomizeなどoverlayに特化したツールで対応する
というのが、クラウドインフラやKubernetesのIaCにおいて採用され、広く用いられている手法です。
ネットワークコンフィグにおけるIaCについて
ネットワークの話に戻ります。
本記事の冒頭でも紹介したとおり、ネットワークコンフィグはネットワークの振る舞いを宣言的に記述したものですが、クラウドインフラのIaCとは異なる点が大きく3点あります。
1点目は、ネットワークコンフィグはクラウドインフラのIaCで扱うような高抽象でわかりやすく記述できるものとは限らない、という点です。
そもそもの話になりますが、IaCとしてマニフェストに記述する内容は、ユーザにとって「インフラをこう構成したい」という意図(インテント)が表現できる程度に高レベルなものでなければなりません。Terraformでも「こういうマシンインスタンスを建てたい」「こういうKubernetesクラスターを建てたい」「こういうオブジェクトストレージがほしい」というインテントを冗長性を廃し凝集された形で記述するだけで、実際のリソースを作成できます。IaCの可読性と保守性を高めるためには、こういった高レベルなモデルへの抽象化は必須の作業であり、ネットワークも例外ではありません。
例としては、L2/L3VPNのようなものが考えられます。ネットワークの構成や具体コンフィグを抽象化しネットワーク全体をビッグスイッチ・ビッグルータと見立てて、抽象化されたグラフにおける端点を指定するだけでエンドツーエンドの疎通性が実現する、という形にモデリングされていれば、IaCとして見通しよく構成を記述・管理できます。
データプレーンから分離されたコントロールプレーンでネットワーク全体を集中管理するSDN[1](Software Defined Network)は、インテントに基づくネットワーク管理を実現するための技術ですが、SDNだけでネットワーク全体を構成しエンドツーエンドの疎通性を実現するのは困難です。データセンター内だけなら十分に実現可能性があり、クラウドプロバイダの中では実際に運用されていますしベンダソリューションとしても様々に選択肢がありますが、キャリアのネットワークでは物理的に全国展開している装置を全てSDN対応装置に置き換えるわけにもいかず、レガシーな装置を利活用する必要があります。また、キャリアの局舎やユーザの宅内に配置されるエッジデバイスのSDN化も道のりは険しいです。このように、キャリアネットワークの既設の物理インフラをうまく活用するためには、SDNにより適切に抽象化されたリソースだけでなく、レガシーな装置そのものを制御する必要があります。
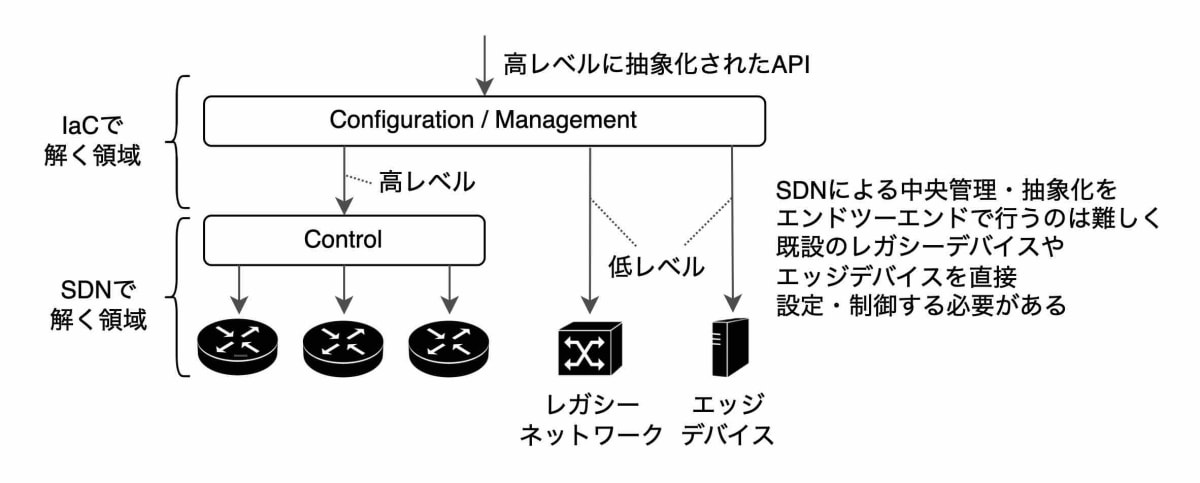
2点目は、ネットワーク装置のコンフィグはそれぞれが1つの大きなドキュメントツリーから構成されている、という点です。[2]
ネットワーク装置は、最近の装置であればNETCONF・RESTCONF・gNMIなどのプロトコルをサポートしており、これらのデータ構造はYANGというスキーマ記述用のDSLによって定義されます。YANGは、最上位のルートノードからツリー構造のドキュメントを定義できます。またYANGは、旧来のCLIコンフィグも適切に表現できる能力を有しているため、ネットワーク装置は新旧問わず単一のドキュメントツリーとして扱うことができると言えます。あくまでデータ管理にのみ着目すると、ネットワーク装置は「ネットワーキングという副作用を有した単一のドキュメントツリーだけを保持するデータストア」とみなせます。

3点目は、ネットワーク装置のコンフィグは非常に低レベルであり、IaCで扱うためには抽象化した高レベルなモデリングを行う必要がある、という点です。
前述したとおり、ユーザのインテントをわかりやすく表現できる高抽象APIがSDNにより提供されている場合は、そのリソースモデルをそのまま扱えば良いですが、装置そのものを制御対象とする場合はモデルが低レベルかつ複雑すぎてIaCで扱うことが困難です。ネットワーク装置のコンフィグを直接扱うのは、宣言的ではありますがインテントを表現できるモデルになっておらず、ユーザが理解しやすいインターフェースへの抽象化が必要です。
