はじめに
こんにちは、HRBrainバックエンドエンジニアをしているなかじです!
現在担当しているプロダクトでは「ユーザーがPDFをアップロードできる」機能があります。
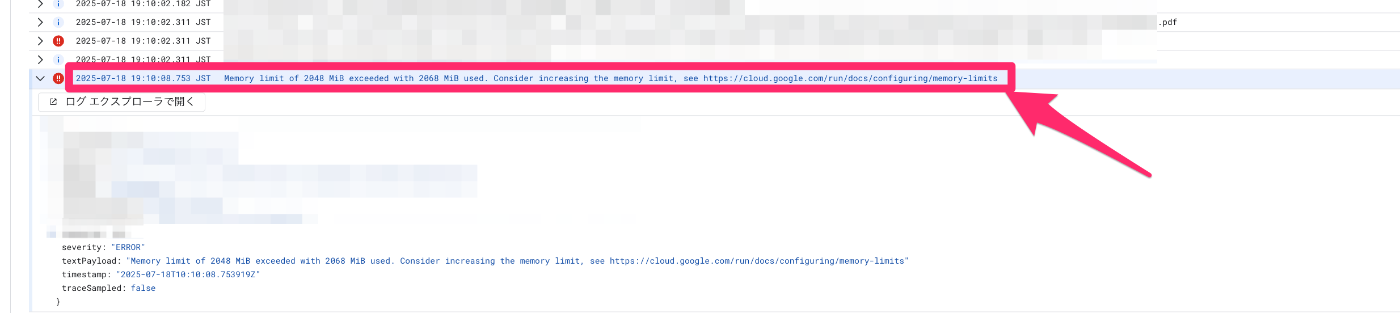
PDFアップロード機能は基本的なユースケースでは安定稼働していますが、数百ページに及ぶようなPDFや高画質の大容量ファイルを扱うと、メモリ制限で処理が失敗していました。
今後、規模が拡大する中で、より幅広い利用に耐えられる仕組みが必要になってくるため、今回改善を入れたのでそちらを紹介します。
今回は、Cloud Profilerを使ってボトルネックを特定し、処理方式を改善した結果、大幅に性能が向上したので、その内容を紹介します。
前提
使用している技術スタック
- Go / Cloud Run / GCS
- ImageMagick(imagickライブラリ)
処理概要
- 「PDFがアップロードされる → ページごとに画像へ変換 → GCSへ保存」という流れ
- ユーザーがアップロードしたPDFファイルと、変換したファイルは、別々のバケットに保存
問題点の数値(例:処理時間、メモリ消費、失敗率)
- 特定PDF(容量の大きいPDFや、ページ数の多いPDF)をアップロードすること
- 複数ユーザー同時利用で失敗が頻発
Memory limit of 2048 Mi exceeded with 2068 Mi used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits
Cloud Profiler導入
Cloud Profilerとは?
Cloud Profiler は Google Cloud が提供するアプリケーションプロファイラ です。
本番環境で動いているアプリケーションの CPU使用率 や メモリ使用量 をサンプリングし、処理のどこに時間やリソースを使っているかを可視化できます。
Cloud Profiler は、本番環境のアプリケーションから CPU 使用率やメモリ割り当てなどの情報を継続的に収集する、オーバーヘッドの少ないプロファイラです。収集した情報から情報の生成元であるソースコードが特定されるので、最もリソースを消費しているアプリケーション部分を容易に識別できます。アプリケーションの特定が難しい場合でも、パフォーマンスの特徴を把握できます。
セットアップ
今回、イベントアークをトリガーとして動くバッチのようなCloud Runの中のプロファイリングをしたかったので、Cloud Profilerを使いました。
- Cloud Runに環境変数を設定
-
profiler.Start()を呼び出すだけで有効化可能 - IAMロール
roles/cloudprofiler.agentを付与
Cloud Profiler導入は、Cloud Runの環境変数を追加して、弊社のプラットフォームチームが構築してくださったラップしたライブラリを呼び出すのみで構築できました!
以下の関数を呼び出すだけで構築できました。(プラットフォームチームいつもありがとうございます!)
if err := profiler.Start(); err != nil {
log.Fatalf("cloud run profiler not started: %v", err)
}
resource "google_project_iam_binding" "profiler_agent" {
members = [
...
