はじめに
Metaが新しく公開したLLMの性能が他の最新モデルに匹敵する性能となっており、ベンダーから提供されるAPIを使わずに、自分のPC上でLLMを動かしたい欲求が高まりました。
ローカルでLLMを動かすメリットとして、以下が考えられます。
- 従量課金制のAPIの費用を気にしなくて良い (※PCの電気代はかかるが)
- 個人情報を第三者に送信しないので、プライバシー面を考慮する必要がない
LM Studio
ローカルでLLMを動かす懸念として、環境構築など準備に時間がかかることが一つ挙げられます。
そこで、便利なツールを探していたところ、LM Studioを発見しました。
このツールは、GUI上でLLMの取得から起動までをボタンクリックで進めることができます。
さらに、チャットのUIやローカルサーバの起動・Pythonコード例の提示までしてくれる便利ツールとなっていました。
操作手順
使用したいモデルを選択し、ダウンロードする。
ダウンロードが完了したら、モデルを選択し、ロードします。
ロードが完了したら、チャットができるようになります!
注意点
- モデルの容量以上のGPUメモリが必要です
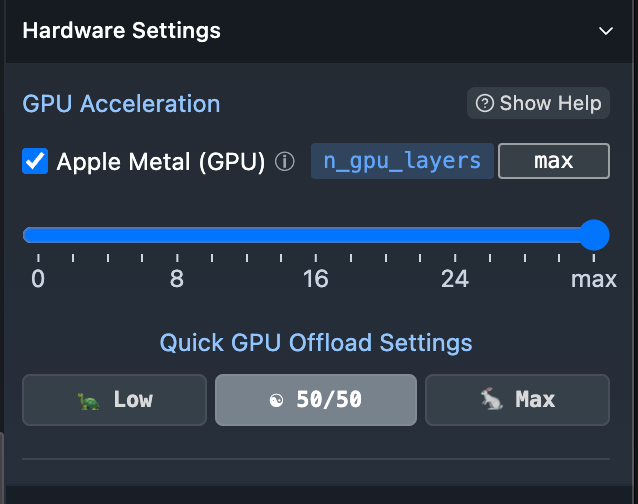
Apple Silicon の場合は、通常のメモリをGPUメモリとしても扱うことができる - GPUを最大限利用するには、設定を確認する
Macの場合、デフォルト値がMaxではありませんでした。
動かしてみた結果
Meta LIama 3 と Command R+ を動かしてみました。以下のtoken/sはほぼテキスト生成速度です。
PC環境
M2 Max メモリ64GB
Meta LIama 3
| モデル名 | 使用VRAM(GB) | token/s |
|---|---|---|
| 8B Q2_K | 3.3 | 30.34 |
| 8B Q4_K_M | 5.1 | 27.28 |
| 8B Q8_0 | 8.5 | 21.48 |
| 8B fp16 | 15 | 14.80 |
Command R+
| モデル名 | 使用VRAM(GB) | token/s |
|---|---|---|
| r-plus-IQ2-M | 34.9 | 2.0 |
わかったこと
- 量子化されるビット数が小さいほど、小型になり、速度も上がる。
- 量子化により、どれくらい精度が落ちるのかはモデルごとの具体的な情報は見当たらない。 - GPT-4-turboのAPIのレスポンス速度は10 ~ 30 token/s前後であることを考えると、Mac Bookでは現状小型のLLMを使う程度が現実的である。
- Command R+など性能の高いモデルは使用メモリ・速度ともに動かすことはできるが、実用できる水準ではない。

Discussion