高レベルなインターフェースから受け取ったインテントを低レベルな装置コンフィグに変換するためには、抽象化されたモデルを定義してコンフィグ間のデータマッピングを行う必要があります。この高レベルなモデルへの抽象化において重要なポイントは、抽象化されたモデルは1つの装置ではなくネットワークの一部もしくは全体を扱うものである、という点です。前述したL2/L3VPNのエンドツーエンドのような抽象化を行う場合は、経路上の複数の装置に対して設定が投入する必要が生じます[3]。結果として、高レベルな抽象リソースを1つ設定することで、複数の装置に設定が入ることになります。逆に言えば、一つの装置には複数の抽象リソースから生成されたコンフィグが流入することになります。
なお、このデータマッピングはSDNによるネットワーク抽象化を一部代替していると捉えることもできます[4]。
上記3点から、ネットワークコンフィグにおけるIaCでは、以下の要件を満たす必要があります。
- ネットワークコンフィグのIaCでは、SDNにより適切に抽象化された理想的なリソースモデルだけではなく、装置コンフィグそのものを扱う能力が要る
- 装置コンフィグは宣言的だが低レベルすぎるため、IaCとして適切なレベルの上位モデルに抽象化する
- 上位の抽象モデルからは、マニフェスト上の1つのリソース定義から複数の装置に対して設定が投入される(OneToMany)
- 1つのネットワーク装置には、マニフェスト上の複数のリソース定義から1つの装置に対して設定が投入される(ManyToOne)
このため、ネットワーク装置のIaCでは、マニフェストに記述した上位リソースとネットワーク装置コンフィグとの関係がManyToOneないしManyToManyにならざるを得ないです。クラウドインフラのIaCでは、ManyToOneの関係を極力避け必要な箇所だけ局所的に作り込む方針で対応していたのに対し、ネットワーク装置のIaCでは、ManyToOneによって生じるマージの方法・コンフリクトの問題を真面目に解かなければなりません。

加えて、L2/L3VPNやその他のネットワークリソースを抽象モデルとした場合、ネットワークの規模やサービスの規模によりますが、その抽象モデルのリソース数は数千から数万に上ります。クラウドインフラのoverlayはたかだか数個であり、規模が大きく異なります。このスケールに対応できる技術・方式を選定する必要があります。
以降では、上記のスケールかつManyToOneの関係性を持つ上位モデルと下位モデルにおける、データマッピングの手法について深堀りしていきます。[5]
なお補足ですが、GCP・AWS・Azureのようなパブリッククラウドにおけるネットワークリソースでは、上記のような問題を一切気にせず宣言的に扱うことができます。これは、クラウドプロバイダの内部においてSDN技術を活用して適切に抽象化し内部実装を隠蔽することで、宣言的にリソースを扱えるようにしてくれているからに他なりません。本記事は、そのようなSDN技術を活用して適切に抽象化されたネットワークリソースではなく、ネットワーク装置自身の低レベルのコンフィグをいかに宣言的かつ保守性高く管理するかに主眼を置いています。
ネットワーク装置のIaCの構成とデータマッピングの難しさ
データマッピングについて深堀りするまえに、ネットワーク装置をIaCで管理するシステムの全体像を簡単に説明します。以下の図に示すとおり、大きく3つのコンポーネントから構成されます[6]。
- スタック(同じライフサイクルでまとめてデリバリされるマニフェストのグループ)を管理するスタックマネージャー
- 高レベルにモデリングされているマニフェストをデータマッピングして、ネットワーク装置のコンフィグを導出するデータマッパー
- 装置に設定を投入するデバイスドライバー

処理の流れを簡単に説明します。
スタックマネージャーでは、前回デリバリされたマニフェストをスタックに保持しています。
CLIまたはAPI経由で新しいマニフェストのデリバリ指示を受けると、前回のマニフェストと今回デリバリしようとしているマニフェストを比較して、差分を導出します。
