疑問:末尾呼び出し最適化(goto)をCで書いたらスタックは少なく消費されるのか?
経緯とお題
人と話していて以下のように疑問を抱いた。
- 本当に再帰はスタックを多く消費するのか?
- 末尾再起で良くなるのか?
- C言語で末尾呼び出し最適化ぽいことをしたらどうなるのか?
なので、以下のようなコマンドライン引数として関数(ループ、再帰、末尾再起、末尾呼び出し最適化(goto))とNの指定が出来るようなフィボナッチ計算をするコードを使用し、スタックメモリの消費率を計測してみた。
実験の流れ
-
コンパイル
gcc -o fib_compare fib_compare.c -
デフォルトではヒープメモリのみ計測するようになっていて、スタックメモリの計測はオフになっているので以下のようにオプション指定しながら、valgrindでmassif指定で実行し、指定名のファイルを作成するようにした。
ex.)
valgrind --tool=massif --heap=no --stacks=yes --massif-out-file=fib_loop.txt ./fib_compare 0 30
valgrind --tool=massif --heap=no --stacks=yes --massif-out-file=fib_rec.txt ./fib_compare 1 30
... -
ms_printだと見にくいので、massif-visualizerで可視化
massif-visualizer *.txt
結果
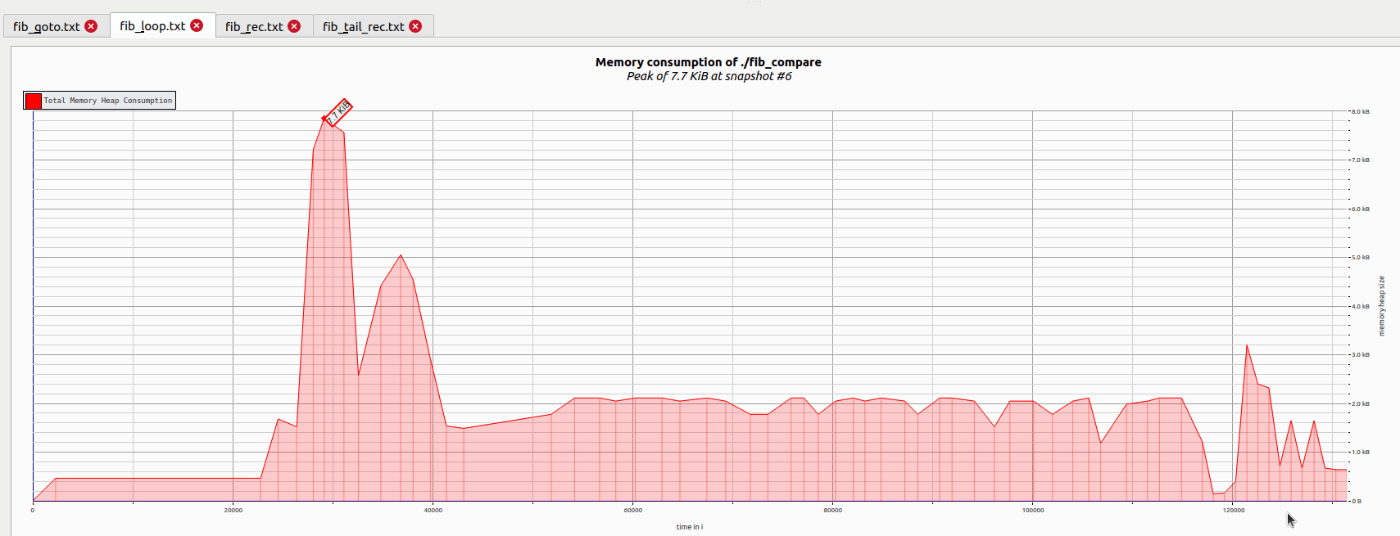
- fib_loop.txt
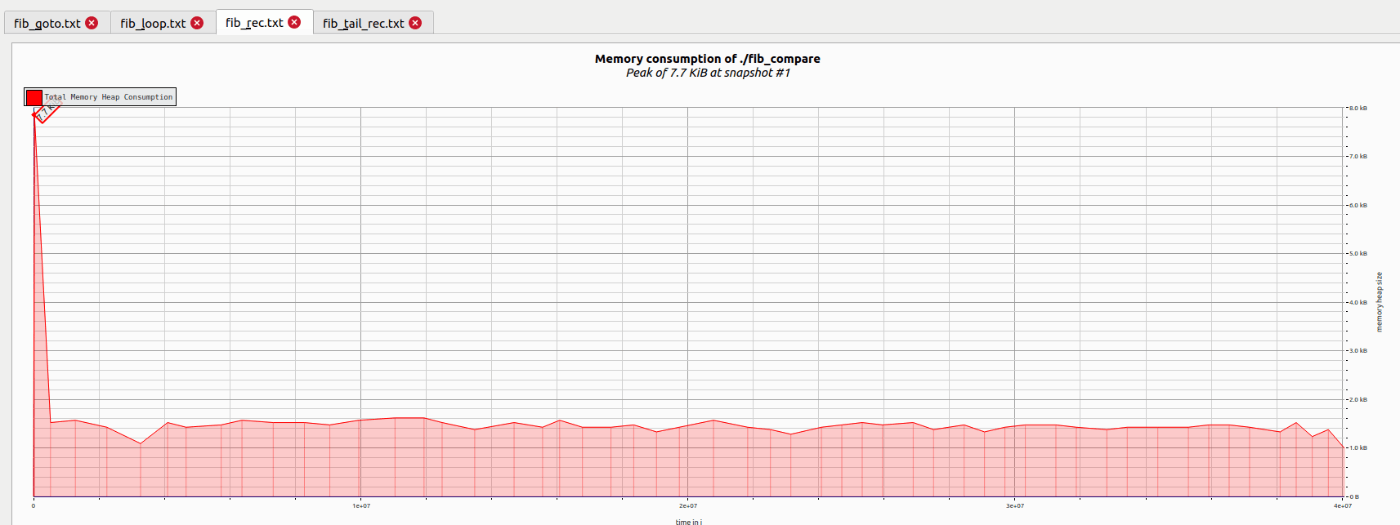
- fib_rec.txt
- fib_tail_rec.txt

- fib_goto.txt

疑問
- なぜそのタイミングでピーク時なのか?
- Nの値を大きくしてもなぜピークはずっと7.7KiB?
7.7KiBにはこれが影響していそう
--peak-inaccuracy=<m.n> [default: 1.0]
