BERTの埋め込み空間の可視化を最速で
BERTのtoken embeddings(入力部分にある単語id->単語埋め込みに変換する層)の埋め込み空間の可視化をやったので、手順をまとめた。
文脈化単語埋め込みの方(BERTの出力ベクトル)の可視化も似たような手順でできると思う。
今回は東北大の乾研の方が公開されている日本語BERT(cl-tohoku/bert-base-japanese-whole-word-masking)を利用した。
使用する技術は主に以下。
- huggingface/transformers: 事前学習済みモデルの利用
- holoviews: 可視化まとめツール
- t-SNE: 次元削減
- poetry: パッケージマネージャ
環境構築
poetryでいい感じにやった。
以下のpyproject.tomlをコピペしてpoetry installすればよさそう。
[tool.poetry]
name = "hoge"
version = "0.1.0"
description = ""
authors = ["hogefuga"]
[tool.poetry.dependencies]
python = "^3.8"
transformers = "^4.6.1"
torch = "^1.8.1"
holoviews = {extras = ["recommended"], version = "^1.14.4"}
numpy = "^1.20.3"
param = "^1.10.1"
matplotlib = "^3.4.2"
bokeh = "^2.3.2"
plotly = "^4.14.3"
fugashi = {extras = ["unidic-lite"], version = "^1.1.0"}