導出された差分は、CREATE、UPDATE、REPLACE、DELETEのコマンドシーケンスの形でデータマッパーに渡されます。
データマッパーは、受け取ったコマンドシーケンスを元にデータマッピングを実行し、上位リソースからネットワーク装置のコンフィグを導出します。
導出されたコンフィグをデバイスドライバーに渡すことで、デバイスドライバーが装置ごとのプロトコル差異を吸収しつつ、コンフィグを装置に投入します。
それぞれ、様々な技術課題を抱えていて面白いトピックなのですが、本記事ではデータマッパーの箇所に限定して話を進めます。
前述したとおり、ネットワークコンフィグのIaCではマニフェストに記述した上位リソースとネットワーク装置コンフィグとの関係がManyToOneになりますが、これによりデータマッパーの実装が難しくなります。OneToOneもしくはOneToManyの関係性だと、下位リソースの親がただ1つであるため、他のリソースへの影響を気にせず疎にCRUDすることができますが、ManyToOneだと、他の親への影響を考慮しなければならないためです。この問題は特に、上位リソースを削除したり更新したときに顕著に発生します。
まず、削除のケースを考えてみます。以下は、X1というリソースを作成したのちにX2というリソースを作成し、その後X1を消したケースです。

ここで、A1という構造体(YANGだとコンテナと呼ばれます。以後コンテナを使用します)はX2が生成するコンフィグでも使用されているため消してはいけませんが、B1というコンテナはX1のみが親であるため、X1を消したときに削除しなければなりません。消さなければ、孤児コンフィグが残ってしまうことになります。一方で、A1コンテナのfooフィールドはX2も設定を投入しているため、X1を消しても削除してはいけません。このように、他の親が存在している場合は消さず、親がいなくなったら消す、という操作を、全てのレイヤで行う必要があります。
次に、更新のケースを考えます。ここでは、
- X1というリソースを作成し
- X3というリソースを作成して、A1コンテナのfooフィールドとB1コンテナのbar・bazフィールドを設定したのち
- X3を更新して、A1コンテナ・B1コンテナの各フィールドの設定を破棄し、B3コンテナを追加した
というケースを扱います。

X3の更新に伴い新規追加されたB3コンテナはこのままで良いですが、フィールドの変更・削除を行ったB1・A1コンテナでは、様々なことを考慮しなければなりません。まず、新しいX3をデータマッピングした結果B1コンテナのbar・bazフィールドがなくなりましたが、barについてはX1も親であるため削除してはならず、bazだけ削除します。同様にB1コンテナも残す必要があります。また、A1コンテナのfooフィールドについては値が99に更新されていましたが、X3の変更が破棄されたため、値を元の1に戻す必要があります。
ここでは2つの上位リソースを用いて削除・更新のケースを示しましたが、多くのケースを考慮する必要があり十分に複雑でした[7]。いわんや数万の上位リソースが存在する場合に、全ての上位リソースからのデータマッピングを全て整合しながら変更を行うのがいかに難しいか、ご理解いただけたのではないでしょうか。
データマッピングを実現する方法
上述の通り、多数の上位モデルのリソースをデータマッピングするのを愚直に解くのは困難なので、問題を別の側面から捉えて解くか、ユースケースを絞って問題を簡単化するなどの工夫が必要になります。そういった工夫を取り入れて、この問題を現実的に解くことが可能な方法を2つご紹介します。
方法1. フィールドレベルのポインタを用いて、上位・下位の依存を全て表現する
1つ目の方法は、問題を別の側面から捉えて解く方法です。
前節の例で、更新・削除するときには他の親リソースの管理下にあるかを確認する必要がありましたが、これを逐一確認するのは実装コストとしてもパフォーマンスとしても非効率です。そこで、上位リソースから下位リソースに対するフィールドレベルでのポインタを導入します。具体的には、上位リソースをデータマッピングすることで生成された装置コンフィグに含まれる全てのコンテナとフィールドに対して、1本ずつポインタを設定します。