]
project = module.project.id
role = "roles/cloudprofiler.agent"
}
ボトルネックの発見
分析目的:課題から、速度パフォーマンス改善よりも、メモリ使用量を抑えたい
分析項目:割り当てられたヒープメモリ
一部紹介:pprof.WriteHeapProfileの下にあたりに出力される項目
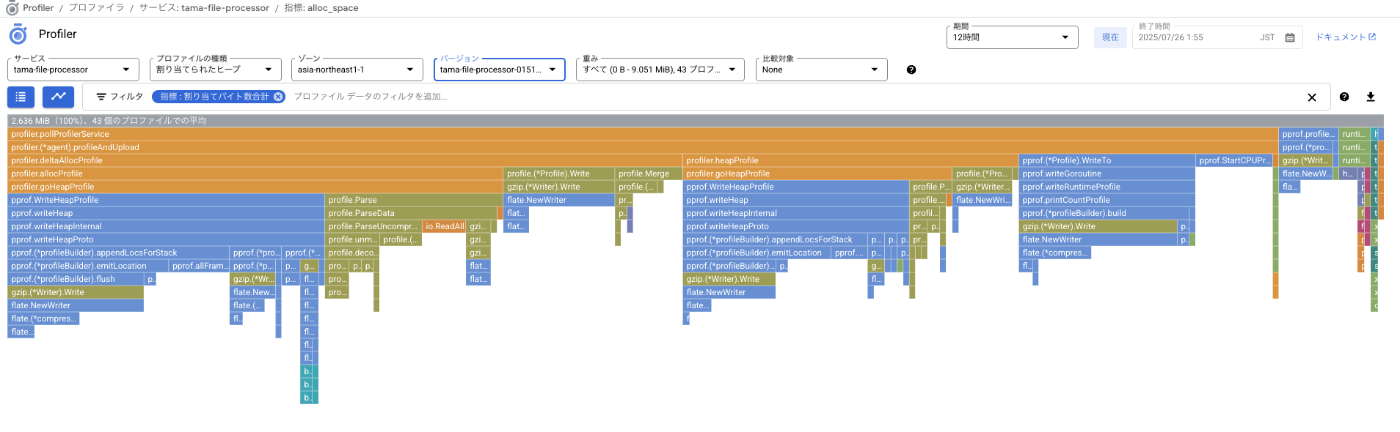
pprof.WriteHeapProfile
└─ gzip.(*Writer).Write
└─ flate.NewWriter
└─ flate.(*compressor).init
profilerから読み取れるコード特定
1️⃣ PDF全体がメモリに確保され、再度PDF全データをImageMagickに読み込み、大幅にメモリを消費している
2️⃣ 全ページを変換 → 全ページをアップロードの処理をしている(全画像データをメモリに保持)
改善アプローチ
改善対象1️⃣:PDF 全体がヒープメモリに確保されて、再度PDF全データをImageMagick に読みこみ確保している
before
- PDFの全バイナリデータをメモリ上の
[]byteスライスに一度に読み込んでいる - PDF 全体がヒープメモリに確保されたものが、GCで解放対象となるのは、関数が終了し、そのスコープ内で参照がなくなった後
- ImageMagickのメモリ空間にPDFデータを展開・保持している点
after
// 1ページのPDFを画像に変換する
func ConvertPDFToImage(tmpfilePath string, index int) ([]byte, error) {
mw := imagick.NewMagickWand()
defer mw.Destroy()
if err := mw.SetResolution(dpi, dpi); err != nil {
return nil, fmt.Errorf("failed to set resolution: %w", err)
}
// "file.pdf[0]" のようにページ指定読み込み
pagePath := fmt.Sprintf("%s[%d]", tmpfilePath, index)
// 対象ページのみを読み込む
if err := mw.ReadImage(pagePath); err != nil {
return nil, fmt.Errorf("failed to read image from file: %w", err)
}
if err := mw.SetImageFormat("jpg"); err != nil {
return nil, fmt.Errorf("failed to set image format: %w", err)
}
if err := mw.SetImageCompressionQuality(quality); err != nil {
return nil, fmt.Errorf("failed to set image compression quality: %w", err)
}
imageBlob, err := mw.GetImageBlob()
if err != nil {
return nil, fmt.Errorf("failed to get image blob: %w", err)
}
return imageBlob, nil
}
- 一時ファイルを /tmp に保存し、1ページずつ読み込む方式に変更
- ImageMagickは "file.pdf[0]" のようにページ指定で読み込み可能
- インデックスでアクセスする(
"file.pdf[0]")には、一時ファイルの活用して、ファイルパスでアクセスしないといけない(イメージマジックの仕様上仕方ない)
- インデックスでアクセスする(
※インメモリファイルシステム(一時ファイル/tmp)に保存するがパフォーマンス改善ではありません
- Cloud Runの仕様では、メモリ効率は、バイトデータダウンロードと同じ
https://cloud.google.com/run/docs/configuring/services/memory-limits?hl=ja#understanding
改善対象2️⃣:全ページを変換 → 全ページをアップロードの処理
before
- 全ページ変換 → 全ページを一度にアップロード
- PDFの全ページを画像に変換した後、それらすべてを
[][]byteスライスとしてメモリ上に保持し、呼び出し元に返している
after
// PDFファイルを1ページごとにJPEG画像に変換して、分割単位でアップロードする
for i := range splitCount {
imgData, err := pdf.ConvertPDFToImage(tmpFilePath, i)
if err != nil {
return fmt.Errorf("failed to split PDF to image for page %d: %w", i, err)
}
// ファイルパスを生成
imagePath, err := domain.GenerateFilePath()
if err != nil {
return fmt.Errorf("failed to generate processed file path: %w", err)
}
if err := u.file.UploadBytes(ctx, storage.ProcessedFilesBucket, imagePath, "image/jpeg", imgData); err != nil {
return fmt.Errorf("failed to upload image to GCS (page: %d, path: %s): %w", i, imagePath, err)
}
}
- 「全ページを変換 → 全ページをアップロード」という2段階の処理を、「1ページ変換 → 1ページアップロード → 次のページへ」にする
結果
400枚以上のPDF、大容量のPDFを複数同時アップロードできるようになりました!👏👏👏
まとめ
Cloud Profilerを使うことで、本番環境のメモリ使用状況を正確に把握できるのでおすすめです!
メモリ効率を気にするのは大事だなと感じました〜(おもろいですね)
また次回の記事でお会いしましょう!👋

Discussion