jupyter = "^1.0.0"
ipadic = "^1.0.0"
sklearn = "^0.0"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry>=0.12"]
build-backend = "poetry.masonry.api"
コード
結構単純なことしかやっていないが、流れとしては
- 東北大の日本語BERTのモデルとtokenizerをロード
-
model.get_input_embeddings()でnn.Embeddingのインスタンスが取れるので、そこからtorch.Tensorを作る。 -
tokenizer.get_vocab()で辞書オブジェクトを取得 - ベクトルのリストなり辞書なり何かにする
- t-SNEの設定をして、射影する(東北大BERTの語彙サイズは32000なので、全部やると超重いため今回は頻度順上位3000個)
- holoviewsの設定をして、インタラクティブにグラフを見たいので
plotlyの設定をしつつグラフを描画する。
# %%
import torch
from transformers import AutoModel, AutoTokenizer
# %%
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")
model = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")
# %%
token_embeddings = model.get_input_embeddings().weight.clone()
vocab = tokenizer.get_vocab()
vectors = {}
# %%
for idx in vocab.values():
vectors[idx] = token_embeddings[idx].detach().numpy().copy()
# %%
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0)
# %%
reduced_vectors = tsne.fit_transform(list(vectors.values())[:3000])
# %%
import holoviews as hv
from holoviews import opts
hv.extension('plotly')
# %%
points = hv.Points(reduced_vectors)
labels = hv.Labels({('x', 'y'): reduced_vectors, 'text': [token for token, _ in zip(vocab, reduced_vectors)]}, ['x', 'y'], 'text')
(points * labels).opts(
opts.Labels(xoffset=0.05, yoffset=0.05, size=14, padding=0.2, width=1500, height=1000),
opts.Points(color='black', marker='x', size=3),
)
実験結果
結果としては以下の通り。
結構BERTのtoken embeddingsってまともなんだなという気持ちになった。
これ文脈化単語埋め込み(contextualized word embeddings, BERTのTransformer Stackから出力される方)じゃないので、その点だけご注意を。