ポインタを用いることで、削除・更新のそれぞれのケースを効率的に解くことができます。
まず削除のケースでは、上位リソースを削除する際にデータマッピングされた装置コンフィグを直接削除するのではなく、代わりにポインタを削除します。そして、ポインタがまだ残っているリソースは他の親リソースからの管理下にあるため残し、ポインタが全てなくなったフィールド・コンテナに限り削除します。これにより、他のどの親の管理下にあるかは気にせず、あくまでポインタが残っているかだけを条件として、削除するか否かの判定が可能になります。ポインタがなくなった時点で削除されるため、孤児コンフィグが残存することもなくなります。
次に更新のケースでは、更新を行う前の装置コンフィグを出発点として、更新対象の上位リソースから生えているポインタを一度削除し、そのうえで再度上位リソースからのデータマッピングを行い、生成された装置コンフィグに対してポインタを張り直します。これにより、前節の例にあったような更新時の様々なケースを考慮することなく、「ポインタを張り替えて、ポインタがなくなったフィールド・コンテナを削除する」というシンプルな処理に置き換えることが可能です。
ただし、値を設定した上位リソースを削除・更新することで設定内容が破棄されたケースに対しては、ポインタだけでは対応できません。このケースは、ポインタもしくは対象のフィールドどちらかに対して、以前設定されていた値をメタデータとして持たせることで対処可能です。これにより、値を上書きしたポインタが破棄された場合には、以前に設定されていた値を復元することで、設定前の状態に戻すことが可能です。
勘の良い方はお気づきかもしれませんが、以前設定されていた値を保持して復元することを完全に解くことは、この方式を用いても残念ながら難しいです。過去の全ての変更を順序付きで保持しなければならない上、サービスを設定更新した順番の逆操作を行う場合を除き、コンフィグが競合や不整合を起こす可能性を否定できません。このため、上書きした設定を破棄した際に値を復元する操作をフィールドレベルで行う機能は、不整合を起こさない範囲に限定するなど、スコープを絞る配慮が必要と考えています(管理下にある全ての装置コンフィグ全体をバックアップ・リストアする場合はこの限りでなく、整合が取れている任意の時点に戻すことが可能です。あくまでフィールド単位での値の復元に限定されます)。
このポインタを用いた方式は、ネットワークのIaCツールとして有名なCisco社のNSO(Network Service Orchestrator)で用いられている方式になります。より詳しく知りたい方は、Cisco社より提供されているドキュメントをご確認ください。
方法2. コンフィグ全体を都度再作成し、競合を検出したらエラーにする
2つ目の方法は、問題を簡単化することでシンプルな処理で解く方法です。
1つ目の方法では、全ての上位リソースをデータマッピングし合成した結果が永続化されていて、そこからの差分反映を効率化し画一的に解くことを、ポインタを用いて可能にしていました。2つ目の方法は、差分反映を行うのではなく、装置コンフィグ全体を毎回再生成します。
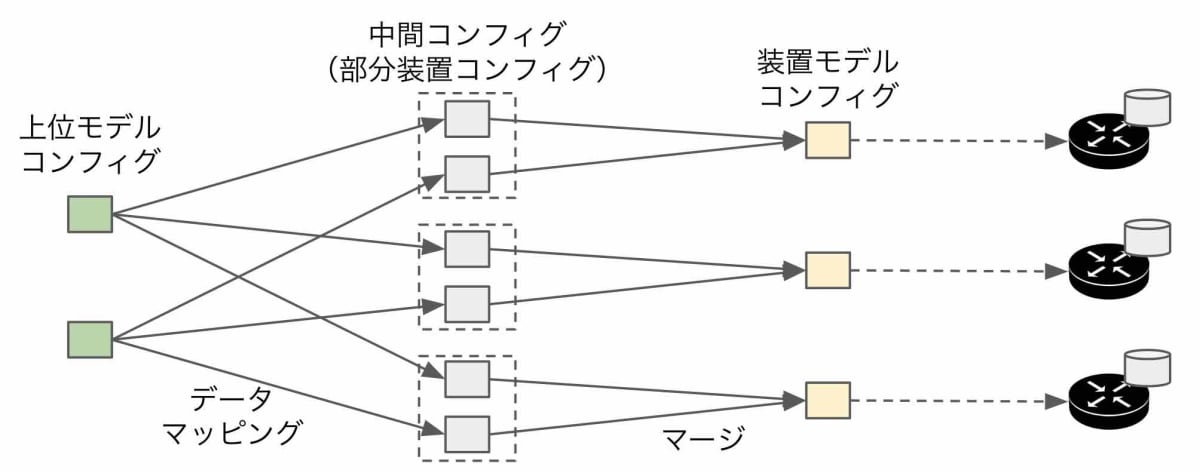
上の図を用いて説明します。まず、上位モデルの全てのコンフィグをデータマッピングにより変換します。データマッピングを行うと各装置の部分的な装置コンフィグができるので、これらを順番にマージすることで、装置コンフィグ全体を作成します。これだけです。
やっていることはとてもシンプルですが、上位モデルに渡されたコンフィグ全てを入力として全てのコンフィグを再生成しているため、前節で説明したような更新や削除に際して他の親の管理下にあるコンフィグを保護するなどといった考慮をすることなく、同等の結果を出力できます。
ただし、この方式には解かなければならない問題が2つあります。パフォーマンスと値の競合の問題です。