Massif does not necessarily record the actual global memory allocation peak; by default it records a peak only when the global memory allocation size exceeds the previous peak by at least 1.0%. This is because there can be many local allocation peaks along the way, and doing a detailed snapshot for every one would be expensive and wasteful, as all but one of them will be later discarded. This inaccuracy can be changed (even to 0.0%) via this option, but Massif will run drastically slower as the number approaches zero.
もしかして、massifを使用したのが間違い?
詳しく出る動的解析ツールある?
実行時間も計測してみた
f(n), n=46がintの範囲内に収まる最大値を計算できる。
./measure_time.bash 46
bashの内容は以下の通り。
ループ: fib(46) = 1836311903
実行時間: real 0m0.001s
user 0m0.001s
再帰: fib(46) = 1836311903
実行時間: real 0m7.968s
user 0m7.967s
末尾再帰: fib(46) = 1836311903
実行時間: real 0m0.001s
user 0m0.001s
末尾呼び出し最適化 (goto): fib(46) = 1836311903
実行時間: real 0m0.000s
user 0m0.000s
goto文が一番早かった。
参考
Discussion
コンパイラがどう変換するか?メモリの深掘り、や他の動的解析ツールで計測するとかでもっとちゃんと理解できそう。
先生におすすめされた計測方法
スタックポインタの値を見る