大体同じ空間を構成すると思うけど。
(誰か文脈化単語埋め込みの方で検証してくれたら喜びます)
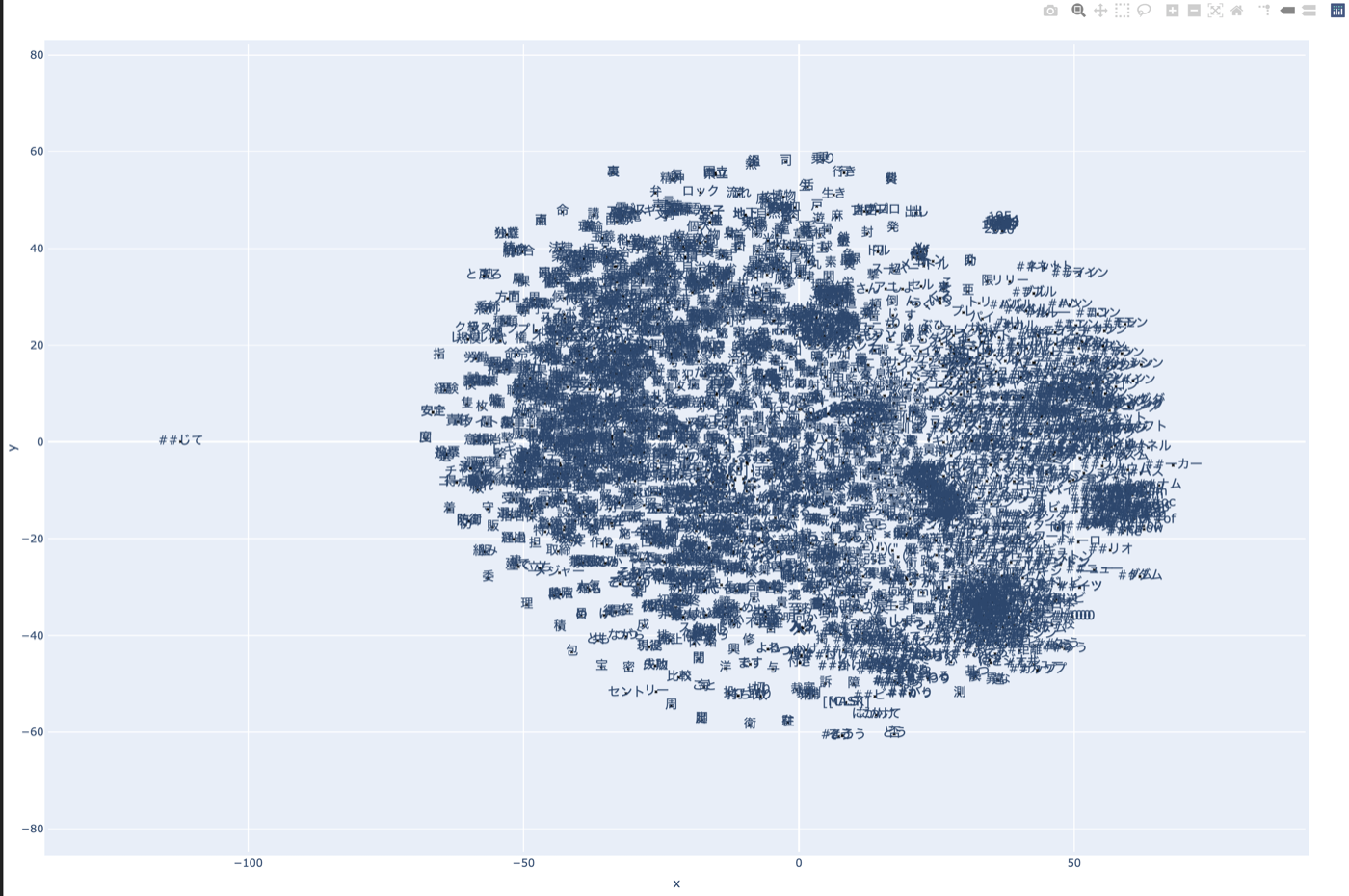
大きな図を見てもよくわからないのでもっとズームした図を見てみる。
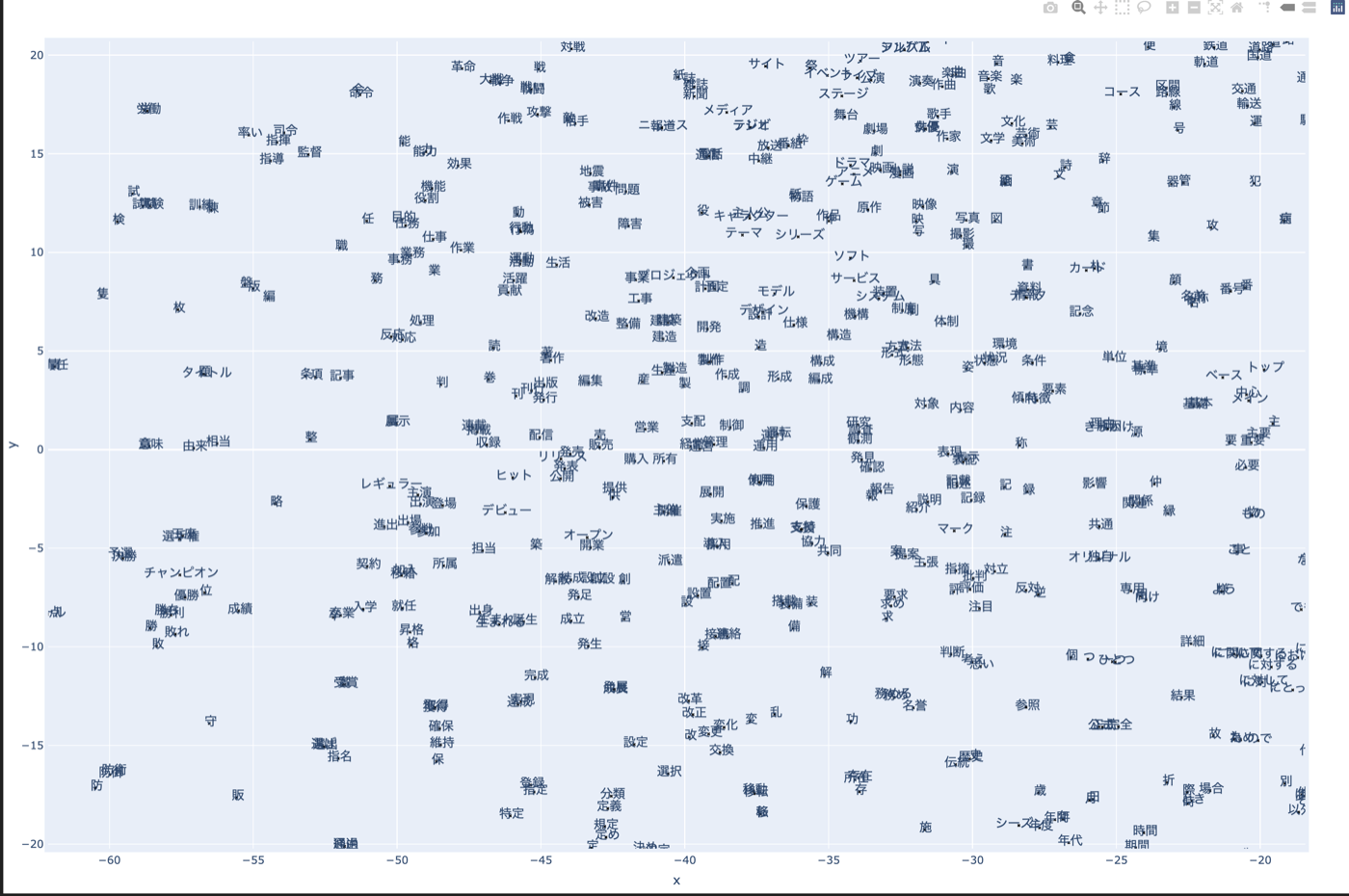
上図を見ると、例えば「優勝」「チャンピオン」「勝利」や「改革」「改正」「変化」、「研究」「調査」のような、意味的に近い単語が埋め込み空間上でも近くに分布していることがわかる。
他の部分も見てみる。

上図を見ると、例えば数字(0~9とかまあ数字全般)、記号(symbol)が固まってたり、右下に元号が固まっていたりする。
さらに他の部分も見てみる。
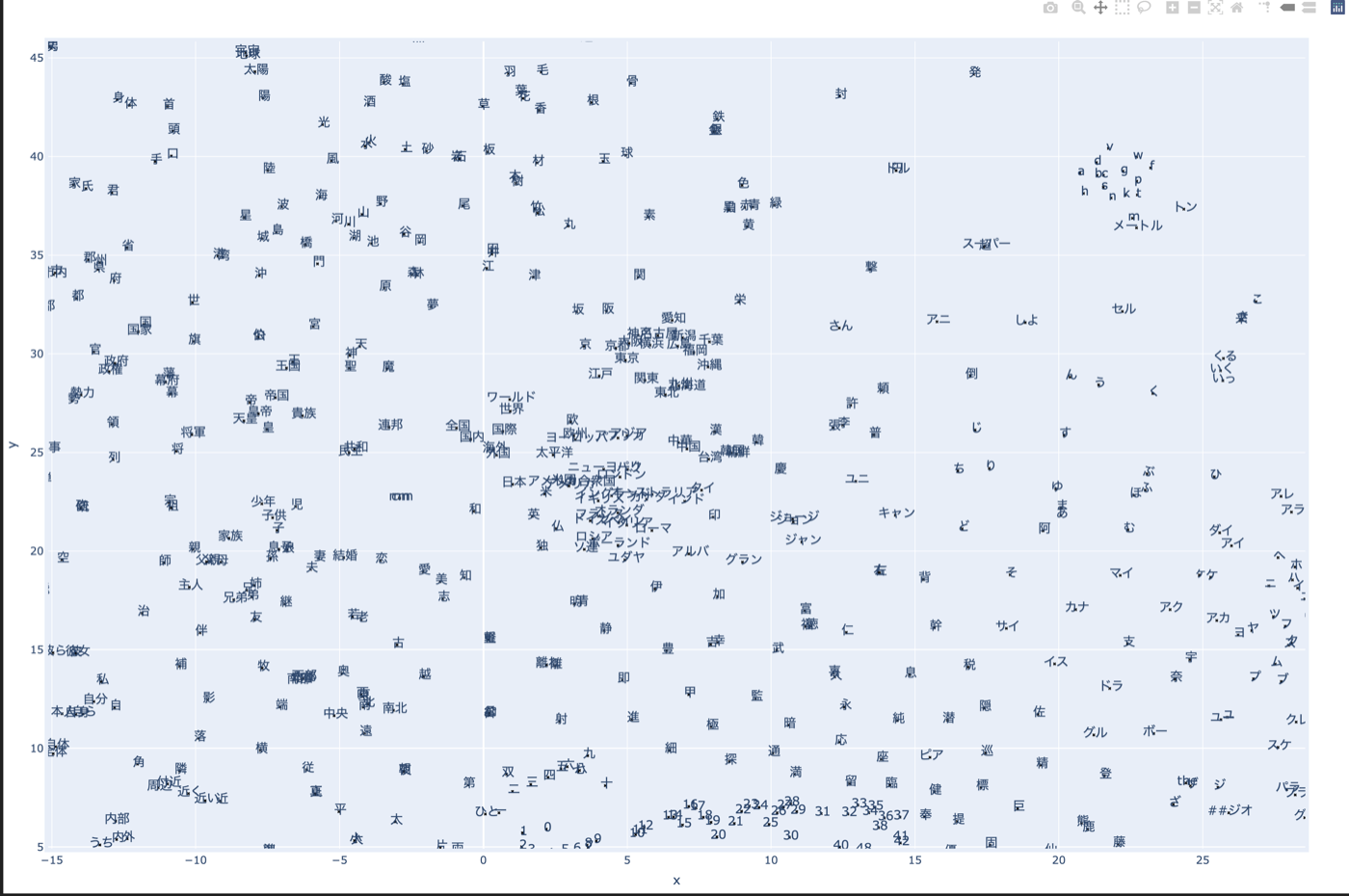
上図を見ると、中心に国名が固まっていて、その近くに日本の地名クラスタができていそうなことがわかる。
また、右上に数量単位クラスタがありそう。
とりあえずはこんなところで、頻度順上位3000語(サブワード)じゃなくて、もっと多くを見てみたり、頻度順下位からみたりするのもいいと思う。
英語BERTやその他のRoBERTaとかの埋め込み空間を見ても面白いと思うし、GPT-2とかAutoRegressiveなモデルの埋め込み空間を見ても面白いと思う。
何か質問があれば @hpp_ricecakeまでなんでもどうぞ!
再現実験用の環境構築用コードはこのリポジトリを参照ください。
追記: 英語のBERTについてもやってみた
結構不思議な分布をしていておもしろい。
使用したモデルはbert-base-uncased。
Discussion