パフォーマンスに関しては、キャッシュを活用することで大幅に改善できます。上述した全てのデータマッピングとマージ処理を毎回やっていると膨大な計算量になりますが、データマッピング処理とマージ処理は全て疎結合な処理であるため、結果をキャッシュすることが可能です。上位モデルのコンフィグ、中間コンフィグ、マージされた装置コンフィグの全てをキャッシュし、上位モデルに変更があった箇所だけマッピングし、変更があった装置コンフィグに対してのみ伝搬してマージ処理を行う、という方式にすることで、計算量を最小化できます。
次に値の競合についてですが、そもそも競合を許容しない設計にすることで競合の解決をスコープ外とし、問題を簡単化できます。全体を都度再作成する方式にしたことでコンフィグを設定した時系列の序列がなくなったため、競合時にどの値を優先するか、というロジックを組むことができません(厳密には組めなくはないですが、利用者に優先度を決定するロジックを組んでもらう必要が生じます)。競合を解消する仕組みを組んだとしても、前述したとおり、競合の解消はあらゆるケースに対応できる完璧な解法を実現するのが難しいです。
そもそも、複数の上位モデル(すなわちユーザのインテント)をマージしたところネットワークの装置に競合が生じるというのは、装置のコンフィグが一意に定まらないイレギュラーな事態です。このため、競合するコンフィグのどれかを優先するというよりも、競合を生じる状態を解消することの方が正しい選択だと考えられます。このため、競合は許容せずエラーにしてしまい、競合を生じさせた上位モデルの修正を促す方式とすることで、競合の問題を回避できます。
方法2の技術要件
前述したデータマッピングを実現する2つの手段のうち、2つ目については、私の知る限りこの方式を採用したプロダクトやオープンソースは存在しません。本記事のしめくくりとして、この方式を実現する際に必要となる技術要件について触れたいと思います。
まず、YANGなどのスキーマ言語で記述されたスキーマに従ってマニフェストを記述する言語、もしくはデータストアが必要です。表現形式としてはRFC7951の形式か、NETCONF XML形式が妥当です。データストアは、シリアライズしてRDBに保存することも、NoSQLに保存することもできます。
次に、データをマッピングするためのロジックを記述するための処理記述言語が必要です。汎用言語のどれでも利用できますが、データマッピングの出力だけでなく処理も型安全に書けるように、型指向の言語が望ましいです。また、記述する主な処理がデータマッピングであるため、テンプレートライブラリを具備したものが良いでしょう。主要な言語であれば大体備えていますが、テンプレートの記述とテンプレートのハンドリングをする処理がシームレスで、シンプルにマッピングを記述できるものが望ましいです。
このようにデータマッピングについては幅広い選択肢から選べますが、マージ処理については特殊な要件が多く、選択肢が限られます。まず、データマッピングにより複数の部分装置コンフィグが生成されますので、これらのドキュメントツリーをマージして1つのドキュメントツリーに合成する能力が必要です。このとき、時系列の序列、すなわちマージの順によらず同じ結果を出力することが必要です。このためには、ドキュメントツリーのマージ演算に対して結合律と交換律を満たす必要があります。加えて、値の競合を許容しないためにマージの際に競合が発生したらエラーになる必要がありますが、結合律と交換律が満たされていればこの要件も満たされることは自明です。
要件を満たす新しい技術
前述の要件はネットワークコンフィグのIaCを実現する上で重要な要素となりますが、クラウドインフラ・KubernetesのIaCでも構成が複雑になると同種の課題に直面する傾向にあり[8]、その解決に向けた新しい方式が生み出されています。その1つとしてCUEという新しいデータ記述言語が2018年に公開され、徐々に広がりを見せています[9]。
CUEは、上述した要件を満たす特性を備えており、ネットワークコンフィグのIaCを記述する言語としても期待できると考えています。CUEの詳細については本家のサイトもしくは他の記事に譲ることにして、CUEがどのように要件を満たすかについてのみ、簡単にまとめます。
- CUEはドキュメントツリーの型を定義できます。
- CUEはgo structやOpenAPI、JSON SchemaなどからCUE型を自動生成できます。YANGについても、これらの形式に変換できればCUE型を自動生成できます。
- CUEは、JSONのようにデータを記述しますが、データの中に宣言的プログラミングでロジックを記述できます。テンプレートロジックを記述することもできます。
- 上記を組み合わせて、上位モデルをインプットとして受け取り、テンプレーティングを介して装置コンフィグを生成するデータマッピングロジックを簡単に記述できます。
- CUEは、結合律と交換律を満たしており、マージ順によらず同一の結果を出力します。
- CUEは、マージなどの演算を行った際に競合を起こした場合はボトム型になりエラー終了します。これにより、値の競合を検出できます。
上記より、CUEは前述の要件を全て満たしており、ネットワークコンフィグのIaCを実現する技術として期待できそうです。
まとめ
この記事では、ネットワークコンフィグではIaCの実現が難しい理由について深堀りし、
- ネットワークコンフィグを高レベルなモデルで管理するためには、高レベルのモデルから低レベルのモデルにおいてManyToOneなデータマッピングが必要になること
- ManyToOneのデータマッピングでは、マージ方法、他の親の管理下にあるコンフィグの保護、競合の解消などの問題があり、OneToManyのデータマッピングとは異なる解き方が求められること
- ManyToOneのデータマッピングには2つの解き方があり、後者の技術要件を満たすにはCUEが適していること
について説明しました。
現在、CUEを用いた宣言的ネットワークコントローラについての取り組みを進めており、開発と装置との結合検証を進めています。ご興味がある方は、以下の講演資料についてもご参照いただけると嬉しいです。
それでは、明日の記事もお楽しみに!
-
SDNについて詳しく知りたければ、ONOS開発チームによる書籍Software-Defined Networks(https://www.shoeisha.co.jp/book/detail/9784798172040)にわかりやすくまとまっているので、こちらをご参照ください。 ↩︎
-
シャーシ型の場合は、統合コントローラが各装置のコンフィグを管理し、複数のドキュメントを有する場合もあります。 ↩︎
-
利用するネットワーキング技術によって多寡は異なります。 ↩︎
-
設定更新の頻度・クローズドループ制御の周期などは大きく異なります。コントロールとコンフィグレーションの特性の違いと同様であり、コントロールはミリ秒単位での制御周期であるのに対し、コンフィグレーションは秒〜数十秒となります。 ↩︎
-
物理的に分散している複数ネットワーク装置に対してOneToManyの設定を行う必要があるため、分散トランザクションをどう実現するかという問題もありますが、こちらについては本記事ではスコープ外とします。 ↩︎
-
ネットワーク装置に対するIaCツールとしてはAnsibleが有名ですが、Ansibleも各部名称は異なりますが同様の構成を取っています。 ↩︎
-
この問題は、一部コンフィグの事前設定を前提条件としたり、削除時の孤児コンフィグを許容することで簡易化できます。Ansibleのような手続き型のIaCツールの場合は、言及した問題について一部は許容しつつ、クリティカルな箇所に限定して競合解消のロジックをpythonなどで記述することで対処しています。すなわち、上記問題を考慮しながらCRUDの各シナリオのロジックを実装しなければならず、シンプルなケースなら良いですが複雑なケースでは実装コストが大きく膨らみます。 ↩︎
-
デリバリするコンテナの数やデリバリ先の環境が増えすぎると、kustomizeやHelmの構成が複雑になり管理が困難になる、など ↩︎
-
IstioやGrafanaのマニフェスト、dagger.io、OpenSSFのFRSCAなどで使われています。 ↩︎
Discussion